Visão geral
O suporte a ANSI JOIN foi adicionado em N1QL à versão 5.5 do Couchbase. Nas versões anteriores do Couchbase, o suporte a junções era limitado a junções de pesquisa e junções de índices, o que funciona muito bem quando a chave do documento de um lado da junção pode ser produzida pelo outro lado da junção, ou seja, junção em um relacionamento pai-filho ou filho-pai por meio de uma chave de documento.
Essa abordagem é insuficiente quando a união é feita em campos arbitrários ou expressões de campos, ou quando são necessárias várias condições de união. ANSI JOIN é uma sintaxe de união padronizada amplamente usada em bancos de dados relacionais. O ANSI JOIN é muito mais flexível do que a junção de pesquisa e a junção de índices, permitindo que a junção seja feita em expressões arbitrárias em qualquer campo de um documento. Isso torna as operações de união muito mais simples e eficientes.
Sintaxe ANSI JOIN:
lhs-expression [ join-type ] JOIN rhs-keyspace ON [ join-condition ]
O lado esquerdo da união, lhs-expression, pode ser um espaço-chave, uma expressão N1QL, uma subconsulta ou uma união anterior. O lado direito da união, rhs-keyspace, deve ser um espaço-chave. A cláusula ON especifica a condição de união, que pode ser qualquer expressão arbitrária, embora deva conter predicados que permitam uma varredura de índice no espaço-chave do lado direito. O tipo de junção pode ser INNER, LEFT OUTER, RIGHT OUTER. As palavras-chave INNER e OUTER são opcionais, portanto, JOIN é o mesmo que INNER JOIN, e LEFT JOIN é o mesmo que LEFT OUTER JOIN. Em bancos de dados relacionais, o tipo de junção também pode ser FULL OUTER ou CROSS, embora FULL OUTER JOIN e CROSS JOIN não sejam suportados atualmente no N1QL.
Detalhes do suporte a ANSI JOIN
Usaremos exemplos para mostrar novas maneiras de executar consultas usando a sintaxe ANSI JOIN e como transformar suas consultas de junção existentes no N1QL da sintaxe de junção de pesquisa ou junção de índice na nova sintaxe ANSI JOIN. Deve-se observar que a junção de pesquisa e a junção de índice continuarão a ser suportadas no N1QL para compatibilidade com versões anteriores; no entanto, não é possível misturar a junção de pesquisa ou a junção de índice com a nova sintaxe ANSI JOIN no mesmo bloco de consulta.
Para acompanhar, instalar a amostra de viagem balde de amostra.
Exemplo 1: ANSI JOIN com condição de união arbitrária
A condição de união (cláusula ON) para ANSI JOIN pode ser qualquer expressão, envolvendo quaisquer campos dos documentos que estão sendo unidos. Por exemplo:
Índice necessário:
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
Índice opcional:
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(city, country) WHERE type = "airport"; |
Consulta:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
Nessa consulta, estamos unindo um campo ("faa") do documento do aeroporto com um campo ("sourceairport") do documento da rota (consulte a cláusula ON da união). Essa junção não é possível com a junção de pesquisa ou junção de índice no N1QL, pois ambas exigem a junção somente na chave do documento.
O ANSI JOIN requer um índice apropriado no espaço-chave do lado direito ("Índice obrigatório" acima). Você também pode criar outros índices (por exemplo, "Índice opcional" acima) para acelerar a consulta. Sem o índice opcional, uma varredura primária será usada e a consulta ainda funcionará, mas sem o índice obrigatório a consulta não funcionará e retornará um erro.
Olhando para a explicação:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
"plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "airport", "index": "airport_city_country", "index_id": "8e782fd1b124eec3", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"San Francisco\"", "inclusion": 3, "low": "\"San Francisco\"" }, { "high": "\"United States\"", "inclusion": 3, "low": "\"United States\"" } ] } ], "using": "gsi" }, { "#operator": "Fetch", "as": "airport", "keyspace": "travel-sample", "namespace": "default" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "NestedLoopJoin", "alias": "route", "on_clause": "(((`airport`.`faa`) = cover ((`route`.`sourceairport`))) and (cover ((`route`.`type`)) = \"route\"))", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "route", "covers": [ "cover ((`route`.`sourceairport`))", "cover ((`route`.`destinationairport`))", "cover ((meta(`route`).`id`))" ], "filter_covers": { "cover ((`route`.`type`))": "route" }, "index": "route_airports", "index_id": "f1f4b9fbe85e45fd", "keyspace": "travel-sample", "namespace": "default", "nested_loop": true, "spans": [ { "exact": true, "range": [ { "high": "(`airport`.`faa`)", "inclusion": 3, "low": "(`airport`.`faa`)" } ] } ], "using": "gsi" } ] } }, { "#operator": "Filter", "condition": "((((`airport`.`type`) = \"airport\") and ((`airport`.`city`) = \"San Francisco\")) and ((`airport`.`country`) = \"United States\"))" }, { "#operator": "InitialProject", "distinct": true, "result_terms": [ { "expr": "cover ((`route`.`destinationairport`))" } ] }, { "#operator": "Distinct" }, { "#operator": "FinalProject" } ] } }, { "#operator": "Distinct" } ] } |
Você verá que um operador NestedLoopJoin é usado para realizar a união e, abaixo dele, um operador IndexScan3 é usado para acessar o espaço-chave do lado direito, "route". Os intervalos para a varredura de índice se parecem com:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"spans": [ { "exact": true, "range": [ { "high": "(`airport`.`faa`)", "inclusion": 3, "low": "(`airport`.`faa`)" } ] } ] |
A varredura de índice para o espaço-chave do lado direito ("route") está usando um campo ("faa") do espaço-chave do lado esquerdo ("airport") como chave de pesquisa. Para cada documento do espaço-chave externo "airport", o operador NestedLoopJoin executa uma varredura de índice no espaço-chave interno "route" para encontrar documentos correspondentes e produz resultados de junção. A junção é realizada em um loop aninhado, em que o loop externo produz um documento do espaço-chave externo e um loop interno aninhado pesquisa o documento interno correspondente para o documento externo atual.
As informações de explicação também podem ser visualizadas graficamente no Query Workbench, clicando no botão Explain (Explicar) seguido do botão Plan (Planejar):
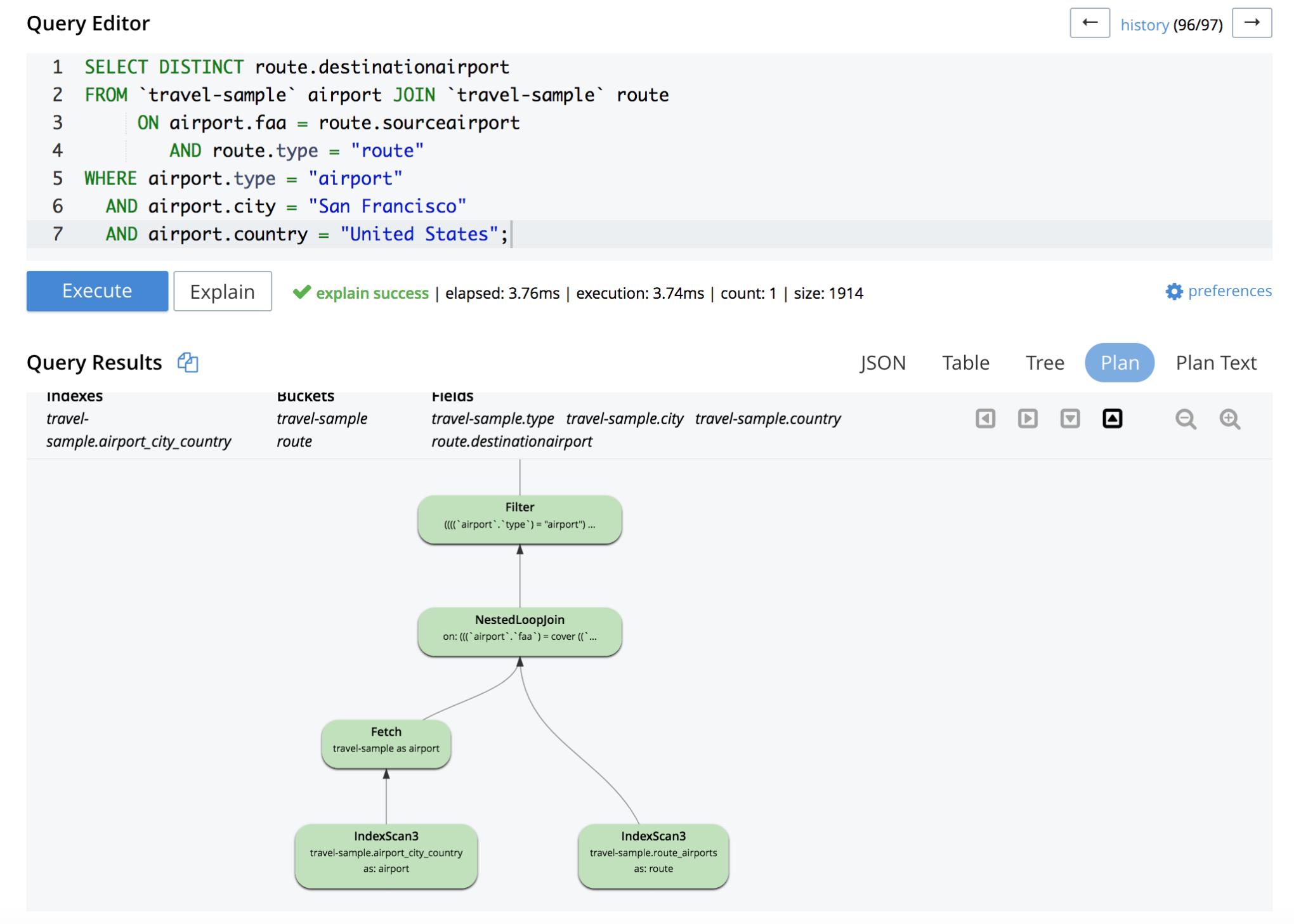
Neste exemplo, a varredura de índice no espaço de chave do lado direito é uma varredura de índice coberta. Caso a varredura de índice não seja coberta, um operador de busca seguirá o operador de varredura de índice para buscar o documento.
Deve-se observar que a junção de loop aninhado requer um índice secundário apropriado no espaço de chave do lado direito do ANSI JOIN. O índice primário não é considerado para essa finalidade. Se não for possível encontrar um índice secundário apropriado, será retornado um erro para a consulta.
Além disso, você deve ter notado que o filtro route.type = "route" (rota) também aparece na cláusula ON. A cláusula ON é diferente da cláusula WHERE, pois a cláusula ON é avaliada como parte da união, enquanto a cláusula WHERE é avaliada depois que todas as uniões são feitas. Essa distinção é importante, especialmente para uniões externas. Portanto, é recomendável que você inclua filtros no espaço de chaves do lado direito para uma união na cláusula ON, além de quaisquer filtros de união.
Exemplo 2: ANSI JOIN com várias condições de união
Enquanto a união de pesquisa e a união de índice se unem somente em uma única condição de união (igualdade da chave do documento), a cláusula ON do ANSI JOIN pode conter várias condições de união.
Índice necessário:
|
1 |
CREATE INDEX landmark_city_country ON `travel-sample`(city, country) WHERE type = "landmark"; |
Índice opcional:
|
1 |
CREATE INDEX hotel_title ON `travel-sample`(title) WHERE type = "hotel"; |
Consulta:
|
1 2 3 4 |
SELECT hotel.name hotel_name, landmark.name landmark_name, landmark.activity FROM `travel-sample` hotel JOIN `travel-sample` landmark ON hotel.city = landmark.city AND hotel.country = landmark.country AND landmark.type = "landmark" WHERE hotel.type = "hotel" AND hotel.title like "Yosemite%" AND array_length(hotel.public_likes) > 5; |
Observando a explicação, os intervalos de índice para o índice ("landmark_city_country") do espaço-chave do lado direito ("landmark") são:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
"spans": [ { "exact": true, "range": [ { "high": "(`hotel`.`city`)", "inclusion": 3, "low": "(`hotel`.`city`)" }, { "high": "(`hotel`.`country`)", "inclusion": 3, "low": "(`hotel`.`country`)" } ] } ] |
Assim, vários predicados de união podem potencialmente gerar várias chaves de pesquisa de índice para a varredura de índice do lado interno de uma união de loop aninhado.
Exemplo 3: ANSI JOIN com expressões de junção complexas
A condição de união na cláusula ON pode ser uma expressão de união complexa. Por exemplo, o campo "airlineid" no documento "route" corresponde à chave do documento "airline", mas também pode ser construído pela concatenação de "airline_" com o campo "id" do documento "airline".
Índice necessário:
|
1 |
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type = "route"; |
Índice opcional:
|
1 |
CREATE INDEX airline_name ON `travel-sample`(name) WHERE type = "airline"; |
Consulta:
|
1 2 3 4 |
SELECT count(*) FROM `travel-sample` airline JOIN `travel-sample` route ON route.airlineid = "airline_" || tostring(airline.id) AND route.type = "route" WHERE airline.type = "airline" AND airline.name = "United Airlines"; |
A explicação contém os seguintes intervalos de índice para o espaço-chave do lado direito ("route"):
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"spans": [ { "exact": true, "range": [ { "high": "(\"airline_\" || to_string((`airline`.`id`)))", "inclusion": 3, "low": "(\"airline_\" || to_string((`airline`.`id`)))" } ] } ] |
A expressão será avaliada em tempo de execução para gerar as chaves de pesquisa para a varredura de índice no lado interno da união de loops aninhados.
Exemplo 4: ANSI JOIN com cláusula IN
A condição de união não precisa ser um predicado de igualdade. Uma cláusula IN pode ser usada como condição de união.
Índice necessário:
|
1 |
CREATE INDEX airport_faa_name ON `travel-sample`(faa, airportname) WHERE type = "airport"; |
Índice opcional:
|
1 |
CREATE INDEX route_airline_distance ON `travel-sample`(airline, distance) WHERE type = "route"; |
Consulta:
|
1 2 3 4 |
SELECT DISTINCT airport.airportname FROM `travel-sample` route JOIN `travel-sample` airport ON airport.faa IN [ route.sourceairport, route.destinationairport ] AND airport.type = "airport" WHERE route.type = "route" AND route.airline = "F9" AND route.distance > 3000; |
A explicação contém os seguintes intervalos de índice para o espaço-chave do lado direito ("airport"):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
"spans": [ { "range": [ { "high": "(`route`.`sourceairport`)", "inclusion": 3, "low": "(`route`.`sourceairport`)" } ] }, { "range": [ { "high": "(`route`.`destinationairport`)", "inclusion": 3, "low": "(`route`.`destinationairport`)" } ] } ] |
Exemplo 5: ANSI JOIN com cláusula OR
Semelhante à cláusula IN, a condição de união de um ANSI JOIN também pode conter uma cláusula OR. Diferentes braços da cláusula OR podem potencialmente fazer referência a diferentes campos do espaço-chave do lado direito, desde que existam índices apropriados.
Índice necessário (índice route_airports igual ao do exemplo 1):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX route_airports2 ON `travel-sample`(destinationairport, sourceairport) WHERE type = "route"; |
Índice opcional (igual ao exemplo 1):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(city, country) WHERE type = "airport"; |
Consulta:
|
1 2 3 4 |
SELECT count(*) FROM `travel-sample` airport JOIN `travel-sample` route ON (route.sourceairport = airport.faa OR route.destinationairport = airport.faa) AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "Denver" AND airport.country = "United States"; |
A explicação mostra um UnionScan sendo usado em NestedLoopJoin, para lidar com a cláusula OR:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
"#operator": "UnionScan", "scans": [ { "#operator": "IndexScan3", "as": "route", "index": "route_airports", "index_id": "f1f4b9fbe85e45fd", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "nested_loop": true, "spans": [ { "exact": true, "range": [ { "high": "(`airport`.`faa`)", "inclusion": 3, "low": "(`airport`.`faa`)" } ] } ], "using": "gsi" }, { "#operator": "IndexScan3", "as": "route", "index": "route_airports2", "index_id": "cdc9dca18c973bd3", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "nested_loop": true, "spans": [ { "exact": true, "range": [ { "high": "(`airport`.`faa`)", "inclusion": 3, "low": "(`airport`.`faa`)" } ] } ], "using": "gsi" } ] |
Exemplo 6: ANSI JOIN com dicas
Para junção de pesquisa e junção de índice, as dicas só podem ser especificadas no espaço-chave do lado esquerdo da junção. Para ANSI JOIN, as dicas também podem ser especificadas no espaço-chave do lado direito. Usando a mesma consulta do exemplo 1 (com a adição da dica USE INDEX):
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route USE INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
A dica USE INDEX limita o número de índices que o planejador precisa considerar para executar a união.
As dicas também podem ser especificadas no espaço de chave do lado esquerdo do ANSI JOIN.
|
1 2 3 4 5 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport USE INDEX(airport_city_country) JOIN `travel-sample` route USE INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Francisco" AND airport.country = "United States"; |
Exemplo 7: ANSI LEFT OUTER JOIN
Até agora, examinamos as junções internas. Você também pode executar LEFT OUTER JOIN simplesmente incluindo as palavras-chave LEFT ou LEFT OUTER na frente da palavra-chave JOIN na especificação da união.
Índice necessário (igual ao exemplo 1):
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
Índice opcional (igual ao exemplo 1):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(city, country) WHERE type = "airport"; |
Consulta:
|
1 2 3 4 |
SELECT airport.airportname, route.airlineid FROM `travel-sample` airport LEFT JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "Denver" AND airport.country = "United States"; |
O conjunto de resultados para essa consulta contém todos os resultados unidos, bem como qualquer documento do lado esquerdo ("airport") que não se une ao documento do lado direito ("route"), de acordo com a semântica de LEFT OUTER JOIN. Assim, você encontrará resultados que contêm apenas airport.airportname, mas não route.airlineid (que está faltando). Você também pode selecionar apenas o documento do lado esquerdo ("airport") que não se junta ao documento do lado direito ("route") adicionando um predicado IS MISSING no espaço-chave do lado direito ("route"):
|
1 2 3 4 5 |
SELECT airport.airportname, route.airlineid FROM `travel-sample` airport LEFT JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "Denver" AND airport.country = "United States" AND route.airlineid IS MISSING; |
Exemplo 8: ANSI RIGHT OUTER JOIN
O ANSI RIGHT OUTER JOIN é semelhante ao ANSI LEFT OUTER JOIN, exceto pelo fato de que preservamos o documento do lado direito se não ocorrer nenhuma junção. Podemos modificar a consulta do exemplo 7 trocando os espaços-chave do lado esquerdo e do lado direito e substituindo a palavra-chave LEFT pela palavra-chave RIGHT:
|
1 2 3 4 |
SELECT airport.airportname, route.airlineid FROM `travel-sample` route RIGHT JOIN `travel-sample` airport ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "Denver" AND airport.country = "United States"; |
Observe que, embora tenhamos trocado o aeroporto e a rota na especificação da união, o filtro na rota (agora o espaço-chave do lado esquerdo) ainda aparece na cláusula ON da união, já que a rota ainda está no lado subserviente nessa união externa.
O RIGHT OUTER JOIN é internamente convertido em LEFT OUTER JOIN.
Se uma consulta contiver várias junções, uma RIGHT OUTER JOIN só poderá ser a primeira junção especificada. Como o N1QL suporta apenas junções lineares, ou seja, o lado direito de cada junção deve ser um único espaço-chave, se RIGHT OUTER JOIN não for a primeira junção especificada, após a conversão para LEFT OUTER JOIN, o lado direito da junção conterá vários espaços-chave, o que não é suportado. Se você especificar RIGHT OUTER JOIN em qualquer posição que não seja a primeira junção, será retornado um erro de sintaxe.
Exemplo 9: ANSI JOIN usando Hash Join
O N1QL suporta dois métodos de junção para ANSI JOIN. O método de junção padrão para um ANSI JOIN é a junção de loop aninhado. A alternativa é a junção de hash. A junção de hash usa uma tabela de hash para combinar documentos de ambos os lados da junção. A junção de hash tem um lado de compilação e um lado de sondagem, em que cada documento do lado de compilação é inserido em uma tabela de hash com base nos valores da expressão equi-join do lado de compilação; subsequentemente, cada documento do lado de sondagem procura na tabela de hash com base nos valores da expressão equi-join do lado de sondagem. Se for encontrada uma correspondência, a operação de união será executada.
Em comparação com a junção de loop aninhado, a junção de hash pode ser mais eficiente quando a junção é grande, por exemplo, quando há dezenas de milhares ou mais de documentos do lado esquerdo da junção (após a aplicação de filtros). Se estiver usando a junção de loop aninhado, para cada documento do lado esquerdo, uma varredura de índice precisa ser executada no índice do lado direito. À medida que o número de documentos do lado esquerdo aumenta, a união em loop aninhado se torna menos eficiente.
Para a junção de hash, o lado menor da junção deve ser usado para criar a tabela de hash, e o lado maior da junção deve ser usado para sondar a tabela de hash. Deve-se observar que a junção de hash requer mais memória do que a junção de loop aninhado, pois é necessária uma tabela de hash na memória. A quantidade de memória necessária é proporcional ao número de documentos do lado da construção, bem como ao tamanho médio de cada documento.
A junção de hash é suportada em somente na edição enterprise. Para usar a junção de hash, uma dica USE HASH deve ser especificada no espaço de chave do lado direito do ANSI JOIN. Usando a mesma consulta do exemplo 1:
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route USE HASH(build) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
A dica USE HASH(build) direciona o planejador N1QL para executar a junção de hash para o ANSI JOIN especificado, e o espaço-chave do lado direito ("route") é usado no lado da construção da junção de hash. Observando a explicação, há um operador HashJoin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
{ "#operator": "HashJoin", "build_aliases": [ "route" ], "build_exprs": [ "cover ((`route`.`sourceairport`))" ], "on_clause": "(((`airport`.`faa`) = cover ((`route`.`sourceairport`))) and (cover ((`route`.`type`)) = \"route\"))", "probe_exprs": [ "(`airport`.`faa`)" ], "~child": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "as": "route", "covers": [ "cover ((`route`.`sourceairport`))", "cover ((`route`.`destinationairport`))", "cover ((meta(`route`).`id`))" ], "filter_covers": { "cover ((`route`.`type`))": "route" }, "index": "route_airports", "index_id": "f1f4b9fbe85e45fd", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "range": [ { "inclusion": 0, "low": "null" } ] } ], "using": "gsi" } ] } } |
O operador filho ("~child") de um operador HashJoin é sempre o lado da construção da junção de hash. Para essa consulta, é uma varredura de índice no espaço-chave "route" do lado direito.
Observe que, para acessar o documento "route", não podemos mais usar as informações do espaço-chave do lado esquerdo ("airport") para a chave de pesquisa do índice (veja as informações de "spans" na seção de explicação acima). Diferentemente da junção de loop aninhado, a varredura de índice em "route" não está mais vinculada a um documento individual do lado esquerdo e, portanto, nenhum valor do documento "airport" pode ser usado como chave de pesquisa para a varredura de índice em "route".
A dica USE HASH(build) usada na consulta acima direciona o planejador a usar o espaço-chave do lado direito como o lado de construção da junção de hash. Também é possível especificar a dica USE HASH(probe) para direcionar o planejador a usar o espaço-chave do lado direito como o lado da sonda da junção de hash.
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route USE HASH(probe) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
Observando a explicação, você encontrará o operador HashJoin:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
{ "#operator": "HashJoin", "build_aliases": [ "airport" ], "build_exprs": [ "(`airport`.`faa`)" ], "on_clause": "(((`airport`.`faa`) = cover ((`route`.`sourceairport`))) and (cover ((`route`.`type`)) = \"route\"))", "probe_exprs": [ "cover ((`route`.`sourceairport`))" ], "~child": { "#operator": "Sequence", "~children": [ { "#operator": "IntersectScan", "scans": [ { "#operator": "IndexScan3", "as": "airport", "index": "airport_city_country", "index_id": "8e782fd1b124eec3", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"San Jose\"", "inclusion": 3, "low": "\"San Jose\"" }, { "high": "\"United States\"", "inclusion": 3, "low": "\"United States\"" } ] } ], "using": "gsi" }, { "#operator": "IndexScan3", "as": "airport", "index": "airport_faa", "index_id": "c302afbf811470f5", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "null" } ] } ], "using": "gsi" } ] }, { "#operator": "Fetch", "as": "airport", "keyspace": "travel-sample", "namespace": "default" } ] } } |
O operador filho ("~child") do HashJoin é uma varredura de índice de interseção no espaço-chave do lado esquerdo do ANSI JOIN, "airport", seguido por um operador de busca.
A dica USE HASH só pode ser especificada no espaço-chave do lado direito em um ANSI JOIN. Portanto, dependendo do fato de você querer que o espaço de chave do lado direito seja o lado de compilação ou o lado de sondagem de uma junção de hash, uma dica USE HASH(build) ou USE HASH(probe) deve ser especificada no espaço de chave do lado direito.
A junção de hash só é considerada quando a dica USE HASH(build) ou USE HASH(probe) é especificada. A junção de hash requer predicados de junção de igualdade para funcionar. A junção de loop aninhado requer um índice secundário apropriado no espaço de chave do lado direito, mas a junção de hash não (uma varredura de índice primário é uma opção para a junção de hash). No entanto, a junção de hash requer mais memória do que a junção de loop aninhado, pois é necessária uma tabela de hash na memória para que a junção de hash funcione. Além disso, a junção de hash é considerada uma operação de "bloqueio", o que significa que o mecanismo de consulta deve terminar de criar a tabela de hash antes de produzir o primeiro resultado da junção. Portanto, para consultas que precisam apenas dos primeiros resultados rapidamente (por exemplo, com uma cláusula LIMIT), a junção de hash pode não ser a melhor opção.
Se uma dica USE HASH for especificada, mas uma união de hash não puder ser gerada com êxito (por exemplo, falta de predicados de união de igualdade), será considerada uma união de loop aninhado.
Exemplo 10: ANSI JOIN com várias dicas
Agora você pode especificar várias dicas para um espaço-chave no lado direito de um ANSI JOIN. Por exemplo, a dica USE HASH pode ser usada junto com a dica USE INDEX.
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route USE HASH(probe) INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
Observe que, quando várias dicas são usadas juntas, você só precisa especificar a palavra-chave "USE" uma vez, como no exemplo acima.
A dica USE HASH também pode ser combinada com a dica USE KEYS.
Exemplo 11: ANSI JOIN com várias uniões
ANSI JOIN podem ser encadeados. Por exemplo:
Índices necessários (índice route_airports igual ao do exemplo 1):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX airline_iata ON `travel-sample`(iata) WHERE type = "airline"; |
Índice opcional (igual ao exemplo 1):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(city, country) WHERE type = "airport"; |
Consulta:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `travel-sample` airport INNER JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" INNER JOIN `travel-sample` airline ON route.airline = airline.iata AND airline.type = "airline" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
Como não há uma dica USE HASH especificada na consulta, a explicação deve mostrar dois operadores NestedLoopJoin.
Você pode combinar a junção de hash com a junção de loop aninhado adicionando a dica USE HASH a qualquer uma das junções em uma cadeia de ANSI JOINs.
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `travel-sample` airport INNER JOIN `travel-sample` route ON airport.faa = route.sourceairport AND route.type = "route" INNER JOIN `travel-sample` airline USE HASH(build) ON route.airline = airline.iata AND airline.type = "airline" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
ou
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `travel-sample` airport INNER JOIN `travel-sample` route USE HASH(probe) ON airport.faa = route.sourceairport AND route.type = "route" INNER JOIN `travel-sample` airline ON route.airline = airline.iata AND airline.type = "airline" WHERE airport.type = "airport" AND airport.city = "San Jose" AND airport.country = "United States"; |
A explicação visual para a última consulta é a seguinte:
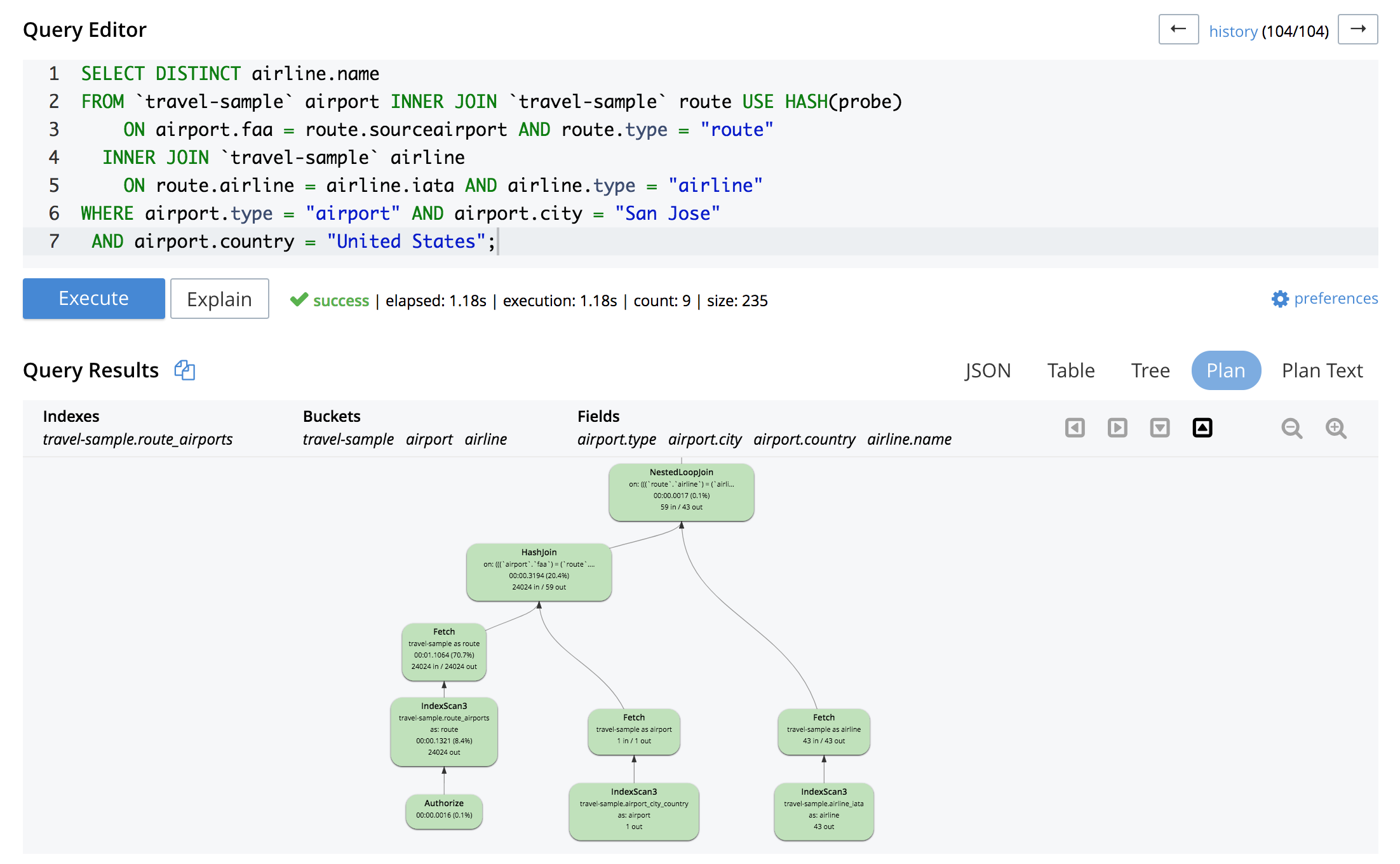
Conforme mencionado anteriormente, o N1QL suporta apenas junções lineares, ou seja, o lado direito de cada junção deve ser um espaço-chave.
Exemplo 12: ANSI JOIN envolvendo matrizes do lado direito
Embora o ANSI JOIN venha do padrão SQL, como o Couchbase N1QL lida com documentos JSON e a matriz é um aspecto importante do JSON, estendemos o suporte do ANSI JOIN também para matrizes.
Para obter exemplos de manuseio de matriz, crie um bucket "default" e insira os seguintes documentos:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO default (KEY,VALUE) VALUES("test11_ansijoin", {"c11": 1, "c12": 10, "a11": [ 1, 2, 3, 4 ], "type": "left"}), VALUES("test12_ansijoin", {"c11": 2, "c12": 20, "a11": [ 3, 3, 5, 10 ], "type": "left"}), VALUES("test13_ansijoin", {"c11": 3, "c12": 30, "a11": [ 3, 4, 20, 40 ], "type": "left"}), VALUES("test14_ansijoin", {"c11": 4, "c12": 40, "a11": [ 30, 30, 30 ], "type": "left"}); INSERT INTO default (KEY,VALUE) VALUES("test21_ansijoin", {"c21": 1, "c22": 10, "a21": [ 1, 10, 20], "a22": [ 1, 2, 3, 4 ], "type": "right"}), VALUES("test22_ansijoin", {"c21": 2, "c22": 20, "a21": [ 2, 3, 30], "a22": [ 3, 5, 10, 3 ], "type": "right"}), VALUES("test23_ansijoin", {"c21": 2, "c22": 21, "a21": [ 2, 20, 30], "a22": [ 3, 3, 5, 10 ], "type": "right"}), VALUES("test24_ansijoin", {"c21": 3, "c22": 30, "a21": [ 3, 10, 30], "a22": [ 3, 4, 20, 40 ], "type": "right"}), VALUES("test25_ansijoin", {"c21": 3, "c22": 31, "a21": [ 3, 20, 40], "a22": [ 4, 3, 40, 20 ], "type": "right"}), VALUES("test26_ansijoin", {"c21": 3, "c22": 32, "a21": [ 4, 14, 24], "a22": [ 40, 20, 4, 3 ], "type": "right"}), VALUES("test27_ansijoin", {"c21": 5, "c22": 50, "a21": [ 5, 15, 25], "a22": [ 1, 2, 3, 4 ], "type": "right"}), VALUES("test28_ansijoin", {"c21": 6, "c22": 60, "a21": [ 6, 16, 26], "a22": [ 3, 3, 5, 10 ], "type": "right"}), VALUES("test29_ansijoin", {"c21": 7, "c22": 70, "a21": [ 7, 17, 27], "a22": [ 30, 30, 30 ], "type": "right"}), VALUES("test30_ansijoin", {"c21": 8, "c22": 80, "a21": [ 8, 18, 28], "a22": [ 30, 30, 30 ], "type": "right"}); |
Em seguida, crie os seguintes índices:
|
1 2 |
CREATE INDEX default_ix_left on default(c11, DISTINCT a11) WHERE type = "left"; CREATE INDEX default_ix_right on default(c21, DISTINCT a21) WHERE type = "right"; |
Quando o predicado de união envolve uma matriz no lado direito do ANSI JOIN, você precisa criar um índice de matriz no espaço-chave do lado direito.
Consulta:
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM default b1 JOIN default b2 ON b2.c21 = b1.c11 AND ANY v IN b2.a21 SATISFIES v = b1.c12 END AND b2.type = "right" WHERE b1.type = "left"; |
Observe que parte da condição de união é uma cláusula ANY que especifica que o campo do lado esquerdo b1.c12 pode corresponder a qualquer elemento da matriz do lado direito b2.a21. Para que essa união funcione corretamente, precisamos de um índice de matriz em b2.a21, por exemplo, o índice default_ix_right criado acima.
O plano de explicação mostra um NestedLoopJoin, com o operador filho sendo uma varredura distinta no índice de matriz default_ix_right.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
{ "#operator": "NestedLoopJoin", "alias": "b2", "on_clause": "((((`b2`.`c21`) = (`b1`.`c11`)) and any `v` in (`b2`.`a21`) satisfies (`v` = (`b1`.`c12`)) end) and ((`b2`.`type`) = \"right\"))", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "DistinctScan", "scan": { "#operator": "IndexScan3", "as": "b2", "index": "default_ix_right", "index_id": "ef4e7fa33f33dce", "index_projection": { "primary_key": true }, "keyspace": "default", "namespace": "default", "nested_loop": true, "spans": [ { "exact": true, "range": [ { "high": "(`b1`.`c11`)", "inclusion": 3, "low": "(`b1`.`c11`)" }, { "high": "(`b1`.`c12`)", "inclusion": 3, "low": "(`b1`.`c12`)" } ] } ], "using": "gsi" } }, { "#operator": "Fetch", "as": "b2", "keyspace": "default", "namespace": "default", "nested_loop": true } ] } } |
Exemplo 13: ANSI JOIN envolvendo matrizes do lado esquerdo
Se o ANSI JOIN envolver uma matriz no lado esquerdo, haverá duas opções para realizar a união.
Opção 1: usar UNNEST
Use a cláusula UNNEST para achatar a matriz do lado esquerdo antes de realizar a união.
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM default b1 UNNEST b1.a11 AS ba1 JOIN default b2 ON ba1 = b2.c21 AND b2.type = "right" WHERE b1.c11 = 2 AND b1.type = "left"; |
Após o UNNEST, a matriz se torna campos individuais e a união subsequente é como um ANSI JOIN "regular" com campos de ambos os lados.
Opção 2: usar a cláusula IN
Como alternativa, use a cláusula IN como condição de união.
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM default b1 JOIN default b2 ON b2.c21 IN b1.a11 AND b2.type = "right" WHERE b1.c11 = 2 AND b1.type = "left"; |
A cláusula IN é satisfeita quando qualquer elemento da matriz no espaço-chave do lado esquerdo ("b1.a11") corresponde ao campo do lado direito ("b2.c21").
Observe que há uma diferença semântica entre as duas opções. Quando há duplicatas na matriz, a opção UNNEST não se importa com as duplicatas e achatará os documentos do lado esquerdo para o mesmo número de documentos que o número de elementos na matriz, portanto, pode produzir resultados duplicados; a opção IN-clause não produzirá resultados duplicados se houver elementos duplicados na matriz. Além disso, quando LEFT OUTER JOIN é executado, pode haver um número diferente de documentos preservados devido ao achatamento da matriz com a opção UNNEST. Assim, o usuário é aconselhado a escolher a opção que reflita a semântica necessária para a consulta.
Exemplo 14: ANSI JOIN envolvendo matrizes em ambos os lados
Embora seja incomum, é possível executar um ANSI JOIN quando os dois lados da união são matrizes. Nesses casos, você pode usar uma combinação das técnicas descritas acima. Use o índice de matriz para lidar com a matriz do lado direito e use a opção UNNEST ou a opção IN-clause para lidar com a matriz do lado esquerdo.
Opção 1: usar a cláusula UNNEST
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM default b1 UNNEST b1.a11 AS ba1 JOIN default b2 ON b2.c21 = b1.c11 AND ANY v IN b2.a21 SATISFIES v = ba1 END AND b2.type = "right" WHERE b1.type = "left"; |
Opção 2: usar a cláusula IN
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM default b1 JOIN default b2 ON b2.c21 = b1.c11 AND ANY v IN b2.a21 SATISFIES v IN b1.a11 END AND b2.type = "right" WHERE b1.type = "left"; |
Novamente, as duas opções não são semanticamente idênticas e podem gerar resultados diferentes. Escolha a opção que reflete a semântica desejada.
Exemplo 15: migração de junção de pesquisa
O N1QL continuará a oferecer suporte à junção de pesquisa e junção de índice para compatibilidade com versões anteriores; no entanto, você não pode misturar ANSI JOIN com junção de pesquisa ou junção de índice na mesma consulta. Você pode converter suas consultas existentes do uso de lookup join e index join para a sintaxe ANSI JOIN. Este exemplo mostra como converter uma união de pesquisa em sintaxe ANSI JOIN.
Crie o seguinte índice para acelerar a consulta (igual ao exemplo 1):
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
Essa é uma consulta que usa a sintaxe de junção de pesquisa (observe a cláusula ON KEYS):
|
1 2 3 4 |
SELECT airline.name FROM `travel-sample` route JOIN `travel-sample` airline ON KEYS route.airlineid WHERE route.type = "route" AND route.sourceairport = "SFO" AND route.destinationairport = "JFK"; |
Na junção de pesquisa, o lado esquerdo da junção ("rota") precisa produzir chaves de documento para o lado direito da junção ("companhia aérea"), o que é obtido pela cláusula ON KEYS. A condição de união (que está implícita na sintaxe) é route.airlineid = meta(airline).idportanto, a mesma consulta pode ser especificada usando a sintaxe ANSI JOIN:
|
1 2 3 4 |
SELECT airline.name FROM `travel-sample` route JOIN `travel-sample` airline ON route.airlineid = meta(airline).id WHERE route.type = "route" AND route.sourceairport = "SFO" AND route.destinationairport = "JFK"; |
Neste exemplo, a cláusula ON KEYS contém uma única chave de documento. É possível que a cláusula ON KEYS contenha uma matriz de chaves de documento e, nesse caso, a cláusula ON convertida terá a forma de uma cláusula IN em vez de uma cláusula de igualdade. Vamos supor que cada documento de rota tenha uma matriz de chaves de documento para companhia aérea e, em seguida, a cláusula ON KEYS original:
|
1 |
ON KEYS route.airlineids |
pode ser convertido para:
|
1 |
ON meta(airline).id IN route.airlineids |
Exemplo 16: migração de união de índices
Este exemplo mostra como converter uma união de índices na sintaxe ANSI JOIN.
Índice necessário (igual ao exemplo 3):
|
1 |
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type = "route"; |
Índice opcional (igual ao exemplo 3):
|
1 |
CREATE INDEX airline_name ON `travel-sample`(name) WHERE type = "airline"; |
Consulta usando a sintaxe de união de índices (observe a cláusula ON KEY ... FOR ...):
|
1 2 3 4 |
SELECT count(*) FROM `travel-sample` airline JOIN `travel-sample` route ON KEY route.airlineid FOR airline WHERE airline.type = "airline" AND route.type = "route" AND airline.name = "United Airlines"; |
Na união de índices, a chave do documento para o lado esquerdo ("airline") é usada para sondar um índice em uma expressão ("route.airlineid" que aparece na cláusula ON KEY) do lado direito ("route") que corresponde à chave do documento para o lado esquerdo ("airline" que aparece na cláusula FOR). A condição de união (implícita na sintaxe) é route.airlineid = meta(airline).idportanto, a mesma consulta pode ser especificada usando a sintaxe ANSI JOIN:
|
1 2 3 4 |
SELECT count(*) FROM `travel-sample` airline JOIN `travel-sample` route ON route.airlineid = meta(airline).id WHERE airline.type = "airline" AND route.type = "route" AND airline.name = "United Airlines"; |
Exemplo 17: ANSI NEST
O Couchbase N1QL oferece suporte à operação NEST. Anteriormente, a operação NEST podia ser feita usando lookup nest ou index nest, semelhante a lookup join e index join, respectivamente. Com o suporte a ANSI JOIN, a operação NEST também pode ser feita usando sintaxe semelhante, ou seja, usando a cláusula ON em vez das cláusulas ON KEYS (lookup nest) ou ON KEY ... FOR ... (index nest). Essa nova variante é chamada de ANSI NEST.
Índice necessário (índice route_airports igual ao do exemplo 1, índice route_airline_distance igual ao do exemplo 4):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX route_airline_distance ON `travel-sample`(airline, distance) WHERE type = "route"; |
Índice opcional:
|
1 |
CREATE INDEX airline_country_iata_name ON `travel-sample`(country, iata, name) WHERE type = "airline"; |
Consulta:
|
1 2 3 4 |
SELECT airline.name, ARRAY {"destination": r.destinationairport} FOR r in route END as destinations FROM `travel-sample` airline NEST `travel-sample` route ON airline.iata = route.airline AND route.type = "route" AND route.sourceairport = "SFO" WHERE airline.type = "airline" AND airline.country = "United States"; |
Como você pode ver, a sintaxe do ANSI NEST é muito semelhante à do ANSI JOIN. No entanto, há uma propriedade peculiar para o nest. Por definição, a operação nest cria uma matriz de todos os documentos correspondentes do lado direito para cada documento do lado esquerdo, o que significa que a referência ao espaço-chave do lado direito, "route" nessa consulta, tem um significado diferente, dependendo de onde está a referência. A cláusula ON é avaliada como parte da operação NEST e, portanto, as referências a "route" estão fazendo referência a um único documento. Por outro lado, as referências na cláusula de projeção ou na cláusula WHERE são avaliadas após a operação NEST e, portanto, as referências a "route" significam a matriz aninhada e, portanto, devem ser tratadas como uma matriz. Observe que a cláusula de projeção da consulta acima tem uma construção ARRAY com uma cláusula FOR para acessar cada documento individual dentro da matriz (ou seja, a referência a "route" está agora em um contexto de matriz).
Resumo
O ANSI JOIN oferece muito mais flexibilidade nas operações de junção no Couchbase N1QL, em comparação com a junção de pesquisa e a junção de índice anteriormente suportadas, ambas as quais exigem a junção somente na chave do documento. Os exemplos acima mostram várias maneiras de usar o ANSI JOIN em consultas. Como o ANSI JOIN é amplamente utilizado no mundo relacional, o suporte para ANSI JOIN no Couchbase N1QL deve facilitar muito a migração de aplicativos de um banco de dados relacional para o Couchbase N1QL.
finalmente :)
Exemplos incríveis!