모니터링을 통해 리소스 호그를 발견했습니다. 이제 어떻게 할까요?
카우치베이스 서버 4.5는 실행 중인 요청을 계속 주시하는 메커니즘을 도입하여 성능이 느린 요청을 강조 표시할 수 있도록 했습니다.
이 DZone 문서 에서 N1QL 모니터링에 대한 주제를 자세히 다루고 있지만, 이제 문제는 폭도들이 있는데 그들의 요구를 어떻게 확인하느냐는 것입니다.
일반적으로 모든 데이터베이스 엔진은 데이터를 반환하기 위한 요청에 사용된 쿼리 계획을 분석하는 수단을 일종의 EXPLAIN 문 형태로 제공하지만, 이것은 말 그대로 계획을 설명하지만 실제로 계획의 어떤 부분이 잘못 작동하는지 딱딱한 숫자를 사용하여 말해주지는 않습니다.
숙련된 데이터베이스 관리자는 경험, 휴리스틱, 직감 등을 혼합하여 특정 계획을 개선할 수 있는 방법을 알 수 있지만, 이러한 특정 기술에는 상당한 양의 교육이 필요하며 공정하게 말하면 어느 정도의 추측도 수반됩니다.
더 잘할 수 있을까요?
프로파일링 입력
Couchbase 5.0은 무엇보다도 개별 요청의 모든 이동 부분에 대한 메트릭을 수집하는 기능을 도입했습니다.
이 기능을 활성화하면 결과 문서에 이어 요청에 따라 프로파일링 정보가 반환되며, 나중에 처리할 수 있도록 시스템 키 공간에서 사용할 수 있습니다.
이 메트릭은 각 작업자와 각 처리 단계에서 소요된 시간, 수집 및 소화된 문서 등의 정보가 포함된 실행 트리를 자세히 보여줍니다.
이러한 데이터로 무장한 데이터베이스 관리자는 요청에서 비용이 많이 드는 운영자를 쉽게 식별할 수 있습니다. 인덱스 스캔에서 반환되는 정규화된 키의 수를 최소화하기 위해 올바른 인덱스를 생성하는 등 문제를 해결합니다.
하지만 처음부터 다시 시작하겠습니다.
프로파일링 사용
프로파일링이 자주 사용되는 이유는 특정 문장이 느린 이유를 파악하기 위해서입니다.
따라서 느린 문장은 이미 식별되어 샌드박스 환경에서 테스트 중일 가능성이 높으며, 필요한 정보는 문장의 텍스트뿐이므로 다른 곳에서 프로필을 수집할 필요가 없습니다.
반대로 프로덕션 노드에서 느린 패치가 진행 중일 수도 있습니다.
범인 요청이 식별되지 않았으므로 사용 가능한 모든 진단 정보를 즉시 수집하여 느린 요청이 식별되면 위반 진술을 다시 실행할 필요 없이 이미 프로파일링을 사용할 수 있도록 하는 것이 중요합니다.
요청 수준에서
이 작업은 프로필 요청 REST API 매개변수를 요청 문과 함께 쿼리 서비스에 전달하여 개별 문장을 조사하는 데 이상적입니다.
다음과 같이 가능한 가장 낮은 수준에서 다운될 수 있습니다. curl 예제
|
1 |
curl https://localhost:8093/query/service -d 'statement=select * from `travel-sample`&profile=timings' -u Administrator:password |
또는 더 간단하게는 cbq 셸 세션에서 다음을 수행합니다.
|
1 |
cbq> \set -profile timings; |
나중에 살펴보겠지만 쿼리 워크벤치에서는 기본적으로 프로파일링이 활성화됩니다.
그리고 프로필 매개변수는 세 가지 값을 받습니다: 꺼짐 (기본값)으로 설정합니다, 단계및 타이밍.
첫 번째는 예상대로 기능을 비활성화합니다.
두 번째는 각 요청 단계별 실행 시간 요약 정보를 제공하며, 마지막은 실행 연산자별 전체 시간이라는 가장 높은 수준의 정보를 제공합니다.
서비스 수준에서
모든 요청에 대해 프로파일링이 필요한 경우 노드 시작 시 -프로필 명령줄 매개변수를 사용합니다.
이는 쿼리 REST API 매개변수와 동일한 인수를 사용하며 동일한 의미를 갖습니다.
REST API 수준에서 프로파일링 수준을 지정하지 않는 모든 요청은 명령줄 인수의 값을 선택한 옵션으로 사용합니다.
즉석에서
프로덕션 클러스터가 피로의 징후를 보이는 경우, 다음과 같이 /admin/settings REST 엔드포인트를 통해 쿼리 서비스 프로필 설정을 즉시 변경할 수 있습니다.
|
1 |
curl https://localhost:8093/admin/settings -d '{ "profile": "timings"}' -u Administrator:password |
이는 쿼리 서비스를 초기화하는 것과 동일한 효과가 있습니다. -프로필 명령줄 매개변수를 사용하지만 이미 시작된 요청에도 적용되므로 요청에 쿼리 수준 프로필 설정을 지정하지 않으면 새로 설정된 수준을 선택한 옵션으로 사용합니다.
프로파일링 정보는 항상 수집되며, 위의 스위치는 보고 여부와 정보 양을 결정할 뿐이라는 점을 알아두는 것이 중요합니다.
따라서 이미 시작된 요청에 대해 프로파일링을 소급하여 설정할 수 있으므로, 시스템 속도 저하를 발견했을 때 DBA는 요청을 다시 제출하거나 어떤 요청이 잘못 수행되는지 먼저 조사할 필요 없이 이미 실행 중인 모든 요청을 프로파일링할 수 있습니다!
프로파일링 정보 얻기
개별 요청 프로파일링 정보는 실행 트리를 자세히 설명하는 json 하위 문서로 제공됩니다.
일반적으로 이것은 다음과 같은 형식과 매우 유사한 내용의 구조입니다. 설명 문 출력과 비슷하지만 실행 통계로 보강되었습니다.
클라이언트 애플리케이션은 응답 문서(일회성 조사에 유용)를 통해, 타사는 시스템 키스페이스를 통해 액세스할 수 있으며, 이는 예를 들어 동일한 문에 대한 다양한 변형을 비교하거나 자리 표시자의 값이 다른 동일한 문을 실행하는 데 유용합니다.
요청 응답에서
다음 예는 프로파일링이 켜진 상태에서 cbq에서 문을 실행하는 것을 보여줍니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 |
cbq> \set -profile timings; cbq> select * from `travel-sample` limit 1; { "requestID": "eff5d221-fc0d-459f-9de3-727747368a3e", "signature": { "*": "*" }, "results": [ { "travel-sample": { "callsign": "MILE-AIR", "country": "United States", "iata": "Q5", "icao": "MLA", "id": 10, "name": "40-Mile Air", "type": "airline" } } ], "status": "success", "metrics": { "elapsedTime": "65.441768ms", "executionTime": "65.429661ms", "resultCount": 1, "resultSize": 300 }, "profile": { "phaseTimes": { "authorize": "1.544104ms", "fetch": "1.776843ms", "instantiate": "777.209µs", "parse": "840.796µs", "plan": "53.121896ms", "primaryScan": "6.741329ms", "run": "10.244259ms" }, "phaseCounts": { "fetch": 1, "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "executionTimings": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "3.41µs", "kernTime": "10.23877ms" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 4, "execTime": "3.268µs", "kernTime": "8.651859ms", "servTime": "1.540836ms" }, "privileges": { "List": [ { "Target": "default:travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 3, "execTime": "8.764µs", "kernTime": "8.639269ms" }, "~children": [ { "#operator": "Sequence", "#stats": { "#phaseSwitches": 2, "execTime": "8.037µs", "kernTime": "8.591094ms" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "6.254658ms", "kernTime": "1.609µs", "servTime": "486.671µs" }, "index": "def_primary", "keyspace": "travel-sample", "limit": "1", "namespace": "default", "using": "gsi" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "48.055µs", "kernTime": "6.766558ms", "servTime": "1.728788ms" }, "keyspace": "travel-sample", "namespace": "default" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 5, "execTime": "1.675µs", "kernTime": "8.580305ms" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "4.113µs", "kernTime": "8.555317ms" }, "result_terms": [ { "expr": "self", "star": true } ] }, { "#operator": "FinalProject", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "2.201µs", "kernTime": "8.570215ms" } } ] } ] }, { "#operator": "Limit", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 11, "execTime": "3.244µs", "kernTime": "8.621338ms" }, "expr": "1" } ] } }, { "#operator": "Stream", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 9, "execTime": "8.647µs", "kernTime": "10.225903ms" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } } |
이제 응답에 프로필 섹션에 다음과 같은 위상 정보를 표시합니다. phaseTimes, phaseCounts, 단계 연산자 (각각 각 단계를 실행하는 데 소요된 시간, 단계당 처리된 문서 수, 각 단계를 실행하는 작업자 수) - 다음과 같은 경우에 제공되는 유일한 정보입니다. 프로필 로 설정되어 있습니다. 단계 - 뿐만 아니라 실행 타이밍 하위 섹션입니다.
시스템 키 공간에서
시스템 키 공간에 대한 쿼리는 쿼리 시점에 해당 요청에 대해 프로파일링이 켜져 있는 경우 요청 프로파일링 정보를 반환할 수 있습니다.
다음은 간단한 예입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
cbq> select * from system:active_requests; { "requestID": "7f500733-faba-45dc-8015-3127e305e86e", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "87.698587ms", "executionTime": "87.651658ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "1.406584ms", "fetch": "15.793µs", "instantiate": "50.802µs", "parse": "438.25µs", "plan": "188.113µs", "primaryScan": "75.53238ms" }, "remoteAddr": "127.0.0.1:57711", "requestId": "7f500733-faba-45dc-8015-3127e305e86e", "requestTime": "2017-10-09 19:36:04.317448352 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "88.016701ms", "executionTime": "87.969113ms", "resultCount": 1, "resultSize": 1220 } } |
선택 항목에 대한 레코드 시스템:활성_요청 자체가 스포츠 단계 정보입니다.
프로파일링이 다음과 같이 설정된 경우 타이밍로 설정하면 세부 실행 트리가 계획 첨부 파일을 통해 액세스할 수 있습니다. 메타() 함수입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 |
cbq> select *, meta().plan from system:active_requests; { "requestID": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "signature": { "*": "*", "plan": "json" }, "results": [ { "active_requests": { "elapsedTime": "58.177768ms", "executionTime": "58.163366ms", "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "phaseTimes": { "authorize": "674.937µs", "fetch": "8.26µs", "instantiate": "20.294µs", "parse": "985.136µs", "plan": "69.766µs", "primaryScan": "47.460796ms" }, "remoteAddr": "127.0.0.1:57817", "requestId": "53e3b537-c781-402a-b3ae-49cd4ad4b4ac", "requestTime": "2017-10-09 19:36:31.374286818 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select *, meta().plan from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" }, "plan": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "818ns", "kernTime": "57.105844ms", "state": "kernel" }, "~children": [ { "#operator": "Authorize", "#stats": { "#phaseSwitches": 3, "execTime": "3.687µs", "kernTime": "56.428974ms", "servTime": "671.25µs", "state": "kernel" }, "privileges": { "List": [ { "Priv": 4, "Target": "#system:active_requests" } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "1.35µs", "kernTime": "56.439225ms", "state": "kernel" }, "~children": [ { "#operator": "PrimaryScan", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "19.430376ms", "kernTime": "2.821µs", "servTime": "28.03042ms" }, "index": "#primary", "keyspace": "active_requests", "namespace": "#system", "using": "system" }, { "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" }, { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "638ns", "kernTime": "56.466039ms", "state": "kernel" }, "~children": [ { "#operator": "InitialProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.402µs", "kernTime": "56.471719ms", "state": "kernel" }, "result_terms": [ { "expr": "self", "star": true }, { "expr": "(meta(`active_requests`).`plan`)" } ] }, { "#operator": "FinalProject", "#stats": { "#phaseSwitches": 1, "execTime": "1.105µs", "kernTime": "56.49816ms", "state": "kernel" } } ] } ] } }, { "#operator": "Stream", "#stats": { "#phaseSwitches": 1, "execTime": "366ns", "kernTime": "57.250988ms", "state": "kernel" } } ], "~versions": [ "2.0.0-N1QL", "5.1.0-1256-enterprise" ] } } ], "status": "success", "metrics": { "elapsedTime": "59.151099ms", "executionTime": "59.136024ms", "resultCount": 1, "resultSize": 6921 } } |
여기에 표시된 정보는 시스템:활성_요청 에서도 액세스할 수 있습니다. 시스템:완료_요청에 저장할 자격이 있다고 가정할 때, 해당 요청이 완료되면 시스템:완료_요청 를 클릭하고 프로파일링이 켜져 있습니다.
에서 반환되는 타이밍 정보는 시스템:활성_요청 는 현재를 선택하면 지금까지 발생한 실행 타이밍이 포함됩니다. 시스템:활성_요청 를 사용하여 두 선택 항목 사이에 경과한 시간 간격에서 특정 연산자의 비용을 결정할 수 있습니다.
제공된 정보
다음 예제에서 볼 수 있듯이
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
{ "#operator": "Fetch", "#stats": { "#itemsIn": 1, "#phaseSwitches": 7, "execTime": "8.26µs", "kernTime": "47.474703ms", "servTime": "8.946656ms", "state": "services" }, "keyspace": "active_requests", "namespace": "#system" } |
실행 트리 문서는 각 작업자에 대해 수집 및 소화된 문서 수를 보고합니다(#itemsIn 그리고 #itemsOut), 연산자 코드 실행에 소요되는 시간(실행 시간), 예약 대기 중(kernTime) 및 서비스에서 데이터를 제공할 때까지 대기(servTime), 운영자가 상태를 변경한 횟수(실행 중, 예약 대기 중, 데이터 대기 중), 현재 상태(요청이 아직 완료되지 않았다는 가정 하에) 등을 표시합니다.
운영자 통계는 의도적으로 매우 상세하게 작성되었습니다. 각각의 개별 측정값은 특정 성능 조사에서 두드러지게 눈에 띄는 것으로 알려져 있으며, 제 자신의 디버깅 세션에서도 유용하게 사용되었다고 말해도 부끄럽지 않습니다!
달성할 수 있는 것의 종류에 대한 느낌을 주기 위해 다음을 고려해 보겠습니다. 단계 스위치.
프로파일을 두 번 수집한 후 다음과 같이 가정해 보겠습니다. 단계 스위치 특정 운영자의 경우 증가하지 않았습니다.
특정 운영자가 올바르게 작동하지 않을 수 있습니다. 상태 에 갇히다 "서비스"를 호출하면 작업자에 따라 문서 저장소(가져오기의 경우) 또는 인덱싱 서비스(스캔의 경우)에서 대기 중일 수 있습니다.
관련 서비스가 다운되었거나 멈췄나요?
반대로 "커널"로 표시되면 파이프라인 아래의 소비자가 데이터를 수락하지 않거나 머신이 너무 로드되어 스케줄러가 실제로 운영자를 위한 시간 조각을 찾지 못하고 있을 수 있습니다.
다음 섹션에서는 몇 가지 일반적인 시나리오에 대한 몇 가지 징후, 가장 가능성이 높은 시나리오를 먼저 다룹니다.
프로필 해석하기
모든 운영자: 높은 커널 시간
이는 파이프라인의 더 아래쪽에 있는 운영자에게는 병목 현상입니다.
실행 또는 서비스 시간이 긴 운영자를 찾아보세요.
쿼리 노드를 찾을 수 없는 경우 런타임 커널이 연산자 스케줄링에 어려움을 겪고 있는 것으로, 쿼리 노드에 과부하가 걸려 새 노드를 추가하는 것이 도움이 될 수 있습니다.
가져오기, 조인, 스캔: 높은 서비스 시간
이는 외부 서비스에서 스트레스를 받고 있음을 나타낼 수 있습니다.
이를 확인하는 방법은 다음과 같은 낮은 변화율에서 확인할 수 있습니다. #itemsOut이 경우 동일한 프로필을 두 번 이상 촬영해야 하므로 불편할 수 있습니다(이미 요청이 완료된 경우 불가능할 수도 있음).
대안으로 다음에 설명된 증상을 찾아보세요.
가져오기 및 조인: 수신 문서당 높은 서비스 시간
개별 문서 가져오기는 빨라야 합니다.
나누기 servTime by #itemsOut 는 항상 1밀리초 미만의 Fetch 시간을 제공해야 합니다.
그렇지 않다면 문서 저장소가 스트레스를 받고 있는 것입니다.
분명히 말하지만, 프로파일링되는 요청 때문에 스토어가 스트레스를 받는 것이 아니라 서비스의 전반적인 부하가 문제일 가능성이 높습니다.
스트레스 테스트를 수행하면서 전체 부하가 문제인지 확인하는 한 가지 방법은 작업자 클라이언트 수를 줄이는 것입니다. 과부하가 걸린 스토어에서는 클라이언트 수가 감소함에 따라 개별 가져오기 시간이 일정하게 유지되며, 부하가 더 쉽게 처리할 수 있는 수준에 도달해야만 개선되기 시작합니다.
가져오기: 수집된 문서 수가 많음
좋은 쿼리 계획은 요청과 관련된 문서 키만 생성하는 인덱스를 사용해야 합니다.
Fetch 연산자에게 전달된 키의 수가 클라이언트에 반환된 최종 문서 수보다 훨씬 많으면 선택한 인덱스가 충분히 선택적이지 않은 것입니다.
스캔: 많은 수의 문서 생성
이것은 앞의 증상과 반대되는 것으로, 선택된 인덱스가 충분히 선택적이지 않다는 것입니다. 인덱스 스캔에 추가 술어를 푸시할 수 있도록 인덱스를 만드는 것을 고려해 보세요.
조인: 수집된 문서는 적고, 생성된 문서는 많음
다시 말하지만, 분명히 잘못된 인덱스 경로입니다. 애초에 조인이 그렇게 많은 결과를 생성해야 했나요?
필터: 수집된 문서가 많고, 생성된 문서가 적음
또 다른 "선택된 인덱스가 충분히 선택적이지 않음" 지표입니다.
필터: 높은 실행 시간
이런 일은 절대 일어나지 않아야 하며, 만약 이런 일이 발생한다면 이전 증상을 동반할 가능성이 높습니다.
인덱스가 충분히 선택적이지 않고 너무 많은 문서 키를 반환할 뿐만 아니라, 너무 많은 문서에 대해 WHERE 절의 모든 표현식을 평가하는 것은 다소 비용이 많이 드는 것으로 판명되었습니다!
프로젝션: 빠른 실행 시간
다시 한 번 말씀드리지만, 쿼리 서비스가 요청에 대한 결과 문서를 모으는 데 어려움을 겪고 있습니다.
SELECT 문의 투영 절에 몇 개의 용어가 있습니까? 몇 개만 줄이세요!
복잡한 표현이 있으신가요?
스트림: 높은 실행 시간
요청이 결과를 JSON 형식으로 변환하여 클라이언트로 전송하는 데 어려움을 겪고 있습니다.
그리고 예쁜 REST 매개 변수가 다음과 같이 설정되었을 수 있습니다. true 오류가 발생했습니다.
투사 목록에 용어가 너무 많을 수 있습니다.
또는 네트워크에 문제가 있거나 전송되는 결과 문서가 너무 커서 네트워크가 처리할 수 없는 경우일 수 있습니다.
컨트롤
요청 동작이 자리 표시자 값에 따라 달라지는 경우가 많으므로 프로필과 함께 자리 표시자 값을 캡처하는 것이 매우 유용합니다.
이 작업은 컨트롤 쿼리 REST API, 명령줄 매개변수 및 /admin/settings REST 엔드포인트를 사용하는 true 또는 false 값입니다.
이 동작은 완전히 동일한 프로필 설정은 요청별로, 시작 시, 즉석에서, 서비스 전체에서 설정할 수 있으며, 이 역시 설정을 지정하지 않은 실행 중인 요청에 소급 적용됩니다.
이름 및 위치 매개변수는 자체 제어 섹션의 요청 출력에 보고됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
cbq> \set -controls true; cbq> \set -$a 1; cbq> select * from default where a = $a; { "requestID": "bf6532d6-f009-4e55-b333-90e0b1d17283", "signature": { "*": "*" }, "results": [ ], "status": "success", "metrics": { "elapsedTime": "9.864639ms", "executionTime": "9.853572ms", "resultCount": 0, "resultSize": 0 }, "controls": { "namedArgs": { "a": 1 } } } |
뿐만 아니라 시스템 키 공간(프로필과 달리 첨부 파일은 메타() 함수):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
cbq> select * from system:active_requests; { "requestID": "dced4ef6-7a31-4291-a15d-030ac67b033c", "signature": { "*": "*" }, "results": [ { "active_requests": { "elapsedTime": "69.458652ms", "executionTime": "69.434706ms", "namedArgs": { "a": 1 }, "node": "127.0.0.1:8091", "phaseCounts": { "primaryScan": 1 }, "phaseOperators": { "authorize": 1, "fetch": 1, "primaryScan": 1 }, "remoteAddr": "127.0.0.1:63095", "requestId": "dced4ef6-7a31-4291-a15d-030ac67b033c", "requestTime": "2017-10-09 20:51:33.400550619 +0100 BST", "scanConsistency": "unbounded", "state": "running", "statement": "select * from system:active_requests;", "userAgent": "Go-http-client/1.1 (godbc/2.0.0-N1QL)", "users": "Administrator" } } ], "status": "success", "metrics": { "elapsedTime": "69.62242ms", "executionTime": "69.597934ms", "resultCount": 1, "resultSize": 977 } } |
시각적 프로필
특별한 작업을 하지 않고도 개별 명세서에 대한 자세한 프로파일링 정보에 쉽게 액세스할 수 있는 방법은 관리 콘솔 UI의 쿼리 탭을 사용하는 것입니다.
쿼리 워크벤치는 기본적으로 프로파일링이 켜져 있으며, 요청이 완료되면 '계획' 버튼을 클릭하면 타이밍과 문서 수를 그림 형식으로 쉽게 확인할 수 있습니다.
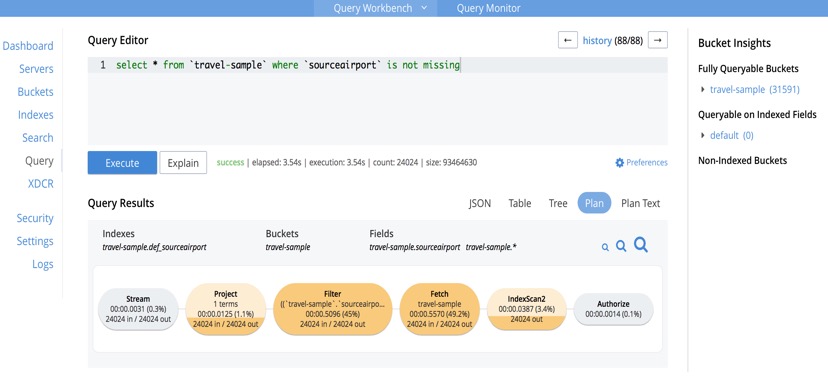
오퍼레이터는 비용별로 깔끔하게 색상으로 구분되어 있으며, 개별 오퍼레이터 위로 마우스를 가져가면 많은 양의 원시 타이밍이 표시됩니다.
환경설정에서는 프로파일링 설정은 물론 이름 및 위치 매개변수와 같은 기타 설정을 변경할 수 있습니다.
프로파일링은 단순한 프로파일링 그 이상입니다.
프로필 및 제어 정보는 더 자세한 모니터링을 위해서도 사용할 수 있습니다.
예를 들어 과도한 양의 문서를 생성하는 작업자가 있는 요청을 찾으려면 다음을 사용할 수 있습니다.
|
1 2 |
select * from system:active_requests where any o within meta().plan satisfies o.`#itemsOut` > 100000 end; |
(필요에 따라 출력 문서의 임계값을 변경합니다).
이 예제는 매우 간단하며 실제로는 다음을 사용하여 더 쉽게 수행할 수 있습니다. phaseCounts이지만, ANY 절을 만족하는 것으로 전환합니다.
|
1 2 3 |
o.`#operator` = "Fetch" and o.keyspace = "travel-sample" and o.`#stats`.`#itemsOut` > 100000 |
를 입력하면 특정 키 스페이스를 로드하는 요청이 표시됩니다.
마찬가지로, 명명된 매개 변수에 특정 값을 사용한 요청을 찾는 것은 다음을 사용하여 수행할 수 있습니다.
|
1 2 |
select * from system:active_requests where namedArgs.`some parameter` = "target value"; |
('일부 매개변수' 및 '목표 값'을 필요한 값으로 대체하세요!).
가능성은 무궁무진합니다.
마지막으로 고려해야 할 사항
프로파일링 정보는 실행 트리 자체에 보관되므로 상당한 양의 메모리를 사용합니다.
이 자체는 문제가 되지 않지만 느리게 실행되는 요청이 다음에 저장할 수 있게 되면 시스템:완료_요청 그리고 프로필 로 설정되어 있습니다. 타이밍를 누르면 전체 실행 트리도 저장됩니다.
이 역시 그 자체로는 문제가 되지 않습니다. 하지만 다음과 같은 경우 문제가 될 수 있습니다. 시스템:완료_요청 는 모든 요청을 기록하도록 설정되어 있으며, 제한이 없으며 모든 요청에는 프로필 로 설정 타이밍이 경우 시간 시작 이후 실행된 모든 요청에 대한 모든 타이밍을 저장하기 때문에 메모리 사용량이 적정 수준 이상으로 증가할 수 있습니다!
다행히도 기본 설정은 시스템:완료_요청 로깅을 한다는 것은 자신도 모르게 곤경에 빠지지 않는다는 것을 의미하며, 어쨌든 로깅하는 시간을 절약해야 한다는 것은 아니지만 과잉이 고통스러울 수 있는 경우입니다.
경고를 받았습니다.
결론
카우치베이스 서버 버전 5.0부터 N1QL은 실행 타이밍을 상당히 심층적으로 분석할 수 있는 특수 도구를 제공합니다.
기능에 액세스하고 수집된 데이터를 해석하는 방법에 대한 예시가 제공되었습니다.