Coautor: Sitaram Vemulapalli, Engenheiro Principal, Couchbase R&D.
"A resposta, meu amigo, está escondida em JSON" - Bob Dylan
Há muitos público conjuntos de dados JSON e, em seguida, é incrível Conjuntos de dados JSON. Todas as empresas, inclusive a sua, armazenam muitos dados em JSON, resultado de pesquisas, campanhas e fóruns.
Há muitas maneiras de obter o JSON. Você pode escrever um programa Python para cada relatório, visualizando o que deseja fazer. Ou, você pode usar N1QL (SQL para JSON) para gerar o algoritmo certo para você para analisar dados JSON. Neste artigo, mostramos como usar o N1QL para extrair insights rapidamente. Também usamos dois recursos que serão lançados na próxima versão: Common Table Expression (CTE) e Window Functions.
Objetivo: usar o conjunto de dados JSON público para as pontuações de golfe do US Open para criar uma tabela de classificação simples, ranking, etc.
Três coisas que você fará como parte disso:
- Ingerir os dados no Couchbase facilmente.
- Comece a obter o valor desses dados JSON imediatamente.
- Molde o JSON para gerar relatórios úteis usando novos recursos rapidamente.
Dados de origem: https://github.com/jackschultz/usopen
As consultas desta postagem também estão disponíveis em: https://github.com/keshavmr/usopen-golf-queries
Estrutura de repositório de dados: Este repositório do GitHub https://github.com/jackschultz/usopen contém dados do US Open de golfe de 2018. Para cada buraco, é um documento separado para cada dia.

Cada documento tem essa estrutura. Este é o documento do buraco 1 no dia 1. O Ps arquivado tem a lista de jogadores, cada um com um ID exclusivo.

As estatísticas de jogo de cada jogador são apresentadas a seguir, tacada por tacada. Os jogadores são combinados com as pontuações usando o ID exclusivo do campo para o jogador.

Comece a obter insights:
Antes de começar a consultar, crie um índice primário no bucket.
CREATE PRIMARY INDEX ON usopen;
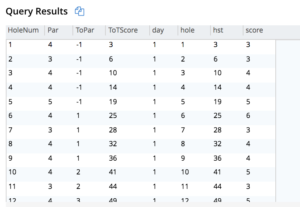
Tarefa 1: Crie um relatório das pontuações dos jogadores por rodada e o total final.
Depois de brincar com o JSON de baixo para cima, chegamos a esta consulta. A explicação está após a consulta.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
WITH d AS ( SELECT pl.hnum AS holedn, pl.ps.Nat AS country, (pl.ps.FN || " " || pl.ps.LN) AS name, pl.ps.ID AS ID, array_length(hps.Sks) AS score, hpl.hole AS `hole`, hpl.day AS `day` FROM ( SELECT meta(usopen).id AS hnum, ps FROM usopen USE keys "holes:1:1" unnest Ps AS ps ) pl INNER JOIN ( SELECT TONUMBER(split(meta(usopen).id, ":") [1]) AS `hole`, TONUMBER(split(meta(usopen).id, ":") [2]) AS `day`, hps FROM usopen unnest Rs AS rs UNNEST rs.Hs AS hs UNNEST hs.HPs AS hps ) hpl ON (pl.ps.ID = hps.ID) ) SELECT d.name, SUM( CASE WHEN d.day = 1 THEN d.score ELSE 0 END ) R1, SUM( CASE WHEN d.day = 2 THEN d.score ELSE 0 END ) R2, SUM( CASE WHEN d.day = 3 THEN d.score ELSE 0 END ) R3, SUM( CASE WHEN d.day = 4 THEN d.score ELSE 0 END ) R4, SUM(d.score) T FROM d GROUP BY d.name ORDER BY d.name |
Resultados tabulares (em formato tabular, do workbench de consulta do Couchbase)
Vamos examinar a consulta bloco por bloco.
Observe a cláusula WITH d. A instrução desvincula o JSON dos dados PER-day-PER-hole-shot-by-shot para valores escalares simples.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
{ "d": { "ID": "37189", "country": "USA", "day": 1, "hole": 10, "holedn": "holes:1:1", "name": "Harold Varner", "score": 6 } } |
Holedn é a chave do documento - número do dia do furo
País é a nacionalidade do jogador
ID é o ID exclusivo do jogador.
O buraco e o dia são óbvios e a pontuação é a pontuação do jogador para aquele buraco.
Na cláusula FROM da instrução SELECT, pl é a lista completa de jogadores retirada do documento para o primeiro dia, primeiro buraco (buracos:1:1).
Rs é o resultado dos jogadores, tacada por tacada, buraco por buraco. Primeiro, aninhamos essa matriz algumas vezes para projetar os detalhes de cada buraco e a pontuação desse buraco, determinada por array_length(hps.Sks).
Quando tivermos a pontuação buraco a buraco, é fácil escrever a consulta final para agregar por jogador e por dia.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
select d.name, sum(case when d.day = 1 then d.score else 0 end) R1, sum(case when d.day = 2 then d.score else 0 end) R2, sum(case when d.day = 3 then d.score else 0 end) R3, sum(case when d.day = 4 then d.score else 0 end) R4, sum(d.score) T from d group by d.name order by d.name |
**A cláusula WITH é o recurso de expressão de tabela comum (CTE) na próxima versão do Mad-Hatter. A maneira antiga de fazer isso no Couchbase 5.5 ou inferior é usar a cláusula LET. Publique a pergunta no fórum do Couchbase se precisar de ajuda aqui).
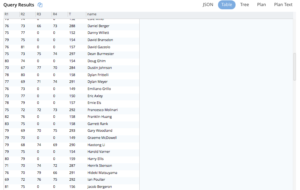
Tarefa 2: Agora, crie a tabela de classificação completa e adicione a tag CORTE informações. Os golfistas que foram cortados não jogarão a terceira ou a quarta rodada. Usamos essas informações para determinar os jogadores que foram cortados.
Consulta 2. Pegue a consulta anterior e nomeie-a como uma tabela comum dx e, em seguida, adicione a seguinte expressão para determinar esse corte.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
( CASE WHEN ( d2.R1 = 0 OR d2.R2 = 0 OR d2.R3 = 0 OR d2.R4 = 0 ) THEN "CUT" ELSE MISSING END ) AS CUT |
Aqui está a consulta completa:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 |
WITH dy AS ( SELECT pl.hnum AS holedn, pl.ps.Nat AS country,(pl.ps.FN || " " || pl.ps.LN) AS name, pl.ps.ID AS ID, array_length(hps.Sks) AS score, hpl.hole AS `hole`, hpl.day AS `day` FROM ( SELECT meta(usopen).id AS hnum, ps FROM usopen USE keys "holes:1:1" unnest Ps AS ps ) pl INNER JOIN ( SELECT TONUMBER(split(meta(usopen).id, ":") [1]) AS `hole`, TONUMBER(split(meta(usopen).id, ":") [2]) AS `day`, hps FROM usopen unnest Rs AS rs unnest rs.Hs AS hs unnest hs.HPs AS hps ) hpl ON (pl.ps.ID = hps.ID) ), dx AS ( SELECT d.name, sum( CASE WHEN d.day = 1 THEN d.score ELSE 0 END ) R1, sum( CASE WHEN d.day = 2 THEN d.score ELSE 0 END ) R2, sum( CASE WHEN d.day = 3 THEN d.score ELSE 0 END ) R3, sum( CASE WHEN d.day = 4 THEN d.score ELSE 0 END ) R4, sum(d.score) T FROM dy AS d GROUP BY d.name ORDER BY d.name ) SELECT d2.name, d2.R1, d2.R2, d2.R3, d2.R4, d2.T,( CASE WHEN ( d2.R1 = 0 OR d2.R2 = 0 OR d2.R3 = 0 OR d2.R4 = 0 ) THEN "CUT" ELSE MISSING END ) AS CUT FROM dx AS d2 ORDER BY CUT ASC, d2.T ASC |
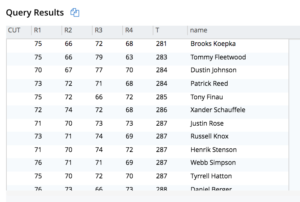
Tarefa 3: Determinar os vencedores.
Precisamos classificar os jogadores com base na pontuação total para determinar quem venceu o torneio. As classificações serão ignoradas se houver empates nas pontuações. Fazendo isso em SQL sem funções de janela é caro. Aqui, escrevemos a consulta usando a função de janela RANK(). As funções de janela são um recurso do N1QL na próxima versão (Mad-Hatter)
Consulta 3:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 |
WITH dy AS ( SELECT pl.hnum AS holedn ,pl.ps.Nat AS country ,(pl.ps.FN || " " || pl.ps.LN) AS name ,pl.ps.ID AS ID ,array_length(hps.Sks) AS score ,hpl.hole AS `hole` ,hpl.day AS `day` FROM ( SELECT meta(usopen).id AS hnum ,ps FROM usopen USE keys "holes:1:1" unnest Ps AS ps ) pl INNER JOIN ( SELECT TONUMBER(split(meta(usopen).id, ":") [1]) AS `hole` ,TONUMBER(split(meta(usopen).id, ":") [2]) AS `day` ,hps FROM usopen unnest Rs AS rs unnest rs.Hs AS hs unnest hs.HPs AS hps ) hpl ON (pl.ps.ID = hps.ID) ) ,dx AS ( SELECT d.name ,sum(CASE WHEN d.day = 1 THEN d.score ELSE 0 END) R1 ,sum(CASE WHEN d.day = 2 THEN d.score ELSE 0 END) R2 ,sum(CASE WHEN d.day = 3 THEN d.score ELSE 0 END) R3 ,sum(CASE WHEN d.day = 4 THEN d.score ELSE 0 END) R4 ,sum(d.score) T FROM dy AS d GROUP BY d.name ORDER BY d.name ) SELECT d2.name ,d2.R1 ,d2.R2 ,d2.R3 ,d2.R4 ,d2.T ,RANK() OVER (ORDER BY d2.T + CUT) AS Rank FROM dx AS d2 LET CUT = ( CASE WHEN ( d2.R1 = 0 OR d2.R2 = 0 OR d2.R3 = 0 OR d2.R4 = 0 ) THEN 1000 ELSE 0 END ) ORDER BY Rank |
Observe que as classificações 4, 8, 9, 10 e 11 estão faltando por causa do empate nas pontuações!
Tarefa 4: Agora, vamos descobrir como cada jogador se saiu após a rodada 1, a rodada 2 e a rodada 3 em comparação com a rodada final. Usando as funções de janela, é muito fácil fazer desaparecer os marshmallows cobertos com chocolate.
Consulta 4: Use a mesma função RANK(), ordenando pela pontuação de cada dia (dia1, dia1+dia2, dia1+dia2+dia3) em vez de apenas a pontuação final.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 |
WITH dy AS ( SELECT pl.hnum AS holedn, pl.ps.Nat AS country,(pl.ps.FN || " " || pl.ps.LN) AS name, pl.ps.ID AS ID, array_length(hps.Sks) AS score, hpl.hole AS `hole`, hpl.day AS `day` FROM ( SELECT meta(usopen).id AS hnum, ps FROM usopen USE keys "holes:1:1" unnest Ps AS ps ) pl INNER JOIN ( SELECT TONUMBER(split(meta(usopen).id, ":") [1]) AS `hole`, TONUMBER(split(meta(usopen).id, ":") [2]) AS `day`, hps FROM usopen unnest Rs AS rs unnest rs.Hs AS hs unnest hs.HPs AS hps ) hpl ON (pl.ps.ID = hps.ID) ), dx AS ( SELECT d.name, sum( CASE WHEN d.day = 1 THEN d.score ELSE 0 END ) R1, sum( CASE WHEN d.day = 2 THEN d.score ELSE 0 END ) R2, sum( CASE WHEN d.day = 3 THEN d.score ELSE 0 END ) R3, sum( CASE WHEN d.day = 4 THEN d.score ELSE 0 END ) R4, sum(d.score) T FROM dy AS d GROUP BY d.name ORDER BY d.name ) SELECT d2.name, d2.R1, d2.R2, d2.R3, d2.R4, d2.T, DENSE_RANK() OVER ( ORDER BY d2.T + CUT ) AS rankMoney, RANK() OVER ( ORDER BY d2.T + CUT ) AS rankFinal, RANK() OVER ( ORDER BY d2.R1 ) AS round1rank, RANK() OVER ( ORDER BY d2.R1 + d2.R2 ) AS round2rank, RANK() OVER ( ORDER BY d2.R1 + d2.R2 + d2.R3 + CUT ) AS round3rank FROM dx AS d2 LET CUT = ( CASE WHEN ( d2.R1 = 0 OR d2.R2 = 0 OR d2.R3 = 0 OR d2.R4 = 0 ) THEN 1000 ELSE 0 END ) ORDER BY rankFinal, round1rank, round2rank, round3rank |
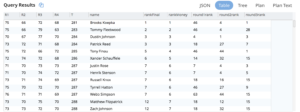
Agora você pode ver como os jogadores subiram ou desceram a cada dia.
Tarefa 5: Crie o scorecard completo para o líder usando as estatísticas básicas de tacada por tacada.
Consulta 5: Brooks Koepka é o vencedor final do US Open. Vamos obter suas pontuações, buraco a buraco, e obter as pontuações cumulativas para ele por rodada. Observe como o agregado simples SUM() e COUNT() funciona como uma função de janela com a cláusula OVER().
|
1 |
SUM(d2.score) OVER (PARTITION BY d2.day ORDER BY d2.hole) hst |
Isso primeiro divide a pontuação por dia e depois por buraco - especificado pela cláusula PARTITION BY, na ordem dos buracos 1-18. Em seguida, o SUM soma as pontuações até o momento.
|
1 |
SUM(d3.score) OVER (ORDER BY d3.day,d3.hole) ToTScore |
Essa função SUM() simplesmente soma a pontuação do dia 1, buraco 1, ao dia 4, buraco 18 - isso é especificado pelo ORDER BY d3.day, d3.hole dentro da cláusula OVER(). O campo ToTScore mostra o total de shorts do torneio de Koepka em cada buraco.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
WITH dy AS ( SELECT pl.hnum AS holedn, pl.ps.Nat AS country,(pl.ps.FN || " " || pl.ps.LN) AS name, pl.ps.ID AS ID, array_length(hps.Sks) AS score, hpl.hole AS `hole`, hpl.day AS `day`, hpl.Par AS Par FROM ( SELECT meta(usopen).id AS hnum, ps FROM usopen USE keys "holes:1:1" unnest Ps AS ps WHERE ps.LN = "Koepka" ) pl INNER JOIN ( SELECT TONUMBER(split(meta(usopen).id, ":") [1]) AS `hole`, TONUMBER(split(meta(usopen).id, ":") [2]) AS `day`, hs.Par, hps FROM usopen unnest Rs AS rs unnest rs.Hs AS hs unnest hs.HPs AS hps ) hpl ON (pl.ps.ID = hps.ID) ), dx AS ( SELECT d.name, d.day, d.score, d.hole, d.Par FROM dy AS d ORDER BY d.name ), dz AS ( SELECT d2.day, d2.hole, d2.score, SUM(d2.score) OVER ( PARTITION BY d2.day ORDER BY d2.hole ) hst, d2.Par, SUM(d2.Par) OVER ( PARTITION BY d2.day ORDER BY d2.hole ) hpr FROM dx AS d2 LET CUT = ( CASE WHEN ( d2.R1 = 0 OR d2.R2 = 0 OR d2.R3 = 0 OR d2.R4 = 0 ) THEN 1000 ELSE 0 END ) ORDER BY d2.day, d2.hole ) SELECT d3.Par, d3.day, d3.hole, d3.hst, d3.score,(d3.hst - d3.hpr) ToPar, sum(d3.score) OVER ( ORDER BY d3.day, d3.hole ) ToTScore, count(1) OVER ( ORDER BY d3.day, d3.hole ) HoleNum FROM dz AS d3 |