Autores e equipe de engenharia: Bingjie Miao, Keshav Murthy, Marco Greco, Prathibha Bisarahalli. Couchbase, Inc.
Um otimizador baseado em regras conhece regras para tudo e custos para nada. Oscar Wilde
Resumo
O Couchbase é um banco de dados JSON distribuído. Ele oferece processamento de dados distribuído, indexação de alto desempenho e linguagem de consulta declarativa N1QL, além de índice de pesquisa, eventos e análises. N1QL (Non First Normal Query Language) é SQL para JSON. A N1QL é para o JSON o que o SQL é para as relações. Os desenvolvedores dizem o que precisa ser feito, e o mecanismo N1QL descobrirá o "como". O otimizador N1QL atual é um otimizador baseado em regras. O otimizador baseado em custo (CBO) para SQL foi inventado em IBM há cerca de 40 anos e tem sido fundamental para o sucesso dos RDBMS e para a produtividade do desenvolvedor/DBA. Os bancos de dados NoSQL foram inventados há cerca de 10 anos. Logo após sua invenção, os bancos de dados NoSQL começaram a adicionar uma linguagem de consulta semelhante à SQL com caminhos de acesso limitados e recursos de otimização. A maioria usa um otimizador baseado em regras ou simplesmente oferece suporte à otimização baseada em custos somente para valores escalares simples (strings, números, booleanos etc.).
Para criar uma CBO no modelo JSON, primeiro você precisa coletar e organizar as estatísticas. Como você coleta, armazena e usa estatísticas no esquema flexível do JSON? Como coletar estatísticas sobre objetos, matrizes, elementos dentro de objetos? Como usá-las de forma eficiente em seu otimizador?
Lukas Eder uma vez me disse: "O otimizador baseado em custo torna o SQL totalmente declarativo". Ele tem razão. O Couchbase 6.5 (agora GA) tem o otimizador baseado em custo para N1QL. Este artigo apresenta a introdução do N1QL Cost Based Optimizer (CBO) em Couchbase 6.5. CBO é um recurso de visualização de desenvolvedor com patente pendente. Neste artigo, descrevemos como você pode usar o CBO, bem como os detalhes de sua implementação.
Uma versão em PDF deste artigo pode ser baixado aqui.
Índice
- Resumo
- Introdução ao N1QL
- Uso do otimizador baseado em custo para N1QL
- Otimizador N1QL
- Otimizador baseado em custo para N1QL
- Coleta de estatísticas para a CBO N1QL
- Resumo
- Recursos Otimizador baseado em regras N1QL
- Referências
Introdução ao N1QL
Como o JSON tem sido cada vez mais aceito pelo setor de tecnologia da informação como a língua franca para a mudança de informações, houve um aumento exponencial na necessidade de repositórios que armazenam, atualizam e consultam documentos JSON de forma nativa. O SQL adicionou recursos que manipulam JSON em SQL:2016. O SQL:2016 adiciona novas funções escalares e de tabela para manipular o JSON. Uma abordagem alternativa é tratar o JSON como o modelo de dados e projetar a linguagem para operar no JSON de forma nativa. N1QL e SQL++ usam a última abordagem e fornecem acesso natural a escalares, objetos, matrizes, matrizes de objetos, matrizes dentro de objetos e assim por diante.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
SQL:2016: From: Microsoft SQL Server. SELECT Name,Surname, JSON_VALUE(jsonCol,'$.info.address.PostCode') AS PostCode, JSON_VALUE(jsonCol,'$.info.address."Address Line 1"')+' ' +JSON_VALUE(jsonCol,'$.info.address."Address Line 2"') AS Address, JSON_QUERY(jsonCol,'$.info.skills') AS Skills FROM People WHERE ISJSON(jsonCol) > 0 AND JSON_VALUE(jsonCol,'$.info.address.Town')='Belgrade' AND Status='Active' ORDER BY JSON_VALUE(jsonCol,'$.info.address.PostCode') |
|
1 2 3 4 5 6 7 8 9 10 |
N1QL: Same query written in N1QL on the JSON model SELECT Name,Surname, jsonCol.info.address.PostCode AS PostCode, (jsonCol.info.address.`Address Line 1` + ' ' + jsonCol.`info.address.`Address Line 2`) AS Address, jsonCol.info.skills' AS Skills FROM People WHERE jsonCol.info.address.Town = 'Belgrade' AND Status='Active' ORDER BY jsonCol.info.address.PostCode |
Aprenda N1QL em https://query-tutorial.couchbase.com/
Servidor Couchbase:
O Couchbase tem mecanismos que suportam N1QL:
- N1QL para aplicativos interativos no serviço Query.
- N1QL for Analytics no serviço Analytics.
Neste artigo, vamos nos concentrar no N1QL for Query (aplicativos interativos) implementado no serviço de consulta. Todos os dados manipulados pelo N1QL são salvos em JSON no armazenamento de dados do Couchbase gerenciado pelo serviço de dados.
Para dar suporte ao processamento de consultas em JSON, o N1QL amplia a linguagem SQL de várias maneiras:
-
- Suporte para esquema flexível em JSON autodescritivo semiestruturado.
- acessar e manipular elementos em JSON: valores escalares, objetos, matrizes, objetos de valores escalares, matrizes de valores escalares, matrizes de objetos, matrizes de matrizes etc.
- Introduzir um novo valor booleano, MISSING, para representar um par chave-valor ausente em um documento, diferente de um valor nulo conhecido. Isso estende o lógica de três valores para lógica de quatro valores.
- Novas operações para as operações NEST e UNNEST para criar matrizes e achatar matrizes, respectivamente.
- Amplie as operações JOIN para trabalhar com escalares, objetos e matrizes JSON.
- Para acelerar o processamento desses documentos JSON, os índices secundários globais podem ser criados em um ou mais valores escalares, valores escalares de matrizes, objetos aninhados, matrizes aninhadas, objetos, objetos de matriz, elementos de matriz.
- Adicione o recurso de pesquisa integrada usando o índice de pesquisa invertido.
Uso do CBO para N1QL
Introduzimos o (CBO) no Couchbase 6.5 (agora GA). Vamos dar uma olhada em como usar o recurso antes de nos aprofundarmos nos detalhes.
- CRIE um novo bucket e carregue os dados do bucket de amostra travel-sample.
|
1 2 3 4 5 6 7 8 9 |
INSERT INTO hotel(KEY id, VALUE h) SELECT META().id id, h FROM `travel-sample` h WHERE type = "hotel" |
- Modelo de documento de hotel
Aqui está um exemplo de documento de hotel. Esses valores são escalares, objetos e matrizes. Uma consulta sobre isso acessará e processará todos esses campos.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 |
{ "hotel": { "address": "Capstone Road, ME7 3JE", "alias": null, "checkin": null, "checkout": null, "city": "Medway", "country": "United Kingdom", "description": "40 bed summer hostel about 3 miles from Gillingham, housed in a districtive converted Oast House in a semi-rural setting.", "directions": null, "email": null, "fax": null, "free_breakfast": true, "free_internet": false, "free_parking": true, "geo": { "accuracy": "RANGE_INTERPOLATED", "lat": 51.35785, "lon": 0.55818 }, "id": 10025, "name": "Medway Youth Hostel", "pets_ok": true, "phone": "+44 870 770 5964", "price": null, "public_likes": [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Ms. Moses Feeney", "Elnora Trantow" ], "reviews": [ { "author": "Ozella Sipes", "content": "This was our 2nd trip here and we enjoyed it as much or more than last year. Excellent location across from the French Market and just across the street from the streetcar stop. Very convenient to several small but good restaurants. Very clean and well maintained. Housekeeping and other staff are all friendly and helpful. We really enjoyed sitting on the 2nd floor terrace over the entrance and \"people-watching\" on Esplanade Ave., also talking with our fellow guests. Some furniture could use a little updating or replacement, but nothing major.", "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } }, { "author": "Barton Marks", "content": "We found the hotel de la Monnaie through Interval and we thought we'd give it a try while we attended a conference in New Orleans. This place was a perfect location and it definitely beat staying downtown at the Hilton with the rest of the attendees. We were right on the edge of the French Quarter withing walking distance of the whole area. The location on Esplanade is more of a residential area so you are near the fun but far enough away to enjoy some quiet downtime. We loved the trolly car right across the street and we took that down to the conference center for the conference days we attended. We also took it up Canal Street and nearly delivered to the WWII museum. From there we were able to catch a ride to the Garden District - a must see if you love old architecture - beautiful old homes(mansions). We at lunch ate Joey K's there and it was excellent. We ate so many places in the French Quarter I can't remember all the names. My husband loved all the NOL foods - gumbo, jambalya and more. I'm glad we found the Louisiana Pizza Kitchen right on the other side of the U.S. Mint (across the street from Monnaie). Small little spot but excellent pizza! The day we arrived was a huge jazz festival going on across the street. However, once in our rooms, you couldn't hear any outside noise. Just the train at night blowin it's whistle! We enjoyed being so close to the French Market and within walking distance of all the sites to see. And you can't pass up the Cafe du Monde down the street - a busy happenning place with the best French dougnuts!!!Delicious! We will defintely come back and would stay here again. We were not hounded to purchase anything. My husband only received one phone call regarding timeshare and the woman was very pleasant. The staff was laid back and friendly. My only complaint was the very firm bed. Other than that, we really enjoyed our stay. Thanks Hotel de la Monnaie!", "date": "2015-03-02 19:56:13 +0300", "ratings": { "Business service (e.g., internet access)": 4, "Check in / front desk": 4, "Cleanliness": 4, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } } ], "state": null, "title": "Gillingham (Kent)", "tollfree": null, "type": "hotel", "url": "https://www.yha.org.uk", "vacancy": true } } |
- Depois de conhecer as consultas que deseja executar, basta criar os índices com as chaves.
|
1 2 3 4 5 6 7 8 9 10 11 |
CREATE INDEX i3 ON `hotel`(name, country); CREATE INDEX i4 ON `hotel`(country, name); CREATE INDEX i3 ON `hotel`(country, city); CREATE INDEX i4 ON `hotel`(city, country); /* Array indexes on the array keys you want to filter on. CREATE INDEX i5 ON `hotel`(DISTINCT public_likes); CREATE INDEX i6 ON `hotel`(DISTINCT ARRAY r.ratings.Overall FOR r IN reviews END); /* Index on the fields within the geo object */ CREATE INDEX i7 ON `hotel`(geo.lat, geo.lon) |
- Agora, colete estatísticas sobre o campo em que você terá filtros. Normalmente, você indexa os campos que indexa. Portanto, você deseja coletar estatísticas sobre eles também. Ao contrário do comando CREATE INDEX, a ordem das chaves não tem nenhuma consequência para o comando UPDATE STASTICS
UPDATE STATISTICS for `hotel` (type, address, city, country, free_breakfast, id, phone);
- Índice de matriz em uma matriz simples de escalares. public_likes é uma matriz de cadeias de caracteres. DISTINCT public_likes cria um índice em cada elemento de public_likes em vez de toda a matriz public_likes. Detalhes sobre estatísticas de matriz mais adiante neste artigo.
UPDATE STATISTICS for `hotel`(DISTINCT public_likes);
- Agora execute, explique e observe essas declarações. O CBO, com base nas estatísticas que você coletou acima, calculou a seletividade do predicado (country = 'France')
|
1 2 3 4 |
SELECT count(*) FROM `hotel` WHERE country = 'France'; { "$1": 140 } |
- Aqui está o trecho do EXPLAIN. A saída do Explain terá estimativas de cardinalidade e a saída do perfil terá os documentos reais (linhas, chaves) qualificados em cada operador.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
"#operator": "IndexScan3", "cardinality": 141.54221635883903, "cost": 71.19573482849603, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`type`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i2", SELECT count(*) FROM `hotel` WHERE country = 'United States'; { "$1": 361 } "cardinality": 361.7189973614776, "cost": 181.94465567282322, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`type`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i2", |
- combinando o cálculo de custo em vários predicados. Observe que os resultados reais são proporcionais às estimativas de cardinalidade. Estimativas de seletividade de união são difíceis de estimar devido às correlações e exigem técnicas adicionais.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 |
SELECT count(*) FROM `hotel` WHERE country = 'United States' and name LIKE 'A%'; { "$1": 7 } "cardinality": 13.397476328354337, "cost": 8.748552042415382, "covers": [ "cover ((`hotel`.`country`))", "cover ((`hotel`.`name`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i4", SELECT count(*) FROM `hotel` WHERE country = 'United States' and name = 'Ace Hotel DTLA' { "$1": 1 } "#operator": "IndexScan3", "cardinality": 0.39466325234388644, "cost": 0.25771510378055784, "covers": [ "cover ((`hotel`.`name`))", "cover ((`hotel`.`country`))", "cover ((meta(`hotel`).`id`))", "cover (count(*))" ], "index": "i3", select count(1) from hotel where country = 'United States' and city = 'San Francisco'; { "$1": 132 } "#operator": "IndexScan3", "cardinality": 361.7189973614776, "cost": 181.94465567282322, "index": "i2", "index_id": "a020ba7594f7c045", "index_projection": { "primary_key": true }, "keyspace": "hotel", |
- Cálculo no predicado da matriz: ANY. Isso usa a coleção de estatísticas sobre a expressão (DISTINCT public_likes) nas estatísticas UPDATE acima. As estatísticas de matriz são diferentes das estatísticas escalares normais, da mesma forma que as chaves de índice de matriz são diferentes das chaves de índice normais. O histograma em public_keys conterá mais de um valor do mesmo documento. Portanto, todos os cálculos terão de levar isso em conta para que as estimativas se aproximem da realidade.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT COUNT(1) FROM hotel WHERE ANY p IN public_likes SATISFIES p LIKE 'A%' END { "$1": 272 } "#operator": "DistinctScan", "cardinality": 151.68407386905272, "cost": 144.52983565532256, "scan": { "#operator": "IndexScan3", "cardinality": 331.49044875073974, "cost": 143.53536430907033, "covers": [ "cover ((distinct ((`hotel`.`public_likes`))))", "cover ((meta(`hotel`).`id`))" ], |
- Cálculo no predicado de matriz em um campo dentro de um objeto de uma matriz: ANY r IN reviews SATISFIES r.ratings.Overall = 4 END. As estatísticas são coletadas na expressão: (DISTINCT ARRAY r.ratings.Overall FOR r IN reviews END). A expressão de coleta de estatísticas deve ser exatamente a mesma que a expressão da matriz de chaves de índice.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
SELECT COUNT(1) FROM hotel WHERE ANY r IN reviews SATISFIES r.ratings.Overall = 4 END { "$1": 617 } "#operator": "IndexScan3", "cardinality": 621.4762784966113, "cost": 206.95160073937154, "covers": [ "cover ((distinct (array ((`r`.`ratings`).`Overall`) for `r` in (`hotel`.`reviews`) end)))", "cover ((meta(`hotel`).`id`))", "cover (count(1))" ], "filter_covers": { "cover (any `r` in (`hotel`.`reviews`) satisfies (((`r`.`ratings`).`Overall`) = 4) end)": true }, "index": "i6", SELECT COUNT(1) FROM hotel WHERE ANY r IN reviews SATISFIES r.ratings.Overall < 2 END { "$1": 201 } "#operator": "DistinctScan", "cardinality": 182.14723292266834, "cost": 69.4615304990758, "scan": { "#operator": "IndexScan3", "cardinality": 206.73074553296368, "cost": 68.84133826247691, "covers": [ "cover ((distinct (array ((`r`.`ratings`).`Overall`) for `r` in (`hotel`.`reviews`) end)))", "cover ((meta(`hotel`).`id`))" ], "filter_covers": { "cover (any `r` in (`hotel`.`reviews`) satisfies (((`r`.`ratings`).`Overall`) < 2) end)": true }, "index": "i6", |
Otimizador N1QL
Fluxo de execução de consultas:
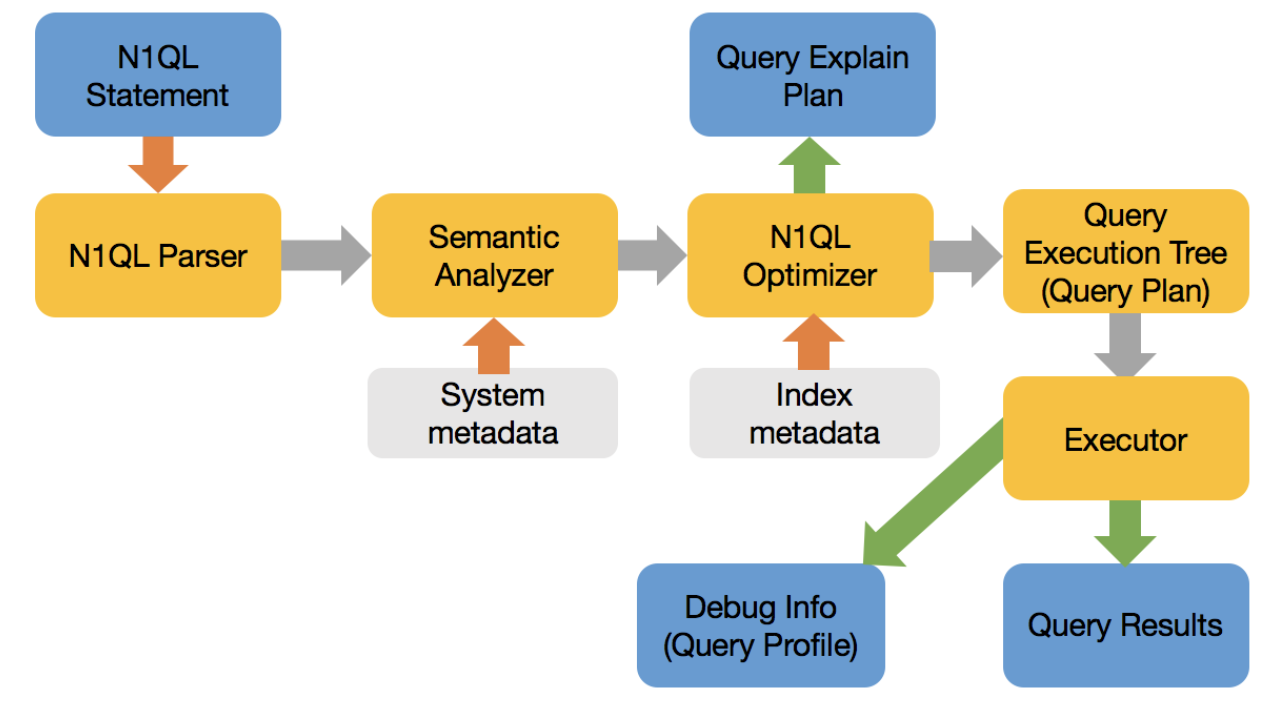
O otimizador, em termos gerais, faz o seguinte:
- Reescreva a consulta em sua forma equivalente ideal para facilitar a otimização e suas escolhas.
- Selecione o caminho de acesso para cada espaço-chave (equivalente a tabelas)
- Selecione um ou mais índices para cada espaço-chave.
- Selecione a ordem de união para todas as uniões na cláusula FROM. O N1QL Optimizer ainda não reordena as uniões.
- Selecione o tipo de junção (por exemplo, loop aninhado ou junção de hash) para cada junção
- Por fim, crie a árvore de execução da consulta (plano).
Neste documento, descrevemos o otimizador baseado em regras do N1QL: Um mergulho profundo na otimização de consultas N1QL do Couchbase.
Embora a discussão neste artigo seja principalmente sobre instruções SELECT, o CBO escolhe planos de consulta para instruções UPDATE, DELETE, MERGE e INSERT (dentro com SELECT). Os desafios, a motivação e a solução são igualmente aplicáveis a todos esses comandos DML.
O N1QL tem os seguintes métodos de acesso disponíveis:
- Varredura de valores
- Varredura de chaves
- Varredura de índice
- Varredura do índice de cobertura
- Exame primário
- Junção de loop aninhado
- Junção de hash
- Varredura anônima
Motivação para um otimizador baseado em custos (CBO)
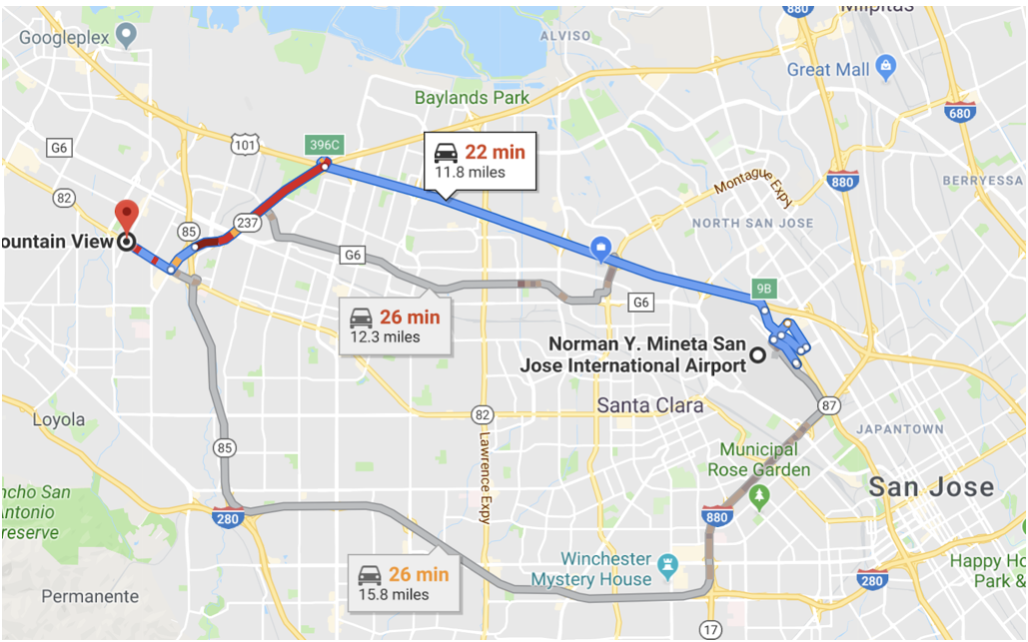
Imagine que o Google Maps lhe dê a mesma rota, independentemente da situação atual do trânsito? Um roteamento baseado em custo leva em consideração o custo atual (tempo estimado com base no fluxo de tráfego atual) e encontra a rota mais rápida. Da mesma forma, um otimizador baseado em custo leva em consideração a quantidade provável de processamento (memória, CPU, E/S) para cada operação, estima o custo de rotas alternativas e seleciona o plano de consulta (árvore de execução de consulta) com o menor custo. No exemplo acima, o algoritmo de roteamento considera a distância e o tráfego e fornece a você as três melhores rotas.
Para sistemas relacionais, o CBO foi inventado em 1970 na IBM, descrito neste artigo seminal. No atual otimizador baseado em regras do N1QL, as decisões de planejamento são independentes da inclinação dos dados para vários caminhos de acesso e da quantidade de dados que se qualificam para os predicados. Isso resulta em geração de planos de consulta inconsistentes e desempenho inconsistente porque as decisões podem ser menos que ideais.
Há muitos bancos de dados JSON: MongoDB, Couchbase, Cosmos DB, CouchDB. Muitos bancos de dados relacionais suportam o tipo JSON e funções acessórias para indexar e acessar dados em JSON. Muitos deles, como Couchbase, CosmosDB e MongoDB, têm uma linguagem de consulta declarativa para JSON e fazem seleção de caminho de acesso e geração de plano. Todos eles implementam um otimizador baseado em regras com base em heurística. Ainda não vimos um artigo ou documentação que indique um otimizador baseado em custo para qualquer banco de dados JSON.
No mundo do NoSQL e do Hadoop, há alguns exemplos de um otimizador baseado em custos.
Porém, eles lidam apenas com os tipos escalares básicos, assim como o otimizador de banco de dados relacional. Eles não lidam com a mudança de tipos, mudança de esquema, objetos, matrizes e elementos de matriz - tudo isso é crucial para o sucesso da linguagem de consulta declarativa sobre JSON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
Consider the bucket customer: /* Create some indexes */ CREATE PRIMARY index ON customer; CREATE INDEX ix1 ON customer(name, zip, status); CREATE INDEX ix2 ON customer(zip, name, status); CREATE INDEX ix3 ON customer(zip, status, name); CREATE INDEX ix4 ON customer(name, status, zip); CREATE INDEX ix5 ON customer(status, zip, name); CREATE INDEX ix6 ON customer(status, name, zip); CREATE INDEX ix7 ON customer(status); CREATE INDEX ix8 ON customer(name); CREATE INDEX ix9 ON customer(zip); CREATE INDEX ix10 ON customer(status, name); CREATE INDEX ix11 ON customer(status, zip); CREATE INDEX ix12 ON customer(name, zip); |
Exemplo de consulta:
SELECT * DO cliente WHERE name = "Joe" E CEP = 94587 E status = "Premium";
A pergunta é simples:
- Todos os índices acima são caminhos de acesso válidos para avaliar a consulta. Qual dos vários índices o N1QL deve usar para executar a consulta de forma eficiente?
- A resposta correta para isso é, depende. Depende da cardinalidade, que depende da distribuição estatística dos dados para cada chave.
Pode haver um milhão de pessoas com o nome Joe, dez milhões de pessoas no código postal 94587 e apenas 5 pessoas com status Premium. Pode haver apenas algumas pessoas com o nome Joe ou mais pessoas com status Premium ou menos clientes no CEP 94587. O número de documentos qualificados para cada filtro e as estatísticas combinadas afetam a decisão.
Até o momento, os problemas são os mesmos da otimização de SQL. Seguir essa abordagem é seguro para coletar estatísticas, calcular seletividades e elaborar o plano de consulta.
Mas o JSON é diferente:
- O tipo de dados pode mudar entre vários documentos. O Zip pode ser numérico em um documento, string em outro, o objeto no terceiro. Como você coleta estatísticas, armazena-as e as utiliza de forma eficiente?
- Ele pode armazenar estruturas complexas e aninhadas usando matrizes e objetos. O que significa coletar estatísticas sobre estruturas aninhadas, matrizes, etc.?
Cicatrizes: números, booleano, cadeia de caracteres, nulo, ausente. No documento abaixo, a, b, c,d, e são todos escalares.
{ "a": 482, "b": 2948.284, "c": "Hello, World", "d": nulo, "e": ausente }
Objetos:
- Pesquisar os objetos inteiros
- Pesquisar elementos em um objeto
- Pesquisar o valor exato de um atributo nos objetos
- Combine os elementos, matrizes e objetos em qualquer lugar da hierarquia.
Essa estrutura é conhecida somente depois que o usuário especifica as referências a elas na consulta. Se essas expressões estiverem em predicados, seria bom saber se elas realmente existem e, em seguida, determinar sua seletividade.
Aqui estão alguns exemplos.
Objetos:
- Referir-se a um escalar dentro de um objeto. Por exemplo, Name.fname, Name.lname
- Referir-se a um escalar dentro de uma matriz de um objeto. Por exemplo, Billing[*].status
- Caso aninhado de (1), (2) e (3). Usando INÚTIL operação.
- Refere-se a um objeto ou a uma matriz nos casos de (1) a (4).
Matrizes:
- Combine a matriz completa.
- Corresponder elementos escalares de uma matriz com tipos compatíveis (número, cadeia de caracteres, etc.)
- Combinar objetos em uma matriz.
- Combine os elementos em uma matriz de uma matriz.
- Combine os elementos, matrizes e objetos em qualquer lugar da hierarquia.
Expressões LET:
- Preciso obter seletividade nas expressões usadas na cláusula WHERE.
Operação UNNEST:
- Seletividades nos filtros do documento UNNESTed para ajudar a escolher o índice correto (matriz).
JOINs: INTERNO, EXTERNO ESQUERDO, EXTERNO DIREITO
- Unir seletividades.
- Normalmente, também é um grande problema em RDBMS. Pode não ser na v1.
Predicados:
- USAR CHAVES
- Comparação de valores escalares: =, >, =, <=, BETWEEN, IN
- Predicados de matriz: ANY, EVERY, ANY & EVERY, WITHIN
- Subconsultas
Otimizador baseado em custo para N1QL
O otimizador baseado em custo agora estimará o custo com base nas estatísticas disponíveis sobre dados, índice, calculará o custo de cada operação e escolherá o melhor caminho.
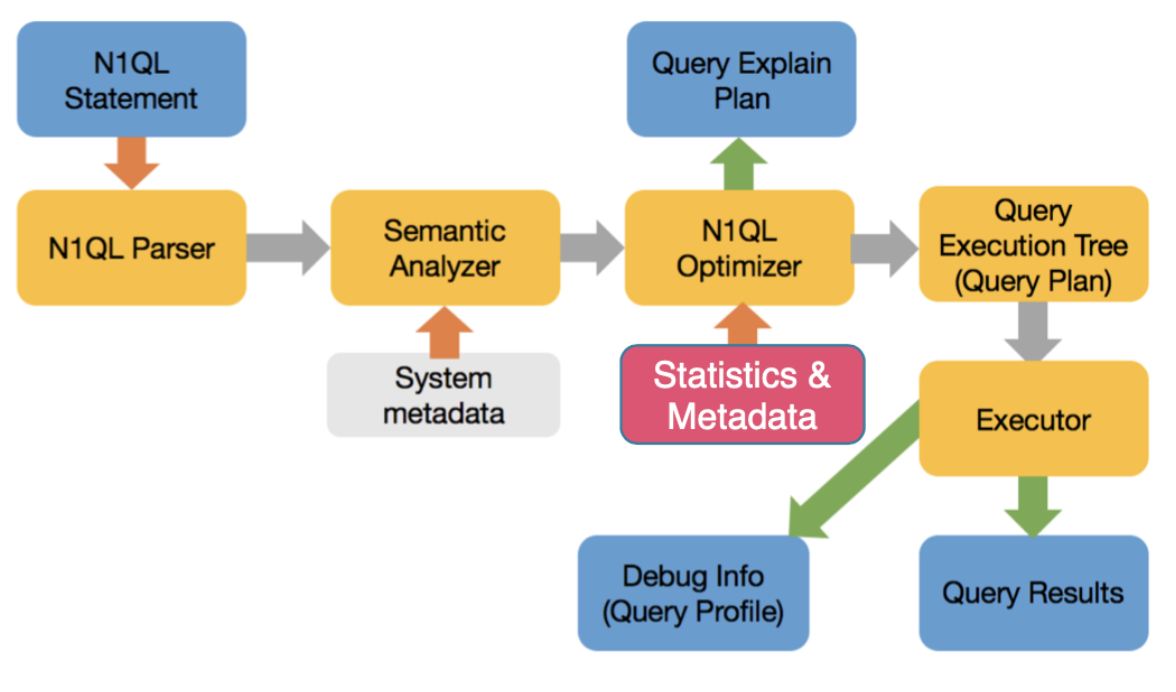
Desafios do otimizador baseado em custo para JSON
- Colete estatísticas sobre escalares, objetos, matrizes, elementos de matriz - qualquer coisa em que você possa aplicar um predicado (filtro)
- Crie a estrutura de dados correta para armazenar estatísticas em um campo cujo tipo pode variar de um tipo para outro.
- Crie métodos para usar as estatísticas para calcular com eficiência estimativas precisas sobre o conjunto complexo de estatísticas coletadas acima.
- Use estatísticas apropriadas, considere caminhos de acesso válidos e crie um plano de consulta.
- Um campo pode ser um número inteiro em um documento, uma cadeia de caracteres no próximo, uma matriz em outro e não existir em outro. Os histogramas
Abordagem do otimizador baseado em custos N1QL
O otimizador N1QL será responsável por determinar a estratégia de execução mais eficiente para uma consulta. Normalmente, há um grande número de estratégias de avaliação alternativas para uma determinada consulta. Essas alternativas podem diferir significativamente em seus requisitos de recursos do sistema e/ou tempo de resposta. Um otimizador de consultas baseado em custo usa um mecanismo de enumeração sofisticado (ou seja, um mecanismo que enumera o espaço de pesquisa de planos de acesso e junção) para gerar com eficiência uma profusão de estratégias alternativas de avaliação de consultas e um modelo detalhado de custo de execução para escolher entre essas estratégias alternativas.
O trabalho do N1QL Optimizer pode ser categorizado da seguinte forma:
- Coletar estatísticas
- Coletar estatísticas sobre campos individuais e criar um único histograma para cada campo (incluindo todos os tipos de dados que podem aparecer nesse campo).
- Coletar estatísticas sobre cada índice disponível.
- Reescrita de consulta.
- Reescrita de consultas com base em regras básicas.
- Estimativas de cardinalidade
- Use as estatísticas de histograma e índice disponíveis para estimar a seletividade.
- Use essa seletividade para a estimativa de cardinalidade
- Isso não é tão simples no caso de matrizes.
- Faça o pedido de adesão.
- CONSIDERAR uma consulta: a JOIN b JOIN c
- Isso é o mesmo que ( b JOIN a JOIN c), (a JOIN c JOIN b), etc.
- A escolha da ordem correta causa um grande impacto na consulta.
- A implementação do Couchbase 6.5 ainda não faz isso. Esse é um problema bem compreendido para o qual podemos pegar emprestadas soluções do SQL. O JSON não apresenta novos problemas. Os predicados da cláusula ON podem incluir predicados de matriz. Isso está no roteiro.
- CONSIDERAR uma consulta: a JOIN b JOIN c
- Tipo de união
- O otimizador baseado em regras usava o loop aninhado em bloco por padrão. É necessário usar diretivas para forçar a junção de hash. A diretiva também precisa especificar o lado da compilação/probe. Ambos são indesejáveis.
- O CBO deve selecionar o tipo de junção. Se for escolhida uma junção de hash, ele deverá escolher automaticamente o lado da construção e o lado da sonda. A escolha do melhor espaço-chave interno/externo para o loop aninhado também está em nosso roteiro.
Coleta de estatísticas para a CBO N1QL
As estatísticas do otimizador são uma parte essencial da otimização baseada em custos. O otimizador calcula os custos de várias etapas da execução da consulta, e o cálculo se baseia no conhecimento do otimizador sobre vários aspectos das entidades físicas no servidor, conhecidas como estatísticas do otimizador.
Manuseio de tipos mistos
Diferentemente dos bancos de dados relacionais, um campo em um documento JSON não tem um tipo, ou seja, podem existir diferentes tipos de valores no mesmo campo. Portanto, uma distribuição precisa lidar com diferentes tipos de valores. Para evitar confusão, colocamos diferentes tipos de valores em diferentes compartimentos de distribuição. Isso significa que podemos ter compartimentos parciais (como o último compartimento) para cada tipo. Há também um tratamento especial para os valores especiais MISSING, NULL, TRUE e FALSE. Esses valores (se presentes) sempre residem em um compartimento de estouro. O N1QL tem uma ordem de classificação predefinida para diferentes tipos e MISSING/NULL/TRUE/FALSE aparece no início do fluxo classificado.
estatísticas de coleta/bucket
Para coleções ou baldes, nós nos reunimos:
- número de documentos na coleção/bucket
- tamanho médio do documento
Estatísticas do índice
Para um índice GSI, reunimos:
- número de itens no índice
- número de páginas de índice
- proporção de residentes
- tamanho médio do item
- tamanho médio da página
Estatísticas de distribuição
Para determinados campos, também coletamos estatísticas de distribuição, o que permite uma estimativa de seletividade mais precisa para predicados como "c1 = 100", "c1 >= 20" ou "c1 < 150". Também produz estimativas de seletividade mais precisas para predicados de junção, como "t1.c1 = t2.c2", supondo que existam estatísticas de distribuição para t1.c1 e t2.c2.
Coleta de estatísticas do otimizador
Embora nossa visão seja fazer com que o servidor atualize automaticamente as estatísticas necessárias do otimizador, para a implementação inicial, as estatísticas do otimizador serão atualizadas por meio de um novo comando UPDATE STATISTICS.
UPDATE STATISTICS [FOR] <keyspace_reference> (<index_expressions>) [WITH <options>]
é um nome de coleção (também podemos oferecer suporte a bucket, mas isso não está decidido neste momento).
O comando acima é para coletar estatísticas de distribuição, é uma ou mais expressões (separadas por vírgulas) para as quais as estatísticas de distribuição devem ser coletadas. Oferecemos suporte às mesmas expressões do comando CREATE INDEX, por exemplo, um campo, campos aninhados (dentro de objetos aninhados, por exemplo, location.lat), uma expressão ALL para matrizes etc. A cláusula WITH é opcional e, se presente, especifica opções para o comando UPDATE STATISTICS. As opções são especificadas no formato JSON, da mesma forma que as opções são especificadas para outros comandos, como CREATE INDEX ou INFER.
Atualmente, as seguintes opções são suportadas na cláusula WITH:
- tamanho_da_amostraTamanho da amostra: para coletar estatísticas de distribuição, o usuário pode especificar um tamanho de amostra a ser usado. É um número inteiro. Observe que também calculamos um tamanho mínimo de amostra e tomamos o maior entre o tamanho de amostra especificado pelo usuário e o tamanho mínimo de amostra calculado.
- resoluçãoPara coletar estatísticas de distribuição, indique quantos compartimentos de distribuição são desejados (granularidade dos compartimentos de distribuição). Ele é especificado como um número flutuante, considerado como uma porcentagem. Por exemplo, {"resolution": 1.0} significa que cada compartimento de distribuição contém aproximadamente 1% do total de documentos, ou seja, são desejados ~100 compartimentos de distribuição. A resolução padrão é 1,0 (100 compartimentos de distribuição). Uma resolução mínima de 0,02 (5000 compartimentos de distribuição) e uma resolução máxima de 5,0 (20 compartimentos de distribuição) serão aplicadas
- update_statistics_timeoutSe o comando UPDATE STATISTICS for usado para atualizar as estatísticas, é possível especificar um valor de tempo limite (em segundos). O comando UPDATE STATISTICS é encerrado com um erro quando o período de tempo limite é atingido. Se não for especificado, um valor de tempo limite padrão será calculado com base no número de amostras usadas.
Manuseio de tipos mistos
Diferentemente dos bancos de dados relacionais, um campo em um documento JSON não tem um tipo, ou seja, podem existir diferentes tipos de valores no mesmo campo. Portanto, uma distribuição precisa lidar com diferentes tipos de valores. Para evitar confusão, colocamos diferentes tipos de valores em diferentes compartimentos de distribuição. Isso significa que podemos ter compartimentos parciais (como o último compartimento) para cada tipo. Há também um tratamento especial para os valores especiais MISSING, NULL, TRUE e FALSE. Esses valores (se presentes) sempre residem em um compartimento de estouro. O N1QL tem uma ordem de classificação predefinida para diferentes tipos e MISSING/NULL/TRUE/FALSE aparece no início do fluxo classificado.
Caixas de limite
Como mantemos apenas o valor máximo para cada compartimento, o limite mínimo é derivado do valor máximo do compartimento anterior. Isso também significa que o primeiro compartimento de distribuição não tem um valor mínimo. Para resolver isso, colocamos uma "posição limite" logo no início, que é uma posição especial com tamanho de posição 0, e o único propósito da posição é fornecer um valor máximo, que é o limite mínimo da próxima posição de distribuição.
Como uma distribuição pode conter vários tipos, separamos os tipos em diferentes compartimentos de distribuição e também colocamos um "compartimento limite" para cada tipo, de modo que saibamos o valor mínimo para cada tipo em uma distribuição.
Exemplo de manuseio de tipos mistos e compartimentos de limite
UPDATE STATISTICS for CUSTOMER(quantity);
Histograma: Número total de documentos: 5000 com a quantidade em números inteiros simples.

Predicados:
-
(quantidade = 100): Estimativa 1%
-
(quantidade entre 200 e 100): Estimativa 20%
Também usamos técnicas adicionais, como manter os valores mais alto/segundo mais alto, mais baixo, segundo mais baixo para cada compartimento, manter um compartimento de estouro para valores que ocorrem mais de 25% do tempo para aprimorar esse cálculo de seletividade.
No JSON, a quantidade pode ser de qualquer um dos tipos: MISSING, null, boolean, integer, string, array e um objeto. Para simplificar, mostramos o histograma de quantidade com três tipos: inteiros, strings e matrizes. Isso foi ampliado para incluir todos os tipos.

O N1QL define o método pelo qual valores de tipos diferentes podem ser comparados.
- Ordem de tipo: do menor para o maior
- Ausente < nulo < falso < verdadeiro < numérico < cadeia de caracteres < matriz < objeto
- Depois de coletar amostras dos documentos, primeiro os agrupamos por tipos, os classificamos dentro do grupo de tipos e criamos o mini-histograma para cada tipo.
- Em seguida, juntamos esses mini-histogramas em um histograma grande com um compartimento de limite entre cada tipo. Isso ajuda o otimizador a calcular eficientemente as seletividades em um único tipo ou em vários tipos.
Exemplos:
|
1 2 3 4 5 6 7 8 |
WHERE quantity between 100 and 1000; WHERE quantity between 100 and "4829"; WHERE quantity between 100 and [235]; WHERE quantity between 100 and {"val": "2829"}; |
As estatísticas de distribuição para tipos de dados simples são diretas. Os valores booleanos terão dois compartimentos de estouro que armazenam valores VERDADEIROS e FALSOS. Os valores numéricos e de cadeia de caracteres também são fáceis de lidar. Uma questão em aberto é se queremos limitar o tamanho de um valor de cadeia de caracteres como um limite de compartimento, ou seja, se uma cadeia de caracteres for muito longa, queremos truncá-la antes de armazená-la como um valor máximo para um compartimento de distribuição. Os valores de cadeia de caracteres longos em um compartimento de estouro não serão truncados, pois isso requer uma correspondência exata.
O projeto de como coletar estatísticas de distribuição não foi finalizado. O que queremos fazer é provavelmente coletar estatísticas de distribuição em elementos individuais da matriz, já que é assim que o índice da matriz funciona. Talvez seja necessário oferecer suporte às variações DISTINCT/ALL do índice de matriz, incluindo a mesma palavra-chave na frente da especificação do campo da matriz, que determina se removemos as duplicatas da matriz antes de construir o histograma.
Estimar a seletividade de um predicado de matriz (QUALQUER predicado) com base nesse histograma é um pouco desafiador. Não há uma maneira fácil de levar em conta os comprimentos variáveis das matrizes na coleção. Na primeira versão, manteremos apenas um tamanho médio de matriz como parte das estatísticas de distribuição. Isso pressupõe alguma forma de uniformidade, o que certamente não é ideal, mas é um bom começo.
Estimar a seletividade do predicado ALL é ainda mais complicado, talvez seja necessário usar algum tipo de valor padrão para isso.
Considere este documento JSON no espaço-chave
|
1 2 3 4 5 6 7 8 9 10 11 12 |
{ "a": 1, "b": [ 5, 10, 15,20,5,20,10], "c": [ { "x": "hello", "y": true }, { "x": "thanks", "y": false} ] } |
O campo "a" é um escalar, b é uma matriz de escalares e c é uma matriz de objetos. Ao emitir uma consulta, você pode ter predicados em qualquer um ou em todos os campos: a, b, c. Até agora, discutimos os escalares cujo tipo pode mudar. Agora vamos discutir a coleta de estatísticas de predicados de matriz e o cálculo de seletividade.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
Array predicates: FROM k WHERE ANY e IN b SATISFIES e = 10 END FROM k WHERE ANY e in b SATISFIES e > 50 END FROM k WHERE ANY e IN b SATISFIES e BETWEEN 30 and 100 END FROM k UNNEST k.b AS e WHERE e = 10; FROM k UNNEST k.b AS e WHERE e > 10; FROM k WHERE ANY f IN c SATISFIES e.x = “hello” END FROM k WHERE ANY f IN c SATISFIES e.y = true END FROM k UNNEST k.c AS f WHERE f.x = “thanks” |
Essa é uma implementação generalizada em que a consulta pode ser escrita para filtrar elementos e valores em matrizes de matrizes, matrizes de objetos de matrizes etc.
Quando você tem um bilhão desses documentos, cria índices de matriz para executar o filtro com eficiência. Agora, para o otimizador, é importante estimar o número de documentos que se qualificam para um determinado predicado.
|
1 2 3 4 5 6 7 8 9 |
CREATE INDEX i1 ON k(DISTINCT b); CREATE INDEX I2 ON k (ALL b); CREATE INDEX i3 ON k(DISTINCT array f.x for f IN c) CREATE INDEX i3 ON k(ALL array f.x for f IN c) |
O índice i1 com a chave DISTINCT b cria um índice com apenas os elementos distintos (exclusivos) de b.
O índice i2 com a chave ALL b cria um índice com todos os elementos de b.
Isso existe para gerenciar o tamanho do índice e a possibilidade de obter grandes resultados intermediários a partir do índice. Em ambos os casos, haverá MÚLTIPLAS entradas de índice para CADA elemento de uma matriz. Isso é diferente de um escalar que tem APENAS uma entrada no índice POR documento JSON.
Para saber mais sobre indexação de matriz, consulte Documentação de indexação de matriz no Couchbase.
Como você coleta estatísticas sobre essa matriz ou matriz de objetos? O principal insight é coletar estatísticas sobre EXATAMENTE a mesma expressão que a expressão na qual você está criando o índice.
Nesse caso, coletamos estatísticas sobre o seguinte:
|
1 2 3 4 5 6 7 8 |
UPDATE STATISTICS FOR k(DISTINCT b) UPDATE STATISTICS FOR k(ALL b) UPDATE STATISTICS FOR k(DISTINCT array f.x for f IN c) UPDATE STATISTICS FOR k(ALL array f.x for f IN c) |
Agora, dentro do histograma, pode haver zero, um ou mais valores originários do mesmo documento. Portanto, calcular a seletividade (porcentagem estimada de documentos que qualificam o filtro) não é tão fácil!
Aqui está a nova solução para resolver o problema com matrizes:
Para estatísticas normais: há uma entrada de índice por documento.
A cardinalidade se torna simples: seletividade x cardinalidade da tabela;
Para estatísticas de matriz: Há N entradas de índice por documento;
N-> Número de valores distintos na matriz.
N = 0 a n, n <= ARRAY_LENGTH(a)
Essas estatísticas adicionais devem ser coletadas e armazenadas no histograma.
Agora, quando um índice for escolhido para a avaliação de um determinado predicado, a varredura do índice retornará todas as chaves qualificadas do documento, que contêm duplicatas. O mecanismo de consulta fará então uma operação distinta para obter as chaves exclusivas e obter os resultados corretos (não duplicados). O otimizador baseado em custo terá de levar isso em conta ao calcular o número de documentos (não o número de entradas de índice) que qualificarão o predicado. Portanto, dividimos a estimativa pela estimativa do comprimento médio do tamanho da matriz.
Essa cardinalidade pode ser usada para calcular o custo e comparar o custo do uso do caminho de índice de matriz em relação a outro caminho de acesso legal para encontrar o melhor caminho de acesso.
Valores de objetos, JSON e binários
Não está claro qual será a utilidade de um histograma em um valor de objeto/JSON ou em um valor binário. Deve ser raro ver comparações com esses valores na consulta. Podemos lidar com eles exatamente como outros tipos simples, ou seja, colocar o número de valores, o número de valores distintos e um limite máximo em cada compartimento de distribuição; ou podemos simplificar e apenas colocar a contagem no compartimento de distribuição sem o número de valores distintos e o valor máximo. O problema com o valor máximo é semelhante ao das cadeias de caracteres longas, em que o valor pode ser grande, e o armazenamento desses valores grandes pode não ser vantajoso no histograma. Por enquanto, essa é uma questão em aberto.
Estatísticas para campos em objetos aninhados
Considere este documento JSON no espaço-chave:
|
1 2 3 4 5 6 7 8 9 10 11 |
{ "a": 1, "b": {"p": "NY", "q": "212-820-4922", "r": 2848.23}, "c": { "d": 23, "e": { "x": "hello", "y": true , "z": 48} } } |
A seguir, a expressão pontilhada para acessar objetos aninhados.
FROM k WHERE b.p = "NY" AND c.e.x = "hello" AND c.e.z = 48;
Como cada caminho é único, coletar e usar o histograma é como um escalar.
UPDATE STATISTICS FOR k(b.p, c.e.x, c.e.z)
Resumo
Descrevemos como implementamos um otimizador baseado em custos para o N1QL (SQL para JSON) e lidamos com os seguintes desafios.
- O N1QL CBO pode lidar com um esquema JSON flexível.
- O N1QL CBO pode manipular escalares, objetos e matrizes.
- O N1QL CBO pode lidar com a coleta de estatísticas e calcular estimativas em qualquer campo de qualquer tipo dentro do JSON.
- Tudo isso aprimorou os planos de consulta e, portanto, melhorou o desempenho do sistema. Isso também reduzirá o TCO, diminuindo a sobrecarga de depuração do desempenho do DBA.
- Baixar Couchbase 6.5 e experimente você mesmo!
Recursos Otimizador baseado em regras N1QL
O primeiro artigo descreve o Couchbase Optimizer a partir da versão 5.0. Adicionamos junções ANSI no Couchbase 5.5. O segundo artigo inclui sua descrição e algumas das otimizações feitas para ele.
- Um mergulho profundo na otimização de consultas N1QL do Couchbase https://dzone.com/articles/a-deep-dive-into-couchbase-n1ql-query-optimization
- Suporte a ANSI JOIN no N1QL https://dzone.com/articles/ansi-join-support-in-n1ql
- Crie o índice correto, obtenha o desempenho correto para o otimizador baseado em regras.
- Algoritmo de seleção de índices
Referências
- Seleção do caminho de acesso em um sistema de gerenciamento de banco de dados relacional. https://people.eecs.berkeley.edu/~brewer/cs262/3-selinger79.pdf
- Otimização baseada em custos no DB2 XML. https://www2.hawaii.edu/~lipyeow/pub/ibmsys06-xmlopt.pdf
- Seleção do caminho de acesso em um sistema de gerenciamento de banco de dados relacional. https://people.eecs.berkeley.edu/~brewer/cs262/3-selinger79.pdf