리밸런스는 노드 추가/제거, 하드웨어 또는 소프트웨어의 온라인 업그레이드, 노드 장애 후 복구 등 온라인 클러스터 관리 작업을 가능하게 하는 Couchbase 아키텍처의 중요한 구성 요소입니다.
Couchbase Server 6.5에서는 리밸런싱이 더욱 강력하고 관리하기 쉬우며 빨라졌습니다. 이러한 모든 개선 사항에 대해 자세히 알아보려면 계속 읽어보세요.
실패 시 리밸런싱 자동 재시작
카우치베이스는 다른 분산 시스템과 마찬가지로 네트워크 속도 저하, 프로세스 충돌 등과 같은 일시적인 장애가 발생할 수 있으며, 이러한 장애는 자체적으로 복구될 수 있습니다. 이러한 장애가 발생하면 진행 중인 리밸런싱이 실패할 수 있습니다. 실패한 리밸런스를 다시 시도하는 것이 사용자가 취하는 첫 번째 조치인 경우가 많지만, 이를 위해서는 누군가가 리밸런스를 적극적으로 모니터링하고 있어야 합니다.
이제 수동으로 모니터링하고 재시작할 필요가 없도록 실패한 재밸런싱에 대한 재시도 기능이 내장되어 있습니다. 재시도 횟수와 재시도 간격은 물론 실패한 재밸런싱을 다시 시작하기 전에 얼마나 기다릴지 설정할 수 있습니다.
참고: 재조정 재시도 기능은 기본적으로 꺼져 있으므로 명시적으로 켜야 합니다(아래 스크린샷 참조).
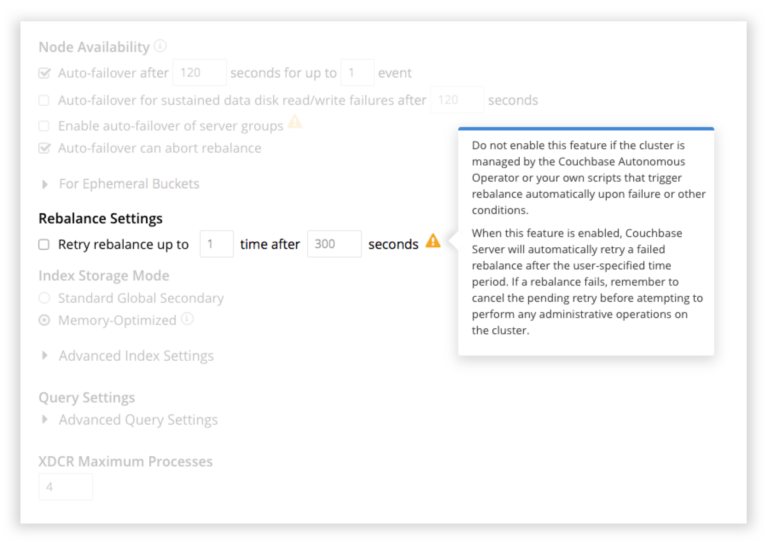
재조정 재시도가 보류 중이면 UI에 이를 알리는 배너가 표시됩니다. 원할 경우 재시도를 취소할 수 있는 옵션이 제공됩니다. 자동 장애 조치로 중단되었거나 사용자가 명시적으로 중단한 경우 등 일부 조건에서는 재밸런스가 자동으로 다시 시도되지 않습니다.
리밸런싱 중 자동 페일오버
리밸런싱은 종종 시간이 걸릴 수 있으며 클러스터의 노드(리밸런싱에 참여했는지 여부와 관계없이)가 실패했을 수 있습니다. 이러한 상황에서는 복제본을 승격하고 데이터 액세스 가용성을 유지하기 위해 노드를 페일오버해야 합니다. 이제 이 자동 페일오버를 진행하기 위해 Couchbase 클러스터 관리자가 진행 중인 리밸런싱을 중단합니다. 이렇게 하면 애플리케이션에서 기대하는 엄격한 가동 시간 SLA에 따라 가용성이 신속하게 복원됩니다.
위의 스크린샷에서 볼 수 있듯이 이 동작은 기본적으로 켜져 있습니다. 어떤 이유로 이 동작을 끄고 싶다면 끄면 됩니다.
또한 자동 장애 조치 후 자동으로 리밸런싱을 다시 시작하려고 하지만 이는 향후 릴리스에서 개선할 사항입니다.
리밸런싱 진행 상황 모니터링
Couchbase 클러스터에서 리밸런싱을 시작하면 데이터 서비스, 인덱스 서비스, 쿼리 서비스, 검색, 이벤트 및 분석을 포함한 모든 서비스가 리밸런싱됩니다. 각각의 리밸런싱 서비스 자체에는 여러 단계가 포함되며, 데이터 서비스가 가장 복잡하고 일반적으로 리밸런싱에서 가장 오래 걸리는 부분입니다. 데이터 서비스 리밸런싱은 한 번에 하나의 버킷을 처리하며, 각 버킷은 여러 개의 v버킷을 동시에 처리합니다.
리밸런싱이 순조롭게 진행 중이라면 관리자는 원치 않는 한 진행 상황을 모니터링하고 관찰할 필요가 없습니다. 그러나 작업이 멈추거나 느려지는 것처럼 보이는 경우 위의 리밸런싱 단계를 파악하면 완료된 작업, 진행 중인 작업, 남은 작업을 파악하는 데 매우 유용합니다.
새로운 재조정 모니터링 UI는 위의 서비스, 버킷, 단계 계층 구조를 모방하여 각 버킷의 재조정이 얼마나 완료되었는지 표시합니다(아래 스크린샷 참조).
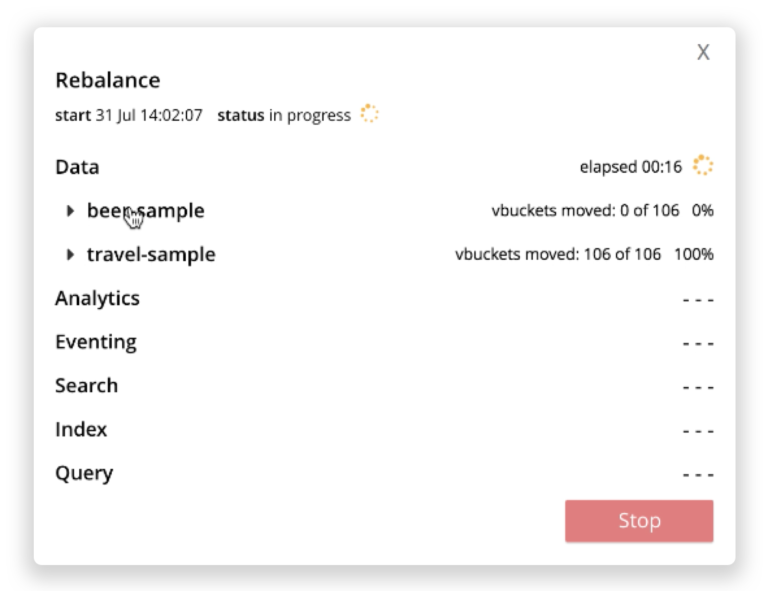
리밸런싱 보고서
이제 REST API를 통해 다음과 같은 마지막 재조정 보고서를 받을 수 있습니다:
curl -X GET -u 관리자:비밀번호 https://localhost:8091/logs/rebalanceReport
UI에 표시되는 정보 외에도 보고서에는 각 v버킷의 4단계(백필, 이동, 지속성, 인수)의 시작 및 종료 시간이 표시됩니다.

더 빠른 리밸런싱
리밸런싱은 여러 개의 v버킷을 동시에 처리하며 각 v버킷은 리밸런싱 중에 많은 내부 단계를 거치게 되는데, 주요 단계 중 하나는 다음과 같습니다. 백필 대부분의 데이터 복사가 발생하는 곳입니다. 백필은 리밸런싱에서 가장 긴 단계인 경우가 많습니다. 이제 리밸런싱의 백필 단계에 더 나은 흐름 제어 메커니즘이 적용되었습니다. 클러스터 관리자는 노드에서 진행 중인 백필의 수를 제어하고 새 백필이 시작되기 전에 이전 백필이 디스크에 대한 지속성을 완료하도록 합니다.
내부 테스트에서 이 새로운 흐름 제어 메커니즘은 특히 대규모 데이터 세트에서 매우 유망한 성능 향상을 보였습니다. 또한 디스크 쓰기 대기열이 줄어들고 메모리 부담이 줄어들어 프론트엔드 애플리케이션에 미치는 영향도 줄어듭니다.
다음 단계
이번 리밸런싱 개선에 대한 여러분의 의견을 듣고 싶습니다. 다음은 시작하는 데 도움이 되는 몇 가지 리소스입니다:
다운로드
문서
블로그
Couchbase Server 6.5 GA 발표 - 새로운 기능 및 개선 사항