복제는 가용성과 재해 복구를 제공하기 위해 수십 년 동안 데이터베이스 시스템의 중요한 부분으로 자리 잡았습니다. 최근에는 여러 디바이스에서 운영되는 고가용성, 확장성, 전 세계적으로 분산된 배포의 필요성을 해결하기 위해 분산 데이터베이스가 발전하면서 복제의 역할이 진화하고 그 어느 때보다 중요해졌습니다. 데이터베이스 시스템은 클러스터 내, 클러스터 간, 에지-코어 간 등 다양한 수준의 요구 사항을 해결하기 위해 광범위한 복제 솔루션을 개발하고 있으며, 클라우드, 모바일 및 기타 IoT 사용 사례도 포괄하고 있습니다.
가장 인기 있는 NoSQL 데이터베이스 다목적 복제 솔루션을 갖춘 시스템으로는 Couchbase와 MongoDB가 있습니다. 이러한 각 솔루션에 대해 자세히 살펴보고 이러한 요구 사항을 해결하는 방법을 살펴보겠습니다. 간단하게 비교하기 위해 여러 DC에 걸쳐 고가용성 및 글로벌 배포를 위한 복제에 초점을 맞춰 보겠습니다.
글로벌 배포를 위한 MongoDB의 복제
마스터-슬레이브 아키텍처
몽고 복제 아키텍처는 복제본 세트를 기반으로 하며, 다음과 같이 구성됩니다. 단 하나의 기본 모든 데이터 변경 사항을 캡처하고 쓰기를 확인합니다. 보조 데이터는 일반적으로 기본 데이터로 선출되지 않는 한 읽기 전용인 기본 데이터의 데이터를 복사합니다. 각 복제본 세트는 최대 50개의 보조로 구성할 수 있습니다. 복제 세트의 구성원은 데이터 센터 장애 및 지리적으로 분산된 애플리케이션에 대한 보호를 위해 여러 데이터 센터에 배포할 수도 있습니다. 데이터는 비동기식으로 보조 데이터센터에 복제됩니다.
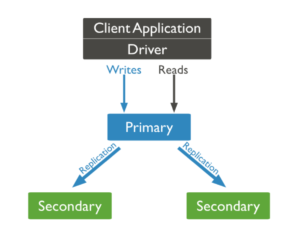
그림. 몽고의 복제 모델
기본에서 보조로 자동 장애 조치하는 데 걸리는 평균 시간은 약 12초이며, 네트워크 지연 시간으로 인해 보조를 다른 DC에 배포하는 경우 이보다 더 길어질 수 있습니다. 이는 보조가 쓰기를 수행할 수 없기 때문에 단일 장애 지점이 될 가능성이 있습니다.
기본값은 기본에서 읽기이지만, 사용자는 대기 시간을 최소화하기 위해 읽기 기본 설정을 보조에서 수행하도록 지정할 수 있습니다. 그러나 복제는 비동기식이기 때문에 특히 지리적으로 분산된 애플리케이션에서 오래된 데이터를 읽을 수 있는 위험이 있을 수 있습니다.
멀티센터 배포 및 액티브-액티브와 같은 설정
멀티센터 배포의 경우, 복제본 세트의 보조를 다음 위치에 배포할 수 있지만 모든 데이터 센터가 쓰기를 수행할 수 있을 때까지는 충분하지 않습니다. 여러 데이터센터에서 동시에 쓰기를 수행할 수 있는 액티브-액티브 배포는 지리적으로 분산된 애플리케이션에 매우 중요합니다. Mongo는 기본 데이터센터에서만 쓰기를 수행할 수 있기 때문에 액티브-액티브 사용 사례를 해결하기 위해 아래에 언급된 접근 방식을 권장합니다.
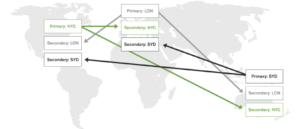
그림: MongoDB를 사용한 액티브-액티브 같은 설정
A shard 는 논리적 저장소 단위로, 여기에는 하위 집합 의 데이터 집합을 생성합니다. 액티브-액티브와 같은 설정을 활성화하기 위해, Mongo는 모든 샤드에 기본 샤드를 배포할 것을 권장합니다. 모든 샤드에는 별개의 데이터 하위 집합이 포함되어 있기 때문에, 애플리케이션은 서로 다른 데이터 하위 집합만 동시에 수정할 수 있습니다. 따라서 동일한 데이터 세트가 다른 사이트에서 수정될 수 있는 완전한 액티브-액티브가 아닙니다.
샤드는 애플리케이션에 완전히 투명하며 쿼리 라우터가 배포되어 애플리케이션에서 각 샤드로 쿼리를 라우팅합니다. 쿼리 라우팅은 또한 추가적인 오버헤드를 추가합니다.
이 설정을 통한 배포는 모든 샤드에 기본 샤드가 있어야 할 뿐만 아니라 모든 샤드의 기본 샤드에 대해 보조 샤드가 고가용성을 위해 다른 샤드에 위치해야 하며 기본 샤드는 계속해서 단일 장애 지점 역할을 하기 때문에 확장에 따라 매우 복잡해질 수 있습니다. 모든 샤드에 대해 복제본의 수는 샤드 수 * 데이터센터 수와 같습니다. 또한 모든 복제본 세트에 대해 언제든지 프라이머리를 선출할 수 있는 쿼럼을 유지해야 합니다. Learn 더 보기.
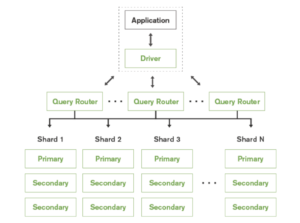
이 설정은 토폴로지 측면에서도 매우 제한적이며, 배포는 기본이 병목 현상이므로 허브 및 스포크 모델을 준수해야 합니다.
클라우드 배포 - 글로벌 클러스터
Mongo Atlas는 지역 복제 사용 사례를 개선하기 위해 글로벌 클러스터를 제공합니다. 글로벌 클러스터를 사용하는 배포는 클라우드 공급업체가 지원을 제공하는 모든 영역 및 지역에 샤드에 대한 기본 설정을 갖는 액티브-액티브 설정과 유사합니다.
글로벌 클러스터를 통해 Mongo는 클라우드 제공업체로부터 얻은 위치 메타데이터를 사용하여 위치 인식 라우팅을 제공할 수 있습니다. 이를 통해 Mongo는 쿼리를 시작 지점에서 가장 가까운 데이터 센터로 라우팅하고 네트워크 지연 시간을 최소화할 수 있습니다. 이는 업데이트가 로컬인 대부분의 경우에 유용합니다. 쓰기가 비로컬인 경우에는 프라이머리만 쓰기를 수행할 수 있으므로 네트워크 지연 시간이 추가됩니다.
글로벌 클러스터의 가장 큰 장점은 Atlas가 완전 관리형 서비스이기 때문에 설정 및 관리와 관련된 운영 및 배포의 복잡성을 몽고에서 처리한다는 점입니다. 이는 다시 한 번 단일 클라우드 공급업체의 배포로 제한됩니다. 글로벌 클러스터는 단일 클러스터이므로 하이브리드 배포를 지원하기 위해 여러 클라우드 공급업체 및 지역에 걸쳐 확장할 수 없습니다. 글로벌 클러스터에 대해 자세히 알아보기 여기를 클릭하세요.
글로벌 배포를 위한 Couchbase의 복제
피어 투 피어 아키텍처
Couchbase는 노드 수준 장애에 대한 클러스터 내 복제, 데이터센터 및 지역 수준 장애에 대한 클러스터 간 복제를 위해 서로 다른 복제 체계를 채택했습니다. 글로벌 배포에 관심이 있으므로 클러스터 간 또는 데이터센터 간 복제가 이 논의의 초점이 될 것입니다.
Couchbase는 피어 투 피어 아키텍처를 따르며, 이는 데이터센터 간 복제 솔루션에도 반영되어 있습니다. Couchbase를 사용하면 여러 개의 독립 클러스터를 생성하고 클러스터 간에 단방향 또는 양방향 복제 스트림을 설정할 수 있습니다. 이러한 독립 클러스터는 동일한 데이터센터 내에 함께 위치하거나 완전히 다른 지역에 존재할 수 있습니다. 피어 투 피어 독립 클러스터를 사용하는 이 아키텍처는 워크로드 격리, 다양한 정책 설정 기능, 다양한 토폴로지 지원, 이기종 확장 등 다양한 이점을 제공하며 하이브리드 배포도 가능합니다.
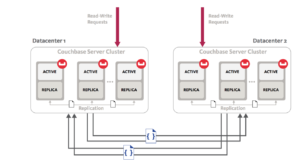
Couchbase의 솔루션은 메모리에서 메모리로 복제가 이루어지고 병렬성이 높기 때문에 성능도 뛰어난 것으로 평가됩니다. 병렬성은 성능 요구 사항에 따라 사용자 정의할 수 있습니다. 또한 기존 복제 스트림의 우선순위를 새 복제 스트림보다 우선시하거나 그 반대로 설정할 수 있는 기능도 있습니다. 또한 네트워크 중단 후에도 자동으로 복구됩니다.
또 다른 큰 장점은 유연한 토폴로지로, 나머지 시스템에 영향을 주지 않고 언제든지 클러스터를 토폴로지에 추가하거나 제거할 수 있다는 점입니다. 따라서 리소스 활용도가 매우 우수합니다. 예를 들어 양방향 링 토폴로지에서 클러스터는 활성 트래픽을 처리할 뿐만 아니라 재해 복구 솔루션으로 작동할 수 있습니다.
멀티 센터 및 액티브-액티브 설정
데이터센터 간 복제 솔루션은 고객이 데이터센터를 소유하고 있는 전 세계 어디에서나 배포할 수 있습니다. 몇 번의 클릭만으로 새 클러스터를 생성하고 클러스터 간에 복제를 설정할 수 있습니다.
카우치베이스의 XDCR은 양방향 복제를 통해 전 세계 사용자가 여러 위치에서 동시에 동일한 데이터를 수정할 수 있는 진정한 액티브-액티브 설정을 지원합니다. 액티브-액티브 설정 중에 발생하는 모든 충돌을 해결하기 위해 대부분의 업데이트가 승리하는 모드와 마지막 쓰기가 승리하는 모드의 두 가지 충돌 해결 모드를 지원합니다.
현재 Couchbase는 위치 인식 라우팅을 제공하지 않지만, 마스터-마스터 아키텍처이므로 읽기 및 쓰기는 항상 로컬로 이루어집니다. 고객은 데이터 센터의 어느 곳에나 데이터를 배포하여 충분한 데이터 로컬리티를 확보할 수 있습니다. 또한 고객은 고급 필터링을 사용하여 해당 지역과 관련된 데이터만 복제함으로써 데이터 상주 및 지리적 펜싱 요건을 충족할 수 있습니다.
클라우드 배포
카우치베이스는 모든 주요 클라우드에서 사용할 수 있습니다: AWS, Azure, GCP 및 Oracle Cloud.
Couchbase 클러스터는 모든 클라우드에 배포할 수 있으며, 클러스터 간에 복제 스트림을 설정할 수 있습니다. 여기에는 프라이빗과 퍼블릭 또는 두 개 이상의 퍼블릭 클라우드와 같은 다양한 클라우드에 클러스터를 배포할 수 있는 멀티 클라우드 및 하이브리드 클라우드 배포가 포함됩니다.
복제 시스템의 배포와 관리는 매우 간단하고 직관적입니다.
Couchbase에는 아직 DBaaS 솔루션이 없지만 곧 출시될 예정입니다. 그러나 현재 자동화된 배포에 대한 지원은 다음을 통해 제공됩니다. 카우치베이스 자율 운영자.
카우치베이스 및 몽고 DB의 복제 특성 요약
| 기능 | 카우치베이스 | MongoDB |
| 아키텍처 | 종속성 없이 확장 및 관리할 수 있는 완전히 독립적인 클러스터 | 독립 시스템이 아닌 클러스터 내 확장 |
| 성능 | 메모리-메모리, 스트림 기반, 고도로 병렬화된 복제. 노드당 복제 스트림 수는 (2-100)이 될 수 있습니다. | 보조 로그는 기본 로그 또는 다른 보조 로그의 데이터를 복제합니다. 병렬이지만 스트림은 1-1(기본-보조)입니다. |
| 우려 사항 작성 | 모든 클러스터가 쓰기를 허용하도록 구성할 수 있습니다. | 쓰기 가용성에 영향을 주는 쓰기 작업은 기본 쓰기만 가능하며 비로컬 쓰기는 매우 비쌉니다. |
| 우려 사항 읽기 | 항상 로컬 | 비용이 많이 들 수 있는 기본 기본값은 보조에서 읽도록 구성할 수 있습니다. |
| 자동 장애 조치 | SDK 수준에서 클러스터 간 자동 페일오버를 활성화할 수 있습니다. | 단일 클러스터, 자동 |
| 복제 유연성 | 매우 유연함 - 버킷 수준, 고급 최적화 기술을 통한 사용자 지정 | 튜닝, 속도, 대역폭 선택이 불가능합니다. |
| 대역폭 최적화 기술 | 고급 필터링, 데이터 압축, 네트워크 대역폭 제한, 복제의 우선 순위를 정하는 서비스 품질. | 데이터 압축 |
| 토폴로지 | 복잡한 토폴로지 지원 - 양방향, 스타, 메시, 체인, 링 등 무엇이든 가능 | 복잡한 토폴로지를 지원하지 않음 - 단방향, 스타. 기본은 병목 현상입니다. |
| 활성-활성 | 지원 | 진정한 지원 없음(단일 마스터) |
| 충돌 해결 | 예 - 대부분 쓰기 승리, 마지막 쓰기 승리(LWW) | 충돌 해결 없음. 하나의 기본값만 지원됩니다. |
| 설정 및 구성 | 몇 번의 클릭만으로 직관적인 UI와 CLI로 간편하게 구성할 수 있습니다. | 복제본 세트 배포는 까다롭고 복제본 세트가 늘어날수록 힘들어질 수 있습니다. |
| 하위 집합 복제를 위한 필터링 | 문서 키 ID, 값 또는 메타데이터를 사용하여 데이터의 하위 집합을 복제하는 고급 필터링. | 필터링이 지원되지 않음 |
| 복제 우선순위 지정 | 진행 중인 복제를 새 복제에 비해 우선순위를 정하거나 그 반대의 경우도 가능합니다. | 복제 우선순위 지정은 지원하지 않습니다. |