
이전 글에서 페이지 매김 배경을 읽어보세요: https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
페이지 매김은 잠재적인 결과를 페이지로 나누고 필요한 페이지를 필요에 따라 하나씩 검색하는 작업입니다. 데이터베이스 쿼리에 페이지 매김을 작성하는 가장 쉬운 방법은 OFFSET과 LIMIT을 사용하는 것입니다. OFFSET과 LIMIT을 함께 사용하면 SELECT 문의 페이지 매김 절을 만들 수 있습니다. 페이지 매김은 일반적인 애플리케이션 작업이며 그 구현은 고객 경험에 큰 영향을 미칩니다. Couchbase N1QL의 문제점과 해결책을 자세히 살펴보겠습니다.
Markus Winand https://use-the-index-luke.com/ 가 가장 효율적이지 않을 수 있다고 주장합니다. 그는 또한 가능하면 오프셋 페이지 매김 대신 키세트 페이지 매김 방식을 사용할 것을 제안합니다. 이 글에서는 그의 글에서 모델링한 예제 쿼리를 사용하겠습니다, https://use-the-index-luke.com/no-offset 를 통해 어떤 오프셋 최적화를 수행했는지, 언제, 어떻게 N1QL에서 키세트 페이지 매김을 활용했는지 보여드리겠습니다.
카우치베이스는 여행 샘플 데이터 세트와 함께 제공되므로 이를 사용하여 페이지 매김 쿼리를 작성하겠습니다.
- 첫 페이지 가져오기
|
1 2 3 4 5 6 7 8 9 10 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 0 LIMIT 10; CREATE INDEX ixtopic ON `travel-sample`(type); |
이 쿼리의 경우, 인덱스 ixtopic을 사용하여 쿼리 엔진은 간단한 방식으로 실행됩니다. 쿼리 엔진은 인덱스에서 모든 한정된 키를 가져온 다음 모든 문서를 가져와서 ORDER BY 절에 따라 정렬한 다음 문서의 OFFSET 수(이 경우 0)와 LIMIT(이 경우 10)의 문서 수를 투사합니다.
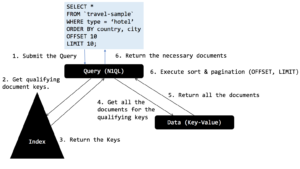
다음은 인덱스와 스팬을 보여주는 계획입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
{ "index": "ixtype", "index_id": "8630f5f7e05ee113", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } |
N1QL은 인덱스 ixtype을 선택하고 필터(유형 = "hotel")를 인덱스 스캔에 푸시합니다. ORDER BY 절을 구현하기 위해 모든 문서를 가져옵니다. 정렬 단계에서는 LIMIT 10 절을 인식하고 상위 10개 항목만 유지하여 정렬을 효율적으로 수행합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "#operator": "Order", "limit": "10", "sort_terms": [ { "expr": "(`travel-sample`.`country`)" }, { "expr": "(`travel-sample`.`city`)" } ] }, |
이 인덱스를 사용하여 인덱스 스캔 작업자의 효율성을 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 917, "#phaseSwitches": 3671, "execTime": "2.646892ms", "kernTime": "31.095431ms", "servTime": "19.781593ms" }, … "#operator": "Fetch", "#stats": { "#itemsIn": 917, "#itemsOut": 917, "#phaseSwitches": 3787, "execTime": "3.43324ms", "kernTime": "20.847541ms", "servTime": "69.875698ms" }, … "#operator": "Order", "#stats": { "#itemsIn": 917, "#itemsOut": 10, "#phaseSwitches": 1849, "execTime": "6.519061ms", "kernTime": "88.307572ms" }, |
인덱서에서 반환한 문서 키는 917개였습니다. 쿼리 엔진은 917개의 문서를 가져왔습니다. 그런 다음 정렬(순서) 연산자가 이를 정렬하여 10개의 항목을 반환했습니다.
2. 두 번째 페이지 가져오기
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
이 경우 쿼리1과 모든 것이 동일합니다:
- 정렬(ORDER BY) 연산자는 20개의 문서(오프셋 + 제한)를 반환합니다.
- 새 오프셋 연산자는 주문 연산자 다음에 실행되어 처음 10개의 행을 삭제합니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
"#operator": "Order", "#stats": { "#itemsIn": 917, "#itemsOut": 20, "#phaseSwitches": 1859, "execTime": "6.485904ms", "kernTime": "65.92484ms" }, { "#operator": "Offset", "#stats": { "#itemsOut": 10, "#phaseSwitches": 32, "execTime": "5.071503ms", "kernTime": "701ns", "state": "running" }, "expr": "10", "#time_normal": "00:00.0050", "#time_absolute": 0.005071503 }, |
오프셋이 증가하면 정렬에 따라 스캔하는 문서 수도 증가하여 메모리와 CPU를 더 많이 소모합니다.
- 술어와 정렬 키를 단일 인덱스로 처리하여 성능을 개선해 보겠습니다.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ixtypectcy ON `travel-sample`(type, country, city); Let’s execute our recent query again: SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 10 LIMIT 10; |
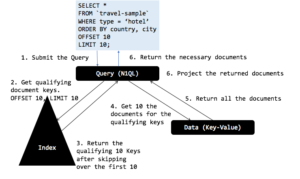
올바른 인덱스를 사용하고 인덱스 스캔에 적합한 필터(스팬)를 생성합니다.설명에는 다음이 포함됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 |
{ "#operator": "IndexScan2", "index": "ixtypectcy", "index_id": "2a2ed6573354e21", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } ], |
이 인덱스를 사용하여 인덱스 스캔 작업자의 효율성을 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 |
"#operator": "IndexScan2", "#stats": { "#itemsOut": 10, "#phaseSwitches": 43, "execTime": "41.786µs", "kernTime": "11.15µs", "servTime": "855.759µs" }, |
인덱스 스캔에서 필요한 문서 키 10개만 반환됩니다! N1QL 옵티마이저는 WHERE 절과 페이지 매김(OFFSET, LIMIT) 절을 모두 평가합니다. 쿼리 최적화 도구는 쿼리의 절별 순서와 인덱스 키 순서에 따라 페이지 매김 절을 인덱서에게 푸시다운할지 여부를 결정합니다.
이 경우 쿼리 술어는 type = 'hotel'입니다.
절별 주문은 다음과 같습니다: 국가, 도시별 주문
색인 키 순서는 (유형, 국가, 도시)입니다.
단순 비교로만 보면 절별 순서는 인덱스 키 순서와 정확히 같지 않습니다. 그러나 인덱스의 선행 키(유형)에는 동일성 술어(유형 = '호텔')가 있습니다. 따라서 옵티마이저는 예상되는 문서 키가 (국가 및 도시) 순서로 정렬될 것임을 알고 있습니다.
**와 ORDER BY 절을 사용하여 페이지 매김 매개 변수를 인덱스 스캔으로 푸시다운할 수 있는지 확인합니다. 이 경우 완벽하게 일치합니다.
옵티마이저는 페이지 매김에서 오프셋과 제한을 모두 인덱스 스캔에 적용하며, 인덱스 스캔은 오프셋에 관계없이 필요한 문서 키 10개만 반환합니다! 따라서 가져오기는 10개의 문서만 가져오면 됩니다. 인덱서는 키를 평가하기 위해 인덱스 스캔을 거쳐야 합니다.
이 쿼리는 제 환경에서 약 6.81밀리초 만에 실행되었습니다. 성능을 확인하기 위해 후속 페이지로 페이지 매김을 해보겠습니다:
| 오프셋 | LIMIT | 응답 시간 |
| 10 | 10 | 6.81ms |
| 20 | 10 | 7.17ms |
| 100 | 10 | 7.02ms |
| 400 | 10 | 9.54ms |
| 800 | 10 | 9.08ms |
내림차순으로 페이지 매김을 하려면 쿼리와 인덱스를 다음과 같이 변경하세요. 인덱스에 있는 키의 데이터 정렬은 쿼리의 데이터 정렬과 일치해야 합니다. 이 경우 국가와 도시 모두 내림차순입니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
DROP INDEX `travel-sample`.ixtypectcy; CREATE INDEX ixtypectcy ON `travel-sample`(type, country DESC, city DESC); SELECT country, city FROM `travel-sample` WHERE type = "hotel" ORDER BY country DESC, city DESC OFFSET 10 LIMIT 10; |
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`country`))", "cover ((`travel-sample`.`city`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "ixtypectcy", "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } ], |
이제 인덱스에 포함되지 않는 쿼리를 살펴보겠습니다. 앞서 살펴본 쿼리에서는 국가 및 도시와 함께 호텔 이름을 검색하기로 했습니다. 이 이름은 색인에 없습니다.
|
1 2 3 4 5 6 7 8 9 10 |
CREATE INDEX ixtypectcy ON `travel-sample` (type, country DESC, city DESC); SELECT country, city, name FROM `travel-sample` WHERE type = "hotel" ORDER BY country desc, city desc OFFSET 10 LIMIT 10; |
이 경우에도 인덱스에는 WHERE 절과 ORDER BY 절을 커버하는 데이터가 있습니다. 인덱스 스캔이 술어를 적용합니다. 인덱스 순서는 쿼리 순서와 일치합니다(참고: 선행 키에는 동일성 술어만 있습니다. 따라서 국가와 도시가 자동으로 순서대로 정렬됩니다.) 한정된 키의 오프셋 수를 건너뛰고 LIMIT 절에 지정된 키 수를 인덱싱하여 반환합니다. 엔진은 ORDER BY 절에 지정된 순서를 유지하기 위해 문서를 검색합니다.
이러한 모든 작은 최적화를 통해 오프셋이 10, 100, 1000이든 상관없이 쿼리 성능이 일관되게 유지됩니다. 오프셋이 높을 때 발생하는 유일한 오버헤드는 추가 항목에 대한 인덱스 스캔 건너뛰기뿐입니다. 인덱스 키 평가와 건너뛰기가 모든 문서를 가져와서 정렬하는 것보다 훨씬 빠릅니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "#operator": "Sequence", "~children": [ { "#operator": "IndexScan2", "index": "ixtypectcy", "index_id": "b2ab2c276bba7862", "index_projection": { "primary_key": true }, "keyspace": "travel-sample", "limit": "10", "namespace": "default", "offset": "10", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" } ] } |
최대 24K 문서를 반환할 가능성이 있는 더 긴 실행 쿼리를 고려해 보겠습니다.
create index idxtypeaiaid ON `travel-sample`(type, airline, airlineid)
페이지 매김 쿼리 술어와 순서 기준이 인덱스에 완전히 포함되는 경우에도 페이지 매김 LIMIT 및 OFFSET을 인덱스 스캔에 푸시하여 매우 효율적으로 만들 수 있는 경우가 제한되어 있습니다.
다음은 인덱서에 OFFSET 및 LIMIT를 푸시다운하기 위한 일반적인 규칙과 요구 사항입니다. 이러한 규칙은 완전하고 완전한 것은 아니지만 최적화가 언제 완료되는지 알 수 있습니다.
- 쿼리 스캔은 단일 키 스페이스에 있어야 합니다(JOIN이 없는 FROM 절의 단일 참조).
- FROM
여행 샘플t - FROM
여행 샘플호텔 이너 조인여행 샘플랜드마크 온 키 호텔.lmid
- FROM
케이스 (a)는 자격이 있고 (b)는 그렇지 않습니다.
- 쿼리의 모든 술어는 인덱스 스캔(스팬)으로 푸시 다운됩니다.
- 술어(예: "%xyz")를 색인 스캔으로 푸시할 수 없습니다. 따라서 페이지 매김도 푸시할 수 없습니다.
- 모든 술어는 단일 스팬으로 표시되어야 합니다. 여러 인덱스 스캔, 인덱스 스캔 후 처리(예: 유니온 스캔, 설명의 고유 스캔)를 수행해야 하는 경우 인덱서가 페이지 매김을 평가하도록 할 수 없습니다. 쿼리는 페이지 매김 절을 인덱스 스캔에 푸시하지 않고 실행됩니다. 다음은 단일 스팬을 생성하는 술어의 예입니다.
- 예: (4~8 사이의 a와 12)
- (a = 5 또는 a = 6)
- (a IN [4, 6, 9])
- 모든 술어는 정확해야 합니다.
- 정확한 술어: (a = 5), (a 9.8~9.99 사이)
- 부정확한 술어: (a > 5 및 a > $param)
- 쿼리에는 집계, 그룹화, 절을 포함할 수 없습니다. 인덱스 스캔 후 문서를 제거해서는 안 됩니다(인덱스 스캔 후 필터링/축소 없음).
- ORDER BY 키와 키의 순서는 인덱스 키와 인덱스 키 순서와 일치해야 합니다.
- t(a, b, c)에 인덱스 i1을 생성합니다;
- SELECT * FROM t WHERE a = 1 ORDER BY a, b, c;
- SELECT * FROM t WHERE a = 1 ORDER BY b, c;
- SELECT * FROM t WHERE a > 3 ORDER BY b, c
- SELECT * FROM t WHERE a > 3 ORDER BY a, b, c
- SELECT * FROM t WHERE (a LIKE "%xyz") ORDER BY a, b, c OFFSET 10 LIMIT 5;
케이스 (2)는 주문과 완벽하게 일치합니다.
케이스 (3)은 완벽하게 일치하지 않지만 선행 키에 동일성 필터가 있습니다. 따라서 스캔 결과가 (b, c) 순서가 될 것임을 알 수 있습니다. 따라서 인덱스에 대한 페이지 매김 푸시다운이 가능합니다.
(4)의 경우 선행 키에 범위 술어(a > 3)가 있으므로 페이지 매김 푸시다운이 불가능합니다.
(5)의 경우 ORDER BY 절과 인덱스 키가 완벽하게 일치합니다. 따라서 선행 키에 범위 술어가 있더라도 페이지 매김을 인덱서까지 밀어낼 수 있습니다.
(f)의 경우, 인덱스 순서를 활용할 수는 있지만 인덱스 스캔으로 완전한 술어를 평가할 수 없기 때문에 OFFSET 및 LIMIT를 밀어낼 수 없습니다. 필요한 순서대로 결과를 가져오기 때문에, 문서 수가 OFFSET 및 LIMIT에 도달하면 인덱스 스캔을 종료합니다.
간단하게 하기 위해 하나의 선행 키를 사용했습니다. 이 문장은 일반화되어 여러 선행 키에 적용할 수 있습니다.
물론 이 최적화 로직은 복잡합니다! 요구 사항에 대한 자세한 내용은 부록의 추가 정보를 참조하세요.
오버헤드 오프셋:
초기 여행 샘플에는 (유형 = "호텔")이 있는 약 900개의 문서가 있습니다. 실험을 위해 다음 쿼리를 사용하여 동일한 데이터를 몇 번 다시 삽입하여 데이터의 양을 늘립니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
insert into `travel-sample`(key UUID(), value t) select t from `travel-sample` t ; select count(*) from `travel-sample` where type = “hotel”; { "$1": 38318 } |
이제 이 쿼리를 시도해 보겠습니다:
|
1 2 3 4 5 6 7 8 |
SELECT * FROM `travel-sample` WHERE type = ‘hotel’ ORDER BY country, city OFFSET 38000 LIMIT 10; |
| 오프셋 | LIMIT | 응답 시간 |
| 38000 | 10 | 28.97ms |
오프셋이 증가하면 인덱서가 인덱스 항목을 탐색하는 데 소요되는 시간이 증가합니다. 이는 지연 시간과 처리량 모두에 영향을 미칩니다.
이 문제를 개선할 수 있을까요? 키세트 페이지 매김이 해결책이 될 수 있습니다. 페이지 매김 최적화에 대해 언급한 모든 규칙이 여기에도 적용됩니다. 또한 술어 중 하나가 고유해야 여러 페이지에 중복된 문서가 나타나지 않고 한 페이지에서 다른 페이지로 명확하게 이동할 수 있습니다. Couchbase를 사용하면 운이 좋았습니다. 버킷의 각 문서에는 고유한 문서 키가 있습니다. 이 키는 N1QL 쿼리에서 META().id에 의해 참조됩니다.
기본적인 인사이트는 고객은 일반적으로 결과 집합의 시작 부분에서 임의의 페이지가 아닌 다음 페이지를 원한다는 것입니다. 따라서 각 페이지를 순서대로 가져올 때 마지막 세트(ORDER BY 절에 따라 가장 높은/낮은)를 기억하세요. 그런 다음 이 정보를 사용하여 술어를 설정하고 다음 스캔을 위한 인덱스 위치를 지정하세요. 이렇게 하면 오프셋 중에 키 처리가 낭비되는 것을 방지할 수 있습니다.
예를 들어 보겠습니다:
인덱스 생성 켜기 여행 샘플 (유형, 국가, 도시, META().id);
- 첫 페이지를 가져옵니다. 인덱스, 프로젝션 및 ORDER BY 절에 META().id를 추가하여 각각에 고유한 값을 보장합니다.
|
1 2 3 4 5 6 7 8 |
SELECT country, city, META().id FROM `travel-sample` use index (ixtypectcy) WHERE type = "hotel" ORDER BY country, city, META().id OFFSET 0 LIMIT 5; |
결과:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
{ "city": "Avignon", "country": "France", "id": "000cb76b-ed85-4f56-9a6e-a6c300902944" }, { "city": "Avignon", "country": "France", "id": "0070d2ac-e411-4aeb-a1e7-4a00635d2d5a" }, { "city": "Avignon", "country": "France", "id": "01e4c1da-3749-43ce-88e3-37a00d0a376f" }, { "city": "Avignon", "country": "France", "id": "0352b5c9-fcbf-48bc-9cf8-f5760cc910a2" }, { "city": "Avignon", "country": "France", "id": "038c8a13-e1e7-4848-80ec-8819ff923602" } |
이 쿼리는 5.14밀리초 만에 실행되었습니다.
- 이제 오프셋을 사용하지 않고 다음 페이지에 대한 쿼리를 작성합니다:
|
1 2 3 4 5 6 7 8 9 10 |
SELECT country, city, META().id FROM `travel-sample` use index (ixtypectcy) WHERE type = "hotel" AND country >= “France” AND city >= “Avignon” AND META().id > "038c8a13-e1e7-4848-80ec-8819ff923602" ORDER BY country, city, META().id LIMIT 5; |
이 쿼리는 어떻게 구성했나요?
- WHERE 절의 모든 술어를 재사용합니다. (유형 = "호텔").
- 이제 ORDER BY의 키를 가져와서 추가 술어를 구성합니다. 따라서 마지막 쿼리에서 반환된 가장 높은 값을 가져와 새 술어를 추가하기만 하면 됩니다. 아직 문서 키를 추가하지 마세요. 이 경우 오름차순으로 정렬합니다. 따라서 Greatherthan-OR-Equal-To 연산자를 사용합니다.
이 경우 (국가 >= "프랑스" AND 도시 >= "아비뇽")입니다.
이제 고유한 값을 보장하기 위해 META().id 술어를 추가합니다.
(META().id > "038c8a13-e1e7-4848-80ec-8819ff923602")
다음 계획으로 5밀리초 안에 실행됩니다. 이후 페이지를 살펴보면서 다음 쿼리를 구성하는 단계를 반복하고 OFFSET을 피하기만 하면 됩니다. 비슷한 응답 시간으로 계속 진행할 수 있습니다!
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "#operator": "IndexScan2", "covers": [ "cover ((`travel-sample`.`type`))", "cover ((`travel-sample`.`country`))", "cover ((`travel-sample`.`city`))", "cover ((meta(`travel-sample`).`id`))", "cover ((meta(`travel-sample`).`id`))" ], "index": "ixtypectcy", "index_id": "5e43ce0471785942", "index_projection": { "entry_keys": [ 0, 1, 2 ], "primary_key": true }, "keyspace": "travel-sample", "limit": "5", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "\"hotel\"", "inclusion": 3, "low": "\"hotel\"" }, { "inclusion": 1, "low": "\"France\"" }, { "inclusion": 1, "low": "\"Avignon\"" }, { "inclusion": 0, "low": "\"038c8a13-e1e7-4848-80ec-8819ff923602\"" } ] } ], |
요약:
페이지 매김이 어떻게 작동하는지 배웠습니다. 또한 쿼리 페이지 매김 성능의 효율성을 개선하기 위해 Couchbase N1QL 옵티마이저가 인덱스를 활용하는 방법도 배웠습니다. 작성된 기술을 사용하여 키세트 페이지 매김 기술을 사용하여 OFFSET의 성능을 더욱 향상시킬 수 있습니다.
참조:
- https://www.couchbase.com/blog/optimizing-database-pagination-using-couchbase-n1ql/
- https://www.slideshare.net/MarkusWinand/p2d2-pagination-done-the-postgresql-way
- https://use-the-index-luke.com/sql/partial-results/fetch-next-page
- https://blog.jooq.org/2013/10/26/faster-sql-paging-with-jooq-using-the-seek-method/
부록: 인덱스 순서를 활용하기 위해 순서, 오프셋, 제한으로 쿼리 최적화하기
쿼리 ORDER BY 평가는 인덱서가 필요한 순서대로 결과를 반환하는 인덱스 순서를 활용할 수 있으며 쿼리는 순서를 수정할 필요가 없습니다(예: does grouping,join). 레코드 순서가 변경될 때마다 ORDER BY 절을 충족하기 위해 정렬 데이터를 사용해야 합니다.
- FROM 절에 집계가 포함된 경우 인덱스 순서는 사용되지 않습니다.
- GROUP BY 절이 있는 경우 인덱스 순서는 사용되지 않습니다.
- JOIN, NEST 또는 UNNEST를 사용할 때는 인덱스 순서가 사용되지 않습니다.
- DISTINCT가 있는 경우 인덱스 순서는 사용되지 않습니다.
- SET 연산자를 사용할 때는 인덱스 순서가 사용되지 않습니다. 여기에는 UNION, UNION ALL, INTERSECT, EXCEPT, EXCEPTALL이 포함됩니다.
- 기본 스캔이 포함된 경우 인덱스 순서는 사용되지 않습니다.
- 교차 또는 유니온 스캔이 포함된 경우 인덱스 순서는 사용되지 않습니다.
- 배열 인덱스가 포함된 경우 인덱스 순서는 사용되지 않습니다.
- 인덱스 정렬(ASC, DESC)이 인덱스 정렬과 일치하지 않는 경우 인덱스 순서가 사용되지 않습니다.
- 주문 용어가 인덱스 키와 일치하지 않는 경우 인덱스 순서가 사용되지 않습니다.
- 쿼리가 인덱스 순서를 악용하는 경우 쿼리의 설명에 Order 연산자가 나타나지 않습니다.
오프셋과 제한을 인덱스 스캔으로 푸시할 수 있습니다.
- 가 존재하고 인덱스 순서를 활용할 수 있는 경우
- ORDER BY 쿼리가 없는 경우
- 모든 술어는 스팬의 일부로 인덱서에게 푸시됩니다.
- 푸시된 스팬 값은 정확합니다.
- 스팬을 기반으로 하는 인덱서는 오탐을 생성하지 않습니다.
- 쿼리는 인덱스 스캔 결과를 더 이상 줄이지 않습니다.
- 오프셋을 인덱서에 밀어 넣으면 설명의 인덱스 스캔 섹션에 "오프셋"이 나타나고 설명 끝에 오프셋 연산자가 나타나지 않습니다.
- 제한이 인덱서에게 푸시되면 EXPLAIN의 IndexScan 섹션에 "제한"이 표시됩니다.
안녕하세요 케샤브, 저는 현재 카우치베이스에서 커서 페이지 매김을 구현하고 있으므로이 게시물에 로그를 남길 것이라고 생각했지만, 당신과 다르게 구현했는데 내가 놓친 것이 있는지 궁금합니다.
마지막에 사용한 예제에서는
SELECT 국가, 도시, META().id
FROM
여행 샘플인덱스 사용(익스텍티브)WHERE 유형 = "호텔"
AND 국가 >= "프랑스"
AND 도시 >= "아비뇽"
AND META().id > "038c8a13-e1e7-4848-80ec-8819ff923602"
국가, 도시, META().id로 주문하기
제한 5;
META().id > "038c8a13-e1e7-4848-80ec-8819ff923602"로 필터링하기 때문에 많은 레코드를 건너뛰는 것처럼 보이지만 국가 >= "프랑스"에 적용되는 레코드가 있을 수 있습니다.
AND 도시 >= "아비뇽", id가 "038c8a13-e1e7-4848-80ec-8819ff923602"보다 작은 경우