모든 데이터를 어떻게 분석할 수 있을까요? 즉, 지금 이 순간을 기준으로 모든 데이터를 어떻게 분석할 수 있을까요?
하둡은 많은 양의 데이터를 저장하고 분석하기 위한 사실상의 표준이지만, 어떻게 저장될까요? 어떻게 분석할까요? 먼저, 일괄적으로 가져옵니다. 그런 다음, 일괄 처리됩니다. 핵심 단어는? 배치입니다. 데이터 배치를 가져오거나 처리하는 동안 데이터는 계속 생성됩니다. 데이터를 하루에 한 번만 가져오는 경우, Hadoop의 데이터는 불완전합니다. 하루의 데이터가 누락된 것입니다. 처리에 1시간이 필요한 경우 결과가 불완전한 것입니다. 입력에 한 시간 분량의 데이터가 누락되었습니다.
분석에 마지막 순간에 생성된 데이터를 포함해야 하는 경우 어떻게 해야 할까요?
람다 아키텍처는 스트림 프로세서인 Storm의 창시자 네이선 마츠가 정의한 아키텍처입니다.
데이터가 연속적인 데이터 스트림으로 처리된다면 어떨까요? 데이터가 생성되면 저장되기 전에 처리됩니다. 이제 분석에는 모든 데이터가 아니라 들어오는 데이터를 처리하여 지난 1초, 지난 1분 또는 지난 시간에 생성된 데이터도 포함될 수 있습니다.
Hadoop에서 처리된 데이터와 스트림 프로세서에서 처리된 데이터를 결합할 수 있다면 지금 이 순간 생성되는 모든 데이터를 분석할 수 있습니다.
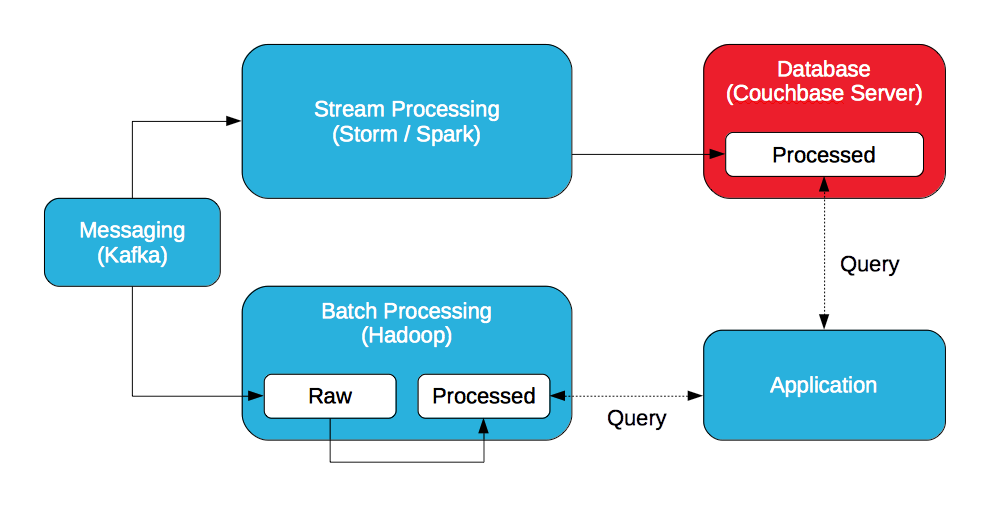
메시징
분산 메시징 시스템(Kafka, JMS 또는 AMQP)은 높은 처리량과 짧은 지연 시간으로 데이터를 수집하는 데 이상적입니다.
스트림 처리(속도 레이어)
분산형 스트림 처리 시스템(Storm, Spark Streaming)은 들어오는 데이터를 실시간으로 분석하는 데 이상적입니다. Storm은 개별 데이터를 처리하는 반면, Spark Streaming은 소규모 데이터 배치를 처리합니다.
Hadoop(배치 레이어)
Hadoop은 원시 데이터 배치를 저장하고 MapReduce/Pig 또는 Spark로 처리합니다.
데이터베이스
분산 데이터베이스는 스트림 프로세서에서 생성된 처리된 데이터를 저장하는 데 이상적입니다. 스트림 프로세서는 원시 데이터나 처리된 데이터를 모두 저장하지 않습니다. 데이터를 저장하지 않습니다. 데이터베이스는 스트림 프로세서의 높은 처리량, 짧은 지연 시간 요구 사항을 충족할 수 있어야 병목 현상이 발생하지 않습니다.
애플리케이션(서빙 레이어)
애플리케이션은 Hadoop과 데이터베이스 모두에서 처리된 데이터를 쿼리하여 결과에 대한 전체 보기를 생성합니다. 애플리케이션은 SQL을 사용하여 Couchbase Server를 쿼리할 수 있습니다( N1QL) 및/또는 조회수및 Hive 또는 Impala/Drill이 포함된 Hadoop.
처리된 데이터, 배치 및 스트리밍을 쿼리하는 것이 아이디어라면 처리된 모든 데이터를 데이터베이스에 저장하여 서버 계층이 되는 것은 어떨까요?
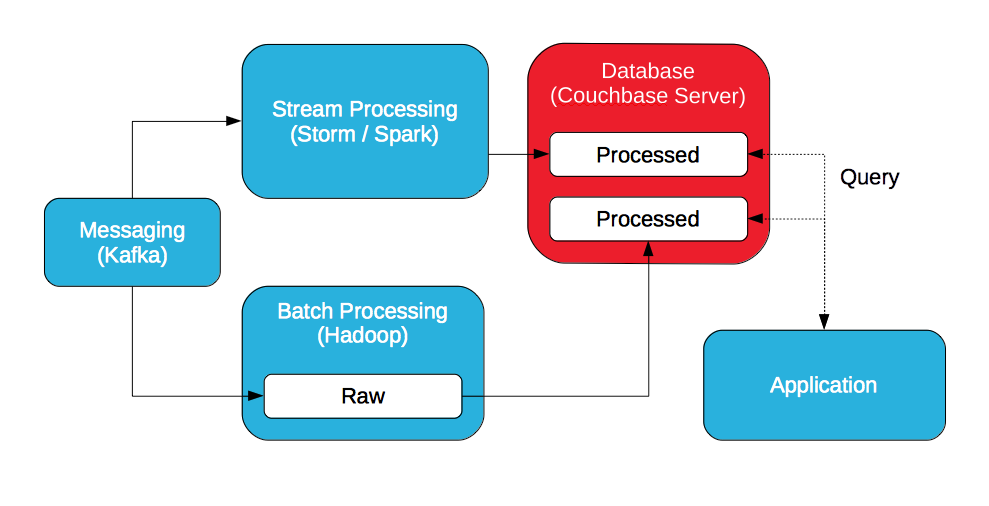
처리된 데이터를 Hadoop에 저장하고 데이터베이스로 내보내거나 처리된 데이터를 데이터베이스에 저장하는 두 가지 옵션이 있습니다. Sqoop용 플러그인을 사용하여 데이터를 Hadoop에서 Couchbase Server로 내보낼 수 있습니다.
Couchbase Server를 사용하면 처리된 데이터를 키/값 API로 액세스하거나 SQL로 쿼리할 수 있습니다( N1QL). 또한 처리된 데이터는 다음을 사용하여 추가 처리 및 쿼리할 수 있습니다. 조회수. 뷰는 데이터를 정렬, 필터링 및 집계하기 위해 맵/축소를 사용하여 구현되지만 증분 업데이트를 활용합니다.
참고
Hadoop이 필요합니다. Hadoop 없이도 Spark를 배포할 수 있지만, Cloudera, Hortonworks 및 MapR의 배포판에는 이 기능이 포함되어 있습니다. Hadoop은 많은 원시 데이터를 저장하고, Spark는 이를 처리하며, 데이터 로컬리티가 중요합니다. 또한 Hadoop은 Spark 그 이상입니다. 맵리듀스와 피그가 포함되어 있습니다. Hive도 포함됩니다. 클라우데라 엔터프라이즈에는 임팔라, 호튼웍스 데이터 플랫폼에는 테즈, 맵알에는 드릴이 포함됩니다.
NoSQL 공급업체가 암시하는 것과는 달리, 저는 여러분을 DataStax로 보고 있지만, Hadoop과 NoSQL 모두 필요합니다. NoSQL 데이터베이스는 Spark와의 통합을 통해 Hadoop을 대체할 수 없습니다.
Shane - 카우치베이스(데이터 수집) 관점에서 바라보는 흥미로운 주제입니다. 다른 측면은 앱 레이어, 즉 스트리밍되는 데이터의 프레젠테이션 및 비즈니스 사용입니다. 저는 지연 시간이 없는 대시보드 및 분석을 원하지만 표시되는 정보의 세분성이 너무 낮아서 좌절하는 많은 고객들과 함께 일해 왔습니다. 제가 고객과 함께 사용한 예는 '주식 시장 시세'입니다. 이 시세는 한 회사의 주식이 어떻게 움직이고 있는지를 거래별로 알려주지만, 시장의 전반적인 성과나 회사의 장기적인 성과에 대해서는 알려주지 않습니다.
블로그 글에 댓글을 다는 것이지 비평하는 것이 아닙니다.
제 경험상, 정보 설계자로서 우리는 매우 신중해야 하며, 데이터를 앱으로 스트리밍하는 것의 비즈니스 장단점을 전달해야 합니다. IMO, 기업은 데이터 인프라의 구성 요소로서 과거 기준선이 필요합니다. 좋은 예측 분석을 위해서는 과거 데이터, 아마도 집계된 데이터 및 스트리밍 데이터가 필요합니다.
감사합니다.
적절한 생각입니다. 그러나 세분성은 구성할 수 있습니다. 예를 들어, 스트림 프로세서는 모든 거래를 평가하여 주식이 아닌 시장이 실시간으로 얼마나 잘 작동하고 있는지 파악할 수 있습니다. 카우치베이스 서버 뷰를 활용하는 애플리케이션은 대시보드를 통해 거의 실시간으로 액세스할 수 있도록 데이터를 추가로 정렬, 필터링 및 집계할 수 있습니다. 산업 또는 부문별로 집계할 수도 있습니다. 하지만 말씀하신 것처럼 과거 데이터와 스트리밍 데이터를 결합하여 전체적인 상황을 파악하는 것이 좋습니다.