Como você pode analisar todos os dados? Ou seja, como você pode analisar todos os dados a partir deste momento?
O Hadoop é o padrão de fato para armazenar e analisar muitos dados, muitos mesmo, mas como eles são armazenados? Como são analisados? Primeiro, eles são importados, como um lote. Em seguida, são processados como um lote. A palavra-chave? Lote. Enquanto um lote de dados está sendo importado ou processado, os dados continuam a ser gerados. Se os dados forem importados uma vez por dia, os dados no Hadoop estarão incompletos. Está faltando um dia de dados. Se o processamento exigir uma hora, os resultados estarão incompletos. A entrada estava faltando uma hora de dados.
E se a análise precisar incluir dados gerados na última hora?
Arquitetura Lambda, definida por Nathan Marz, criador do Storm - um processador de fluxo.
E se os dados forem processados em um fluxo contínuo de dados? Quando os dados são gerados, eles são processados antes de serem armazenados. Agora, a análise pode incluir dados gerados no último segundo, no último minuto ou na última hora, processando os dados recebidos, não todos os dados.
Se você puder combinar dados processados no Hadoop com dados processados de um processador de fluxo, poderá analisar todos os dados gerados a partir deste momento.
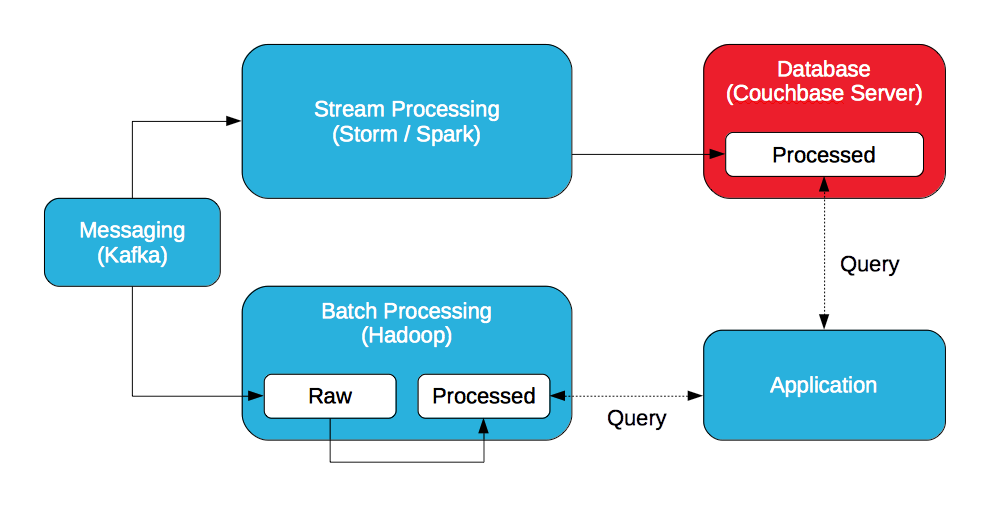
Mensagens
Um sistema de mensagens distribuídas (Kafka, JMS ou AMQP) é ideal para a ingestão de dados com alta taxa de transferência e baixa latência.
Processamento de fluxo (camada de velocidade)
Um sistema de processamento de fluxo distribuído (Storm, Spark Streaming) é ideal para analisar dados recebidos em tempo real. Enquanto o Storm processa dados individuais, o Spark Streaming processa mini-lotes de dados.
Hadoop (camada de lote)
O Hadoop armazena lotes de dados brutos e os processa com o MapReduce / Pig ou Spark.
Banco de dados
Um banco de dados distribuído é ideal para armazenar dados processados gerados pelo processador de fluxo. Um processador de fluxo não armazena nem os dados brutos nem os dados processados. Ele não armazena dados. O banco de dados deve ser capaz de atender aos requisitos de alta taxa de transferência e baixa latência do processador de fluxo para que ele não se torne o gargalo.
Aplicativo (camada de serviço)
Um aplicativo consulta os dados processados no Hadoop e no banco de dados para criar uma visão completa dos resultados. O aplicativo pode consultar o Couchbase Server com SQL (via N1QL) e / ou visualizaçõese Hadoop com Hive ou Impala / Drill.
Se a ideia é consultar dados processados, em lote e em fluxo contínuo, por que não armazenar todos os dados processados no banco de dados para que ele seja a camada de serviço?
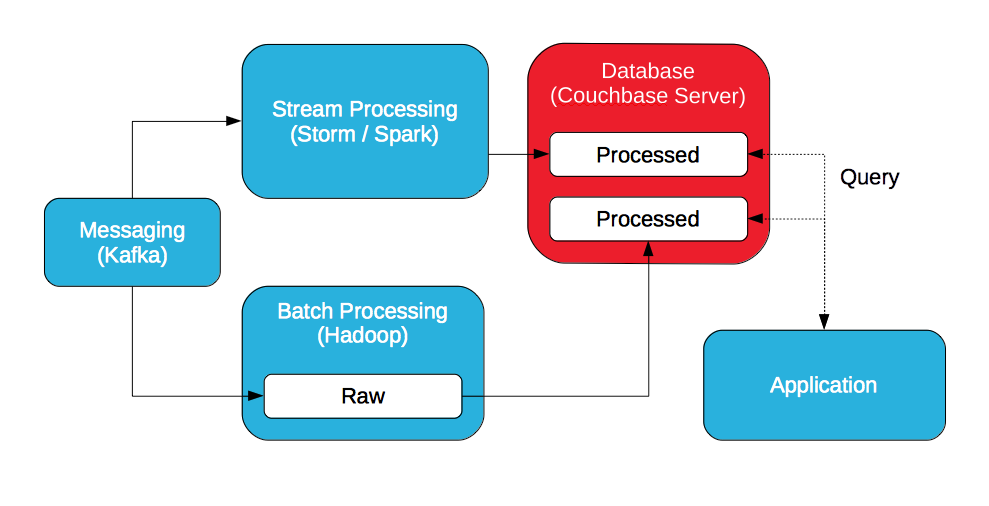
Há duas opções: armazenar os dados processados no Hadoop e exportá-los para o banco de dados ou armazenar os dados processados no banco de dados. Os dados podem ser exportados do Hadoop para o Couchbase Server com um plug-in para o Sqoop.
Com o Couchbase Server, os dados processados podem ser acessados com uma API de chave/valor ou consultados com SQL (via N1QL). Além disso, os dados processados podem ser processados posteriormente e consultados com visualizações. As visualizações são implementadas com map/reduce para classificar, filtrar e agregar dados, mas aproveitam as atualizações incrementais.
Notas
O Hadoop é necessário. Embora seja possível implantar o Spark sem o Hadoop, as distribuições da Cloudera, Hortonworks e MapR o incluem. O Hadoop armazena muitos dados brutos, o Spark os processa e a localidade dos dados é importante. Além disso, o Hadoop é mais do que o Spark. Ele inclui o MapReduce e o Pig. Inclui o Hive. O Cloudera Enterprise inclui o Impala, o Hortonworks Data Platform inclui o Tez e o MapR inclui o Drill.
Apesar do que um fornecedor de NoSQL possa sugerir (estou olhando para você, DataStax), tanto o Hadoop quanto o NoSQL são necessários. Um banco de dados NoSQL não pode substituir o Hadoop integrando-se ao Spark.
Shane - É um tópico interessante que você está analisando a partir de um ponto de vista do CouchBase (ingestão de dados). O outro lado disso é a camada do aplicativo; a apresentação e o uso comercial dos dados que estão sendo transmitidos. Já trabalhei com muitos clientes que disseram que queriam painéis e análises com latência zero, mas depois ficaram frustrados porque a granularidade das informações exibidas era muito baixa. O exemplo que usei com os clientes é o "ticker do mercado de ações". Ele informa a cada negociação o que as ações de uma empresa estão fazendo, mas não diz nada sobre o desempenho geral do mercado ou o desempenho de longo prazo da empresa.
Estou comentando, não criticando o artigo do blog.
Em minha experiência, como arquitetos de informação, devemos ser muito criteriosos, pois precisamos comunicar os prós e contras comerciais do fluxo de dados para aplicativos. Na minha opinião, as empresas precisam de uma linha de base histórica como componente de uma infraestrutura de dados. Dados históricos, possivelmente agregados e de fluxo contínuo para uma boa análise preditiva.
Obrigado.
Esse é um pensamento relevante. Entretanto, a granularidade é configurável. Por exemplo, um processador de fluxo poderia avaliar todas as negociações para identificar o desempenho do mercado, e não de uma ação, em tempo real. Os aplicativos que aproveitam as exibições do Couchbase Server podem classificar, filtrar e agregar dados para acesso quase em tempo real por meio de painéis. Talvez para agregar por indústria ou setor. Embora, como você disse, valha a pena combinar dados históricos com dados de streaming para obter um quadro completo.