이 블로그 게시물에서는 곧 출시될 새로운 기능을 소개합니다. 카우치베이스 서버 버전 4.5 (코드명 왓슨), 이제 베타.
우리는 하위 문서 API (줄여서 하위 문서).
편집: 이 블로그 게시물은 4.5 베타 및 Java SDK의 업데이트로 편집되었습니다. 2.2.6.
Couchbase 4.5의 다른 기능에 대한 자세한 내용은 Don Pinto의 블로그 게시물을 참조하세요. 개발자 미리보기 및 베타.
어떤 내용인가요?
하위 문서는 서버 측 기능으로, 하위 문서에 추가되는 멤캐시드 카우치베이스를 구동하는 프로토콜 키-값 연산. 단일 작업에서 작동하는 몇 가지 작업을 추가합니다. JSON 문서와 비슷하지만, 문서의 전체 내용을 강제로 검색하는 대신 경로 를 검색하거나 변경하려는 JSON 안에 넣습니다.
다음 시나리오를 통해 그 이유를 설명해 드리겠습니다. ID 아래에 저장된 대용량(매우 큰) JSON 문서가 있다고 가정해 보겠습니다. K 를 추가합니다. 문서 내부의 사전에서 sub 이 있습니다. 일부 필드를 업데이트할 수 있습니다. Couchbase 4.1에서는 어떻게 업데이트할 수 있나요?
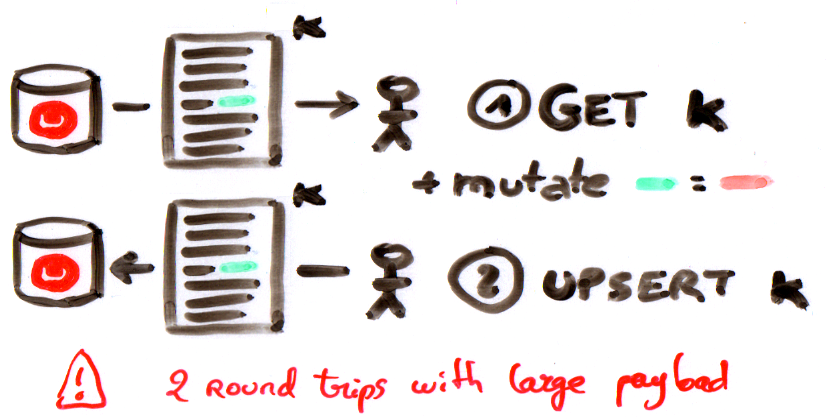
맞습니다. get(k) 을 사용하여 전체 문서의 내용을 로컬에서 수정한 다음 업서트 (또는 대체). 문서의 작은 부분에만 관심이 있을 때 네트워크를 통해 대용량 문서 전체를 전송할 뿐만 아니라 두 번 전송!
그리고 하위 문서 API를 사용하면 이러한 경우 더 간결한 작업이 가능합니다. 문서에서 수행하려는 연산을 선택하고 키, JSON 내부의 경로, 선택적으로 해당 연산에 사용할 값을 제공하면 됩니다. 짜잔!
이전 예제에서는 경로 는 "sub.value". 이는 매우 자연스럽고 쿼리 언어에서 사용되는 경로 구문과 일치합니다, N1QL. 축척에 맞춰 그려지지 않은 실제 모습은 다음과 같습니다.)
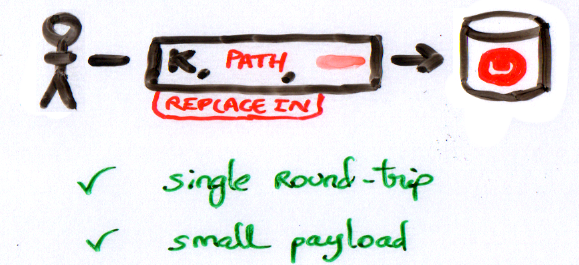
메시지는 실제로 몇 바이트에 불과하므로 원본을 둘러싼 JSON 문서가 클수록 더 큰 이점을 얻을 수 있습니다.
클라이언트 API
이제 여러분의 관심을 끌 수 있을 것 같습니다. 그렇다면 제공되는 작업은 무엇이며 API는 어떻게 생겼을까요?
Java API의 예를 들어 보겠습니다. 2.2.6 Java SDK.
각 예제에 대해 "하위 문서" JSON 문서가 데이터베이스에 존재하며 다음과 같은 내용을 담고 있습니다:
|
1 2 3 4 5 6 7 8 9 |
{ "fruits": [ "apple", "banana", "ananas" ], "sub": { "value": "someString", "bool": false }, "counter": 1, "junk": [ ... ] //a very very long array } |
또한 버킷 인스턴스입니다, 버킷를 사용할 수 있습니다.
조회 작업
JSON 내부의 변이에 대해 이야기하지 않더라도 문서 깊숙이 숨겨진 하나의 값만 읽고 싶을 때가 있습니다. 또는 단순히 항목이 있는지 확인하고 싶을 때도 있습니다. 서브도큐먼트는 두 가지 연산(get 그리고 존재)를 통해 사용할 수 있으며, 이를 위해 다음을 통해 제공됩니다. bucket.lookupIn(String key) 메서드를 사용합니다.
그리고 룩업인 메서드는 실제로 단일 JSON 문서("키")를 사용하여 수행하려는 연산을 유창하게 설명할 수 있습니다. 전체 조회 사양 집합을 준비했으면 빌더의 호출을 통해 연산을 실행할 수 있습니다. 실행() 메서드를 사용합니다. 물론 단일 조회에도 사용할 수 있습니다.
이 메서드는 문서 조각 를 반환하여 결과를 나타냅니다. 다중 조회는 문서 수준 오류가 발생하지 않는 한(즉, 문서가 존재하지 않거나 JSON이 아닌 경우) 항상 이러한 결과를 반환합니다.
다음을 호출하여 각 작업의 개별 결과를 얻을 수 있습니다. result.content(문자열 경로) 또는 result.content(int operationIndex) (동일한 경로를 대상으로 하는 연산이 여러 개 있는 경우, 이 경우 전자는 항상 첫 번째 연산 결과를 반환합니다). 오류가 발생하면 적절한 하위 클래스인 하위 문서 예외. 그렇지 않은 경우 값(또는 존재).
또한 존재 메서드는 콘텐츠와 유사하지만 결과 객체에 해당 경로/색인에 대한 결과가 포함되어 있고 해당 연산이 성공한 경우에만 참을 반환합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
DocumentFragment result = bucket .lookupIn("subdoc") .get("sub.value") .exists("fruits") .exists("sub.foo") .execute(); String subValue = result.content("sub.value", String.class); boolean fruitsExist = result.content("fruits", Boolean.class); boolean fooExist = bucket.exists("sub.foo"); System.out.println(subValue + ", " + fruitsExist + ", " + foExist); |
위의 코드가 인쇄됩니다:
|
1 |
someString, true, false |
돌연변이 연산
돌연변이 연산에는 더 다양한 종류가 있습니다. 일부는 배열을 처리하도록 맞춤화되어 있고, 다른 일부는 사전을 처리하는 데 더 적합합니다.
다시 한 번 특정 JSON 문서의 돌연변이를 대상으로 하는 빌더를 다음을 통해 제공합니다. bucket.mutateIn(String key). 수행하려는 작업을 체인으로 연결하고 최종적으로 다음을 호출합니다. 실행() 를 사용하여 일련의 돌연변이를 수행합니다.
돌연변이는 전체 돌연변이 집합을 적용하기 전에 제공된 CAS를 현재 CAS와 비교하여 동봉 문서의 CAS를 고려할 수 있습니다. 이렇게 하려면 다음을 호출하여 확인할 CAS를 제공하세요. .withCas(긴 cas) 를 빌더 체인에 한 번 입력합니다.
기타 와 함께 메서드(한 번만 호출하면 됨)는 다음과 같습니다:
withDurability(PersistTo p, ReplicateTo r)를 사용하면 전체 돌연변이 집합에 대한 내구성 제약을 관찰할 수 있습니다.withExpiry(int ttl)를 사용하면 문서가 성공적으로 변경될 때 문서에 만료일을 지정할 수 있습니다.
또한 일부 변형을 사용하면 더 깊은 객체를 만들 수 있습니다(예: 경로에 항목 만들기). newDict.sub.entry그럼에도 불구하고 newDict 그리고 sub 존재하지 않음). 이는 createParents 매개변수를 추가할 수 있습니다.
위의 예를 들어 몇 가지 돌연변이 연산을 사용하면 다음과 같은 작업을 효율적으로 수행할 수 있습니다:
- 과일 교체
아나나스(틀린 프랑스어 단어)를 사용하여파인애플. - 새 과일을 추가합니다,
배에서 앞 과일 배열의 - 에 새 항목을 추가합니다.
sub호출새로운 가치. - 증가
카운터의 델타로100. - 제거
정크큰 배열. - cbserver가 마스터의 디스크에 데이터가 기록되었음을 확인할 때까지 기다립니다.
- 서버의 CAS가 아닌 경우 모두 중단
1234.
Java SDK를 사용하여 이를 수행하는 방법은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
boolean createParents = false; DocumentFragment result = bucket .mutateIn("subdoc") .replace("fruits[2]", "pineapple") .arrayPrepend("fruits", "pear", createParents) .insert("sub.newValue", "theNewValue", createParents) .counter("counter", 100L, createParents) .remove("junk") .withDurability(PersistTo.MASTER, ReplicateTo.NONE) .withCas(1234L) .execute(); |
기타 사용 가능한 돌연변이 연산은 다음과 같습니다:
업서트arrayInsert(특정 인덱스에 배열에 값을 삽입하는 데 특화됨)배열 추가(배열 끝에 값을 삽입하는 데 특화됨)- arrayInsertAll (arrayInsert와 동일하지만 컬렉션의 각 요소를 배열에 삽입)
- arrayPrependAll (arrayPrepend와 동일하지만 컬렉션의 각 요소를 배열 앞에 추가)
- arrayAppendAll (arrayAppend와 동일하지만 컬렉션의 각 요소를 배열의 뒤쪽에 추가)
배열 추가 고유(배열에 값이 없는 경우 배열에 값을 삽입하는 데 특화되어 있음)
이 5가지 변형을 적용한 후 데이터베이스에서 문서가 어떻게 보이는지는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 |
{ "fruits": [ "pear", "apple", "banana", "pineapple" ], "sub": { "value": "someString", "bool": false, "newValue": "theNewValue" }, "counter": 101 } |
다중 조회를 수행할 때와 달리, 변이 중 하나라도 실패하면 전체 작업 집합을 건너뛰고 변이가 수행되지 않습니다. 이 경우 다중 돌연변이 예외 를 클릭하면 첫 번째 실패한 작업의 인덱스(및 해당 오류 상태)를 확인할 수 있습니다.
오류 처리
각 하위 문서 작업은 하위 문서 관련 오류로 이어질 수 있습니다. 주어진 키에 해당하는 문서가 JSON이 아닌 경우 어떻게 해야 할까요? 존재하지 않는 경로를 제공하면 어떻게 되나요? 또는 경로에 배열이 아닌 요소의 배열 인덱스가 포함된 경우(예. sub[1])?
모든 하위 문서별 오류에는 해당 하위 문서에 해당하는 응답 상태 의 전용 서브클래스와 Java SDK의 하위 문서 예외. 이러한 예외는 하위 문서용 API를 제공하는 SDK에서 일관되게 적용됩니다:
Java SDK의 전체 목록은 다음과 같습니다:
- PathNotFoundException
- 경로 존재 예외
- NumberTooBigException
- PathTooDeepException
- 경로 불일치 예외
- ValueTooDeepException
- 델타투빅 예외
- CannotInsertValueException
- 경로 유효하지 않은 예외
- DocumentNotJsonException*
- DocumentTooDeepException*
- 다중 돌연변이 예외*
마지막 3개는 문서 수준(개별 경로를 고려하지 않고 전체 문서에 적용됨)이므로 항상 빌더가 직접 던져주게 됩니다. 실행() 메서드.
나머지는 호출할 때 던질 수도 있습니다. 문서 조각's 콘텐츠 메서드를 사용하여 여러 조회 작업을 지정한 경우입니다.
이전 섹션에서 설명했듯이, 하나 이상의 뮤트 작업이 실패하는 여러 개의 뮤트 작업은 다중 돌연변이 예외 가 던져지는 것을 방지합니다. 이 예외에는 첫 번째 실패 인덱스() 그리고 첫 번째 실패 상태() 메서드를 사용하여 전체 작업 실패의 원인이 된 사양에 대한 정보를 얻을 수 있습니다.
결론
이 새로운 기능의 훌륭한 사용 사례를 찾아보시고 마음에 드셨으면 좋겠습니다! 그러니 지금 바로 Couchbase 4.5 베타API를 사용해 보시고, 주저하지 마세요. 피드백!
그동안 행복한 코딩! – Java SDK 팀
게시글을 작성해 주셔서 감사합니다. 하지만 배열 처리에 관한 질문이 있습니다: 배열의 위치 외에 배열 요소를 주소 지정할 수 있으므로 하위 문서의 ID를 사용하여 요소에 액세스 할 수 없습니까?
이 코드를 사용하고 있습니다.
DocumentFragment 결과 = couchbaseBucket.async().lookupIn(docId).get(subDocId).execute().
toBlocking().singleOrDefault(null);
이유는 잘 모르겠지만 result.rawContent(subDocId)는 null을 반환하는 반면 result.content(subDocId)는 적절한 값을 반환합니다.
이 문제를 일으킬 수 있는 위치를 알려주실 수 없나요?