O particionamento de índices é um novo recurso disponível no Couchbase Server 5.5.
Confira o Anúncio do Couchbase Server 5.5 Developer Build e Faça o download da versão gratuitamente agora mesmo.
Nesta postagem, abordarei o assunto:
- Por que você pode querer usar o particionamento de índices
- Um exemplo de como fazer isso
- Eliminação de partições
- Algumas advertências para se ter cuidado
Particionamento de índices
Ao desenvolver seu aplicativo, talvez você queira aproveitar a facilidade de dimensionamento do Couchbase Server para fornecer mais recursos à indexação. Com escalonamento multidimensional (MDS)Uma opção é adicionar várias máquinas de última geração ao cluster com recursos de indexação conforme a necessidade.
Para tirar proveito de vários nós com serviços de índice, você teria que criar réplicas de índice. Isso ainda é possível e, se estiver funcionando para você, não vai desaparecer.
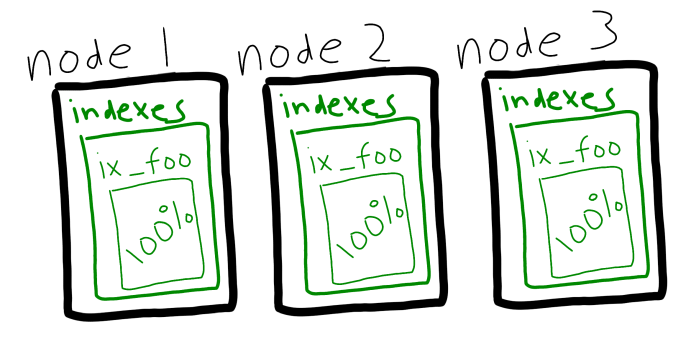
O Couchbase Server 5.5 está introduzindo outra maneira de distribuir a carga do índice: o particionamento do índice. Em vez de replicar um índice, agora você pode dividi-lo entre os nós com hashing.
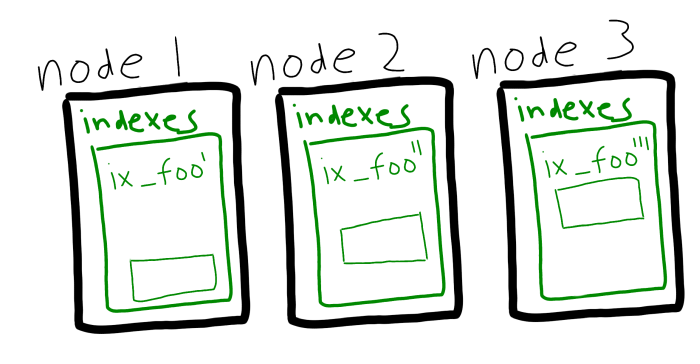
Além disso, você pode usar o particionamento e as réplicas em conjunto. As réplicas de partição de índice serão usadas automaticamente e sem interrupção se um nó ficar inoperante.
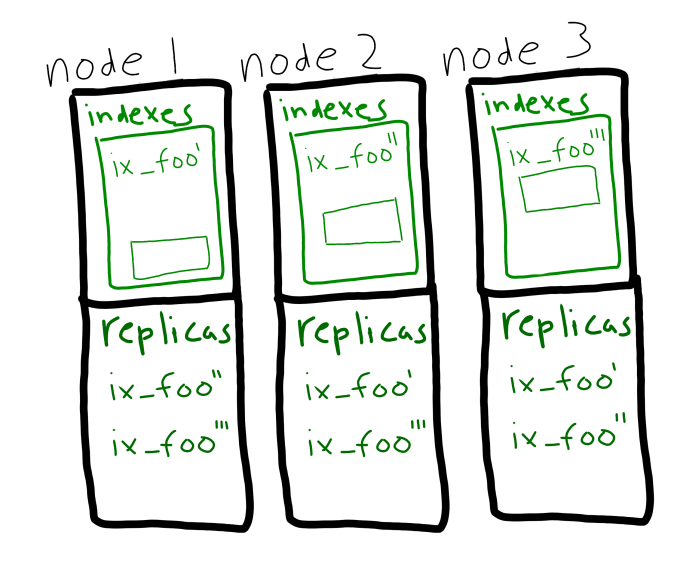
Os principais benefícios do particionamento de índices:
- A carga da varredura de índice agora é equilibrado entre todos os nós de índice. Isso leva a uma distribuição mais uniforme do trabalho e a um melhor desempenho.
- Uma consulta que usa agregação (por exemplo
SUM+GRUPO POR) pode ser funcionar em paralelo em cada partição.
Como usar o particionamento de índices
A sintaxe para criar uma partição de índice é PARTIÇÃO POR HASH(). Por exemplo, se eu quisesse criar um índice composto no bucket "travel-sample" para os campos airline (companhia aérea), flight (voo), source_airport (aeroporto de origem) e destination_airport (aeroporto de destino):
|
1 |
CREATE INDEX ix_route ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(airline); |
Quando você criar esse índice, ele será exibido como "particionado" no Console do Couchbase.

Eliminação de partições
A eliminação de partições é um dos benefícios do uso do particionamento de índices. Esse é um recurso exclusivo do Couchbase no mercado NoSQL.
Digamos que você tenha uma partição no campo companhia aérea, conforme descrito acima. Em seguida, escreva uma consulta que use esse índice e especifique o valor da companhia aérea:
|
1 2 3 4 |
SELECT t.* FROM `travel-sample` t WHERE airline IN ["UA", "AA"] AND source_airport = "SFO" |
Em seguida, o serviço de indexação fará a varredura apenas das partições correspondentes ("UA" e "AA"). Isso resulta em uma resposta de consulta de intervalo mais rápida e na mesma latência de um índice não particionado, independentemente do tamanho do cluster. Falaremos mais sobre isso mais tarde.
Advertências sobre o particionamento de índices
Você deve ter notado que o termo "companhia aérea" foi usado na frase acima CRIAR ÍNDICE comando. Ao usar o particionamento de índice, você deve especificar um (ou mais) campos para fornecer ao hash a ser usado para o particionamento. Esse hash determinará como dividir o índice.
A coisa mais simples que você pode fazer é usar a chave do documento no hash:
|
1 2 |
CREATE INDEX ix_route2 ON `travel-sample` (airline, flight, source_airport, destination_airport) PARTITION BY HASH(META().Id); |
Mas, diferentemente do mecanismo de valor-chave do Couchbase, você pode usar os campos que quiser. Mas é preciso ter em mente que esses campos devem ser considerados imutável. Ou seja, você não deve alterar o valor dos campos. Portanto, se você tiver um campo com um valor que normalmente não muda (muitos usuários do Couchbase criam um campo de "tipo", por exemplo), esse seria um bom candidato para o particionamento.
Se você optar por indexar em um campo "imutável", esteja ciente de que isso também pode causar alguma distorção da partição (usando META().Id minimizará a quantidade de distorção). Se você fizer a partição no campo "type" (tipo), em que 10% dos documentos têm um tipo de "order" (pedido) e 90% dos documentos têm um tipo de "invoice" (fatura), é provável que a partição seja semelhante. O particionamento do índice usa um algoritmo de otimização para equilibrar a RAM, a CPU e o tamanho dos dados durante o rebalanceamento, mas a distorção ainda será uma possibilidade.
Portanto Por que você não usaria META().Id para reduzir a distorção? Lembre-se da seção de eliminação de partições acima. Se as suas consultas se enquadrarem nas mesmas linhas das partições do índice, você estará minimizando as operações de "dispersão e coleta" que precisam verificar todas as partições e poderá reduzir ainda mais a latência.
Mais uma ressalva: O particionamento de índices é um recurso exclusivo da Enterprise Edition.
Resumo
O particionamento de índices permite que você dimensione seus recursos de indexação de forma mais fácil e automática. Se você estiver usando muitas consultas N1QL em seu projeto, isso será muito útil e facilitará muito o seu trabalho.
Se você tiver alguma dúvida sobre particionamento de índice ou qualquer outra coisa relacionada à indexação, consulte a seção Fóruns do Couchbase Server ou o Fóruns N1QL se você tiver dúvidas sobre a criação de índices e consultas. Não se esqueça de Faça o download da versão 5.5 do Couchbase Server hoje mesmo e experimente. Gostaríamos muito de ouvir seus comentários.
Você pode entrar em contato comigo deixando um comentário abaixo ou encontrando-me em Twitter @mgroves.