No Couchbase, os dados são sempre particionados usando o hash consistente da chave do documento em vbukets que são armazenados nos nós de dados. Couchbase Índice Secundário Global (GSI) abstrai as operações de indexação e é executado como um serviço distinto dentro da plataforma de dados do Couchbase. Quando um único índice pode abranger um tipo inteiro de documentos, tudo está bem. Porém, há casos em que você deseja particionar um índice.
- Capacidade: Você deseja aumentar a capacidade porque um único nó não é capaz de manter um índice grande
- Possibilidade de consulta: Você deseja evitar reescrever a consulta para trabalhar com o particionamento manual do índice usando um índice parcial.
- Desempenho: O índice único não consegue atender ao SLA
Para resolver isso, o Couchbase 5.5 introduz o particionamento automático de hash do índice. Você está acostumado a ter dados de bucket com hash em vários nós. O particionamento do índice permite que você faça hash do índice em vários nós também. Há uma boa simetria.
Criar o índice é fácil. Basta adicionar uma cláusula PARTITION BY à definição do índice CREATE.
|
1 2 3 4 5 |
CRIAR ÍNDICE ih ON customer(state, nome, zip, status) PARTIÇÃO BY HASH(estado) ONDE tipo = "cx" COM {"num_partition":8} |
Isso como os seguintes metadados em system:indexes. Observe a nova partição de campo com a expressão de hash. O HASH(state) é a base sobre a qual o índice logicamente denominado cliente.ih é dividido em um número de partições de índice físico. Por padrão, o número de partições de índice é 16 e pode ser alterado com a especificação do parâmetro num_partition. No exemplo acima, criamos 8 partições para o índice cliente.ih.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
selecionar * de sistema:índices onde keypace_id = "cliente" e nome = "ih" ; { "indexes" (índices): { "condição": "(`type` = \"cx\")", "datastore_id": "http://127.0.0.1:8091", "id": "b3ce745f84256319", "index_key": [ "`state`", "`name`", "`zip`", "`status`" ], "keyspace_id": "cliente", "name" (nome): "ih", "namespace_id": "default", "partição": "HASH(`state`)", "estado": "on-line", "usando": "gsi" } } |
Agora, emita a seguinte consulta. Você não precisa de um predicado adicional sobre a chave de hash para que a consulta use o índice. A varredura do índice simplesmente varre todas as partições do índice como parte da varredura do índice.
|
1 2 3 4 5 6 7 |
SELECIONAR * DE cliente ONDE tipo = "cx" e nome = "acme" e zíper = "94051"; |
Entretanto, se você tiver um predicado de igualdade na chave de hash, a varredura de índice detectará a partição de índice correta com o intervalo correto de dados e removerá o restante dos nós de índice da varredura de índice. Isso torna a varredura de índice muito eficiente.
|
1 2 3 4 5 6 7 8 |
SELECIONAR * DE cliente ONDE tipo = "cx" e nome = "acme" e zíper = "94051" e estado = "CA"; |
Agora, vamos ver como esse índice o ajuda com os três aspectos que mencionamos anteriormente: Capacidade, capacidade de consulta e desempenho.
Capacidade
A consulta cliente.ih será particionado em um número especificado de partições, com cada partição armazenada em um dos nós de indexação no cluster. O indexador usa um algoritmo de otimização estocástica para determinar como distribuir as partições no conjunto de nós do indexador, com base no recurso livre disponível em cada nó. Como alternativa, para restringir o índice a um conjunto específico de nós, use o parâmetro nodes. Esse índice criará oito partições de índice e armazenará quatro em cada um dos quatro nós de índice especificados.
|
1 2 3 4 5 6 |
CRIAR ÍNDICE ih ON customer(state, nome, zip, status) PARTIÇÃO POR HASH(estado) ONDE tipo = "cx" COM {"num_partition":8, "nós":["172.23.125.32:9001", "172.23.125.28:9001", "172.23.93.82:9001","172.23.45.20:9001" ]} |
Portanto, com esse índice particionado de hash, um índice lógico (cliente.ih) será particionado em várias partições de índice físico (neste caso, 8 partições) e dará à consulta a ilusão de um único índice.
Como esse índice usa vários nós físicos, ele terá mais recursos de disco, memória e CPU disponíveis. O aumento do armazenamento nesses nós possibilita a criação de índices maiores.
Você escreve suas consultas, como de costume, exigindo predicados apenas na cláusula WHERE (type = "cx") e, pelo menos, em uma das principais chaves de índice (por exemplo, name).
Capacidade de consulta
Limitações na indexação do Couchbase 5.0:
Até o Couchbase 5.0, você podia particionar manualmente o índice como abaixo. Você tinha que particioná-los manualmente usando a cláusula WHERE no CREATE INDEX. Considere os seguintes índices, um por estado. Ao usar o parâmetro node, você pode colocá-los em nós de índice específicos ou o índice tentará se espalhar automaticamente dentro dos nós de índice.
|
1 2 3 4 5 6 |
CRIAR ÍNDICE i1 ON cliente(name, zip, status) ONDE estado = "CA"; CRIAR ÍNDICE i2 ON cliente(name, zip, status) ONDE estado = "NV"; CRIAR ÍNDICE i3 ON cliente(name, zip, status) ONDE estado = "OU"; CRIAR ÍNDICE i4 ON cliente(name, zip, status) ONDE estado = "WA"; |
Para uma consulta simples com o predicado equalify no estado, tudo funciona bem.
|
1 2 3 4 5 |
SELECIONAR * DE cliente ONDE estado = "CA" e nome = "acme" e zíper = "94051"; |
Há dois problemas com esse particionamento manual.
- Considere o seguinte com um predicado ligeiramente complexo sobre o estado. Como o predicado (state IN ["CA", "OR"]) não é um subconjunto de nenhuma das cláusulas WHERE do índice, nenhum dos índices pode ser usado para a consulta abaixo.
|
1 2 3 4 5 6 |
SELECIONAR * DE cliente ONDE estado IN ["CA", "OU"] e nome = ACME; SELECIONAR * DE cliente ONDE estado > "CA" e nome = ACME; |
2. Se você obtiver dados em um novo estado, deverá estar ciente disso e criar o índice com antecedência.
|
1 2 3 |
SELECIONAR * DE cliente ONDE estado = "CO" e nome = ACME |
Se o campo for um campo numérico, você poderá usar a função MOD().
|
1 2 3 4 5 6 |
CRIAR ÍNDICE ix1 ON cliente(name, zip, status) ONDE (MOD(cxid) % 4 = 0); CRIAR ÍNDICE ix2 ON cliente(name, zip, status) ONDE (MOD(cxid) % 4 = 1); CRIAR ÍNDICE ix3 ON cliente(name, zip, status) ONDE (MOD(cxid) % 4 = 2); CRIAR ÍNDICE ix4 ON cliente(name, zip, status) ONDE (MOD(cxid) % 4 = 3); |
Mesmo com esse trabalho, cada bloco de consulta só pode usar um índice e exige que as consultas sejam escritas cuidadosamente para corresponder a um dos predicados na cláusula WHERE.
Solução:
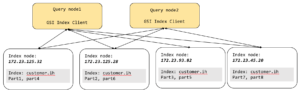
Como você pode ver na figura acima, a interação entre a consulta e o índice passa pelo cliente GSI que fica dentro de cada nó de consulta. Cada cliente GSI dá a ilusão de um único índice lógico (cliente.ih) em cima de oito partições de índice físico.
O cliente GSI recebe todas as solicitações de varredura do índice e, usando o predicado, tenta identificar quais partições do índice têm os dados necessários para a consulta. Esse é o processo de poda de partição (também conhecido como eliminação de partição). Para o esquema de particionamento baseado em hash, os predicados de cláusula de igualdade e IN obtêm o benefício da poda de partição. Todas as outras expressões usam o método de coleta dispersa. Após a eliminação lógica, o cliente GSI envia a solicitação para os nós restantes, obtém o resultado, mescla o resultado e envia o resultado de volta para a consulta. A grande vantagem disso é que as consultas podem ser escritas sem se preocupar com a expressão de particionamento manual.
A consulta de exemplo abaixo nem sequer tem um predicado sobre a chave de hash, estado. A consulta abaixo não obtém o benefício da eliminação da partição. Portanto, o cliente GSI emite uma varredura para cada partição de índice em paralelo e, em seguida, mescla o resultado de cada uma das varreduras de índice. A grande vantagem disso é que as consultas podem ser escritas sem se preocupar com a expressão de particionamento manual para corresponder à expressão de índice parcial e ainda usar a capacidade total dos recursos do cluster.
|
1 2 3 4 5 6 7 8 9 10 11 |
CRIAR ÍNDICE ih1 ON cliente(name, zip, status) PARTIÇÃO POR HASH(estado) ONDE tipo = "cx" COM {"num_partition":8} SELECIONAR * DE cliente ONDE tipo = "cx" e nome = "acme" e zíper = "94051"; |
O predicado adicional sobre a chave de hash (estado = "CA") na consulta abaixo se beneficiará da poda de partição. No processamento de consultas, para consultas simples com predicados de igualdade na chave de hash, você obtém uma distribuição uniforme da carga de trabalho nessas várias partições do índice. Para consultas complexas, incluindo o agrupamento e a agregação que discutimos acima, as varreduras e as agregações parciais são feitas em paralelo, melhorando a latência da consulta.
|
1 2 3 4 5 6 7 8 |
SELECIONAR * DE cliente ONDE tipo = "cx" e nome = "acme" e zíper = "94051" e estado = "CA"; |
Você pode criar índices fazendo hashing em uma ou mais chaves, sendo que cada uma delas pode ser uma expressão. Aqui estão alguns exemplos.
|
1 2 3 4 5 6 7 8 9 |
CRIAR ÍNDICE idx1 ON cliente(nome) PARTIÇÃO POR HASH(META().id); CRIAR ÍNDICE idx2 ON cliente(nome) PARTIÇÃO POR HASH(nome, zip); CRIAR ÍNDICE idx3 ON cliente(nome) PARTIÇÃO POR HASH(SUBSTR(nome, 5, 10)); CRIAR ÍNDICE idx3 ON cliente(nome) PARTIÇÃO POR HASH(SUBSTR(META().id, POSIÇÃO(META().id, "::")+2), zip) |
Desempenho
Para a maioria dos recursos de banco de dados, o desempenho é tudo. Sem um ótimo desempenho, comprovado por bons benchmarks, os recursos são simplesmente diagramas de sintaxe bonitos!
O particionamento de índices proporciona um melhor desempenho de duas maneiras.
- Dimensionamento. As partições são distribuídas em vários nós, aumentando a disponibilidade da CPU e da memória para a varredura de índice.
- Varredura paralela. Predicado correto que fornece às consultas o benefício da poda de partição. Mesmo após o processo de poda, as varreduras de todos os índices são feitas em paralelo.
- Agrupamento e agregação paralelos. O artigo da DZone Entendendo o agrupamento e a agregação de índices nas consultas N1QL do Couchbase explica o aprimoramento do desempenho principal do agrupamento e da agregação usando índices.
- O paralelismo da varredura paralela do índice (e agrupamento, agregação) é determinado pelo parâmetro max_parallelism parâmetro. Esse parâmetro pode ser definido por nó de consulta e/ou por solicitação de consulta.
Considere o índice e a consulta a seguir:
|
1 2 3 4 5 6 7 8 9 10 |
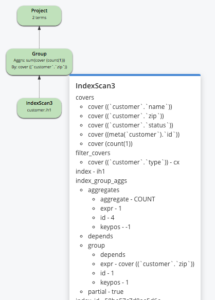
CRIAR ÍNDICE ih1 ON cliente(name, zip, status) PARTIÇÃO POR HASH(estado) ONDE tipo = "cx" COM {"num_partition":8} selecionar zip, contagem(1) contagem de zíperes de cliente onde tipo = "cx" e nome é não ausente grupo por zip; |
O índice é particionado por HASH(state), mas o predicado state está ausente da consulta. Para essa consulta, não podemos fazer a poda de partição ou criar grupos em varreduras individuais das partições do índice. Portanto, ela precisará de uma fase de mesclagem após a agregação parcial com a consulta (não mostrada na explicação). Lembre-se de que essas agregações parciais acontecem em paralelo e, portanto, reduzem a latência da consulta.
Considere o índice e a consulta a seguir:
|
1 2 3 4 5 |
CRIAR ÍNDICE ih2 ON customer(state, cidade, zip, status) PARTIÇÃO POR HASH(zip) ONDE tipo = "cx" COM {"num_partition":8} |
Exemplo a:
|
1 2 3 4 5 6 |
selecionar Estado, contagem(1) contagem de zíperes de cliente onde estado é não ausente grupo por Estado, cidade, zip; |
No exemplo acima, o group by está nas chaves principais (state, city, zip) do índice e a chave hash (zip) faz parte da cláusula group by. Isso ajudará a consulta a fazer a varredura do índice e simplesmente criará os grupos necessários.
Exemplo b:
|
1 2 3 4 5 6 7 8 |
selecionar zip, contagem(1) contagem de zíperes de cliente onde tipo = "cx" e cidade = "São Francisco" e estado = "CA" grupo por zip; |
No exemplo acima, o group by está na terceira chave (zip) do índice e a chave hash (zip) faz parte da cláusula group by. Na cláusula de predicado (cláusula WHERE), há um único predicado de igualdade nas principais chaves de índice antes da chave zip (estado e cidade). Portanto, incluímos implicitamente as chaves (state, city) no group by sem afetar o resultado da consulta. Isso ajudará a consulta a fazer a varredura do índice e simplesmente criará os grupos necessários.
Exemplo c:
|
1 2 3 4 5 6 7 8 |
selecionar zip, contagem(1) contagem de zíperes de cliente onde tipo = "cx" e cidade como "San%" e estado = "CA" grupo por zip; |
No exemplo acima, o group by está na terceira chave (zip) do índice e a chave hash (zip) faz parte da cláusula group by. Na cláusula de predicado (cláusula WHERE), há um predicado de intervalo na cidade. A chave de índice (city) está antes da chave de hash (zip). Portanto, criamos agregados parciais como parte da varredura do índice e, em seguida, a consulta mesclará esses agregados parciais para criar o conjunto de resultados final.
Resumo:
A partição de índice oferece maior capacidade para o seu índice, melhor capacidade de consulta e maior desempenho para suas consultas. Ao explorar a arquitetura de scale-out do Couchbase, os índices melhoram a capacidade, a capacidade de consulta, o desempenho e o TCO.
Referência:
- Documentação do Couchbase: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html
- Documentação do N1QL do Couchbase: https://developer.couchbase.com/documentation/server/5.5/indexes/gsi-for-n1ql.html#
Caro Keshav, obrigado por sempre fornecer ótimos artigos.
Algumas perguntas: se usarmos "num_partition":8 ao criar um índice de partição por hash, isso significa que precisamos ter 8 nós de indexador presentes no cluster? ou esse # pode ser mutuamente exclusivo e não há correlação com isso e apenas correlação com a configuração max_parallelism no admin?
Além disso, você pode ajudar a verificar se o aumento de "Servicers" nas configurações de administração pode fazer alguma diferença no desempenho da consulta?
Obrigado pela ajuda
Cada nó pode ter várias partições de um índice. Você não precisa ter 8 nós de índice para ter um índice com 8 partições.
O parâmetro servicers restringe o número máximo de consultas simultâneas em um nó de consulta. Ele só melhorará o desempenho (taxa de transferência) se você tiver CPUs restantes e aumentar o número de consultas simultâneas. Ele não melhora o desempenho de uma única consulta.
Além disso, temos um fórum ativo. Fique à vontade para fazer perguntas lá. https://www.couchbase.com/forums/