Couchbase는 점점 더 많은 엔터프라이즈 애플리케이션이 NoSQL/JSON 데이터 모델을 활용하고 채택할 수 있도록 지원하는 데 중점을 두고 있습니다. N1QL은 기존 관계형 데이터베이스에서 이러한 전환을 간소화하며, 두 가지 장점을 모두 달성할 수 있는 수많은 기능으로 구축되었습니다. 4.5.1 릴리즈는 Couchbase Server 4.5의 뒤를 이어 N1QL에서 다양한 기능, 사용성 및 성능 개선을 제공합니다. 이러한 개선 사항은 고객이 중요하게 생각하는 많은 문제를 해결하며, 전반적으로 N1QL의 강점과 정교함을 보여줍니다.
새롭게 개선된 기능 중 일부는 기존 기능을 향상시키지만, SUFFIXES() 함수와 같은 다른 기능은 LIKE 쿼리의 성능을 대폭 개선하여 N1QL 쿼리를 강화합니다. 그 외에도 JSON 객체의 동적 생성 및 조작, 숫자 정밀도, 중첩 배열의 UPDATE 구문 등이 개선되었습니다,
시리즈가 필요할 것 같지만 이 블로그에서는 LIKE 쿼리 및 업데이트 개선 사항을 중점적으로 다룰 것입니다. 카우치베이스 서버 4.5.1을 참조하세요. 새로운 기능 그리고 릴리스 노트 에서 N1QL 개선 사항의 전체 목록을 확인하세요. N1QL 팀에 찬사를 보냅니다!
SUFFIXES()로 LIKE 쿼리를 효율적으로 패턴 매칭하기
패턴 일치는 SQL 쿼리에서 널리 사용되는 기능으로, 일반적으로 LIKE 연산자를 사용하여 수행합니다. 특히 효율적인 와일드카드 매칭은 매우 중요합니다. 'foo%'와 같은 경우는 표준 인덱스를 사용하여 효율적으로 구현할 수 있지만, '%foo%'와 같은 경우는 그렇지 않습니다. 이러한 선행 와일드카드를 사용한 패턴 일치는 부분 단어를 일치시키거나 일치하는 텍스트를 스마트 제안하는 검색창이 있는 모든 애플리케이션에 필수적입니다. 예를 들어
- 사용자가 공항 이름 몇 글자를 입력하기 시작하면 일치하는 공항을 팝업으로 표시하려는 여행 예약 사이트입니다.
- 제목에 특정 단어 또는 일부 단어가 포함된 모든 이메일을 찾는 사용자.
- 제목에 특정 키워드가 포함된 포럼 또는 블로그 게시글의 모든 주제를 찾습니다.
Couchbase Server 4.5.1에서 N1QL은 새로운 문자열 함수 SUFFIXES()를 추가하고 이를 Couchbase Server 4.5에 도입된 배열 인덱싱 기능과 결합하여 이 문제를 해결합니다. 이 기능을 함께 사용하면 "%foo%"와 같은 주요 와일드카드를 사용하는 LIKE 쿼리의 성능에 엄청난 차이를 가져올 수 있습니다. SUFFIXES()의 핵심 기능은 매우 간단하며, 기본적으로 주어진 문자열의 가능한 모든 접미사 하위 문자열의 배열을 생성합니다. 예를 들어
|
1 |
접미사("N1QL") = [ "N1QL", "1QL", "QL", "L" ] |
다음 그림은 다음 두 가지를 결합하는 독특한 기법을 보여줍니다. 접미사() 기능을 배열 인덱싱과 함께 사용하면 마법처럼 좋아요 쿼리 성능.
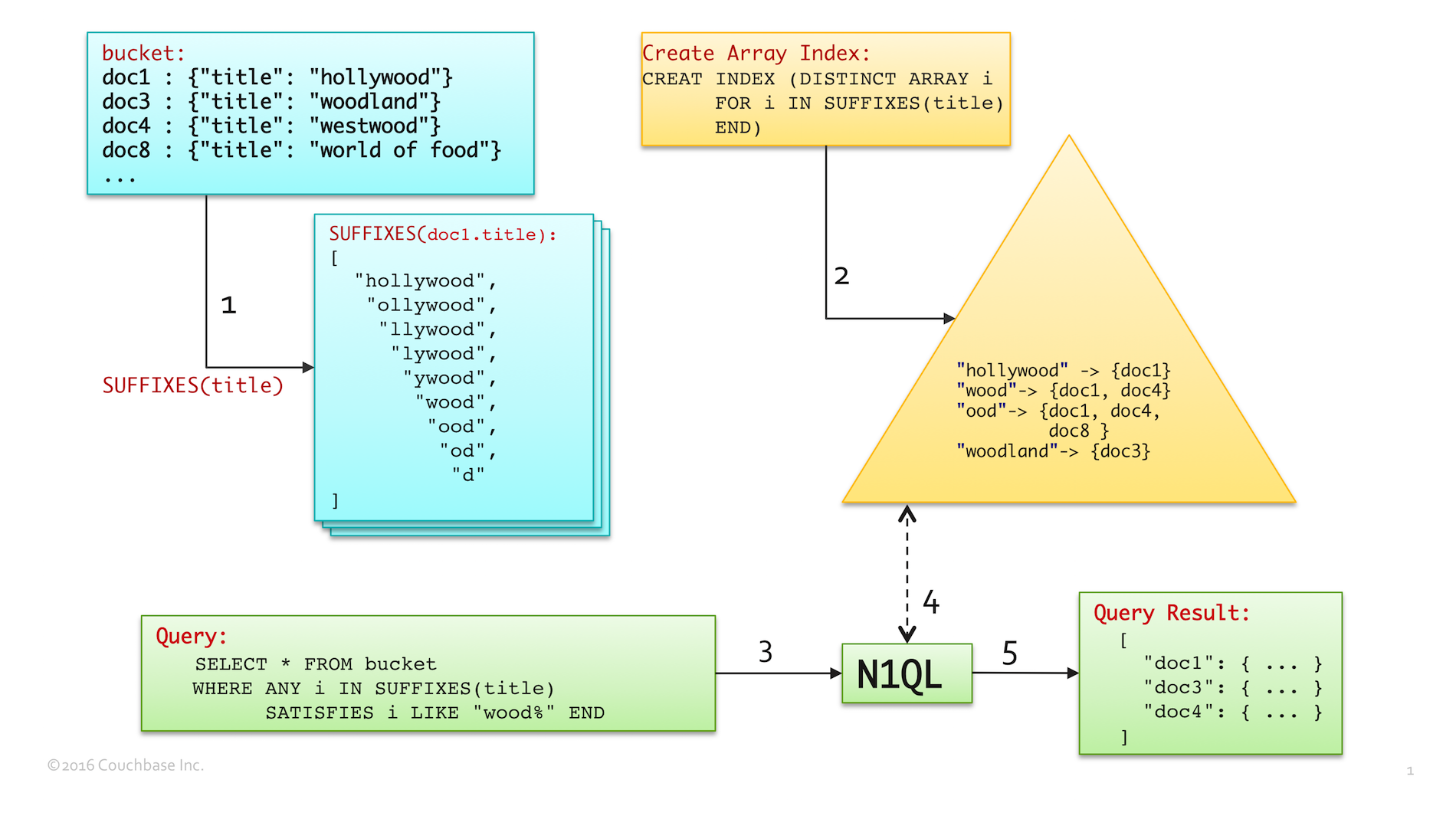
- Step1(파란색)은 다음에서 생성된 접미사 하위 문자열의 배열을 보여줍니다.
접미사()에 대한doc1.title - 2단계(노란색)는 1단계에서 생성된 접미사 하위 문자열로 생성된 배열 인덱스를 보여줍니다. 인덱스 항목은
"wood"은 다음을 가리킵니다.doc1그리고doc4를 사용하여 두 문서 제목의 접미사 하위 문자열 중 하나입니다. 마찬가지로"ood"은 다음을 가리킵니다.doc1,doc4및doc8. - 3단계(녹색)는 다음과 같은 쿼리를 실행합니다.
SELECT title FROM bucket WHERE title LIKE "%wood%". LIKE 술어는 ANY 구문을 사용하여 배열 인덱스를 사용하도록 변환됩니다. 배열 인덱싱 사용에 대한 자세한 내용은 문서를 참조하세요.- 앞의 와일드카드는 새로운
"wood%" 처럼술어. - 배열 인덱스 조회는 다음과 같이 정확한 변환입니다.
"wood"제목에 후행 하위 문자열이 있는 모든 문서를 가리킵니다."wood"
- 앞의 와일드카드는 새로운
- 4단계에서 N1QL은 배열 인덱스에서 조회하여 일치하는 모든 문서를 찾습니다.
"wood%". 그 반환{doc1, doc3, doc4}왜냐하면- 인덱스 조회는 스팬을 생성하여 다음에서 문서를 가져옵니다.
"wood"에"wooe" doc1그리고doc4배열 인덱스를 만들 때 SUFFIXES()에 의해 생성된 인덱스 항목 "wood"로 인해 일치합니다.doc3에 해당하는 인덱스 항목이 있기 때문에 일치합니다."우드랜드"
- 인덱스 조회는 스팬을 생성하여 다음에서 문서를 가져옵니다.
- 마지막으로 5단계에서 N1QL은 쿼리 결과를 반환합니다.
작동하는 예제를 살펴보겠습니다. 여행 샘플 문서에 대한 쿼리 성능이 12배 향상되었습니다.
- 값이 몇 단어의 텍스트 또는 구문인 문자열 필드가 있는 문서가 있다고 가정합니다. 예를 들어 랜드마크의 제목, 장소의 주소, 레스토랑 이름, 사람/장소의 전체 이름 등이 있으며, 이 설명을 위해 다음을 고려합니다.
title의랜드마크문서에여행 샘플. - 다음에 보조 인덱스 만들기
title필드를 사용하여접미사()로 설정합니다:
123만들기 INDEX IDX_제목_접미사켜기 `여행-샘플`(DISTINCT 배열 s FOR s IN 접미사(title) END)어디 유형 = "랜드마크";
접미사(제목)의 가능한 모든 접미사 하위 문자열을 생성합니다.title를 입력하면 색인에는 해당 문서를 참조하는 각 하위 문자열에 대한 항목이 있습니다. - 이제 하위 문자열이 있는 모든 문서를 찾는 다음 쿼리를 고려해 보겠습니다.
"land"intitle. 이 쿼리는 다음과 같은 계획을 생성하며 내 노트북에서 약 120초 만에 실행됩니다. 명확하게 알 수 있듯이 모든랜드마크문서를 적용한 다음"%land%"처럼술어를 사용하여 일치하는 모든 문서를 찾습니다.
12345678910111213141516171819202122232425262728293031323334353637383940414243설명 선택 * FROM `여행-샘플` 사용 INDEX(def_type) 어디 유형 = "랜드마크" AND title 좋아요 "%land%";[{"plan": {"#operator": "시퀀스","~어린이": [{"#operator": "IndexScan","index": "def_type","index_id": "e23b6a21e21f6f2","키스페이스": "travel-sample","네임스페이스": "default","spans": [{"범위": {"High": [""랜드마크""],"포함": 3,"낮음": [""랜드마크""]}}],"사용": "gsi"},{"#operator": "Fetch","키스페이스": "travel-sample","네임스페이스": "default"},{"#operator": "Parallel","~어린이": {"#operator": "시퀀스","~어린이": [{"#operator": "필터","조건": "((`여행 샘플`.`유형`) = "랜드마크") 및 ((`여행 샘플`.` 제목`) 같은 "%land%"))"}]} - Couchbase 4.5.1에서는 배열 인덱스를 활용하도록 이 쿼리를 재작성할 수 있습니다.
IDX_제목_접미사위 (2)에서 생성되었습니다.
12345678910111213141516171819202122232425262728293031323334353637383940414243444546설명 선택 title FROM `여행-샘플` 사용 INDEX(IDX_제목_접미사) 어디 유형 = "랜드마크" ANDANY s IN 접미사(title) 만족 s 좋아요 "land%" END;[{"plan": {"#operator": "시퀀스","~어린이": [{"#operator": "DistinctScan","scan": {"#operator": "IndexScan","index": "IDX_제목_접미사","index_id": "75b20d4b253214d1","키스페이스": "travel-sample","네임스페이스": "default","spans": [{"범위": {"High": [""lane""],"포함": 1,"낮음": [""land""]}}],"사용": "gsi"}},{"#operator": "Fetch","키스페이스": "travel-sample","네임스페이스": "default"},{"#operator": "Parallel","~어린이": {"#operator": "시퀀스","~어린이": [{"#operator": "필터","조건": "((`여행 샘플`.`유형`) = "랜드마크") 및 접미사((`travel-sample`.`title`))의 모든 `s`가 "land%") 끝)"},
참고하세요:
- (4)의 새 쿼리는
LIKE "land%"대신"%land%"처럼. 선행 와일드카드가 없는 전 술어'%'는 술어를 인덱스로 푸시다운할 수 없는 후자의 인덱스 조회보다 훨씬 더 효율적인 인덱스 조회를 생성합니다. - 배열 인덱스
IDX_제목_접미사의 가능한 모든 접미사 하위 문자열로 생성됩니다.title를 사용하므로 제목의 접미사 하위 문자열을 조회하면 일치하는 항목을 찾을 수 있습니다. - 위의 4.5.1 쿼리 계획 (4)에서 N1QL은 LIKE 술어를 인덱스 조회로 밀어내어 추가적인 패턴 일치 문자열 처리를 피합니다. 이 쿼리는 18ms에 실행되었습니다.
- 실제로 배열 인덱스를 적용하면 쿼리 실행 시간이 10ms로 12배 빨라집니다.
|
1 2 3 |
만들기 INDEX IDX_제목_접미사_표지 켜기 `여행-샘플`(DISTINCT 배열 s FOR s IN 접미사(title) END, title) 어디 유형 = "랜드마크"; |
이것을 참조하세요 블로그 를 참조하여 이 기능의 실제 적용에 대해 자세히 알아보세요.
중첩 배열과 함께 작동하도록 업데이트 기능 향상
엔터프라이즈 애플리케이션에는 복잡한 데이터가 있는 경우가 많으며, 여러 수준의 중첩된 개체와 배열이 있는 JSON 문서를 모델링해야 합니다. N1QL은 중첩 배열이 있는 이러한 문서를 탐색하고 쿼리하기 위한 복잡한 표현식과 언어 구성을 지원합니다. N1QL은 또한 다음을 지원합니다. 배열 인덱싱를 사용하여 배열 요소에 보조 인덱스를 생성한 다음 쿼리할 수 있습니다.
카우치베이스 서버 4.5.1에서는 업데이트 문 구문이 문서에서 중첩된 배열을 탐색하고 중첩된 배열 요소의 특정 필드를 업데이트하도록 개선되었습니다. 중첩 배열의 FOR-조항의 업데이트 문이 함수와 표현식을 평가하도록 개선되었으며, 새로운 구문은 여러 개의 중첩된 FOR 표현식을 사용하여 중첩 배열의 필드에 액세스하고 업데이트할 수 있습니다.
다음과 같이 중첩 배열이 있는 문서를 예로 들어보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ 항목: [ { 하위 항목: [ { 이름: "N1QL" }, { 이름: "GSI" } ] } ], 문서 유형: "couchbase" } |
새로운 업데이트 구문을 다양한 방식으로 사용하여 중첩 배열에 액세스하고 업데이트할 수 있습니다:
-
12업데이트 기본값 SET s.새로운 필드 = 'newValue'FOR s IN ARRAY_FLATTEN(항목[*].하위 항목, 1) END;
-
123업데이트 기본값SET s.새로운 필드 = 'newValue'FOR s IN ARRAY_FLATTEN(배열 i.하위 항목 FOR i IN 항목 END, 1) END;
-
123업데이트 기본값SET i.하위 항목 = ( 배열 객체 추가(s, 'newField', 'newValue')FOR s IN i.하위 항목 END ) FOR i IN 항목 END;
참고하세요:
- 그리고
SET-절은 다음과 같은 함수를 평가합니다.객체 추가()그리고array_flatten() FOR구문을 표현식과 함께 중첩된 방식으로 사용하여 서로 다른 중첩 수준에서 배열 요소를 처리할 수 있습니다.
작동하는 예로 샘플 버킷을 살펴보겠습니다. 여행 샘플 4.5.1과 함께 제공됩니다.
- 먼저 배열 일정에 특별 항공편의 중첩 배열을 추가해 보겠습니다.
여행 샘플버킷을 사용하세요.
123456업데이트 `여행-샘플`SET 일정[0] = {"day" : 7, "special_flights" :[ {"flight" : "AI444", "UTC" : "4:44:44"},{"flight" : "AI333", "UTC" : "3:33:33"}] }어디 유형 = "경로" AND 목적지공항 = "CDG" AND 소스공항 = "TLV"; - 다음 업데이트 문은 각 특별 항공편에 세 번째 필드를 추가합니다:
12345678910111213141516171819202122232425262728업데이트 `여행-샘플`SET i.특별 항공편 = ( 배열 객체 추가(s, 'newField', 'newValue' )FOR s IN i.특별 항공편 END )FOR i IN 일정 END어디 유형 = "경로" AND 목적지공항 = "CDG" AND 소스공항 = "TLV";선택 일정[0] 에서 `여행-샘플`어디 유형 = "경로" AND 목적지공항 = "CDG" AND 소스공항 = "TLV" LIMIT 1;[{"$1": {"day": 7,"special_flights": [{"flight": "AI444","newField": "newValue","UTC": "4:44:44"},{"flight": "AI333","newField": "newValue","UTC": "3:33:33"}]}}]
Couchbase Server 4.5.1 릴리스에는 더 많은 중요한 N1QL 개선 사항 및 성능 기능이 있습니다. 이에 대해서는 제 다음 블로그/파트2.
4.5.1 다운로드 를 클릭하고 사용해 보세요. 질문/의견이 있거나 얼마나 멋진지 알려주세요 ;-)
건배!!