O Couchbase é o principal banco de dados de documentos NoSQL do mundo. Ele oferece desempenho, flexibilidade e escalabilidade inigualáveis na borda, no local e na nuvem. O Spark é um dos ambientes de computação em memória mais populares. As duas plataformas podem ser combinadas para executar funções incrivelmente rápidas de consulta, engenharia de dados, ciência de dados e aprendizado de máquina.
Neste QuickStart, eu o guiarei pelas etapas simples para configurar o Couchbase com o Databricks* e executar consultas de dados do Couchbase e consultas SQL do Spark.
*Observação: as etapas deste QuickStart foram validadas com o tempo de execução do Databricks 10.4 LTS.
Configuração
Pré-requisitos
Para concluir este Início Rápido, você precisará do seguinte:
-
- Um cluster do Couchbase e amostra de viagem bucket acessível ao cluster do Databricks. Usei um cluster do Couchbase em uma máquina AWS EC2.
- A Conta da Databricks - Estão disponíveis avaliações gratuitas que exigem uma conta do AWS, Azure ou GCP.
- O Couchbase conector de faísca biblioteca, versão 3.2.2 - disponível via Maven:
- Na tela de criação do cluster, na seção Bibliotecas guia. Selecione Instalar new e procure o pacote no Maven Central. Veja o exemplo abaixo:
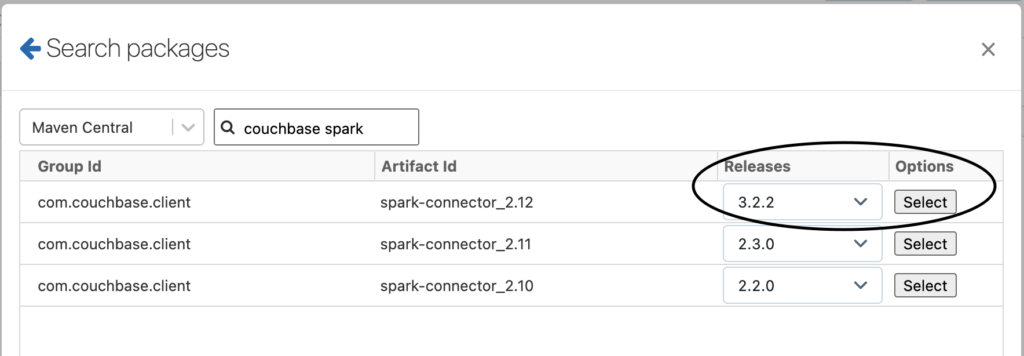
-
- O Instalar a configuração da biblioteca será configurada como no exemplo abaixo:
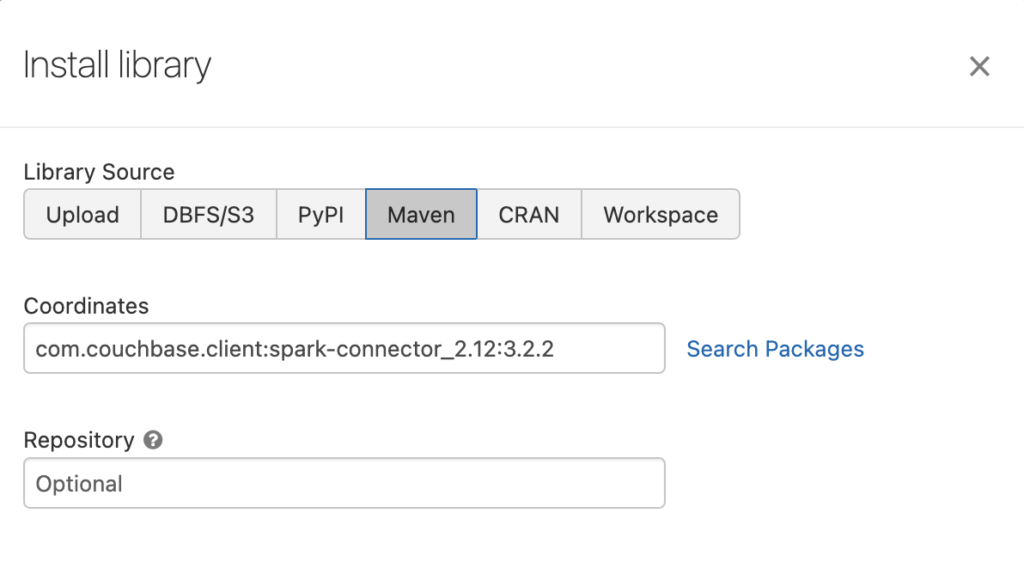
Configuração
Antes de começarmos, precisamos configurar os seguintes parâmetros no cluster do Databricks opções avançadas Configuração do Spark. Isso pode ser feito ao criar um cluster (veja a impressão de tela abaixo):
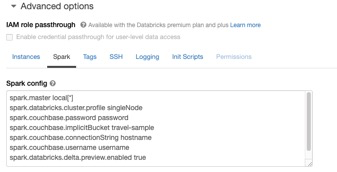
Você pode copiar e colar as configurações abaixo e substituir os parâmetros em <> com os valores de seu cluster do Couchbase na variável opções avançadas Configuração do Spark:
|
1 2 3 4 5 |
spark.couchbase.password <password> spark.couchbase.implicitBucket <travel-sample> spark.couchbase.connectionString <hostname> spark.couchbase.username <username> spark.databricks.delta.preview.enabled true |
Primeiro, vamos executar as importações necessárias. Copie o código de amostra abaixo em um notebook em branco anexado a um cluster com a configuração acima
|
1 2 3 4 5 6 7 8 9 10 11 |
import com.couchbase.spark._ import org.apache.spark.sql._ import com.couchbase.client.scala.json.JsonObject import com.couchbase.spark.kv.Get import com.couchbase.client.scala.kv.MutateInSpec import com.couchbase.spark.kv.MutateIn import com.couchbase.client.scala.kv.LookupInSpec import com.couchbase.spark.kv.LookupIn import com.couchbase.client.scala.query.QueryOptions import com.couchbase.spark.query.QueryOptions import com.couchbase.client.scala.analytics.AnalyticsOptions |
Agora, vamos obter alguns documentos por chaves do Couchbase amostra de viagem usando o código abaixo:
|
1 2 3 4 |
sc .couchbaseGet(Seq(Get("airline_10"), Get("airline_10642"))) .collect() .foreach(result => println(result.contentAs[JsonObject])) |
Ótimo, nos conectamos ao cluster e retornamos nosso primeiro RDD (Resilient Distributed Dataset).
Podemos consultar os dados usando o SQL++ (linguagem de consulta do Couchbase baseada em SQL). Execute o código abaixo como um exemplo:
|
1 2 3 4 |
sc .couchbaseQuery[JsonObject]("select country, count(*) as count from `travel-sample` where type = 'airport' group by country order by count desc") .collect() .foreach(println) |
Consulta ao serviço de análise
O Couchbase também oferece um serviço de análise para análise operacional e análise em tempo real. Abaixo está um exemplo de uma consulta de análise:
|
1 2 |
val query = "SELECT ht.city,ht.state,COUNT(*) AS num_hotels FROM `travel-sample`.inventory.hotel ht GROUP BY ht.city,ht.state HAVING COUNT(*) > 30" sc.couchbaseAnalyticsQuery[JsonObject](query).collect().foreach(println) |
Agora, vamos ver um pouco de Spark SQL
Use o código abaixo para criar exibições temporárias para companhias aéreas e aeroportos DataFrames:
|
1 2 3 4 5 6 7 8 9 |
val airlines = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airline'") .load() airlines.createOrReplaceTempView("airlines") val airports = spark.read.format("couchbase.query") .option(QueryOptions.Filter, "type = 'airport'") .load() airports.createOrReplaceTempView("airports") |
Agora podemos executar consultas Spark SQL nas exibições, por exemplo:
Obter as companhias aéreas em ordem crescente:
|
1 |
%sql select * from airlines order by name asc limit 10 |
Obtenha as companhias aéreas agrupadas por país:
|
1 |
%sql select country, count(*) from airlines group by country; |
E, por fim, vamos visualizar os aeroportos por país usando um UDF (Função definida pelo usuário) junto com o recurso de mapeamento do Databricks. Crie a UDF usando o SQL++ abaixo:
|
1 2 3 4 5 6 7 8 |
val countrymap = (s: String) => { s match { case "France" => "FRA" case "United States" => "USA" case "United Kingdom" => "GBR" } } spark.udf.register("countrymap", countrymap) |
Selecione as contagens de aeroportos por país e visualize os resultados:
|
1 |
%sql select countrymap(country), count(*) from airports group by country; |
Após concluir este Início Rápido, seu resultado deverá ser semelhante à visualização abaixo:
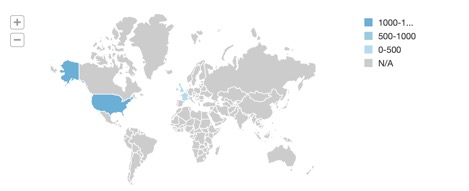
O que realizamos
Neste QuickStart, descrevi como utilizar o Couchbase spark-connector com o Databricks para criar RDDs, executar consultas SQL do Couchbase e do Spark, criar um UDF e utilizar o recurso de mapeamento do Databricks para visualizar os resultados. Essas etapas demonstram o processo usado para acessar, analisar e visualizar dados em um cluster do Couchbase a partir de uma interface de notebook do Databricks.
Próximas etapas
Saiba mais sobre Couchbase Capella:
-
- Faça um test drive com a Capella inscrevendo-se para um teste gratuito de 30 dias.
- Conecte seu cluster de teste ao Playground ou conecte um projeto para testá-lo por si mesmo.
- Visite o Portal do desenvolvedor do Couchbase que toneladas de tutoriais/guias de início rápido e caminhos de aprendizagem para ajudá-lo a começar!
- Consulte a documentação para saber mais sobre os SDKs do Couchbase.
Obrigado por ler esta postagem! Se tiver alguma dúvida ou comentário, entre em contato conosco no Couchbase Fóruns!