쿼리 구문이 제한되어 있습니다. 쿼리는 무제한입니다.
술어 푸시다운, 푸시 다운으로 그룹화, 페이지 매김 오프셋, 키세트 페이지 매김, 조인 최적화, 검색 최적화에서 모두 설명했습니다. 하지만 느리기는 하지만 쿼리의 기본적이고 간단한 실행 흐름을 이해하는 것이 중요합니다.
루카스 에더가 설명한 실제 SQL 실행 순서. N1QL은 SQL에서 영감을 얻었고 SQL을 밀접하게 따르기 때문에 여기에도 그 설명이 적용됩니다. 꼭 읽어보시기를 적극 권장합니다.
N1QL을 사용하면 시각적 설명을 통해 계획 구조와 데이터 흐름을 확인할 수 있습니다. 이렇게 하면 인덱스를 생성하여 성능을 최적화하기 전에 실행 순서를 쉽게 이해할 수 있습니다. 저는 기본 제공 여행 샘플을 사용했기 때문에 USE INDEX 힌트를 사용하여 기본 스캔을 강제로 수행했습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT hotel.name, hotel.country, COUNT(hr.ratings.Service) csr, RANK() OVER(ORDER BY COUNT(hr.ratings.Service) ), DENSE_RANK() OVER(ORDER BY COUNT(hr.ratings.Service)) FROM `travel-sample` AS hotel USE INDEX (def_primary) INNER JOIN `travel-sample` AS airport ON (hotel.country = airport.country) LEFT OUTER UNNEST hotel.reviews AS hr WHERE hotel.type = "hotel" AND airport.type = "airport" AND hr.ratings.Service >= 4 GROUP BY hotel.name, hotel.country HAVING COUNT(hr.ratings.Service) > 0 ORDER BY COUNT(hr.ratings.Service) OFFSET 0 LIMIT 10 |
다음은 시각적 계획입니다. 계획 실행과 데이터 흐름은 상향식입니다. 기본 인덱스 스캔과 보조 인덱스 스캔으로 시작하여 결과를 애플리케이션에 반환하기 전에 LIMIT 페이지 매김 연산자로 끝납니다.
시각적 설명은 대화형입니다. 아래 일부 연산자에 표시된 것처럼 각 연산자를 클릭하면 최적화 도구가 해당 연산자에 설정한 매개변수를 확인할 수 있습니다.
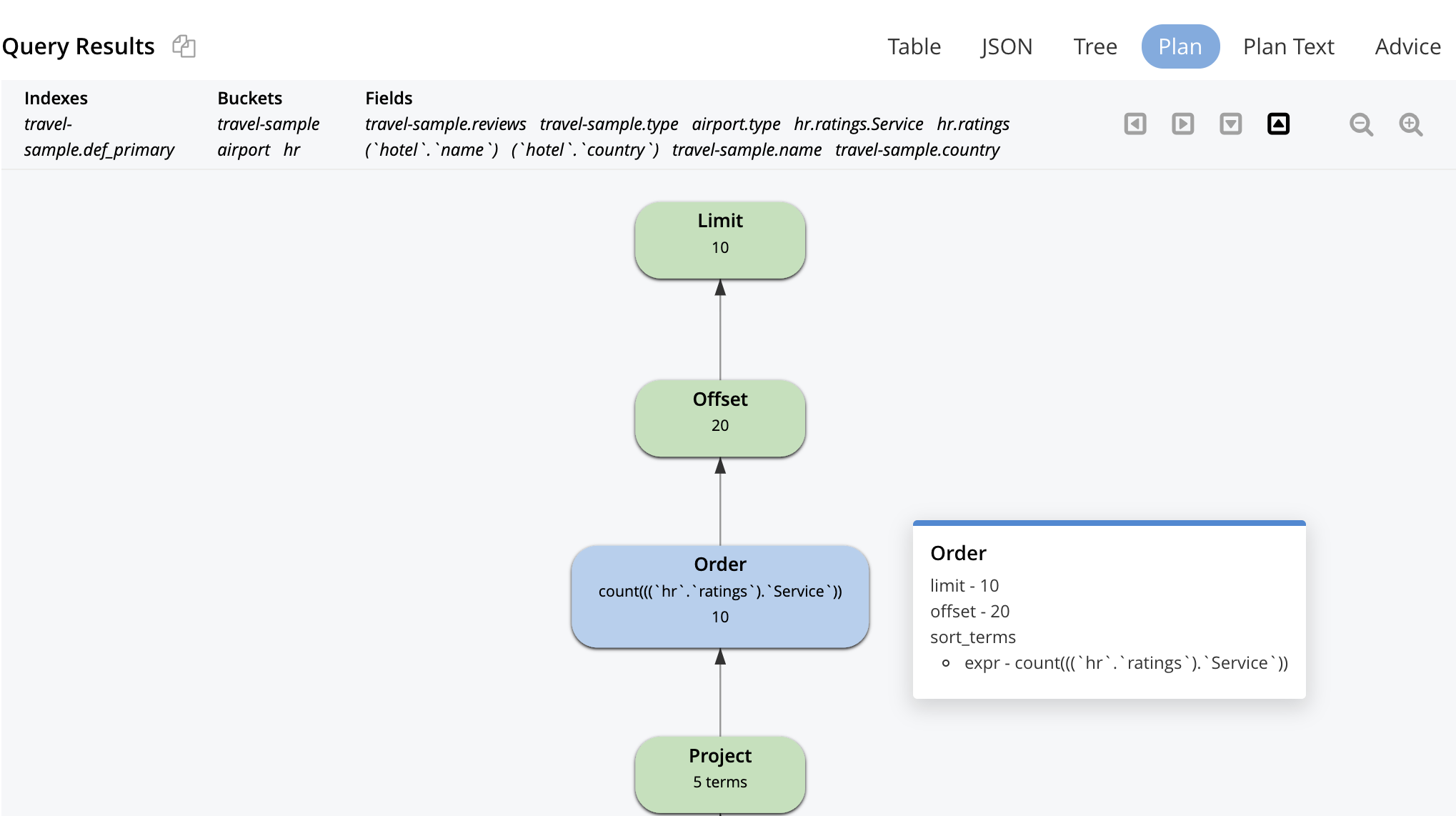
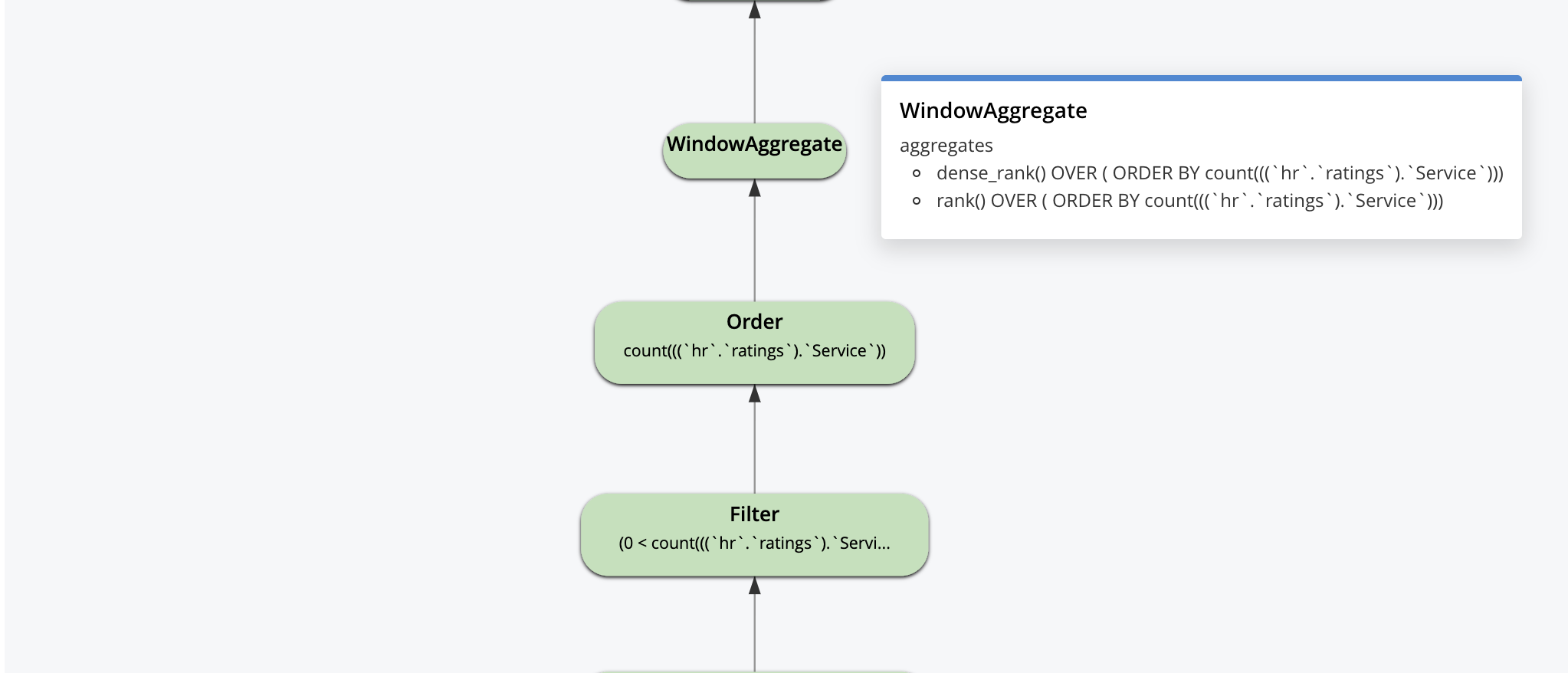
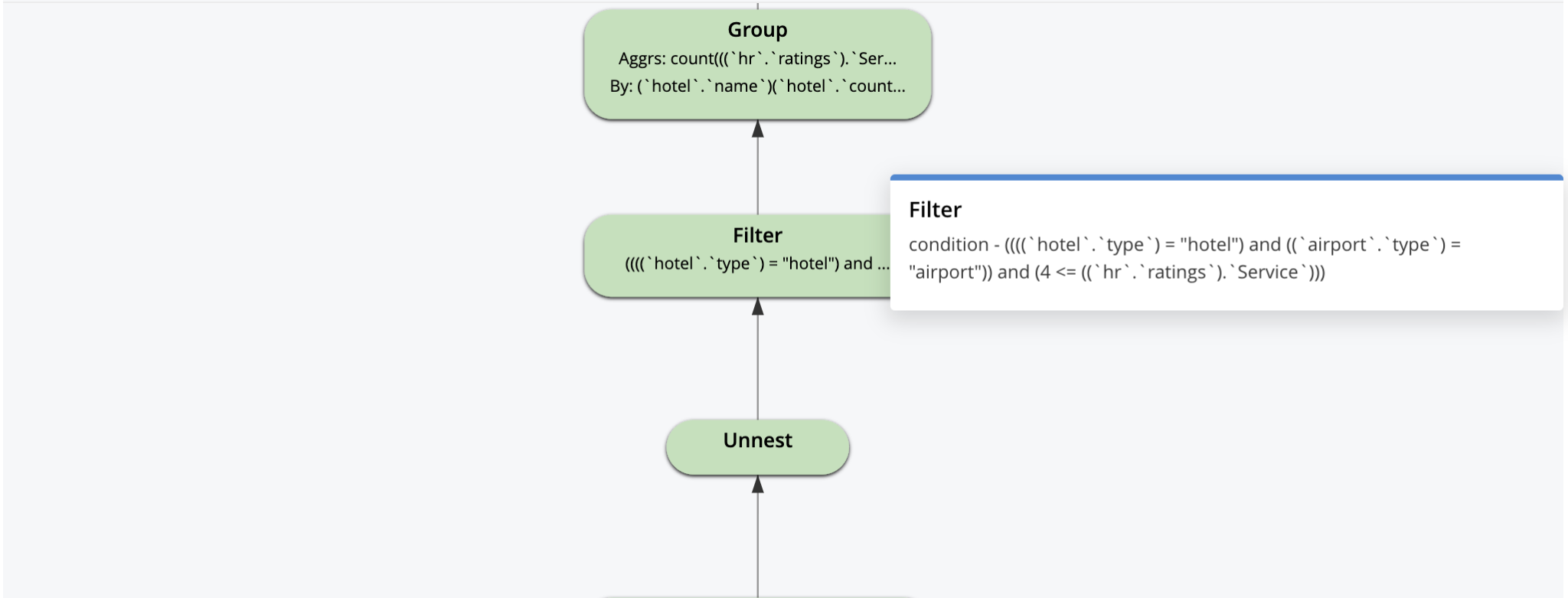
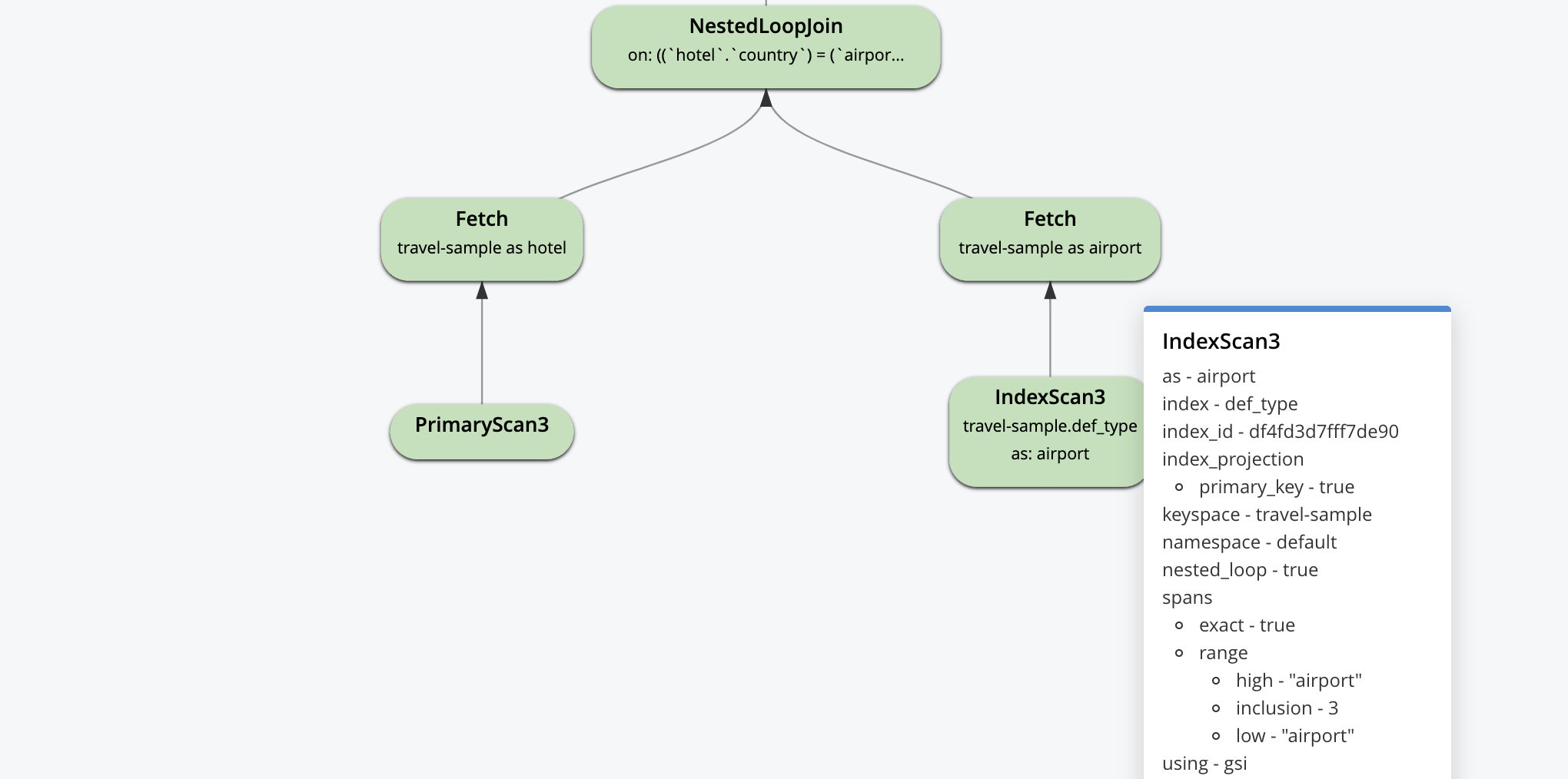
쿼리 계획은 논리적으로 이렇게 시작됩니다. 이 위에 있는 모든 최적화는 사람/도구에 의해 고려되고 최적화 도구가 모든 쿼리에 대한 데이터 흐름 머신을 구성하기 위해 선택합니다. 옵티마이저의 목표는 가능한 한 적은 작업을 수행하면서도 정확한 결과를 제공하는 머신을 만드는 것입니다.