배경:
Google은 어떻게 하나요? Google은 사용자가 무언가를 검색하면 1초 이내에 관련성이 높은 상위 결과를 표시하고 해당 주제에 대한 대략적인 문서 수를 알려줍니다. 다음은 몇 가지 간단한 설명입니다: https://www.google.com/search/howsearchworks/algorithms/
엔터프라이즈 애플리케이션도 검색, 검색, 정렬 및 페이지 매김 기준이 더 복잡하지만 동일한 요구 사항을 가지고 있습니다.
기본적인 페이지 매김 기능을 이해하기 위해 Google 페이지 매김 동작을 살펴보겠습니다. 그런 다음 엔터프라이즈 애플리케이션에서 페이지 매김을 구현하는 방법을 단계별로 살펴보겠습니다.
Google 페이지 매김:
Google에서 "N1QL"을 검색합니다.
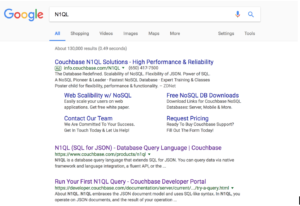
검색 결과가 표시되는 페이지에는 다음과 같은 정보가 있습니다.
- 일치하는 페이지 수 130,000
- 검색이 0.49초 만에 실행되었습니다.
- 페이지에 광고가 포함되어 있습니다. 이 경우 Couchbase의 광고입니다. 당연하죠.
- 결과 집합의 첫 페이지: 12페이지로 연결되는 링크와 각 페이지에서 몇 줄씩 표시됩니다.
- "N1QL"과 관련된 검색어 검색과 관련된 몇 가지 제안 사항
- 다음 10페이지의 결과와 다음 페이지로 연결되는 링크입니다.
데이터베이스 페이지 매김
페이지 매김의 작업은 다음을 검색하고 표시하는 것입니다. 결과 집합의 하위 집합입니다. 하위 집합은 페이지 매김 사양(페이지당 행 수)과 애플리케이션에서 발행한 쿼리의 정렬 순서에 따라 결정됩니다. In 데이터베이스 페이지 매김로 설정하면 애플리케이션은 데이터베이스 관리에서 제공하는 특성과 최적화를 활용하려고 시도합니다.
Google에서 본 각 페이지 매김 기능을 살펴보고 Couchbase에서 쿼리를 구현하고 최적화하는 방법을 살펴보겠습니다.
다음 섹션에서는 Couchbase를 사용한 데이터베이스 페이지 매김에 중점을 두겠습니다.
- 총 결과 계산하기
- 쿼리 실행에 걸리는 시간 가져오기
- 첫 페이지 가져오기
- 다음 페이지 및 다른 페이지로 연결되는 링크 만들기
- 다음 페이지 또는 다른 페이지 가져오기.
Google 광고 선택 또는 관련 검색 제안에 대해서는 다루지 않습니다. 이는 그 자체로 별개의 주제입니다.
이 문서에서는 인덱스 콜레이션(각 인덱스 키에 대한 ASC 및 DESC 사양), 오프셋 푸시다운 및 기타 최적화와 같은 새로운 기능을 Couchbase 5.0에서 사용하고 있습니다.
섹션 1. 총 결과 계산하기
Google은 다음과 같은 답변을 보냈습니다:
약 130,000개의 결과(0.49초)
COUNT: 예상 페이지 수 130,000페이지
TIME: 검색을 수행하는 데 걸린 시간입니다. 이 경우 0.49초
데이터베이스 페이지 매김에서는 이 두 가지가 모두 유용할 수 있습니다.
COUNT는 UI에서 결과를 렌더링할 때 생성해야 하는 다음 및 이전 링크의 수를 결정하는 데 유용합니다. 페이지 매김 쿼리 자체는 최적화 프로그램이 인덱스 및 기타 기술을 사용하여 문서 처리 수를 제한하려고 하기 때문에 총 결과 수를 반환하지 않을 수 있습니다. 이렇게 하면 쿼리에서 결과 집합의 가능한 총 문서 수를 알 수 없게 됩니다.
쿼리에 ORDER BY가 있는 경우 경우에 따라 sortCount를 사용할 수 있습니다. 이렇게 하면 하나의 문서만 반환하더라도 정렬한 총 문서 수를 알려줍니다.
쿼리가 ORDER BY 절을 평가하기 위해 정렬을 피하기 위해 인덱스 순서를 악용하는 경우, sortCount를 사용할 수 없습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY airportname OFFSET 1 LIMIT 1; { "requestID": "709fe2fb-d124-4b0c-b2b4-1c235d3c6f12", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Abilene Rgnl", "city": "Abilene", "country": "United States", "faa": "ABI", "geo": { "alt": 1791, "lat": 32.411319, "lon": -99.681897 }, "icao": "KABI", "id": 3718, "type": "airport", "tz": "America/Chicago" } } ], "status": "success", "metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } } |
아래 쿼리는 필드 faa의 인덱스를 활용하여 데이터를 정렬된 순서로 가져오고 페이지 매김(OFFSET 50 LIMIT 10) 절을 인덱스 스캔으로 푸시합니다. 따라서 결과 집합에서 sortCount가 누락됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
cbq> select * from `travel-sample` where faa > "4AB" ORDER BY faa OFFSET 50 LIMIT 10; { "requestID": "5bc38dd1-7285-41a5-80e3-0f1da23df178", "signature": { "*": "*" }, "results": [ { "travel-sample": { "airportname": "Andrews Afb", "city": "Camp Springs", "country": "United States", "faa": "ADW", "geo": { "alt": 280, "lat": 38.810806, "lon": -76.867028 }, "icao": "KADW", "id": 3552, "type": "airport", "tz": "America/New_York" } }, ... "status": "success", "metrics": { "elapsedTime": "4.167044ms", "executionTime": "4.143152ms", "resultCount": 10, "resultSize": 5033 } } |
이러한 경우 커버링 인덱스 스캔을 사용하여 적격 문서의 COUNT()를 간단히 가져올 수 있습니다. 인덱스 스캔(또는 5.0 이전의 인덱스 스캔)은 단순히 인덱스 스캔을 수행하고 적격 문서의 수를 계산하며 인덱서에서 쿼리 엔진으로의 모든 데이터 전송을 피합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
cbq> SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "requestID": "78a3aeae-4dd1-468c-a01c-38610fd87cf4", "signature": { "$1": "number" }, "results": [ { "$1": 1659 } ], "status": "success", "metrics": { "elapsedTime": "2.945555ms", "executionTime": "2.920307ms", "resultCount": 1, "resultSize": 34 } } |
다음은 이 쿼리가 COUNT를 얻기 위한 쿼리 계획입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
cbq> EXPLAIN SELECT COUNT(faa) FROM `travel-sample` where faa > "4AB"; { "#operator": "IndexCountScan2", "covers": [ "cover ((`travel-sample`.`faa`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "def_faa", "index_id": "460bd5dad1c6c95d", "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "inclusion": 0, "low": "\"4AB\"" } ] } |
섹션 2. 타이밍 및 기타 메트릭
모든 쿼리 결과에는 쿼리 실행에 대한 기본 메트릭이 있습니다.
|
1 2 3 4 5 6 7 |
"metrics": { "elapsedTime": "40.111996ms", "executionTime": "40.087977ms", "resultCount": 1, "resultSize": 500, "sortCount": 1659 } |
경과 시간 는 쿼리 수신 후 서버가 소요한 시계 시간입니다. 여기에는 대기 시간이 포함됩니다. 실행 시간 는 쿼리를 실행하는 데 걸린 시간입니다. resultCount는 반환된 문서 수입니다. resultSize는 결과 집합의 바이트 수입니다. sortCount는 페이지 매김 전에 정렬된 문서 수입니다.
쿼리에 OFFSET 또는 LIMIT가 포함되지 않은 경우 resultCount는 결과 집합의 총 문서 수입니다. 중간 데이터를 정렬해야 하는 경우, 앞서 언급한 것처럼 ORDER BY를 평가하기 위해 수행된 정렬이 없는 경우 sortCount가 누락됩니다.
섹션 3. 결과 집합의 첫 페이지
먼저 첫 페이지에 집중해 보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT * FROM `travel-sample` t WHERE type = “hotel” AND country = “United Kingdom” AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 0 LIMIT 20; CREATE INDEX idx_hotel_ctry_likes ON `travel-sample`(country, ARRAY_LENGTH(public_likes)) WHERE type = “hotel” |
이 인덱스를 사용한 쿼리는 약 30밀리초 만에 실행됩니다.
|
1 2 3 4 5 6 7 8 9 |
"status": "success", "metrics": { "elapsedTime": "30.125957ms", "executionTime": "30.110732ms", "resultCount": 20, "resultSize": 181449, "sortCount": 238 } } |
이 인덱스에는 인덱스에 세 개의 술어가 있습니다. 인덱스가 모든 필터링을 수행하는 동안 쿼리는 여전히 전체 결과 집합을 가져와 정렬한 다음 첫 페이지만 투사해야 합니다. 제 컴퓨터에서는 이 작업이 30밀리초 만에 실행됩니다. 많은 쿼리를 동시에 실행할 수 있도록 이 시간을 더 단축하고 싶습니다.
|
1 2 3 4 |
DROP INDEX `travel-sample`.idx_hotel_ctry_likes; CREATE INDEX idx_hotel_ctry_likes_ratings ON `travel-sample` (country, ARRAY_LENGTH(public_likes), ratings DESC) WHERE type = “hotel” |
쿼리를 다시 실행합니다.
|
1 2 3 4 5 6 7 |
"status": "success", "metrics": { "elapsedTime": "9.449025ms", "executionTime": "9.432752ms", "resultCount": 20, "resultSize": 181449 } |
이 쿼리 및 인덱스의 경우, 설명에 LIMIT 20이 인덱스 스캔으로 푸시 다운되었음을 표시합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
이 쿼리는 전체 가져오기 및 정렬을 피함으로써 10밀리초 미만으로 실행됩니다. 정렬하는 가장 빠른 방법은 정렬 자체를 피하는 것입니다.
섹션 4: 다음 페이지 및 다른 페이지로 연결되는 링크 만들기

첫 페이지가 렌더링되면 Google은 다음 페이지와 다른 10개의 후속 페이지로 연결되는 링크도 제공합니다. 섹션 1에서 설명한 것처럼 잠재적 결과의 총 개수는 여러 가지 방법으로 얻을 수 있습니다. 개수를 파악한 후에는 각 페이지에 필요한 각각의 오프셋을 사용하여 링크를 생성하기만 하면 됩니다. 다음 페이지를 가져오려면 오프셋을 20으로 설정하면 됩니다. 각 후속 페이지 또는 임의의 페이지를 얻으려면 (페이지# * 페이지의 문서 수)로 OFFSET을 계산하면 됩니다. 물론 이 오프셋은 결과 집합에 있는 잠재적인 문서의 총 개수보다 작아야 합니다. 이 총 개수를 구하는 방법은 섹션 1에서 설명했습니다.
예시:
첫 페이지: 오프셋 0 제한 20;
두 번째 페이지: 오프셋 20 제한 20;
8페이지: 오프셋 160 제한 20;
섹션 5: 다음 페이지 또는 다른 페이지 가져오기.
이전 섹션에서는 올바른 페이지 매김 매개변수를 사용하여 링크를 만드는 방법에 대해 설명했습니다. 첫 번째 쿼리를 만들고 후속 페이지에 대한 오프셋을 계산하면 이후의 모든 쿼리에 대한 쿼리를 발행하는 데 필요한 모든 것을 갖추게 됩니다.
다음 쿼리를 통해 두 번째 페이지를 검색합니다:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` t WHERE type = ‘hotel’ AND country = ‘United Kingdom’ AND ARRAY_LENGTH(public_likes) > 3 ORDER BY ARRAY_LENGTH(public_likes), ratings DESC OFFSET 20 LIMIT 20; |
오프셋을 변경하여 각 후속 페이지(또는 임의의 페이지)를 가져오기만 하면 됩니다.
Couchbase 5.0부터는 인덱스가 완전한 술어와 ORDER BY 절을 평가할 수 있는 경우, OFFSET과 LIMIT이 모두 인덱스 스캔으로 푸시됩니다. 이렇게 하면 OFFSET에 지정된 대로 정규화된 행을 건너뛴 후 LIMIT된 행 수만 반환하여 인덱스 스캔을 효율적으로 수행할 수 있습니다.
아래와 같은 쿼리 계획이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "index": "idx_hotel_ctry_likes_ratings", "index_id": "f7de95817c4dc84b", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "20", "namespace": "default", "offset": "20", "spans": [ { "exact": true, "range": [ { "high": "\"United Kingdom\"", "inclusion": 3, "low": "\"United Kingdom\"" }, { "inclusion": 0, "low": "3" } ] } ], |
이 쿼리와 같이 최적의 인덱스를 생성해야 하는 경우에도 인덱스는 반환할 인덱스 항목을 식별하기 위해 오프셋 0에서 오프셋 NN까지 정규화된 항목을 트래버스해야 합니다. 오프셋 값이 크면 비용이 많이 들 수 있습니다. 쿼리에 적절한 인덱스가 없는 경우 오프셋 처리는 훨씬 더 많은 비용이 듭니다.
결론
N1QL 쿼리 처리와 인덱스 스캔을 최적화했지만, 사용 사례가 주로 "다음 가져오기"인 경우 이러한 쿼리를 더 최적화할 수 있습니다. 이것은 일반적이고 중요한 시나리오입니다. 마크 윈앤드와 루카스 에더가 성능을 훨씬 더 향상시키는 키세트 페이지 매김 방법에 대해 설명했습니다. 이들의 글은 참조 섹션에 있습니다.
다음 글에서는 Couchbase N1QL에서 키세트 페이지 매김을 구현하는 방법에 대해 설명하겠습니다.
참조:
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/