SQL Server에서 Couchbase로 이동 3부: 앱 마이그레이션
이 블로그 게시물 시리즈에서는 관계형 배경이 있는 경우 문서 데이터베이스로 이동할 때 고려해야 할 사항을 정리해 보려고 합니다. 특히 Microsoft SQL Server와 카우치베이스 서버.
세 부분으로 나눠서 설명해 드리겠습니다:
- 데이터 모델링
- 데이터 마이그레이션
- 데이터를 사용하는 애플리케이션(이 블로그 게시물)
목표는 애플리케이션 계획 및 디자인에 적용할 수 있는 몇 가지 일반적인 가이드라인을 제시하는 것입니다.
따라 해보고 싶으신 분들을 위해 Couchbase와 SQL Server를 나란히 시연하는 애플리케이션을 만들었습니다. GitHub에서 소스 코드 받기를 클릭하고 다음 사항을 확인하세요. 카우치베이스 서버의 개발자 미리 보기 다운로드.
마이그레이션 대 재작성
새 웹 앱을 빌드하는 경우 Couchbase Server를 사용하는 것이 좋습니다. 기록 시스템. 유연한 데이터 모델링, 빠른 데이터 액세스, 손쉬운 확장성 등 모든 면에서 좋은 선택입니다.
카우치베이스 서버는 기존 웹 애플리케이션의 SQL Server를 보완할 수 있습니다. 세션 저장소 또는 캐시 저장소가 될 수 있습니다. 카우치베이스 서버의 이점을 누리기 위해 RDMBS를 교체할 필요는 없습니다. 다음과 같이 사용할 수 있습니다. 참여 시스템.
그러나 문서 데이터베이스를 기존 앱의 '기록 시스템'으로 만들려는 경우에는 해당 애플리케이션에 대해 무엇을 할 것인지 계획해야 합니다(이 블로그 시리즈의 앞부분에서 다룬 대로 데이터 모델링 및 데이터 마이그레이션 계획을 이미 세웠다고 가정할 때). 실제로 두 가지 옵션이 있습니다:
- 데이터/서비스 레이어 교체. 앱을 기본 지속성으로부터 분리하는 방식으로 앱을 구축했다면 SQL Server에서 Couchbase로 전환할 때 엄청난 이점을 얻을 수 있습니다. 예를 들어 SOA를 사용하는 경우 웹 애플리케이션을 많이 변경할 필요가 없을 수 있습니다.
- 애플리케이션 다시 빌드. 분리형 아키텍처가 없는 경우에는 과감히 애플리케이션의 상당 부분을 다시 작성/리팩터링해야 할 가능성이 높습니다. 이는 문서 데이터베이스로 전환할지 여부를 결정할 때 고려해야 할 상당한 비용이 될 수 있습니다. 마법의 묘약이 있다면 더 쉬워질 것이라고 말하고 싶습니다. 하지만 재구축 비용이 너무 크더라도 다음과 같은 경우에는 Couchbase Server를 계속 사용할 수 있다는 점을 기억하세요.
SQL Server와 함께 사용할 수 있습니다.
재구축하거나 교체해야 할 스택에는 다음이 포함됩니다:
- ADO.NET - 일반 ADO.NET 또는 Dapper와 같은 마이크로 OR/M을 사용하는 경우 Couchbase .NET SDK로 대체할 수 있습니다.
- OR/M - 엔티티 프레임워크, NHibernate, Linq2SQL 등입니다. Linq2Couchbase로 대체할 수 있습니다.
- 이를 직접 사용하는 모든 코드 - ADO.NET, OR/Ms 또는 기타 SQL Server 코드에 닿는 모든 코드는 Couchbase를 사용하기 위해 교체하거나 다른 추상화 계층을 도입하기 위해 다시 작성해야 합니다.
이 블로그 게시물의 나머지 부분은 재작성, 리팩토링 또는 새 프로젝트 시작에 적용되는 팁과 가이드라인입니다.
지원 대상
문서 데이터베이스는 관계형 데이터베이스보다 더 많은 비즈니스 로직을 데이터베이스에서 강제로 추출합니다. 카우치베이스 서버에 모든 기능이 있다면 좋겠지만, 항상 장단점이 존재합니다.
이 블로그 게시물에서는 Couchbase 사용으로 인한 애플리케이션 코딩의 변경 사항을 다룹니다. 이 블로그 게시물에서 다룰 내용은 다음과 같습니다. 왼쪽은 SQL Server 기능이고, 오른쪽은 Couchbase Server를 사용할 때 가장 가까운 기능입니다.
| SQL Server | 카우치베이스 서버 |
|---|---|
|
tSQL |
N1QL |
|
저장된 절차 |
서비스 계층 |
|
트리거 |
서비스 계층 |
|
조회수 |
맵/뷰 축소 |
|
자동 번호 |
카운터 |
|
OR/M(객체/관계형 매퍼) |
ODM(객체 데이터 모델) |
|
ACID |
단일 문서 ACID |
또한 다음과 같은 중요한 주제에 대해서도 다룰 예정입니다:
- 직렬화
- 보안
- 동시성
- SSIS, SSRS, SSAS
N1QL 사용
그리고 N1QL("니켈"로 발음) 쿼리 언어는 제가 Couchbase Server에서 가장 좋아하는 기능 중 하나입니다. 여러분은 이미 SQL 쿼리 언어에 익숙합니다. N1QL을 사용하면 전문 지식을 문서 데이터베이스에 적용할 수 있습니다.
다음은 몇 가지 예시입니다. N1QL과 tSQL의 유사점:
| tSQL | N1QL |
|---|---|
|
DELETE FROM [table] WHERE val1 = 'foo' |
다음에서 삭제 |
|
SELECT * FROM [table] |
SELECT *에서 |
|
SELECT t1.* , t2.* FROM [table1] t1 JOIN [table2] t2 ON t1.id = t2.id |
SELECT b1.* , b2.* FROM |
|
INSERT INTO [table] (key, col1, col2) VALUES (1, 'val1′,'val2') |
삽입 |
|
UPDATE [table] SET val1 = 'newvalue' WHERE val1 = 'foo' |
업데이트 |
덕분에 N1QL를 사용하면 SQL 쿼리를 마이그레이션하는 것이 다른 문서 데이터베이스보다 덜 어렵습니다. 데이터 모델이 다를 수 있으며, tSQL의 모든 기능을 N1QL에서 (아직) 사용할 수 있는 것은 아닙니다. 하지만 대부분의 경우 기존의 tSQL 작성 전문 지식을 적용할 수 있습니다.
장바구니로 돌아가서, 다음은 특정 사용자에 대한 장바구니 정보를 가져오는 간단한 tSQL 쿼리의 예입니다:
|
1 2 3 4 |
SELECT c.Id, c.DateCreated, c.[User], i.Price, i.Quantity FROM ShoppingCart c INNER JOIN ShoppingCartItems i ON i.ShoppingCartID = c.Id WHERE c.[User] = 'mschuster' |
Couchbase에서는 쇼핑 카트를 단일 문서로 모델링할 수 있으므로 대략 동등한 쿼리가 될 수 있습니다:
|
1 2 3 4 |
SELECT META(c).id, c.dateCreated, c.items, c.`user` FROM `sqltocb` c WHERE c.type = 'ShoppingCart' AND c.`user` = 'mschuster'; |
N1QL에는 JOIN 기능, 아니요 JOIN 는 이 장바구니 쿼리에 필요합니다. 모든 장바구니 데이터는 여러 테이블과 행에 분산되어 있지 않고 단일 문서에 있습니다.
결과는 다음과 같습니다. 정확히 와 동일합니다. N1QL 쿼리는 보다 계층적인 결과를 반환합니다. 하지만 쿼리 could 를 사용하여 수정할 수 있습니다. UNNEST 를 눌러 필요한 경우 결과를 평평하게 만듭니다. UNNEST 는 문서 내 조인는 JSON용 SQL을 작성할 때 필요한 기능입니다.
카우치베이스 이외의 많은 문서 데이터베이스에서는 쿼리 생성을 위한 API를 배워야 할 가능성이 높으며, tSQL 경험을 적용하여 속도를 높일 수 없습니다. 번역이 항상 쉽다는 말은 아니지만 다른 대안에 비해 상대적으로 쉬울 것입니다. 만약 여러분이 new 프로젝트에 참여하신다면 SQL 작성 기술을 계속 활용할 수 있다는 사실에 기뻐하실 것입니다!
N1QL과 상호 작용하기 위해 C#를 작성할 때 알아야 할 몇 가지 중요한 개념이 있습니다.
스캔 일관성. N1QL 쿼리를 실행할 때 몇 가지 스캔 일관성 옵션이 있습니다. 스캔 일관성은 N1QL 쿼리가 인덱싱에 대해 어떻게 작동해야 하는지를 정의합니다. 기본 동작은 "Not Bounded"이며 최상의 성능을 제공합니다. 다른 쪽 끝에는 "요청 플러스"가 있으며 최상의 일관성을 제공합니다. 또한 "AtPlus"도 있는데, 이는 좋은 중간 지점이지만 조금 더 많은 작업이 필요합니다. I 스캔 일관성에 대한 블로그 를 지난 6월에 발표했으며, .NET에서 N1QL 작성을 시작하기 전에 검토해 볼 가치가 있습니다.
매개변수화. N1QL 쿼리를 만드는 경우 다음을 수행하는 것이 중요합니다. 매개변수화 사용 를 사용하여 SQL 인젝션을 방지할 수 있습니다. N1QL에는 위치(번호가 매겨진) 매개변수와 네임드 매개변수라는 두 가지 옵션이 있습니다.
다음은 C#에서 사용되는 스캔 일관성과 파라미터화의 예시입니다:
|
1 2 3 4 |
var query = QueryRequest.Create(n1ql); query.ScanConsistency(ScanConsistency.RequestPlus); query.AddNamedParameter("userId", id); var result = _bucket.Query<Update>(query); |
이 글에서 자세히 설명하지는 않겠습니다. N1QL 쿼리 언어 는 매우 심오한 주제이기 때문에 이보다 더 이상 설명할 수 없습니다. 하지만 다음을 수행할 수 있습니다. N1QL의 기본 사항을 확인하세요. 그리고 대화형 N1QL 자습서 시작하기.
SQL 저장 프로시저
Couchbase에는 저장 프로시저(스프로크)에 해당하는 것이 없습니다. 아직 서비스 계층이 없고 도메인 간에 일부 로직을 공유하기 위해 스폭을 사용하는 경우 서비스 계층을 만들고 로직을 해당 계층으로 이동하는 것이 좋습니다.
사실 저는 이 블로그 시리즈의 2부와 3부 중 어느 쪽에 스프로크가 속할지 잘 모르겠습니다. 엔터프라이즈 애플리케이션의 일반적인 티어입니다:
- 웹 계층(UI - Angular/React/Traditional ASP.NET MVC)
- 서비스 계층(ASP.NET WebApi)
- 데이터베이스
스프로크는 데이터베이스에 있지만 로직을 포함하고 있습니다. 서비스 계층에는 비즈니스 로직도 포함되어 있습니다. 그렇다면 이것들을 데이터로 볼까요, 아니면 기능으로 볼까요?
트위터 설문조사를 통해 결정했습니다.
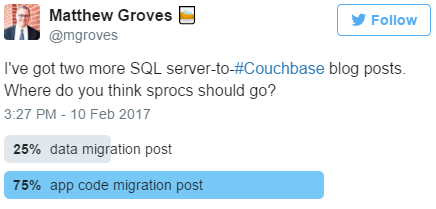
하지만 이미 서비스 계층이 있는 경우에는 스프로크 로직을 해당 계층으로 옮기는 것이 좋습니다. 서비스 티어가 없는 경우에는 서비스 티어를 만드세요. 이렇게 하면 데이터베이스와 UI 사이에 위치하게 됩니다.
이 시리즈의 소스 코드에서는 단일 저장 프로시저를 만들었습니다.
|
1 2 3 4 5 6 7 8 9 |
CREATE PROCEDURE SP_SEARCH_SHOPPING_CART_BY_NAME @searchString NVARCHAR(50) AS BEGIN SELECT c.Id, c.[User], c.DateCreated FROM ShoppingCart c WHERE c.[User] LIKE '%' + @searchString + '%' END GO |
이 스프로크는 다음과 같이 엔티티 프레임워크에서 실행할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public List<ShoppingCart> SearchForCartsByUserName(string searchString) { var cmd = _context.Database.Connection.CreateCommand(); cmd.CommandText = "SP_SEARCH_SHOPPING_CART_BY_NAME @searchString"; cmd.Parameters.Add(new SqlParameter("@searchString", searchString)); _context.Database.Connection.Open(); var reader = cmd.ExecuteReader(); var carts = ((IObjectContextAdapter) _context) .ObjectContext .Translate<ShoppingCart>(reader, "ShoppingCarts", MergeOption.AppendOnly); var result = carts.ToList(); _context.Database.Connection.Close(); return result; } |
그런데 그 엔티티 프레임워크 스프로크 코드가 못생겼어요. 제가 잘못한 걸까요? EF를 비방하려는 것은 아니지만, 일반적으로 저는 제 경력에서 OR/M과 스프로크를 함께 사용한 적이 많지 않습니다. 물론 ADO.NET이나 Dapper 코드가 더 짧고 깔끔하긴 하겠죠.
이것은 매우 간단한 스프로크이지만 기본적인 검색 기능을 도입한 것입니다. 이러한 스프로크의 장점은 다음과 같습니다:
- 재사용: 동일한 스프로크를 다른 애플리케이션에서 재사용할 수 있습니다.
- 추상화: 스프로크 구현은 변경하거나 개선할 수 있습니다. 이 경우 기본
좋아요를 보다 강력한 전체 텍스트 검색으로 전환할 수 있습니다.
서비스 계층을 도입할 때 어떤 접근 방식을 취하든 동일한 이점을 제공해야 합니다. 저는 스폭을 대신할 ASP.NET WebApi 엔드포인트를 만들었습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[HttpGet] [Route("api/searchByName/{searchString}")] public IHttpActionResult SearchByName(string searchString) { var n1ql = @"SELECT META(c).id, c.`user` FROM `sqltocb` c WHERE c.type = 'ShoppingCart' AND c.`user` LIKE $searchString"; var query = QueryRequest.Create(n1ql); query.AddNamedParameter("searchString", "%" + searchString + "%"); query.ScanConsistency(ScanConsistency.RequestPlus); var results = _bucket.Query<ShoppingCart>(query).Rows; return Json(results); } |
참고: 샘플 코드의 단순화를 위해 이 엔드포인트는 실제로는 동일한 웹 프로젝트에 있지만 프로덕션에서는 자체 프로젝트로 이동하여 별도로 배포해야 합니다.
이 엔드포인트는 위의 스프로크와 유사한 성격의 N1QL 쿼리를 보유합니다. 동일한 이점이 있는지 확인해 보겠습니다:
- 재사용? 예. 이 엔드포인트는 자체 서버에 배포하여 다른 애플리케이션에서 재사용할 수 있습니다.
- 추상화? 다시 말하지만 그렇습니다. 이 구현은 순진한
좋아요접근 방식을 사용하도록 전환하여 개선할 수 있습니다. 카우치베이스의 전체 텍스트 검색 기능 API를 변경하지 않고도 사용할 수 있습니다.
엔티티 프레임워크를 통해 스프로크를 호출하는 대신 이 엔드포인트는 HTTP를 통해 호출됩니다. 다음은 RestSharp 라이브러리를 사용하는 예제입니다:
|
1 2 3 4 5 6 7 8 9 |
public List<ShoppingCart> SearchForCartsByUserName(string searchString) { // typically there would be authentication/authorization with a REST call like this var client = new RestClient(_baseUrl); var request = new RestRequest("/api/searchByName/" + searchString); request.AddHeader("Accept", "application/json"); var response = client.Execute<List<ShoppingCart>>(request); return response.Data; } |
새 프로젝트를 구축하는 경우 기업 전체에서 사용할 것을 예상하여 서비스 계층을 만드는 것이 좋습니다. 이렇게 하면 해당 코드를 데이터베이스에 넣지 않고도 일반적으로 스폭이 제공하는 것과 동일한 "공유 코드"를 사용할 수 있습니다.
이는 SQL Server에서도 마찬가지입니다. 함수, 사용자 정의 유형, 규칙, 사용자 정의 CLR 객체.
참고: 위의 스프로크 예시는 선택 를 사용하지 않았습니다. 이 경우, 아래에서 설명하는 MapReduce 보기를 대신 생성할 수 있습니다. 하지만 MapReduce 보기는 문서를 변경할 수 없으므로 서비스 계층 접근 방식이 스폭을 대체하는 더 나은 일반적인 솔루션입니다.
SQL 트리거
스프로크가 아직 논란이 되지 않았다면 대화에서 트리거를 떠올려 보세요. 저장 프로시저와 마찬가지로 일반적으로 트리거 로직을 데이터베이스에서 벗어나 서비스 계층으로 옮기는 것이 좋습니다. 소프트웨어 프로젝트가 많은 트리거 또는 복잡한 트리거에 의존하거나 복잡한 트리거가 많은 경우에는 다른 프로젝트에서 Couchbase Server를 사용해 볼 때까지 기다리는 것이 좋습니다.
그렇긴 하지만 트리거와 거의 비슷한 수준의 최첨단 기능을 개발 중입니다. 이에 관심이 있으시면 저에게 연락해 주시고, 다음에도 계속 지켜봐 주세요. 카우치베이스 블로그 에서 최신 정보를 확인하세요.
조회수
SQL Server에서 뷰는 서버에 복잡한 쿼리를 저장하는 방법일 뿐만 아니라 몇 가지 성능상의 이점을 제공합니다. Couchbase에서는 맵/축소 뷰가 한동안 비슷한 기능을 제공해 왔습니다. 대부분의 경우, 뷰가 제공하는 기능은 N1QL을 통해 보다 표현적인 방식으로 제공될 수 있습니다. 그러나 뷰는 사라지지 않을 것이며 때로는 뷰를 사용하면 이점이 있습니다.
맵/축소 보기를 정의하고 Couchbase 클러스터에 저장할 수 있습니다. 이러한 뷰를 만들려면 '맵' 함수(JavaScript 사용)를 정의하고 선택적으로 '축소' 함수(역시 JavaScript 사용)를 정의하면 됩니다.
Couchbase 콘솔 UI에서 인덱스 → 뷰 → 뷰 만들기로 이동합니다. 디자인 문서를 만들고 해당 디자인 문서 내에 뷰를 만듭니다.
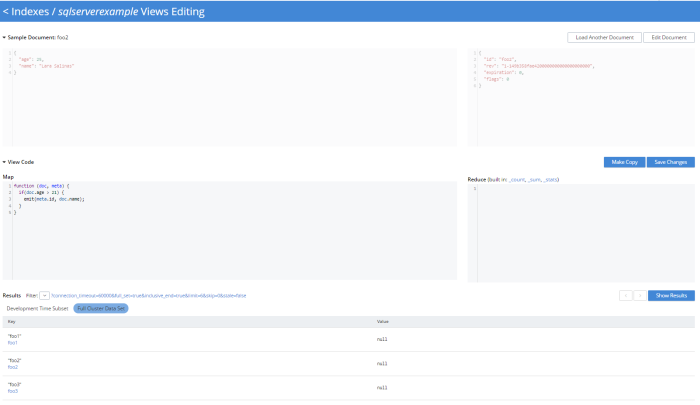
중앙에는 작업 중인 맵/축소 코드가 있습니다. 샘플 문서와 메타데이터도 표시되어 시각적 도움을 제공하며, 하단에는 뷰 실행을 위한 몇 가지 옵션이 있습니다.
보기가 작동하는 방식에 대한 자세한 내용은 맵리듀스 뷰 문서.
간단한 예로, 나이가 21세 이상인 사람만 나열하는 뷰를 만들고 싶습니다.
|
1 2 3 4 5 |
function (doc, meta) { if(doc.age > 21) { emit(meta.id, doc.name); } } |
이 보기는 문서의 키와 '이름' 필드의 값을 표시합니다. 내 버킷에 다음과 같은 문서가 포함되어 있다고 가정해 보겠습니다:
|
1 2 3 |
foo1 {"age":17,"name":"Carmella Albert"} foo2 {"age":25,"name":"Lara Salinas"} foo3 {"age":35,"name":"Teresa Johns"} |
그러면 뷰의 결과는 다음과 같습니다:
| 키 | 가치 |
|---|---|
|
"foo2" |
"라라 살리나스" |
|
"foo3" |
"테레사 존스" |
이러한 보기의 결과는 일정 간격으로 자동으로 업데이트되며 문서가 변경될 때 점진적으로 업데이트됩니다. 즉, 기본적으로 보기의 결과는 다음과 같습니다. 결국 실제 문서와 일관성을 유지합니다. 개발자는 다음을 수행할 수 있습니다. 일관성 수준 지정 (또는 느린 속도)를 설정할 수 있습니다. 이는 성능에 영향을 미칩니다.
뷰 매핑/축소는 매우 복잡한 로직이 있는 경우 N1QL로 작성하는 것보다 자바스크립트로 작성하는 것이 더 쉬울 때 매우 유용할 수 있습니다. 또한 쓰기가 많은 시스템에서 작업할 때 성능상의 이점이 있을 수 있습니다.
.NET에서 다음을 사용하여 뷰에 액세스할 수 있습니다. ViewQuery.
|
1 2 3 4 |
var query = new ViewQuery().From("viewdesigndocument", "viewname").Limit(10); var people = bucket.Query<dynamic>(query); foreach (var person in people.Rows) Console.WriteLine(landmark.Key); |
또는 보기를 사용하는 대신 N1QL 쿼리를 만들 수도 있습니다. 대부분의 경우 N1QL이 더 쉽게 작성할 수 있으며 성능 차이는 무시할 수 있을 정도입니다. 보기와 달리 N1QL 쿼리는 서비스 계층에 존재합니다. 현재 Couchbase Server 클러스터에 "N1QL 보기"를 저장할 수 있는 방법은 없습니다.
직렬화/역직렬화
N1QL, 보기 또는 키/값 연산을 사용하든, JSON이 직렬화 및 역직렬화되는 방식을 고려하는 것이 중요합니다.
NET SDK는 다음을 사용합니다. 뉴턴슨 JSON.NET. NET 개발자 중 해당 도구에 익숙하다면(그리고 그렇지 않은 사람은 없을 것입니다), 동일한 속성( JsonProperty, JsonConverter등). 일부 에지 케이스에서는 Couchbase .NET SDK를 사용하여 사용자 정의 직렬화기를 만드는 것이 유용할 수 있습니다. 자세한 내용은 직렬화 및 비 JSON 문서에 대한 문서 에서 자세한 내용을 확인하세요.
보안
카우치베이스는 역할 기반 액세스 제어(RBAC) 관리자용입니다.
Couchbase는 LDAP와 통합하여 Couchbase 관리자를 관리하고 사용자에게 역할을 할당할 수 있습니다. 또한 내부적으로 읽기 전용 사용자를 만들 수도 있습니다.
Couchbase RBAC 시스템에 더 강력한 변경 사항과 개선 사항이 예정되어 있으니 계속 지켜봐 주세요. 사실, 저는 다음과 같이 시작하는 것이 좋습니다. 월간 개발자 빌드 확인곧 이 영역에서 흥미로운 개선 사항과 기능을 볼 수 있을 것으로 기대합니다!
동시성
동시성은 특히 웹 애플리케이션에서 자주 다루어야 하는 문제입니다. 여러 사용자가 동시에 동일한 문서를 변경하는 작업을 수행할 수 있습니다.
SQL Server 사용 비관적 잠금 를 기본값으로 설정합니다. 즉, SQL Server는 행이 경합 중일 것으로 예상하여 방어적으로 작동합니다. 비정규화된 데이터는 여러 테이블과 여러 행에 분산되어 있기 때문에 관계형 데이터베이스의 경우 이는 합리적인 기본값입니다. SQL Server에는 낙관적 잠금 또한, 다양한 거래 수준.
카우치베이스는 또한 동시성을 처리하는 두 가지 옵션, 즉 낙관적 옵션과 비관적 옵션을 제공합니다.
최적화. 이를 "낙관적"이라고 부르는 이유는 문서가 자주 경합될 가능성이 거의 없을 때 가장 효과적이기 때문입니다. 낙관적인 가정을 하고 있는 것입니다. Couchbase에서는 다음을 사용하여 이 작업을 수행합니다. CAS(비교 및 스왑). 문서를 검색하면 CAS 값(단순한 숫자)을 포함한 메타 데이터가 함께 제공됩니다. 해당 문서를 업데이트할 때 CAS 값을 입력하면 됩니다. 값이 일치하면 낙관적인 판단이 적중한 것이며 변경 사항이 저장됩니다. 일치하지 않으면 작업이 실패하고 병합, 오류 메시지 등의 처리를 해야 합니다. CAS 값을 입력하지 않으면 변경 사항이 무조건 저장됩니다.
비관적. 이 방법을 "비관적"이라고 부르는 이유는 문서가 많이 변조될 것이라는 것을 알고 있을 때 가장 효과적이기 때문입니다. 비관적인 가정을 하고 문서를 강제로 잠그는 것입니다. 사용하는 경우 GetAndLock 를 누르면 문서가 잠기므로 수정할 수 없습니다. 문서는 최대 15초 동안 잠깁니다. 더 낮은 값을 설정할 수 있습니다. 문서를 명시적으로 잠금 해제할 수도 있지만 그렇게 하려면 CAS 값을 추적해야 합니다.
자세한 내용은 다음 문서를 참조하세요. 동시 문서 변경.
자동 번호
카우치베이스 서버는 현재 자동 키 생성이나 순차적 키 번호 지정 기능을 제공하지 않습니다.
그러나 다음을 수행할 수 있습니다. 를 사용하여 카운터 기능 를 사용하여 비슷한 작업을 수행할 수 있습니다. 이 아이디어는 문서가 특별한 카운터 문서로 따로 설정된다는 것입니다. 이 문서는 원자 연산으로 증분될 수 있으며, 이 숫자는 생성되는 새 문서의 일부 또는 전체 키로 사용될 수 있습니다.
에릭슨의 개발자인 라트노팜 차크라바티는 최근 다음과 같은 글을 썼습니다. 카우치베이스 서버로 순차적으로 번호가 매겨진 키를 만드는 방법에 대한 게스트 블로그 게시물. 그의 예제는 Java로 되어 있지만 충분히 쉽게 따라할 수 있으므로 여기서는 그의 예제를 반복하지 않겠습니다.
OR/Ms 및 ODM
SQL Server를 사용 중이라면 OR/Ms(객체 관계형 매퍼)에 익숙하실 것입니다. 엔티티 프레임워크, NHibernate, Linq2SQL 등이 OR/M입니다. OR/M은 C#의 구조화된 데이터와 관계형 데이터베이스의 정규화된 데이터 사이의 격차를 해소하기 위해 시도합니다. 또한 일반적으로 Linq 공급자, 작업 단위 등과 같은 다른 기능도 제공합니다. 저는 OR/M이 80/20 규칙을 따른다고 생각합니다. 80%의 시간 동안은 매우 유용하지만 나머지 20%는 골칫거리가 될 수 있습니다.
문서 데이터베이스의 경우, C# 개체를 JSON으로 직렬화/역직렬화할 수 있고 정규화된 테이블 집합으로 분할할 필요가 없으므로 임피던스 불일치가 훨씬 적습니다.
그러나 OR/M이 제공하는 다른 기능도 문서 데이터베이스에서 유용하게 사용할 수 있습니다. 이와 동등한 도구를 ODM(객체 문서 모델)이라고 합니다. 이러한 도구는 문서에 매핑할 클래스 집합을 정의하는 데 도움이 됩니다. Ottoman과 Linq2Couchbase는 각각 Node와 .NET용 Couchbase에 널리 사용되는 ODM입니다.
Linq2Couchbase 에는 Linq 공급자가 있습니다. 아직 공식적으로 지원되는 프로젝트는 아니지만 제가 사용해 본 것 중 가장 완벽한 Linq 공급자 중 하나이며 Couchbase 고객들이 프로덕션에 사용하고 있습니다.
다음은 엔티티 프레임워크 및 NHibernate.Linq 사용자에게 다소 익숙해 보일 Linq2Couchbase 설명서의 예제입니다:
|
1 2 3 4 5 |
var context = new BucketContext(ClusterHelper.GetBucket("travel-sample")); var query = (from a in context.Query<AirLine>() where a.Country == "United Kingdom" select a). Take(10); |
이 블로그 시리즈의 샘플 코드에서도 Linq2Couchbase를 사용했습니다. 다음은 쇼핑 카트에 대한 예제입니다:
|
1 2 3 4 5 6 7 |
var query = from c in _context.Query<ShoppingCart>() where c.Type == "ShoppingCart" // could use DocumentFilter attribute instead of this Where orderby c.DateCreated descending select new {Cart = c, Id = N1QlFunctions.Meta(c).Id}; var results = query.ScanConsistency(ScanConsistency.RequestPlus) .Take(10) .ToList(); |
Linq2Couchbase는 훌륭한 Linq 제공업체일 뿐만 아니라 실험적인 변경 사항 추적 기능도 제공합니다. 꼭 확인해 볼 가치가 있습니다. 이 프로젝트의 핵심 기여자 중 한 명인 Brant Burnett은 또한 카우치베이스 전문가. 그는 Couchbase Connect 2016에서 다음과 같은 세션을 발표했습니다. 데이터에 링킹하기: SQL에서 쉽게 전환하기.
[유튜브 https://www.youtube.com/watch?v=X__mC2FArp4&w=560&h=315]
거래
이미 단일 문서의 트랜잭션에 대한 비관적 잠금과 낙관적 잠금에 대해 다루었습니다. 이 때문에 Couchbase는 문서 단위의 ACID 트랜잭션을 지원한다고 말할 수 있습니다. 현재 Couchbase는 여러 문서 간의 ACID 트랜잭션은 지원하지 않습니다.
다시 생각해보면 데이터 모델링에 관한 첫 번째 블로그 게시물를 사용하면 관계형 모델에 비해 다중 문서 트랜잭션의 필요성이 줄어들거나 제거되는 경우가 많습니다. 쇼핑 카트와 같은 개념은 관계형 모델에서는 여러 테이블의 행이 필요할 수 있지만, Couchbase에서는 단일 문서 모델만 있으면 됩니다.
참조 모델을 따르는 경우, 소셜 미디어 예제에서와 같이 첫 번째 블로그 게시물를 사용하면 트랜잭션이 부족하다고 걱정할 수 있습니다. 이는 데이터 모델을 만들 때 사용 사례에 대해 생각하는 것이 중요하다는 것을 강조합니다. 트랜잭션이 사용 사례에 필수적인 경우, 데이터 모델은 종종 이를 수용하도록 구조화될 수 있습니다. 문의만 주시면 기꺼이 도와드리겠습니다!
다중 문서 트랜잭션 지원은 향후 충분한 카우치베이스 개발자와 고객이 요청하거나 필요로 할 경우 제공될 수 있습니다. 따라서 문서 데이터베이스 데이터 모델을 설계하는 연습을 진행하면서 트랜잭션은 다음과 같습니다. still 가 프로젝트의 중요한 부분이라면 Couchbase는 프로젝트의 적어도 일부에 대해 최고의 "기록 시스템"이 아닐 수 있습니다. 하지만 필요한 경우 확장, 캐싱, 성능 및 유연성을 지원할 수 있는 최고의 '참여 시스템'일 수 있습니다.
참고로, 다음 내용을 확인해 볼 가치가 있습니다. 프로젝트 설명를 사용하는 것이 좋습니다. 여기에는 Couchbase SDK 위에서 작동하고 트랜잭션 시스템을 제공하는 SDK가 포함되어 있기 때문입니다. (이 도구는 공식적으로 지원되는 도구가 아닙니다).
SSIS, SSAS, SSRS
모든 사람이 SSIS(SQL Server 통합 서비스), SSAS(SQL Server 분석 서비스) 및 SSRS(SQL Server 보고 서비스)를 사용하는 것은 아니지만, 이러한 기능은 통합, 보고 및 분석을 위해 SQL Server가 제공하는 강력한 기능입니다.
사용 사례에 따라 매우 다양하기 때문에 "Y 대신 X를 사용하라"고 일괄적으로 말씀드릴 수는 없습니다. 데이터 처리, 데이터 변환, 보고 및 분석을 중심으로 Couchbase에서 사용할 수 있는 몇 가지 도구의 방향을 알려드릴 수는 있습니다.
- 카프카 는 오픈 소스 데이터 스트리밍 도구입니다. 일부 카프카의 인기 사용 사례 메시징, 웹사이트 활동 추적, 메트릭 등이 포함됩니다.
- Spark 은 대규모 데이터 처리 및 ETL을 위한 데이터 처리 엔진입니다.
- Hadoop 는 분산 저장 및 처리를 위한 빅 데이터 프레임워크입니다.
카우치베이스에는 커넥터가 있습니다. 이 세 가지 인기 도구를 각각 지원합니다.
마지막으로, 카우치베이스 애널리틱스 현재 개발자 프리뷰 중입니다.. Couchbase Server와 병렬로 실행되는 데이터 관리 엔진으로 설계되었습니다. 개발자 프리뷰이며 아직 프로덕션 환경에서 사용하는 것은 권장되지 않지만 다음과 같은 이점을 누릴 수 있습니다. Couchbase Analytics 및 Kafka, Spark, Hadoop 확장 기능을 다운로드(확장 기능 탭 클릭)하고 사용해 보세요..
요약
지금까지 SQL Server의 렌즈를 통해 데이터 모델링, 데이터 마이그레이션 및 애플리케이션 마이그레이션에 대해 살펴봤습니다. 다음 프로젝트를 위한 좋은 출발점이 될 것이며, 마이그레이션을 고려하고 있다면 고려해야 할 사항이 있을 것입니다.
그리고 카우치베이스 개발자 포털 에는 Couchbase Server의 모든 측면에 대한 자세한 내용과 정보가 포함되어 있습니다.
마이그레이션을 하든 새로 시작하든, 전환을 더 쉽게 하기 위해 Couchbase가 무엇을 할 수 있는지 여러분의 의견을 듣고 싶습니다. 제가 놓친 것이 있나요? 추천하는 도구나 시스템이 있나요? 질문이 있으신가요? 다음을 확인하세요. 카우치베이스 포럼으로 이메일을 보내주세요. matthew.groves@couchbase.com 또는 트위터 @mgroves.
[...] 데이터를 사용하는 애플리케이션 [...]
[...] 2017 년 3 월 6 일 /u/mgroves에 의해 제출됨 [링크] [댓글] [...]을 남겨주세요.