JMH (Java Microbenchmarking Harness) tornou-se uma das minhas ferramentas mais valiosas para quantificar (e, em última análise, justificar) uma otimização de desempenho dentro do Couchbase Java SDK e seus projetos relacionados. Como vejo muitos usuários e clientes tendo dificuldades com questões semelhantes, achei que seria uma boa ideia mostrar como você pode usar o JMC (Java Mission Control) em combinação com o JMH para orientar suas decisões de teste de otimização de desempenho de perfil e JMC usando dados reais em vez de suposições.
Você pode simplesmente ler e examinar o código-fonte ao lado, mas se quiser reproduzir o que vou mostrar, precisará de um Oracle JDK recente (para o JMH, estou usando o 1.8.0_51). Além disso, não mostrarei todos os detalhes menores, como importar um projeto para seu IDE ou algo semelhante. Se você tiver dificuldades com os conceitos básicos de criação de perfil de desempenho do Java, esta publicação provavelmente não é para você imediatamente.
O problema com a maioria dos aplicativos e bibliotecas reais é que não há nenhum problema óbvio. Se você encontrar algo, der um tapinha nas costas e for consertá-lo, essas chances são raras. Muitas vezes, você precisa fazer vários pequenos aprimoramentos para obter melhores resultados. No Java SDK, nós nos preocupamos em aumentar a taxa de transferência e, ao mesmo tempo, minimizar a latência o máximo possível. Como essas duas propriedades não se amam particularmente, há apenas algumas coisas que você pode fazer para que ambas fiquem mais felizes ao mesmo tempo:
- Reduzir a quantidade de CPU que seu aplicativo precisa para fazer cálculos
- Minimizar a contenção e os pontos de sincronização
- Evite alocações de objetos para que o GC faça menos
Neste exemplo, você verá o número 3 (e um) em ação. Estou executando o seguinte código no projeto core-io:
Se você já assistiu a algumas de minhas palestras, sempre digo às pessoas que algo assim não é um benchmark adequado - então por que faço isso aqui? A grande diferença é que, como usuário, você está fazendo um benchmark do Couchbase como um todo, essa não é uma carga de trabalho realista que imita o seu sistema de produção. Como desenvolvedor de bibliotecas, quero encontrar caminhos de código quentes e torná-los mais rápidos, portanto, executar o mesmo código repetidamente expõe melhor esses caminhos no profiler da JVM (Java).
Quando executo esse código em meu nó local do Couchbase Server, obtenho cerca de 9 mil operações/s. Não estou interessado em aumentar a taxa de transferência neste momento, estou tentando reduzir as alocações de objetos no caminho do código quente em primeiro lugar. Ao iniciar o JMC e apontá-lo para a minha JVM por meio do JFR (Java Flight Recorder) e, em seguida, deixar a máquina sozinha por 5 minutos enquanto faço o perfil, obtive o seguinte:
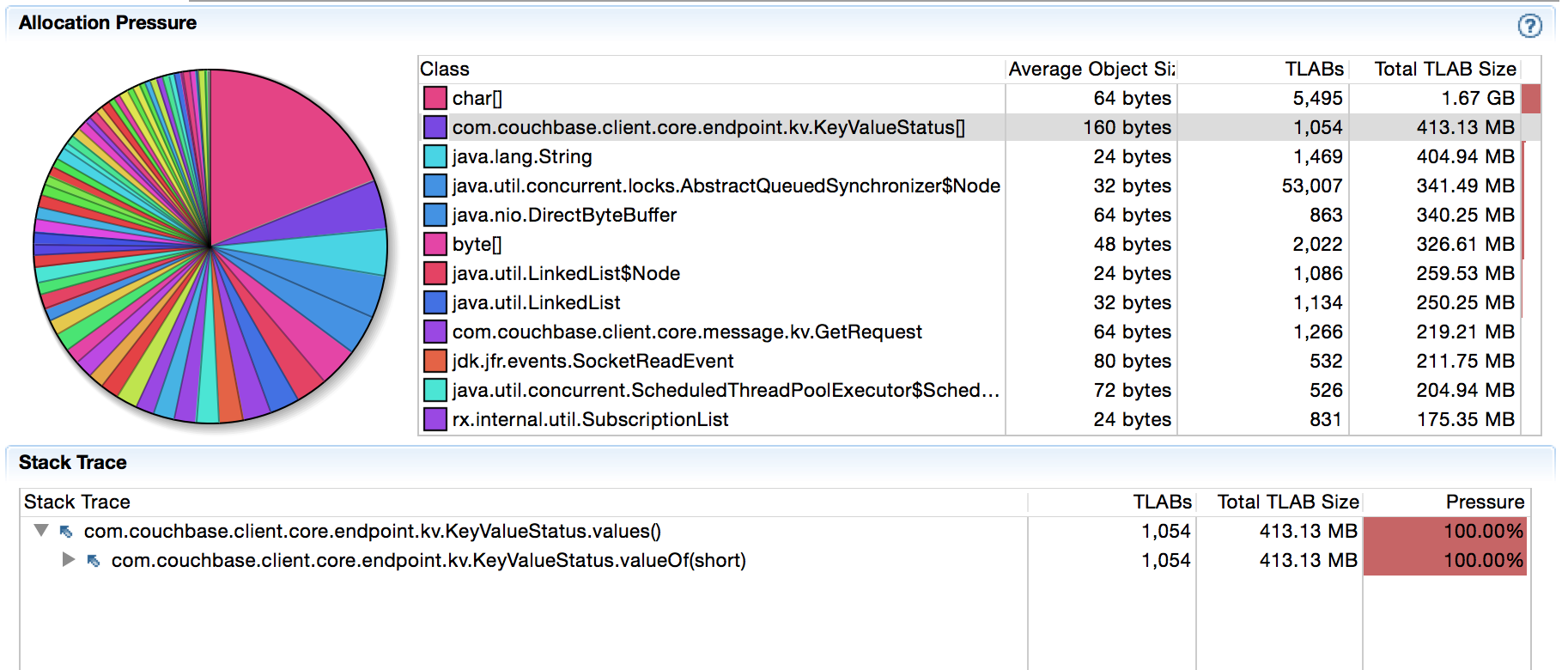
Há 400 MB alocados em 5 minutos para objetos KeyValueStatus[]. Isso pode não ser óbvio para você, mas sei que recentemente alteramos algo nesse caminho de código (consulte aqui) e nunca vi esse tipo específico de alocação aparecer antes. Após uma rápida investigação, ficou claro que o suspeito está no seguinte caminho de código (observe como o JFR nos guia para o lugar certo):
Toda vez que chega uma resposta, nós a comparamos com o enum KeyValueStatus para definir o status de resposta adequado. Um dos meus colegas fez com que o código ficasse bonito durante a refatoração, mas também introduziu sutilmente a sobrecarga de GC. Como mostram as informações de criação de perfil, values() sempre cria uma matriz para que possamos iterar sobre ela e encontrar o código correspondente. Não é muito, mas vai se acumulando com o tempo. Mas o mais importante: é um lixo desnecessário.
Acontece que algumas respostas são (muito) mais prováveis de acontecer do que outras, portanto, podemos otimizar para o caso comum (sempre uma boa ideia). Não vou aborrecê-lo com todos os detalhes de baixo nível, mas, no caso do GET, normalmente você obterá um SUCCESS se o documento existir ou um NOT_FOUND se o documento não existir. Portanto, uma coisa que podemos fazer é o seguinte:
Ao alterar o código e executar o JFR novamente, as alocações de matriz desapareceram:
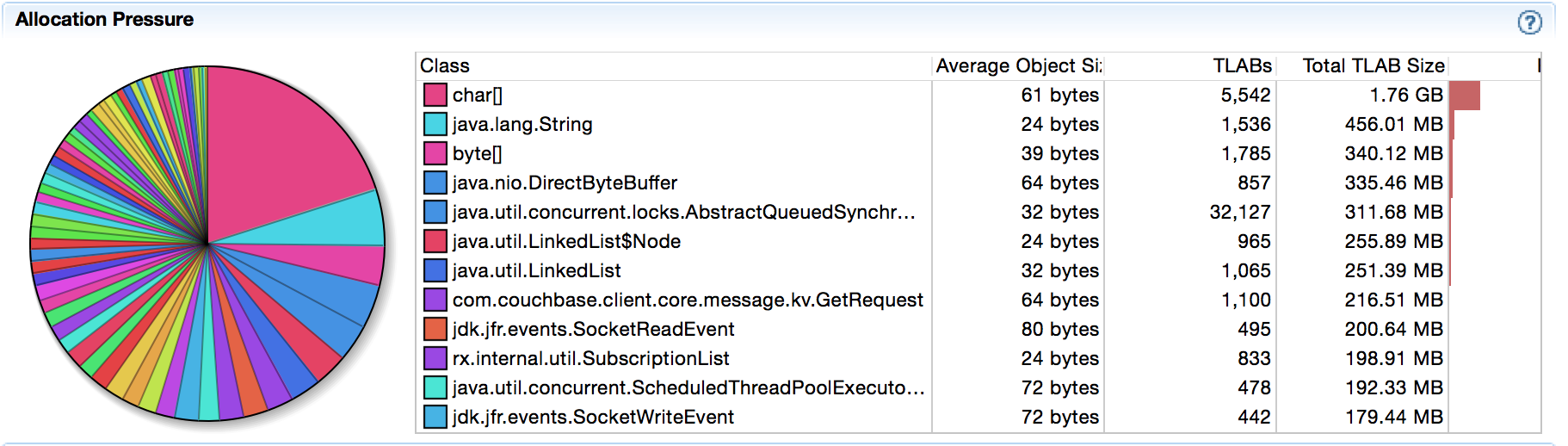
Na maioria das vezes, os desenvolvedores tendem a parar nesse ponto, mas eu recomendo que você continue lendo. O fato de termos evitado as alocações de array (o que é bom) não significa que seja mais rápido, certo? Em geral, acredita-se que sim, mas já fui surpreendido muitas vezes no passado para acreditar nisso. Mesmo que estejamos certos, é bom fazer um microbenchmark rápido do JMH para descobrir isso. Isso também nos permitirá quantificar quaisquer melhorias para o N°1 acima, e não apenas para o N°3, que já verificamos.
O JMH faz parte do projeto OpenJDK e não é muito difícil de usar. Você pode configurar um projeto usando o comando mvn archetype:generate que pode ser encontrado em sua página inicial. Depois de ter o esqueleto do projeto, você tem duas opções: adicionar o Java SDK como uma dependência (ele será sombreado automaticamente) ou simplesmente copiar o enum. Dependendo do tamanho de seus testes e do que deseja testar, você deve escolher uma das duas opções. Como nossos testes atuais são independentes, podemos copiar o ENUM para o projeto. Isso tem a vantagem de podermos modificá-lo à medida que avançamos, adicionar novos métodos para testar coisas e coisas do gênero.
Copiei a classe KeyValueStatus da versão 2.2.0 e alterei o código para que possamos chamar duas variantes ao mesmo tempo:
Agora podemos escrever nosso benchmark JMH (simples):
Em seguida, compilamos o código e o executamos na linha de comando. Primeiro, execute "mvn clean install" e, em seguida, inicie-o com "java -jar target/benchmarks.jar -wi 10 -f1 -i 10 -bm avgt -tu ns".
Se isso for muito complicado para você, significa apenas que queremos medir a latência média em nanossegundos e realizar 10 iterações de aquecimento, bem como 10 iterações medidas em uma bifurcação. Curioso? Aqui estão os resultados:
Todas as operações estão no intervalo inferior de nanossegundos, portanto, a JVM faz um bom trabalho de otimização do loop, mas não consegue superar as operações simples de comparação e retorno. Como o código otimizado tem um fallback, você pode ver no código 134 que ele retorna ao loop. O que você pode ver além disso nas execuções "originais" é que também importa onde os elementos são colocados no ENUM depois que você faz o loop sobre ele. 0 e 1 estão praticamente na parte superior, enquanto 134 está na parte inferior. Portanto, até mesmo a reordenação para o caso comum faz sentido.
Portanto, a esta altura, estamos bastante convencidos de que faz sentido implementar essa alteração. Ela reduz as alocações e é mais rápida de executar. Além disso, ela não torna o código muito mais complexo. Na prática, porém, precisamos de mais códigos no caminho otimizado, já que esses dois não são suficientes. Da longa lista enum, eles são:
- SUCESSO
- ERR_NOT_FOUND
- ERR_EXISTS
- ERR_NOT_MY_VBUCKET
- ERR_BUSY
- ERR_TOO_BIG
- ERR_TEMP_FAIL
Portanto, resta uma última pergunta a ser respondida: devemos usar if/elseif para eles ou um simples bloco switch()? Isso tem alguma importância? Mais um benchmark JMH:
E aqui estão os resultados:
Agora, incluímos todos os três parâmetros em nosso código de caminho rápido, de modo que não há mais nenhum outlier. Além disso, você pode ver que não há nenhuma diferença prática para o nosso caso de uso. Portanto, tanto o caso quanto o if/else funcionam bem e podem ser escolhidos com base na preferência e na clareza do código.
É isso por hoje! Reduzir as alocações de objetos e tornar o código mais rápido é um efeito colateral do uso de ferramentas como JMH e JFR para medições informadas, em vez de suposições. Feliz hacking e sem condições de corrida para todos vocês.
Belo artigo!
Minha primeira tentativa teria sido apenas armazenar em cache o resultado de values() como VALUES no KeyValueStatus2 e, em uma segunda etapa, reordenar os valores de enum para o caso comum.
Em Meus resultados Isso está apenas 1 ou 2 ns atrás de sua versão para o caso comum, mas é um pouco melhor para o caso extremo - talvez um candidato adicional à otimização ;-)
Olá, Thomas,
Ótima ideia - obrigado pelo feedback! Vou tentar - talvez também reordená-los de acordo com a frequência com que aparecem no campo.
Que legal! Alguma chance de eu conseguir a gravação? :)