Bem-vindos de volta, esta será a última postagem desta série sobre dimensionamento. Nas postagens anteriores, forneci uma visão geral das considerações ao dimensionar um cluster do Couchbase Server, a análise mais detalhada de como os vários recursos/versões afetam esse dimensionamento e forneceu alguns considerações e recomendações específicas de hardware.
Nesta última postagem, discutirei as várias métricas que devem ser usadas para entender as necessidades de dimensionamento de um cluster do Couchbase Server em execução. Também tentarei fornecer orientações sobre limites e alertas, quando apropriado. Pegue um café, pois este será um longo artigo...
Depois de usar as três primeiras postagens para entender qual deve ser o seu dimensionamento inicial e ter entrado em produção, é muito importante continuar a monitorar o cluster e fazer quaisquer alterações de dimensionamento relacionadas a esse monitoramento. Um dos benefícios amplamente aceitos do Couchbase Server é a capacidade de atualizar e expandir sem qualquer interrupção do aplicativo, e isso é muito usado em toda a nossa base de clientes.
Para recapitular rapidamente, os 5 principais fatores que usamos para dimensionar são os mesmos 5 que monitoraremos:
- RAM
- Disco (IO e espaço)
- CPU
- Rede
- Distribuição de dados
Muitas métricas virão diretamente do próprio Couchbase e estão relacionadas apenas ao nosso software. No entanto, também é importante ter um monitoramento extensivo do sistema de uma perspectiva fora do Couchbase (para os 4 primeiros). Lembre-se também de que, embora muitas métricas sejam agregadas em todo o cluster (por bucket) e essa seja geralmente a maneira mais fácil de um ser humano consumi-las, tudo está acontecendo por nó/por bucket e, portanto, é importante monitorar a granularidade de um único nó. A melhor abordagem seria unir tudo isso em um sistema de monitoramento centralizado.
Rastreamento e limites
Cada aplicativo será um pouco diferente e, portanto, os valores e os comportamentos dessas estatísticas variarão. Cabe ao administrador entender quais são importantes para seu aplicativo e em quais níveis ele deve se preocupar.
Você também deve esperar que cada nó tenha basicamente os mesmos valores (+/-) em todas essas métricas e, possivelmente, criar algum alerta se um nó divergir muito.
Embora um limite rígido para a maioria desses itens seja certamente valioso, em muitos casos faz mais sentido rastrear essas métricas ao longo do tempo para que você possa estar preparado com alterações de dimensionamento antes de atingir qualquer ponto crítico. Isso também permite que você obtenha linhas de base precisas para o que deve esperar.
Para cada estatística abaixo, tentei dar uma ideia de quais níveis e/ou limites seriam apropriados para diferentes classes de aplicativos. Não hesite em aproveitar as centenas de anos-homem de experiência acumulados na Couchbase, Inc. para responder a quaisquer perguntas específicas sobre seu aplicativo.
Reagindo às mudanças
Você verá abaixo que não apresento um item de ação específico "faça isso" para cada área. Minha abordagem é a de que é mais importante entender o que cada valor significa e, em seguida, usar a combinação de tudo para decidir se é necessário fazer uma alteração. Se algum dos valores abaixo não estiver dentro dos limites aceitáveis para seu aplicativo, é importante voltar aos cálculos de dimensionamento e fazer os ajustes necessários. Em quase todas as situações em que são necessários mais recursos, a resposta será adicionar um ou mais nós.
Resumo
Primeiro, vamos dar uma olhada na seção "Resumo" dos gráficos de monitoramento do Couchbase:
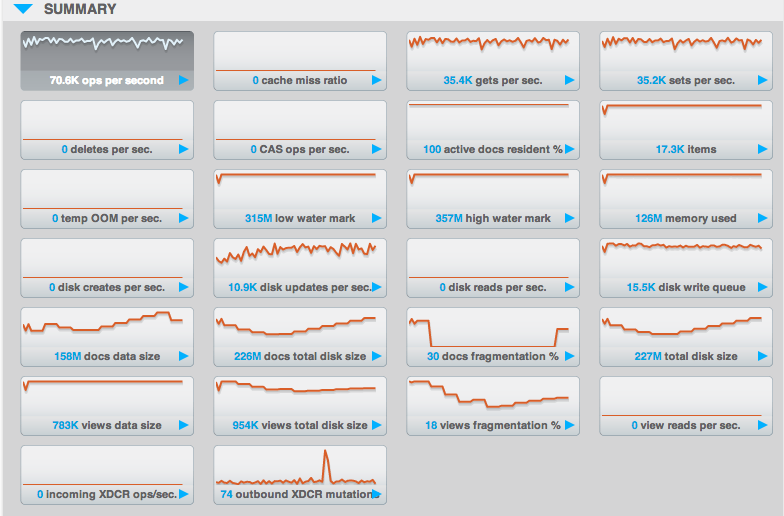
Esse conjunto de estatísticas deve ser seu primeiro ponto de referência para o monitoramento do Couchbase em geral, bem como para o dimensionamento. Ele foi projetado para oferecer uma visão de alto nível em muitas áreas, e usaremos muitas dessas métricas mais adiante na discussão. Você verá que eu apresento algumas estatísticas que não são abordadas diretamente aqui, mas esse é um ótimo lugar para começar, se você estiver procurando um ponto de partida para importar métricas para seus próprios sistemas.
Você verá uma relação proporcional entre a importância de cada fator de dimensionamento e o número de métricas que temos para monitorá-lo.
RAM
Como você já deve ter percebido, a RAM é geralmente um dos fatores mais importantes relacionados ao dimensionamento do Couchbase e é também o que pode mudar mais drasticamente com base na carga de trabalho, no tamanho do conjunto de dados ou em outros fatores.
Há algumas maneiras diferentes de analisar o uso da memória no Couchbase e muitas delas estão inter-relacionadas:
- "itens" é o número de documentos ativos em um determinado bucket (exclui réplicas). É uma indicação indireta da quantidade de memória que está sendo usada e também é um dos principais valores que usamos para nossos cálculos de dimensionamento. No entanto, nem sempre é o mais útil para monitorar de forma contínua.
- "memória utilizada": Isto é o métrica de uso de memória do Couchbase e descreve a quantidade de memória que o software acha que está usando. Esse é o valor que será usado para controlar ejeções e mensagens OOM. (às vezes, você ouvirá nossos engenheiros se referirem a isso como "mem_utilizado"...é a mesma coisa)
- "marca d'água alta" está intimamente relacionado a "memória utilizada" e você pode querer rastreá-los juntos em um gráfico. Esse valor informa em que ponto o nó começará a ejetar dados.
- Você sempre quer "memória utilizada" para ficar abaixo do "marca d'água alta". Alguns aplicativos podem esperar que ele ultrapasse um pouco, mas depois volte a cair à medida que os dados são ejetados, enquanto outros podem esperar que ele nunca atinja o "marca d'água alta".
- Também pode ser importante monitorar esse valor em relação à quantidade real de RAM que está sendo usada pelo processo "memcached" no sistema operacional. Há alguns casos em que esses dois valores divergem e é importante ficar de olho neles. Qualquer divergência acima de 10% justificaria alguma investigação, embora alguns sistemas possam querer permitir porcentagens mais altas antes de tomar qualquer medida.
- Conjunto de trabalho:
- "taxa de perda de cache": Essa é uma porcentagem do número de leituras que estão sendo feitas a partir do disco e não da RAM. Um valor de 0 significa que todas as leituras estão vindo da RAM, enquanto qualquer valor maior que esse indica que algumas leituras estão vindo do disco.
- Para aplicativos que esperam que tudo seja servido a partir da RAM, esse valor deve ser sempre 0.
- Para aplicativos que esperam que esse valor não seja 0, o ideal é que ele seja o mais baixo possível. A maioria das implementações está abaixo de 1%, mas algumas aceitam mais de 10%. Os SSDs em comparação com os discos giratórios têm um grande efeito sobre o que é um valor razoável.
- "docs ativos residentes %": Essa é a porcentagem de itens atualmente armazenados em cache na RAM. 100% significa que todos os itens estão armazenados em cache na RAM, enquanto qualquer valor inferior a esse indica que alguns itens foram ejetados.
- Alguns aplicativos esperam que esse valor seja sempre 100% e alertarão se ele for inferior.
- Outros aplicativos esperam que esse valor seja inferior a 100%, mas o valor real depende de você. Em geral, eu recomendaria não ir abaixo de 30%, a menos que seu aplicativo se sinta confortável com isso.
- "taxa de perda de cache": Essa é uma porcentagem do número de leituras que estão sendo feitas a partir do disco e não da RAM. Um valor de 0 significa que todas as leituras estão vindo da RAM, enquanto qualquer valor maior que esse indica que algumas leituras estão vindo do disco.
- Observe que, embora "docs ativos residentes %" pode ser significativamente menor que 100%, o "taxa de perda de cache" ainda pode estar dentro da faixa aceitável, dependendo do conjunto de trabalho do seu aplicativo.
- "temp OOM por segundo." é uma medida de quantas operações de gravação estão falhando devido a uma situação de "falta de memória" no nó/balde. Isso só ocorrerá se a "memória usada" atingir 90% da cota total do bucket.
- A menos que explicitamente esperado, qualquer coisa diferente de 0 aqui deve ser considerada muito ruim. No entanto, essa situação pode ser evitada com o monitoramento adequado de "memória utilizada", conforme declarado acima.
Além das métricas específicas do Couchbase, você também deve monitorar:
- A RAM livre total disponível no nó. Lembre-se de que o Linux tem algumas formas peculiares de expressar o que é "livre" de fato.
- Alerta se ficar abaixo de 1-2 GB.
- Uso de swap. Embora se espere que o Linux use um pouco de swap em condições normais, qualquer quantidade excessiva de uso de swap ou troca excessiva (veja a saída do "vmstat") seria considerada motivo de preocupação
- O uso da memória do processo beam.smp (erl.exe no Windows). As versões anteriores apresentavam um crescimento potencialmente excessivo nesse processo. Esses problemas foram corrigidos a partir da versão 2.5, mas ainda é uma boa ideia ficar de olho.
- Mais de 4,5 GB seria inadequado aqui.
Disco
Dividido em E/S versus espaço, o dimensionamento geral dos recursos de disco também é extremamente importante. Dependendo da natureza da carga de trabalho, às vezes ele pode ser mais importante do que a RAM.
Considerando o IO primeiro, temos algumas métricas que merecem ser monitoradas:
- "fila de gravação em disco": Isto é o para entender se há E/S de disco suficiente em um nó. Embora existam muitos processos que disputam a E/S do disco (gravação de dados, compactação, visualizações, XDCR, backups locais etc.), usamos a métrica "fila de gravação em disco" como um medidor geral, pois a E/S insuficiente fará com que os itens sejam gravados no disco mais lentamente (independentemente da causa) e deve ser resolvida.
- Qualquer coisa que se aproxime de 1 milhão de itens por cesto e por nó deve ser motivo de preocupação, embora muitos aplicativos esperem que esse valor seja muito menor para sua carga de trabalho. Deve-se esperar que esse valor seja maior durante um rebalanceamento.
- Essa métrica também é importante do ponto de vista de tendências, uma vez que, na maioria dos casos, ela aumentará e diminuirá. Muitos aplicativos aceitam que ela aumente durante o pico de carga de trabalho (ainda assim deve ser <1M), mas é importante que ela diminua durante os períodos de carga mais baixa. Uma fila que aumenta constantemente ao longo do tempo indica que não há E/S de disco suficiente em geral.
- "criações de disco por segundo", "atualizações de disco por segundo", "leituras de disco por segundo": Todas essas são indicações da taxa de leitura/gravação e podem ser usadas em cálculos de dimensionamento futuros
Para o espaço:
- "tamanho total do disco dos documentos" e "visualiza o tamanho total do disco": Mede a quantidade de espaço em disco em uso no diretório de dados e no diretório de visualizações (de acordo com as práticas recomendadas, eles devem estar em partições separadas). Isso é diferente de "tamanho dos dados do disco" ou "tamanho dos dados das visualizações", que medem a quantidade de dados ativos do Couchbase nesses arquivos. A diferença entre essas duas causas "fragmentação de documentos %" e "fragmentação de visualizações %", o que pode acionar a compactação.
- É muito importante garantir espaço em disco disponível suficiente, não apenas para armazenar dados, mas também para a natureza do formato de arquivo somente para anexos, realizar compactação, fazer backups etc. Um nível de alerta adequado seria em torno de 75% de uso de disco, com um alerta crítico em 90%.
Fora do Couchbase, o sistema operacional estará monitorando não apenas o espaço em disco (pense em "df"), mas também a utilização do disco (pense em "iostat").
CPU
Como você viu nas publicações anteriores, a CPU raramente é uma área importante do dimensionamento do Couchbase. Dito isso, ainda é importante monitorar o uso total da CPU de um nó e o uso da CPU do nó memcached e beam.smp/erl.exe processos.
Outro aspecto importante do uso da CPU é a distribuição entre vários núcleos. Embora não esteja necessariamente relacionado ao dimensionamento, um desequilíbrio no uso da CPU pode exigir alguma investigação.
Rede
Embora a largura de banda e a latência da rede tenham um grande efeito sobre o desempenho geral do sistema, é muito raro que isso se desvie dos níveis esperados e cause problemas.
O principal valor que usamos no Couchbase para garantir uma rede saudável está relacionado à fila de replicação entre nós. Embora não esteja presente no "Resumo" acima, ela é conhecida casualmente como a "fila TAP" e é representada por "itens" na seção "TAP QUEUES" da interface do usuário:
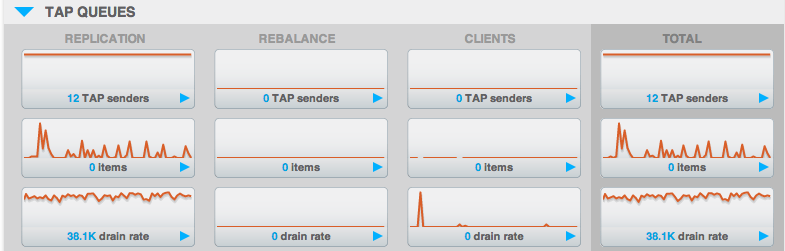
Esse valor quase sempre será 0 e mesmo alguns valores acima de 0 não são motivo de preocupação. Se esse valor subir para mais de 200 por nó e, principalmente, se continuar subindo, pode indicar um problema de rede ou alguma outra coisa no cluster que esteja deixando a replicação mais lenta.
Fora do Couchbase, você também deve ficar de olho no uso da largura de banda da rede entre os nós do Couchbase e entre esses nós e os servidores de aplicativos. Também pode ser importante o número de conexões TCP para os vários nós do Couchbase. portas de rede, principalmente da perspectiva da comunicação entre cliente e servidor.
Distribuição de dados
No final da lista por um bom motivo, não há muito o que monitorar aqui em relação ao dimensionamento. Esse também é o único fator que realmente faz sentido analisar em todo o cluster, em vez de nós individuais.
Se observarmos a seção "recursos do vbucket" da interface do usuário:
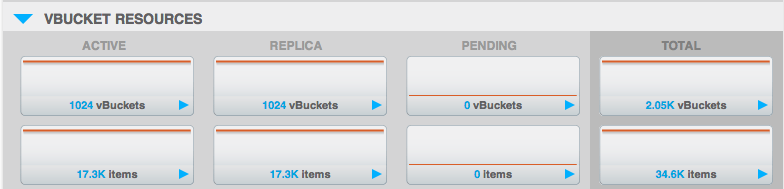
Podemos ver quantos "vBuckets" ativos e quantas réplicas estão presentes para esse bucket. "Ativo vBuckets" deve ser sempre 1024 e "Réplica de vBuckets" deve ser sempre 1024*(número de réplicas). Se não forem, isso significa que há alguns dados indisponíveis ou não replicados e que é necessário agir imediatamente. Isso geralmente acontece após uma falha/failover e exigirá um rebalanceamento para voltar ao normal.
A recomendação geral de sempre ter pelo menos 3 nós no cluster também é válida.
XDCR
Se você estiver usando o XDCR com o Couchbase, a métrica mais importante a ser observada é a fila de mutação do XDCR - "mutações XDCR de saída". Essa é uma indicação de quantos itens estão esperando para serem replicados para os buckets que estão atuando como destinos desse. Assim como a fila de gravação em disco, espera-se que ela cresça e diminua com a carga, mas é importante garantir que ela se aproxime de zero ao longo do tempo e não aumente continuamente cada vez mais.
Virtualização/nuvem
Sem exceções, a discussão acima se aplica igualmente a todos os ambientes em hardware físico, máquinas virtuais e implementações na nuvem. Os valores reais podem variar e, certamente, seus limites e linhas de base esperadas também serão diferentes.
O principal acréscimo a esse quebra-cabeça para ambientes virtualizados e em nuvem é o impacto dos sistemas e hipervisores subjacentes. Forneci algumas diretrizes específicas de implementação na postagem anterior desta série, portanto não vou recapitular aqui. Em termos de monitoramento, todos os mesmos "fora do Couchbase" se aplicam ao sistema subjacente.
Uma interseção interessante entre os dois trata de "tempo roubado".
Conclusão
Para reunir tudo isso em um só lugar, reuni todas essas métricas em um só lugar. Nem todas podem ser aplicáveis ao seu ambiente, mas todas "podem" ser e devem ser compreendidas para seu aplicativo:
| Métricas no Couchbase: | Externo ao Couchbase | |
|---|---|---|
| RAM: |
|
|
| IO de disco: |
|
|
| Espaço em disco: |
|
|
| CPU: |
|
|
| Rede: |
|
|
| Distribuição de dados: |
|
|
| XDCR: |
|
Obrigado por me acompanhar nessa jornada, espero que tenha sido útil. Não hesite em entrar em contato diretamente comigo ou com a equipe do Couchbase se tiver alguma dúvida ou preocupação ou se quiser uma atenção específica para o seu ambiente.
Olá, obrigado por esses artigos. Tenho uma pergunta que não consigo descobrir se é possível.
Considerando os servidores 1, 2 e 3, posso ter instâncias do Couchbase A1, B1, C1 em
Servidor 1; A2, B2, C2 no Servidor 2 e A3, B3 e C3 no Servidor 3, de modo que
A1, A2, A3 formam um cluster, B1, B2 e B3 formam um cluster, etc.?
Isso seria necessário para fins de produção.
Obrigado!
Olá, Renault, peço desculpas pela demora em responder a você. Não há nenhum motivo técnico para que isso seja um problema, mas isso iria contra nossas práticas recomendadas gerais de manter essas cargas de trabalho isoladas. Isso também criaria uma grande tarefa administrativa para você lembrar que há 3 nós em cada servidor físico que fazem parte de 3 clusters diferentes e precisam ser gerenciados/rebalanceados separadamente.
[...] a terceira entrada desta série aborda diferentes opções de hardware e infraestrutura. Por fim, a quarta entrada analisa as métricas que você pode monitorar dentro e fora do Cocuhbase para entender [...]