빅 데이터
아파치 하둡 의 빅데이터 플랫폼입니다. 볼륨에서 가치를 창출하도록 설계되었습니다. 다음을 저장하고 처리할 수 있습니다. 많이 에서 데이터의 rest빅 데이터. 분석용으로 설계되었습니다. 속도를 위해 설계된 것이 아닙니다.
창고입니다. 추가 및 제거가 효율적입니다. 많은 항목을 창고에서 가져옵니다. 그것은 not 를 추가하고 제거하는 것이 효율적입니다. 단일 항목을 창고에서 가져옵니다.
데이터 세트가 저장됩니다. 정보는 과거 데이터에서 생성되며, 이를 검색할 수 있습니다. 순수 볼륨

빠른 데이터
아파치 스톰은 의 스트림 처리 플랫폼입니다. 속도에서 가치를 도출하도록 설계되었습니다. 다음에서 데이터를 처리할 수 있습니다. 모션빠른 데이터. 볼륨을 위해 설계되지 않았습니다.
컨베이어 벨트입니다. 물품은 컨베이어 벨트 위에 놓여져 컨베이어 벨트에서 제거될 때까지 처리될 수 있습니다. 항목은 다음을 수행합니다. not 컨베이어 벨트 위에 무한정 머물러 있습니다. 그들은 그 위에 놓입니다. 컨베이어 벨트에서 제거됩니다.
데이터 항목이 파이핑됩니다. 정보는 현재 데이터에서 생성되지만, 다음과 같은 경우 할 수 없음 검색할 수 있습니다. 순수한 속도
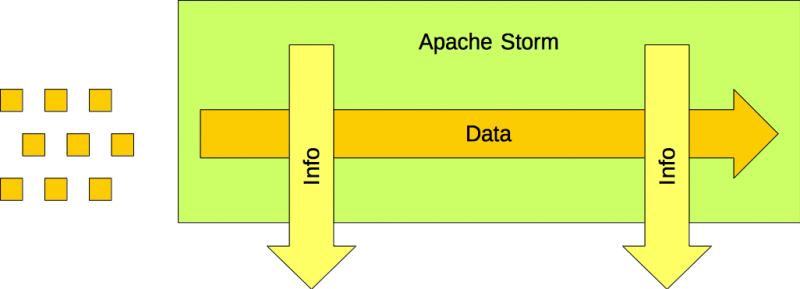
GAP
하지만 한 가지 빠진 것이 있습니다. 컨베이어 벨트에 놓인 물품은 어떻게 창고에 도착할까요?
카우치베이스 서버는 의 엔터프라이즈 NoSQL 데이터베이스입니다. 이 데이터베이스는 볼륨과 속도(및 다양성)의 조합에서 가치를 도출하도록 설계되었습니다.
상자입니다. 컨베이어 벨트 끝에서 물품이 상자에 추가됩니다. 상자에서 물품을 추가하고 제거하는 것이 효율적입니다. 창고에서 상자를 추가하고 제거하는 것이 효율적입니다.
데이터 항목이 저장되고 검색됩니다. 볼륨 + 속도 + 다양성

솔루션
실시간 빅 데이터 아키텍처에는 Apache Storm과 같은 스트림 프로세서, Couchbase Server와 같은 엔터프라이즈 NoSQL 데이터베이스, Apache Hadoop과 같은 빅 데이터 플랫폼이 포함됩니다.
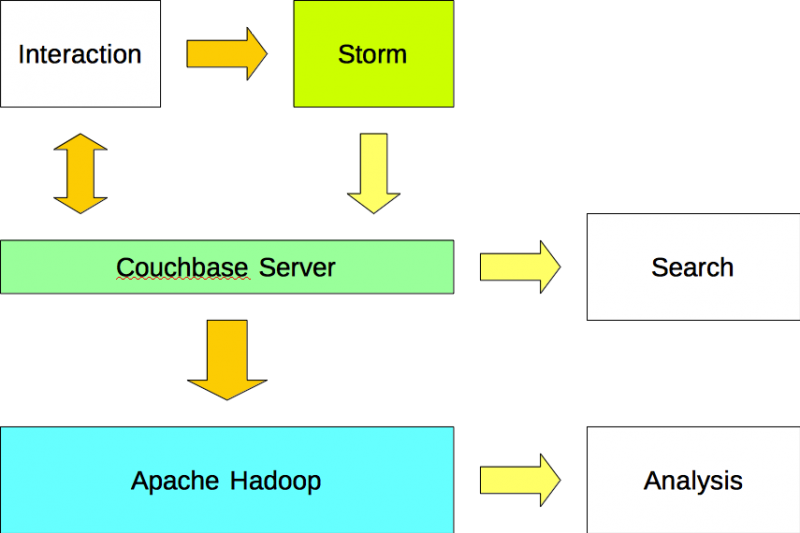
옵션 #1
애플리케이션이 Couchbase Server에 데이터 읽기 및 쓰기 그리고 를 사용하여 Apache Storm에 데이터를 씁니다. Apache Storm은 데이터 스트림을 분석하고 플러그인(예: 볼트)을 사용하여 그 결과를 Couchbase Server에 씁니다. 데이터는 Sqoop 플러그인을 사용하여 Couchbase Server에서 Apache Hadoop으로 가져옵니다.
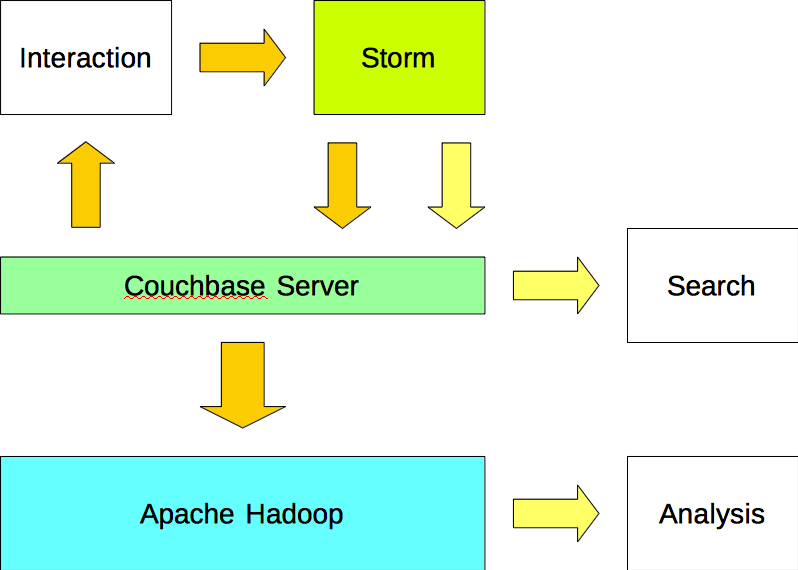
옵션 #2
애플리케이션은 아파치 스톰에 데이터를 쓰고 카우치베이스 서버에서 데이터를 읽습니다. Apache Storm은 데이터(입력)와 정보(출력)를 모두 Couchbase Server에 씁니다. 데이터는 Sqoop 플러그인을 사용하여 Couchbase Server에서 Apache Hadoop으로 가져옵니다.
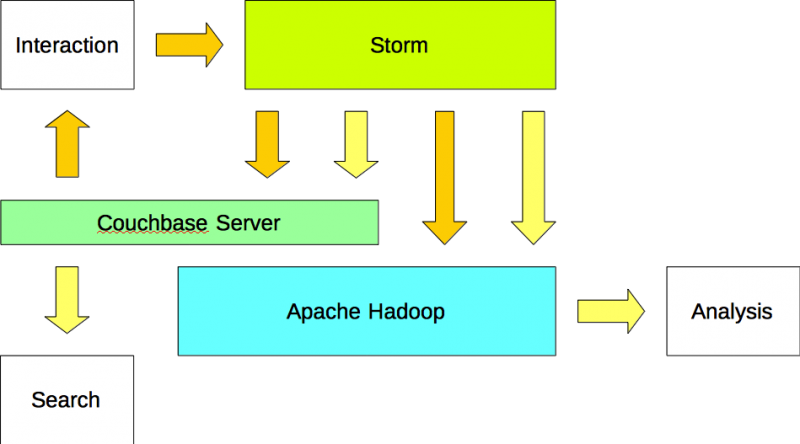
옵션 #3
애플리케이션은 아파치 스톰에 데이터를 쓰고 카우치베이스 서버에서 데이터를 읽습니다. Apache Storm은 데이터(입력)를 Apache Couchbase와 Apache Hadoop 모두에 씁니다. 또한 Apache Storm은 정보(출력)를 Couchbase Server와 Apache Hadoop 모두에 씁니다.
요약
이 문서에서는 세 가지 실시간 빅데이터 아키텍처에 대해 설명합니다. 하지만 실시간 빅 데이터 아키텍처 설계의 가장 좋은 점은 마치 레고 놀이를 하는 것과 같다는 점입니다. 구성 요소는 다양한 모양과 크기로 제공되며, 가장 효율적이고 효과적인 솔루션을 구축하는 데 필요한 조각을 선택하고 연결하는 것은 아키텍트의 몫입니다. 이는 흥미로운 도전입니다.
reddit에서 대화에 참여하세요(링크).
해커 뉴스에서 대화에 참여하세요(링크).
예제
이러한 엔터프라이즈 고객이 Couchbase Server를 통해 Apache Hadoop, Apache Storm 등을 어떻게 활용하고 있는지 알아보세요.
LivePerson - 아파치 하둡 + 아파치 스톰 + 카우치베이스 서버
QuestPoint - 아파치 하둡 + 카우치베이스 서버
McGraw-Hill Education - Elasticsearch + Couchbase Server
AOL - 아파치 하둡 + 카우치베이스 서버
AdAction - 아파치 하둡 + 카우치베이스 서버
참조
카우치베이스 서버 커넥터(링크)
감사합니다, 잘 읽었습니다. 두 번째 옵션이 가장 깔끔한 접근 방식인 것 같지만 모두 그럴듯합니다.
고마워요. 또 다른 접근 방식은 일괄 쓰기를 통해 원시 데이터(입력)를 Apache Hadoop에 쓰는 동안 분석된 데이터(출력)를 실시간으로 Couchbase Server에 쓰도록 Apache Storm을 구성하는 것입니다.
[...] 빅 데이터/빠른 데이터 격차 [...]