[이 블로그는 http://damienkatz.net/ 에서 신디케이트되었습니다.]
이제 Couchbase Server 2.0의 안정화 및 리소스 최적화 모드가 거의 완료되었음을 알려드리게 되어 기쁩니다. 계획했던 것보다 훨씬 더 오래 걸렸습니다. 고성능, 효율적이고 안정적이며 모든 기능을 갖춘 분산 문서 데이터베이스를 만드는 것은 결코 간단한 문제가 아닙니다.)
이전 버전과 동일한 "간단하고 빠르며 탄력적인" 멤캐시드 및 클러스터링 기술 외에도, 성능과 안정성은 물론 기능과 사용 사례를 대폭 확장하는 세 가지 새로운 기능을 추가했습니다.
카우치스토어: 높은 처리량, 복구 지향 스토리지
2.0의 가장 큰 장애물 중 하나는 Erlang 기반 스토리지 엔진이 SQLite를 사용하는 1.8.x 릴리스에 비해 리소스를 너무 많이 사용한다는 것이었습니다. 최대한 빠르고 효율적으로 만들기 위해 가능한 모든 것을 제거하면서 수많은 최적화 작업과 수정을 거쳤고, 그 과정에서 Erlang 기반 스토리지 코드를 처음 시작할 때보다 몇 배 더 빠르게 만들었지만 여전히 CPU와 리소스 사용량이 너무 높았고, 많은 CPU 코어가 없으면 기존 고객이 필요로 하는 전체 시스템 성능을 얻을 수 없었습니다.
결국, 한 프로세스에서 작성된 업데이트를 Erlang에서 읽고, 색인하고, 복제하고, 심지어 압축할 수 있도록 Erlang 스토리지 엔진과 호환되는 비트 대 비트 포맷을 사용하여 코어 스토리지 엔진과 압축기를 C로 다시 작성하는 것이 해답이었습니다. 기본 테일-애플드, 복구 지향 MVCC 설계와 동일하기 때문에 한 OS 프로세스에서 쓰고 다른 프로세스에서 읽는 것이 간단합니다. 이 스토리지 포맷은 서버 충돌, OOM 킬러, 심지어 정전으로 인한 손상에 영향을 받지 않습니다.
C로 재작성함으로써 많은 최적화 장벽을 극복할 수 있었습니다. 더 적은 CPU와 메모리 오버헤드로 최적화된 Erlang 엔진과 SQLite 엔진에 비해 2배의 쓰기 처리량을 쉽게 얻을 수 있습니다.
이 모든 것이 C가 Erlang보다 빠르기 때문은 아닙니다. 성능 향상의 상당 부분은 지속성 엔진을 프로세스 내에 내장할 수 있다는 점입니다. 이것만으로도 프로세스 간 데이터 전송을 피하고 Erlang 인메모리 구조로 변환함으로써 많은 CPU와 오버헤드를 줄일 수 있습니다. 또한 C언어이기 때문에 로우레벨 제어가 우수하고 훨씬 더 쉽게 최적화할 수 있습니다. 비용은 더 많은 엔지니어링 노력과 로우레벨 코드가 필요하지만, 성능 향상은 그만한 가치가 있음이 입증되었습니다.
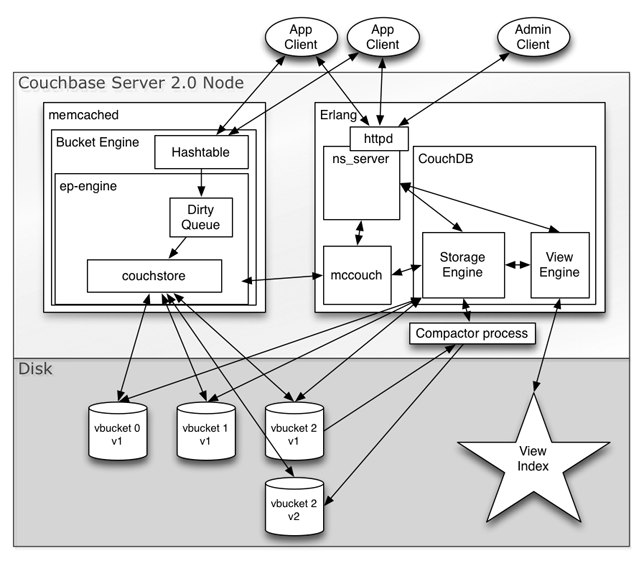
 이제 Erlang과 C 모두에서 읽기가 쓰기를 차단하지 않고 쓰기가 읽기를 차단하지 않는, 복구 지향적이며 조각화 방지 기능을 갖춘 최적의 업데이트, MVCC 지원 스토리지 엔진을 동일하게 사용할 수 있습니다. 쓰기 또한 압축과 동시에 발생합니다. MVCC 스냅샷과 by_sequence 인덱스를 통해 전체 또는 증분 변경 사항을 가져오면 디스크 io를 대부분 선형으로 만들어 빠른 워밍업, 인덱싱 및 클러스터 재밸런싱을 수행할 수 있습니다. 또한 비동기 인덱싱을 허용하고 XDCR을 구동합니다.
이제 Erlang과 C 모두에서 읽기가 쓰기를 차단하지 않고 쓰기가 읽기를 차단하지 않는, 복구 지향적이며 조각화 방지 기능을 갖춘 최적의 업데이트, MVCC 지원 스토리지 엔진을 동일하게 사용할 수 있습니다. 쓰기 또한 압축과 동시에 발생합니다. MVCC 스냅샷과 by_sequence 인덱스를 통해 전체 또는 증분 변경 사항을 가져오면 디스크 io를 대부분 선형으로 만들어 빠른 워밍업, 인덱싱 및 클러스터 재밸런싱을 수행할 수 있습니다. 또한 비동기 인덱싱을 허용하고 XDCR을 구동합니다.
B-슈퍼스타: 클러스터 인식 증분 지도/축소
또 다른 중요한 항목은 CouchDB 증분 맵/축소 보기의 모든 중요한 기능을 Couchbase로 가져와서 리밸런싱 및 장애 조치 중에 일관성을 유지하면서 클러스터링과 결합하는 것이었습니다.
쿼리 시점에 모든 인덱스 결과를 병합하는 가상 파티션별 인덱스(vbucket)를 사용하기 시작했지만, 필요한 성능이나 확장성을 제공하지 못하기 때문에 이 설계를 빠르게 폐기했습니다. 우리는 빠른 다단계 키 기반 축소(_sum, _count, _stats 및 사용자 정의 축소)를 통해 MVCC 범위 스캔을 지원하고 가능한 한 가장 적은 인덱스 읽기를 필요로 하는 시스템이 필요했습니다.
우리가 생각해낸 것은 입증된 CouchDB 기반 뷰 모델, 동일한 자바스크립트 증분 맵/축소, 저비용 범위 쿼리를 위해 내부 btree 노드에 저장된 동일한 사전 색인화된 메모화된 축소를 사용하면서도 파티션이 노드에서 재조정되거나 새 노드에서 부분적으로 색인될 때 잘못된 파티션 결과를 즉시 제외할 수 있는 것입니다.
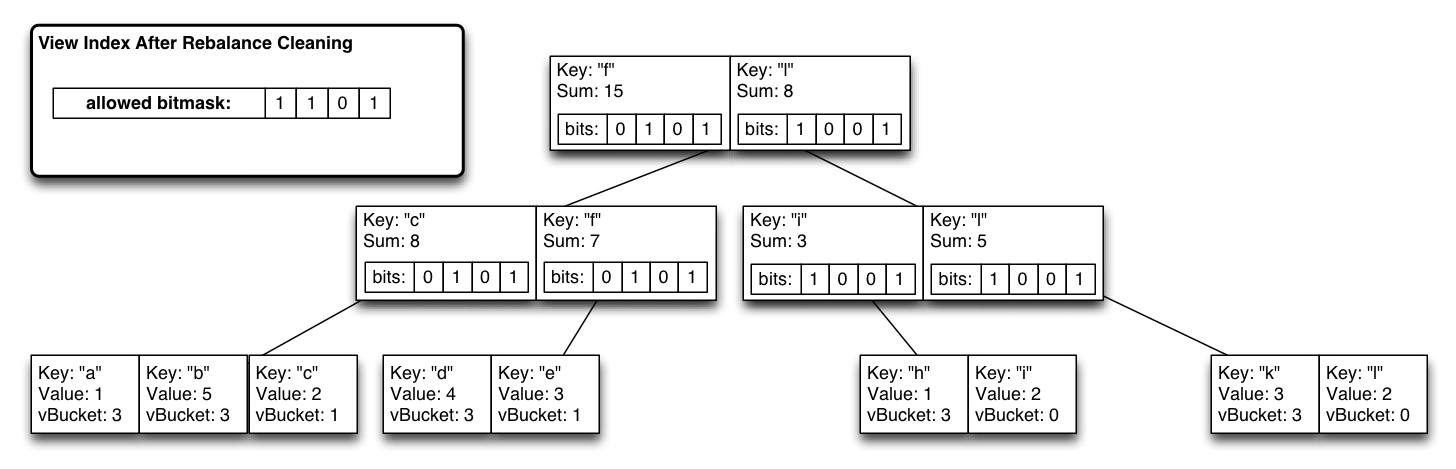
모든 자식 감소의 재귀적 OR인 비트맵 파티션 인덱스를 각 btree 노드에 삽입합니다. 꼬리 추가 인덱스 업데이트로 인해 모든 비트맵을 업데이트하면서 수정된 리프 노드를 루트까지 업데이트하는 선형 쓰기가 이루어집니다. 이제 어떤 하위 트리에 특정 vbucket에서 나온 값이 있는지 즉시 알 수 있습니다.
이미지를 클릭하면 확대됩니다.
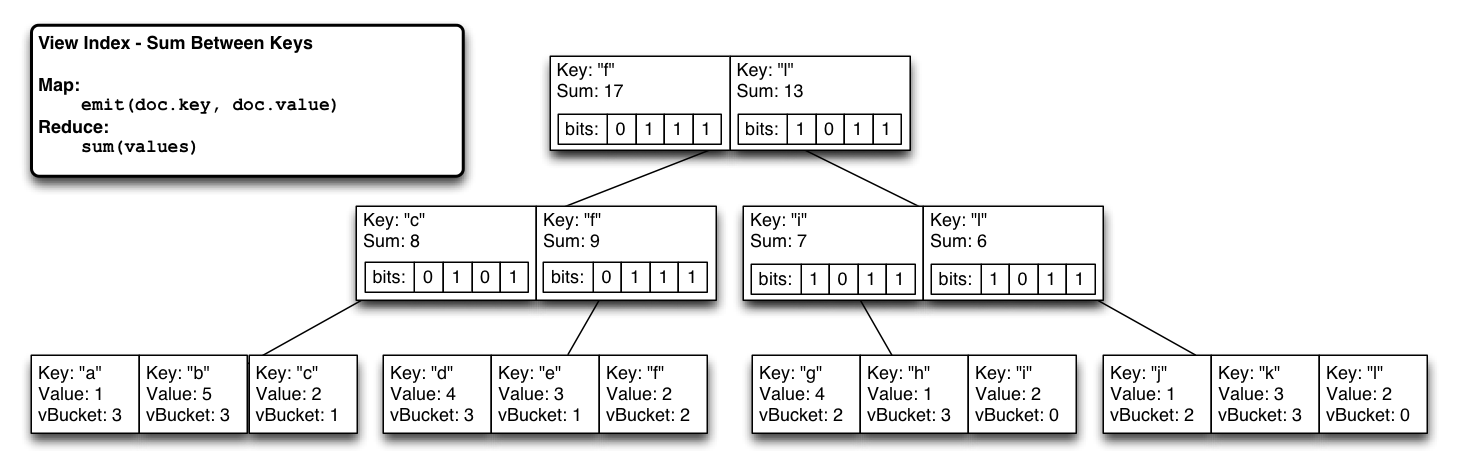
정상 상태에서는 일반 비트리와 거의 동일한 효율로 작동하는 시스템을 갖추고 있습니다(비트리 노드당 1비트에 가상 파티션 수를 곱한 추가 비용만 더하면 됩니다).
이미지를 클릭하면 확대됩니다.
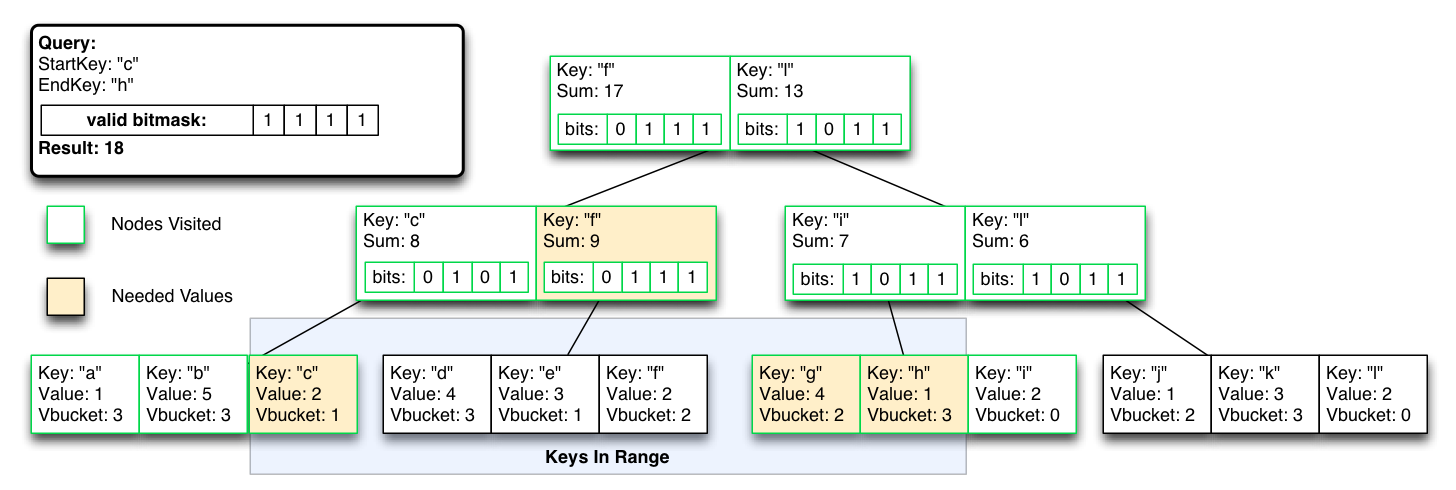
그러나 인덱스가 다시 최적화될 때까지 일시적으로 쿼리 시간 비용이 높아지지만, 리밸런싱/장애 조치 일관성을 위해 단일 비트 마스크를 플립하여 vBucket 파티션을 제외할 수 있습니다.
이미지를 클릭하면 확대됩니다.
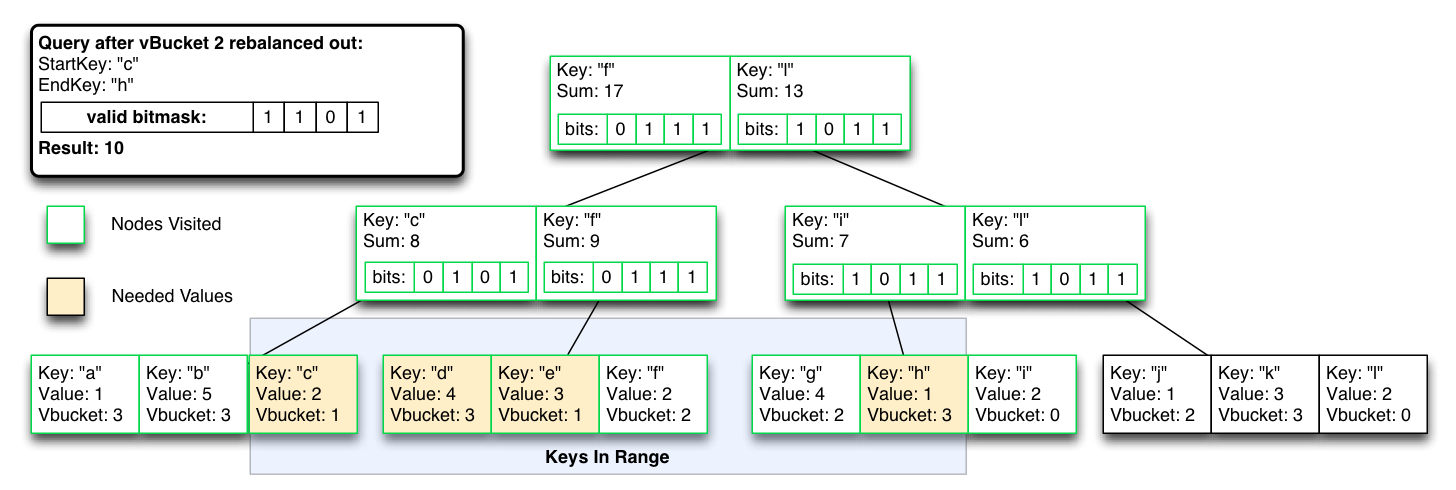
최악의 경우, 제외된 인덱스 결과가 인덱스에서 제거될 때까지 O(logN) 연산이 O(N)이 됩니다.
이미지를 클릭하면 확대됩니다.
인덱스는 다시 정상 상태이고 쿼리는 0(logN)입니다.
이미지를 클릭하면 확대됩니다.
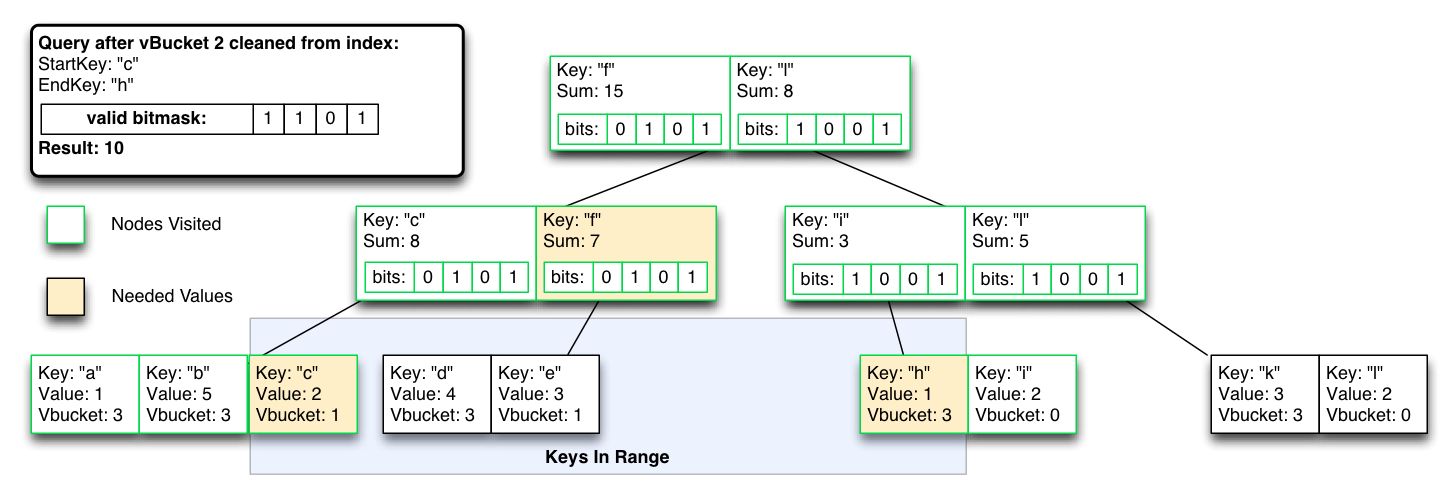
정말 멋진 점은 이 기능이 역방향으로도 작동한다는 것입니다. 즉, 리밸런싱이 완료될 때까지 vBucket의 새 노드의 보기 인덱스에 삽입을 시작하되 리밸런싱이 완료될 때까지 결과를 제외할 수 있습니다. 그 결과 정상 상태와 활성 장애 조치 또는 재조정 중 모두 일관된 보기 인덱스 및 쿼리가 생성됩니다.
데이터 센터 간 복제(XDCR)
Couchbase 2.0에는 멀티마스터, 클러스터 인식 복제 기능도 추가됩니다. 이 기능을 사용하면 지리적으로 분산된 클러스터가 변경 사항을 점진적으로 복제하여 일시적인 네트워크 장애와 독립적인 클러스터 토폴로지를 견딜 수 있습니다.
단일 클러스터에 지리적으로 분산된 사용자가 있는 경우 지연 시간으로 인해 멀리 떨어진 사용자의 애플리케이션 속도가 느려집니다. 사용자가 더 멀리 떨어져 있고 네트워크 홉이 많을수록 지연 시간이 더 많이 발생합니다. 멀리 떨어져 있는 사용자의 지연 시간을 줄이는 가장 좋은 방법은 데이터를 사용자에게 더 가까이 가져오는 것입니다.
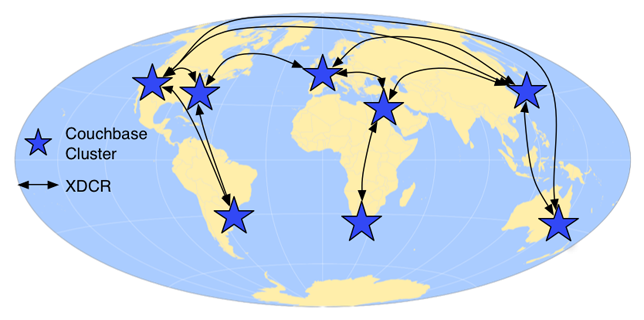
 Couchbase XDCR을 사용하면 여러 지역과 대륙에 분산된 여러 데이터 센터에 클러스터를 구축하여 해당 지역의 사용자의 애플리케이션 지연 시간을 크게 줄일 수 있습니다. 모든 클러스터에서 데이터를 업데이트할 수 있으며, 변경 사항을 고정된 일정에 따라 또는 지속적으로 원격 클러스터에 복제할 수 있습니다. 편집 충돌은 '가장 많이 편집된' 규칙을 사용하여 해결되므로 모든 클러스터가 동일한 값으로 수렴할 수 있습니다.
Couchbase XDCR을 사용하면 여러 지역과 대륙에 분산된 여러 데이터 센터에 클러스터를 구축하여 해당 지역의 사용자의 애플리케이션 지연 시간을 크게 줄일 수 있습니다. 모든 클러스터에서 데이터를 업데이트할 수 있으며, 변경 사항을 고정된 일정에 따라 또는 지속적으로 원격 클러스터에 복제할 수 있습니다. 편집 충돌은 '가장 많이 편집된' 규칙을 사용하여 해결되므로 모든 클러스터가 동일한 값으로 수렴할 수 있습니다.
견고한 기초
이제 시작에 불과한 것 같습니다. 아직 소개하지 못한 세부 사항과 새로운 기능이 많이 있으며, 이는 하이라이트 중 일부에 불과합니다. 저는 2.0의 기능뿐만 아니라 우리가 구축한 빠르고 안정적이며 유연한 기반 위에서 가능한 일들과 앞으로 쉽게 구축할 수 있는 기능 및 기술에 대해 정말 자랑스럽고 흥분됩니다. 저는 매우 밝은 미래를 봅니다.
정말 좋은 분들 같네요. 지연의 원인을 듣게 되어 흥미롭고, (의심할 여지 없이) 어려운 선택을 해주셔서 기쁩니다. 몇 가지 성능 지표를 공유해 주시겠어요?