Como engenheiro de campo, trabalho com clientes e frequentemente os vejo usando Couchbase recursos com uma abordagem de "pensar fora da caixa".
Um desses recursos que vejo sendo usado de forma mais criativa é Índice Secundário Global (GSI) partições. Vamos discutir primeiro o GSI e a consulta e, em seguida, o particionamento para nos atualizarmos.
O que é um índice secundário global?
De acordo com a documentação do Couchbase, um Índice Secundário Global (GSI) apóia as consultas feitas pelo Serviço de consulta em atributos dentro de documentos. Há suporte para filtragem extensiva.
Os índices secundários globais fornecem o seguinte:
-
- Dimensionamento avançado: Os GSIs podem ser atribuídos independentemente a nós selecionados sem que as cargas de trabalho existentes sejam afetadas.
- Desempenho previsível: As operações baseadas em chaves mantêm uma baixa latência previsível, mesmo na presença de um grande número de índices. A manutenção de índices não é competitiva com as operações baseadas em chaves, mesmo quando as cargas de trabalho de mutação de dados são pesadas.
- Consultas de baixa latência: Os GSIs são particionados de forma independente nos nós do Serviço de Índice: Eles não precisam seguir o particionamento de hash dos dados em vBuckets. As consultas que usam GSIs podem atingir tempos de resposta de baixa latência, mesmo quando o cluster é ampliado, pois os GSIs não exigem um amplo fan-out para todos os nós do Data Service.
- Particionamento independente: O serviço de índice oferece independência de partição: Os dados e seus índices podem ter chaves de partição diferentes. Cada índice pode ter sua própria chave de partição, portanto, cada um pode ser particionado de forma independente para corresponder à consulta específica. À medida que surgirem novos requisitos, o aplicativo também poderá criar um novo índice com uma nova chave de partição, sem afetar o desempenho das consultas existentes.
Particionamento GSI
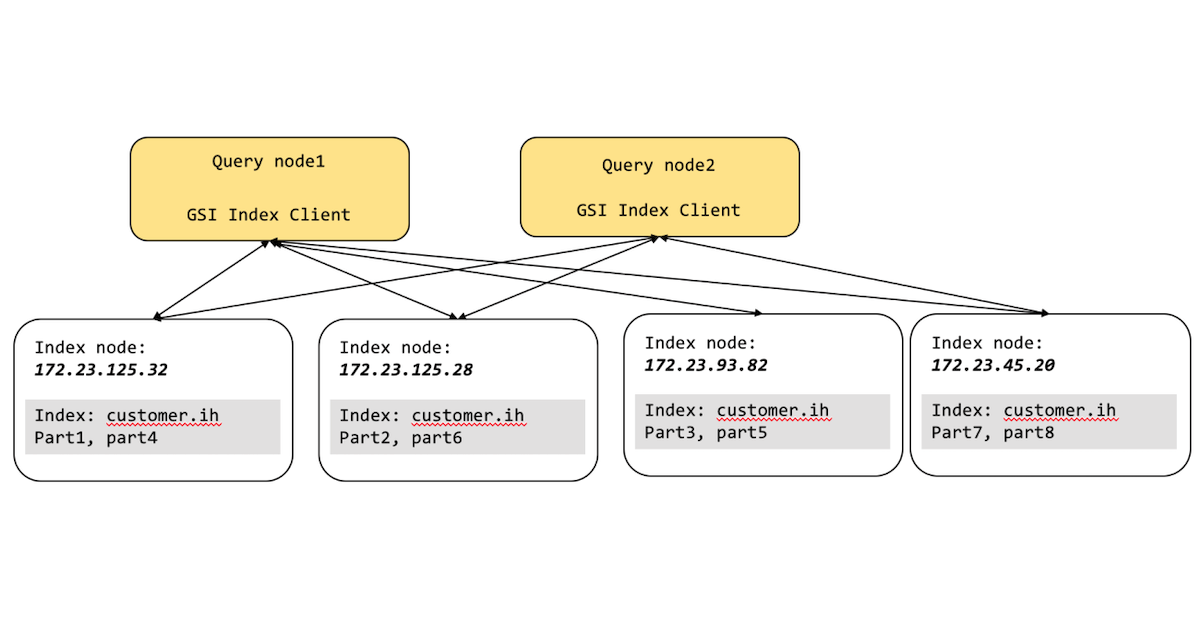
No diagrama acima, a orquestração da consulta para o índice é tratada pelo Query Service e pelo Index Service sem problemas, não apenas para o desenvolvedor do aplicativo, mas também para o administrador do Couchbase.
O particionamento de índice aumenta o desempenho da consulta ao dividir e espalhar um grande índice de documentos em vários nós. Esse recurso está disponível somente no Couchbase Server Enterprise Edition. Os benefícios incluem:
-
- A capacidade de escalonar horizontalmente à medida que o tamanho do índice aumenta.
- Transparência nas consultas, não exigindo nenhuma alteração nas consultas existentes.
- Redução da latência de consulta para consultas grandes e agregadas, já que as partições podem ser verificadas em paralelo.
- Fornecimento de uma consulta de intervalo de baixa latência, permitindo que os índices sejam dimensionados conforme necessário.
Para obter informações detalhadas, consulte Documentação do Couchbase sobre particionamento de índices.
O particionamento de índices oferece muitos recursos que facilitam o gerenciamento de índices, conforme mencionado acima, mas por que não usar o particionamento de índices para mais do que apenas o particionamento?
Mais informações sobre particionamento de índices
Nesta postagem do blog, vamos nos concentrar em casos de uso básicos, mas PARTIÇÃO POR HASH é um recurso muito poderoso que pode ser direcionado e quantificado para o tamanho e o desempenho do índice.
Há muitos recursos excelentes de particionamento de índices para personalizar seus índices a fim de gerenciar o armazenamento, o desempenho ou a escalabilidade.
A maneira mais simples de criar um índice particionado é usar a chave do documento como chave de partição:
|
1 2 3 4 5 6 7 8 |
CREATE INDEX idx_pe1 ON `travel-sample`(country, airline, id) PARTITION BY HASH(META().id); SELECT airline, id FROM `travel-sample` WHERE country="United States" ORDER BY airline; |
Com meta().id como a chave de partição, as chaves de índice serão distribuídas igualmente entre todas as partições. Cada consulta reunirá as chaves de índice qualificadas de todas as partições.
Escolha de chaves de partição para consulta de intervalo
Um aplicativo também tem a opção de escolher a chave de partição que pode minimizar a latência na consulta de intervalo para o índice particionado.
Por exemplo, digamos que uma consulta tenha um predicado de igualdade com base no campo aeroporto de origem e aeroporto de destino. Se o índice também for particionado pelas chaves de índice em aeroporto de origem e aeroporto de destinoentão a consulta só precisará ler uma única partição para o par de aeroporto de origem e aeroporto de destino.
Nesse caso, o aplicativo pode manter uma baixa latência de consulta e, ao mesmo tempo, permitir que o índice particionado seja dimensionado conforme necessário.
As chaves de partição não precisam ser as chaves de índice principais para selecionar as partições qualificadas. Desde que as chaves de índice principais sejam fornecidas junto com as chaves de partição no predicado, a consulta ainda poderá selecionar as partições qualificadas para a varredura de índice. O exemplo a seguir fará a varredura de uma única partição com um determinado par de aeroporto de origem e aeroporto de destino.
Criação de um índice particionado com chaves de partição que correspondem ao predicado de igualdade da consulta:
|
1 2 3 4 5 6 7 |
# Lookup all airlines with non-stop flights from SFO to JFK CREATE INDEX idx_pe2 ON `travel-sample` (sourceairport, destinationairport,stops, airline, id) PARTITION BY HASH (sourceairport, destinationairport); SELECT airline, id FROM `travel-sample` WHERE sourceairport="SFO" AND destinationairport="JFK" AND stops == 0 ORDER BY airline; |
Número de partições
O número de partições de índice é fixado quando o índice é criado.
Por padrão, cada índice terá oito partições. O administrador pode substituir o número de partições em criação de índices tempo.
Colocação de partições
Quando um índice particionado é criado, as partições são delineadas nos nós de índice disponíveis. Durante o posicionamento do novo índice, o indexador assumirá que cada partição tem um tamanho igual e colocará as partições de acordo com a disponibilidade de recursos em cada nó.
Por exemplo, se um nó de indexador tiver mais memória livre disponível do que os outros nós, ele atribuirá mais partições a esse nó de indexador. Se o índice tiver uma réplica, a partição da réplica não será colocada no mesmo nó.
Como alternativa, os usuários podem especificar a lista de nós para restringir o conjunto de nós disponíveis para colocação, usando um comando semelhante ao exemplo a seguir:
Criação de um índice particionado em portas específicas de um nó:
|
1 |
CREATE INDEX idx_pe12 ON `travel-sample`(airline, sourceairport, destinationairport) PARTITION BY KEY(airline) WITH {"nodes":["127.0.0.1:9001", "127.0.0.1:9002"]}; |
Como há casos em que os índices podem ser maiores do que o nó pode armazenar, a intenção original do particionamento de índices era dimensionar índices "grandes" em várias partições, ou seja, nós, em um cluster.
Mas alguns clientes veem as partições GSI de uma maneira diferente.
Um caso que estou vendo com mais frequência é o uso do particionamento como distribuição da carga de trabalho entre os nós. Os índices em si não são grandes, mas a distribuição de todas as partições indexadas em vários nós aproveita a arquitetura do particionamento, em que os índices podem ser verificados em paralelo! Isso distribuirá uniformemente a varredura de índices em todas as partições/nós, em vez de apenas em um único.
Alguns clientes chegam a colocar serviços juntos, como dados, índice e consulta, e não observam degradação do desempenho em comparação com o isolamento de serviços como índice/consulta em nós separados. Uma ressalva a essa abordagem é garantir que haja CPU, memória e espaço em disco suficientes para que todos esses serviços sejam executados juntamente com o próprio sistema operacional.
Os serviços de dados e índices são vinculados à memória e as cotas são definidas por meio das configurações do cluster. O serviço Query não é vinculado à memória, mas usará memória. O administrador do Couchbase precisaria estar ciente da memória disponível e das cotas para os serviços de dados e índice, além de reservar memória livre suficiente para o serviço de consulta e o sistema operacional.
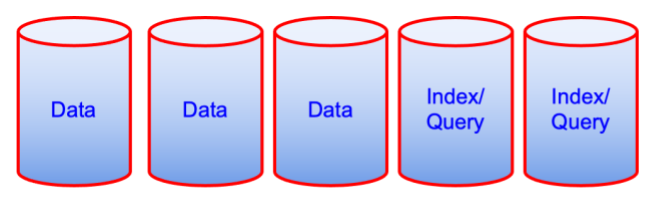
Antes de
Depois de
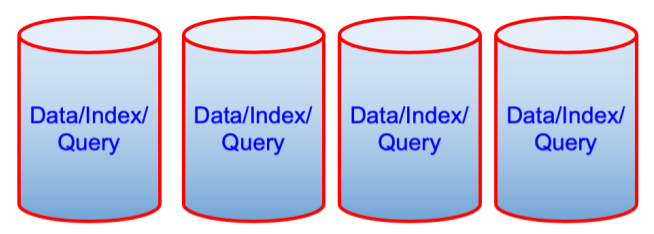
O par de diagramas acima pode parecer contraintuitivo do ponto de vista do desempenho, mas do ponto de vista do custo de propriedade, é uma máquina a menos. Às vezes, esse é um fator determinante.
Quais são as outras estratégias de particionamento? Normalmente, as consultas são orientadas pela latência e pela taxa de transferência, mas também pelos SLAs e pelas particularidades de seu caso de uso. Por exemplo, alguns clientes executam uma consulta uma ou duas vezes por dia para gerar relatórios. Ela precisa ser de alto desempenho? Na verdade, não. Qual é a melhor estratégia para esse tipo de consulta?
Digamos que haja 20 consultas com diferentes ONDE talvez uma consulta para descobrir quantas faturas são geradas em um determinado local por dia. É sensato criar 20 índices diferentes para cada local para a consulta de faturas? E se houver outras consultas que usarão os mesmos dados como um todo (também conhecidos como dados redundantes)? Talvez alguns dos dados sejam específicos de um país, onde 10 dos locais estão no mesmo país.
Se essa fosse uma consulta executada com frequência ou uma parte crítica do aplicativo, como exibições de produtos, um índice dedicado poderia ser apropriado. Mas, nesse caso, talvez um índice grande seja mais eficiente em termos de armazenamento e recursos. Portanto, as partições de índice seriam mais apropriadas.
Segregação de responsabilidade de comando e consulta (CQRS)
Outro uso de partições com melhor desempenho são as cargas de trabalho de gravação pesada, em que as gravações dominam as operações. Um padrão é o CQRS (Segregação de responsabilidade de comando e consulta).
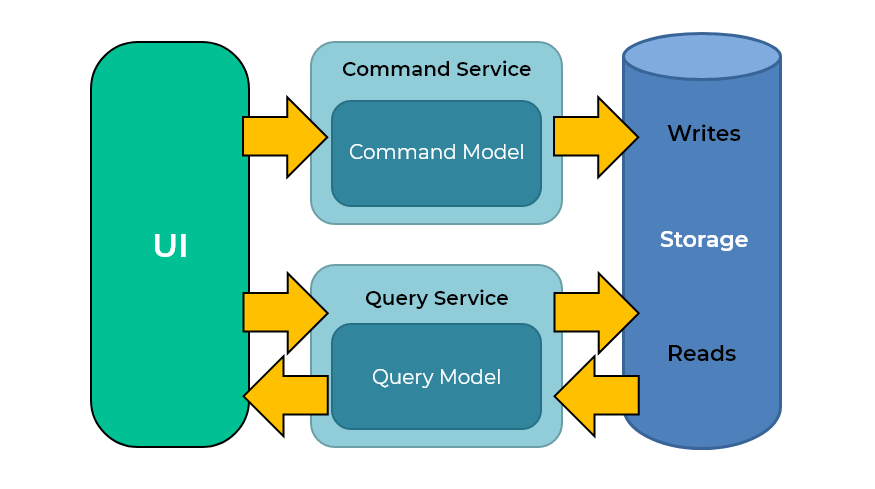
É quando muitos documentos são gravados em um banco de dados e exigem consultas rápidas. Normalmente, são eventos de aplicativos, como interação do usuário com o aplicativo, cliques etc. Esses eventos são gravados em grande volume e consultados com frequência. Com o particionamento do índice, o balanceamento da gravação das chaves do documento no índice não é isolado em um nó, mas distribuído entre os nós do índice. O CQRS é um bom caso de uso para partições de índice.
Conclusão
Cobrimos apenas alguns usos do particionamento do Global Secondary Index. Esse é um dos recursos mais subestimados e subutilizados do GSI, que pode ser ajustado para casos de uso específicos.
Saiba mais sobre Índices secundários globais (GSIs) na documentação do Couchbase.
