Moving from SQL Server to Couchbase Part 3: App Migration
In this series of blog posts, I’m going to lay out the considerations when moving to a document database when you have a relational background. Specifically, Microsoft SQL Server as compared to Couchbase Server.
In three parts, I’m going to cover:
- Data modeling
- Data migration
- Applications using the data (this blog post)
The goal is to lay down some general guidelines that you can apply to your application planning and design.
If you would like to follow along, I’ve created an application that demonstrates Couchbase and SQL Server side-by-side. Get the source code from GitHub, and make sure to download a developer preview of Couchbase Server.
Migrate vs Rewrite
If you’re building a new web app, then Couchbase Server is a good choice to use as your system of record. Flexible data modeling, fast data access, ease of scaling all make it a good choice.
Couchbase Server can supplement SQL Server in your existing web application. It can be a session store or a cache store. You don’t have to replace your RDMBS to benefit from Couchbase Server. You can use it as your system of engagment.
However, if you’re considering making a document database your “system of record” for an existing app, then you need to plan what to do about that application (assuming you’ve already come up with a data modeling and data migration plan as covered in the earlier parts of this blog series). There are really two options:
- Replace your data/service layer. If you’ve built your app in a way that decouples it from the underlying persistence, that’s going to benefit you tremendously when switching from SQL Server to Couchbase. If you are using an SOA, for instance, then you might not have to make very many changes to the web application.
- Rebuild your application. If you don’t have a decoupled architecture, then you’ll likely have to bite the bullet and rewrite/refactor large portions of your application. This can be a significant cost that you’ll have to factor in when deciding whether or not to switch to a document database. I wish I could say it would be easier, that there was some magic potion you could use. But remember, even if the cost of a rebuild is too great, you can still use Couchbase Server in
tandem with SQL Server.
The pieces of your stack that you might need to rebuild or replace include:
- ADO.NET – If you are using plain ADO.NET or a micro-OR/M like Dapper, these can be replaced by the Couchbase .NET SDK.
- OR/M – Entity framework, NHibernate, Linq2SQL, etc. These can be replaced by Linq2Couchbase
- Any code that uses those directly – Any code that touches ADO.NET, OR/Ms, or other SQL Server code will need to be replaced to use Couchbase (and/or rewritten to introduce another layer of abstraction).
The rest of this blog post will be tips and guidelines that apply for rewriting, refactoring, or starting a new project.
What’s going to be covered
Document databases force business logic out of the database to a larger extent than relational databases. As nice as it would be if Couchbase Server had every feature under the sun, there are always tradeoffs.
In this blog post, we will cover the changes to application coding that come with using Couchbase. At a high level, here is what will be covered in this blog post. On the left, a SQL Server feature; on the right, the closest equivalent when using Couchbase Server.
| SQL Server | Couchbase Server |
|---|---|
|
tSQL |
N1QL |
|
Stored Procedures |
Service tier |
|
Triggers |
Service tier |
|
Views |
Map/Reduce Views |
|
Autonumber |
Counter |
|
OR/M (Object/relational mapper) |
ODM (Object data model) |
|
ACID |
Single-document ACID |
In addition, we’ll also be covering these important topics:
- Serialization
- Security
- Concurrency
- SSIS, SSRS, SSAS
Using N1QL
The N1QL (pronounced “nickel”) query language is one of my favorite features of Couchbase Server. You are already comfortable with the SQL query language. With N1QL, you can apply your expertise to a document database.
Here are a few examples to show the similarities between N1QL and tSQL:
| tSQL | N1QL |
|---|---|
|
DELETE FROM [table] WHERE val1 = ‘foo’ |
DELETE FROM |
|
SELECT * FROM [table] |
SELECT * from |
|
SELECT t1.* , t2.* FROM [table1] t1 JOIN [table2] t2 ON t1.id = t2.id |
SELECT b1.* , b2.* FROM |
|
INSERT INTO [table] (key, col1, col2) VALUES (1, ‘val1′,’val2’) |
INSERT INTO |
|
UPDATE [table] SET val1 = ‘newvalue’ WHERE val1 = ‘foo’ |
UPDATE |
Thanks to N1QL, migrating your SQL queries should be less difficult than other document databases. Your data model will be different, and not every function in tSQL is (yet) available in N1QL. But for the most part, your existing tSQL-writing expertise can be applied.
Back to the shopping cart, here’s an example of a simple tSQL query that would get shopping cart information for a given user:
|
1 2 3 4 |
SELECT c.Id, c.DateCreated, c.[User], i.Price, i.Quantity FROM ShoppingCart c INNER JOIN ShoppingCartItems i ON i.ShoppingCartID = c.Id WHERE c.[User] = 'mschuster' |
In Couchbase, a shopping cart could be modeled as a single document, so a roughly equivalent query would be:
|
1 2 3 4 |
SELECT META(c).id, c.dateCreated, c.items, c.`user` FROM `sqltocb` c WHERE c.type = 'ShoppingCart' AND c.`user` = 'mschuster'; |
Notice that while N1QL has JOIN functionality, no JOIN is necessary in this shopping cart query. All the shopping cart data is in a single document, instead of being spread out amongst multiple tables and rows.
The results aren’t exactly the same: the N1QL query returns a more hierarchical result. But the query could be modified with an UNNEST to flatten out the results if necessary. UNNEST is an intra-document join, which is a feature that’s necessary when writing SQL for JSON.
In many document databases other than Couchbase, you would likely have to learn an API for creating queries, and you would not be able to apply your tSQL experience to help ramp up. I’m not saying that translation is always going to be a walk in the park, but it’s going to be relatively easy compared to the alternatives. If you’re starting a new project, then you’ll be happy to know that your SQL-writing skills will continue to be put to good use!
When writing C# to interact with N1QL, there are a couple key concepts that are important to know.
Scan Consistency. When executing a N1QL query, there are several scan consistency options. Scan consistency defines how your N1QL query should behave towards indexing. The default behavior is “Not Bounded”, and it provides the best performance. At the other end of the spectrum is “RequestPlus”, and it provides the best consistency. There is also “AtPlus”, which is a good middle-ground, but takes a little more work. I blogged about Scan Consistency back in June, and it’s worth reviewing before you start writing N1QL in .NET.
Parameterization. If you are creating N1QL queries, it’s important to use parameterization to avoid SQL injection. There are two options with N1QL: positional (numbered) parameters and named parameters.
Here’s an example of both Scan Consistency and Parameterization used in C#:
|
1 2 3 4 |
var query = QueryRequest.Create(n1ql); query.ScanConsistency(ScanConsistency.RequestPlus); query.AddNamedParameter("userId", id); var result = _bucket.Query<Update>(query); |
I’m not going to dive into the N1QL query language any more than this, because it is such a deep topic. But you can check out the basics of N1QL and get started with the interactive N1QL tutorial.
SQL Stored Procedures
There is no equivalent of stored procedures (sprocs) in Couchbase. If you don’t already have a service tier, and you are using sprocs to share some logic across domains, I recommend that you create a service tier and move the logic there.
In fact, I wasn’t sure whether sprocs belonged in part 2 or part 3 of this blog series. Typical tiers in an enterprise application:
- Web tier (UI – Angular/React/Traditional ASP.NET MVC)
- Service tier (ASP.NET WebApi)
- Database
Sprocs live in the database, but they contain logic. The service tier also contains business logic. So do they count as data or functionality?
I took a Twitter straw poll to decide.
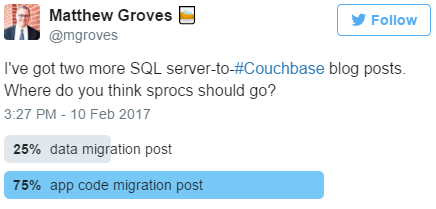
But my recommendation is that if you already have a service tier, move the sproc logic into that. If you don’t have a service tier, create one. This will live between the database and the UI.
In the source code for this series, I’ve created a single stored procedure.
|
1 2 3 4 5 6 7 8 9 |
CREATE PROCEDURE SP_SEARCH_SHOPPING_CART_BY_NAME @searchString NVARCHAR(50) AS BEGIN SELECT c.Id, c.[User], c.DateCreated FROM ShoppingCart c WHERE c.[User] LIKE '%' + @searchString + '%' END GO |
This sproc can be executed from Entity Framework as follows:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
public List<ShoppingCart> SearchForCartsByUserName(string searchString) { var cmd = _context.Database.Connection.CreateCommand(); cmd.CommandText = "SP_SEARCH_SHOPPING_CART_BY_NAME @searchString"; cmd.Parameters.Add(new SqlParameter("@searchString", searchString)); _context.Database.Connection.Open(); var reader = cmd.ExecuteReader(); var carts = ((IObjectContextAdapter) _context) .ObjectContext .Translate<ShoppingCart>(reader, "ShoppingCarts", MergeOption.AppendOnly); var result = carts.ToList(); _context.Database.Connection.Close(); return result; } |
By the way, that Entity Framework sproc code is ugly. Maybe I did it wrong? I’m not trying to slander EF, but generally, I haven’t used OR/Ms and sprocs together much in my career. Certainly a piece of ADO.NET or Dapper code would be shorter and cleaner.
This is a very simple sproc, but it introduces a basic search functionality. The benefits to such a sproc:
- Reuse: The same sproc can be reused between different applications
- Abstraction: The sproc implementation can be changed or improved. In this case, a basic
LIKEcould be switched out for a more robust full text search.
Any approach taken with introducing a service tier should provide the same benefits. I created an ASP.NET WebApi endpoint to take the place of the sproc.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
[HttpGet] [Route("api/searchByName/{searchString}")] public IHttpActionResult SearchByName(string searchString) { var n1ql = @"SELECT META(c).id, c.`user` FROM `sqltocb` c WHERE c.type = 'ShoppingCart' AND c.`user` LIKE $searchString"; var query = QueryRequest.Create(n1ql); query.AddNamedParameter("searchString", "%" + searchString + "%"); query.ScanConsistency(ScanConsistency.RequestPlus); var results = _bucket.Query<ShoppingCart>(query).Rows; return Json(results); } |
Note: for the sake of simplicity in the sample code, this endpoint actually lives in the same web project, but in production, it should be moved to its own project and deployed separately.
This endpoint holds a N1QL query that is similar in nature to the above sproc. Let’s see if it holds up to the same benefits:
- Reuse? Yes. This endpoint can be deployed to its own server and be reused from other applications.
- Abstraction? Again, yes. The implementation uses the naive
LIKEapproach, which we could improve by switching it to use Couchbase’s Full Text Search features without changing the API.
Instead of calling a sproc through Entity Framework, this endpoint would be called via HTTP. Here’s an example that uses the RestSharp library:
|
1 2 3 4 5 6 7 8 9 |
public List<ShoppingCart> SearchForCartsByUserName(string searchString) { // typically there would be authentication/authorization with a REST call like this var client = new RestClient(_baseUrl); var request = new RestRequest("/api/searchByName/" + searchString); request.AddHeader("Accept", "application/json"); var response = client.Execute<List<ShoppingCart>>(request); return response.Data; } |
If you are building a new project, I recommend that you create a service tier with the expectation of it being used across your enterprise. This allows you to have the same “shared code” that sprocs would normally provide without putting that code into the database.
This is also true for SQL Server functions, user defined types, rules, user-defined CLR objects.
Note: the above sproc example is a SELECT just to keep the example simple. In this case, you could potentially create a MapReduce View instead (which is discussed below). A MapReduce view cannot mutate documents though, so a service tier approach is a better general solution to replacing sprocs.
SQL Triggers
If sprocs weren’t already controversial enough, just bring up triggers in a conversation. As with stored procedures, I generally recommend that you move the trigger logic into the service tier, away from the database. If your software project depends on a lot of triggers, or complex triggers, or a lot of complex triggers, then you might want to wait for another project to try using Couchbase Server in.
That being said, there is some cutting-edge stuff that is being worked on that might be roughly equivalent to triggers. If you are interested in this, please contact me, and also stay tuned to the Couchbase Blog for the latest information.
Views
In SQL Server, Views are a way to store complex queries on the server, as well as provide some performance benefits. In Couchbase, Map/reduce views have been providing similar functionality for some time. For the most part, the functionality provided by views can be provided in a more expressive way with N1QL. However, views are not going away, and there are sometimes benefits to using them.
Map/reduce views can be defined and stored on the Couchbase cluster. To create them, you define a “map” function (with JavaScript) and optionally a “reduce” function (also in JavaScript).
In the Couchbase Console UI, go to Indexes → Views → Create View. Create a design document, and create a view within that design document.
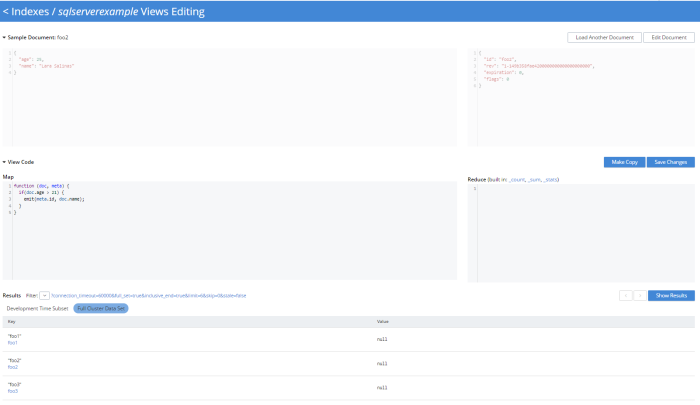
At the center is the Map/Reduce code that you are working on. A sample document and its meta-data is also shown to give you some visual help, and at the bottom you have some options for executing your view.
For complete details on how views work, check out the MapReduce Views documentation.
As a quick example, I want to create a view that lists only the people who have an age greater than 21.
|
1 2 3 4 5 |
function (doc, meta) { if(doc.age > 21) { emit(meta.id, doc.name); } } |
This view would emit the key of the document and the value of the “name” field. If my bucket contained the following documents:
|
1 2 3 |
foo1 {"age":17,"name":"Carmella Albert"} foo2 {"age":25,"name":"Lara Salinas"} foo3 {"age":35,"name":"Teresa Johns"} |
Then the results of the view would look like:
| Key | Value |
|---|---|
|
“foo2” |
“Lara Salinas” |
|
“foo3” |
“Teresa Johns” |
The results of these views are updated automatically on an interval, and are also updated incrementally as documents are mutated. This means that, by default, the results of the views are eventually consistent with the actual documents. As a developer, you can specify the level of consistency (or staleness) you want. This will have an impact on performance.
Map/reduce views can be very helpful when you have very complex logic that’s easier to write in JavaScript than it is to write in N1QL. There can also be performance benefits when you are working with a write-heavy system.
Views can be accessed from .NET using ViewQuery.
|
1 2 3 4 |
var query = new ViewQuery().From("viewdesigndocument", "viewname").Limit(10); var people = bucket.Query<dynamic>(query); foreach (var person in people.Rows) Console.WriteLine(landmark.Key); |
Alternatively, you could create N1QL queries instead of using Views. In many cases, N1QL will be easier to write, and the performance difference will be negligible. Unlike Views, the N1QL queries would live in the service tier. There is currently no way to store a “N1QL View” on the Couchbase Server cluster.
Serialization/deserialization
Whether you’re using N1QL, Views, or key/value operations, it’s important to consider how JSON is serialized and deserialized.
The .NET SDK uses Newtonson JSON.NET. If you are familiar with that tool (and who among .NET developers isn’t), then remember that you can use the same attributes (like JsonProperty, JsonConverter, etc). In some edge cases, it might be useful to create your own custom serializer, which is possible with the Couchbase .NET SDK. Check out the documentation on serialization and non-JSON documents for more information.
Security
Couchbase has role-based access control (RBAC) for administrators.
Couchbase can integrate with LDAP to manage Couchbase administrators and assign roles to users. Couchbase can also create read-only users internally.
There are some more robust changes and improvements coming to the Couchbase RBAC system, so stay tuned. In fact, I would recommend that you start checking out the monthly developer builds, as I expect to see some interesting improvements and features in this area soon!
Concurrency
Concurrency is something that you often have to deal with, especially in a web application. Multiple users could be taking actions that result in the same document being changed at the same time.
SQL Server uses pessimistic locking by default. This means that SQL Server expects rows to be in contention, and so it acts defensively. This is a sensible default for relational databases because denormalized data is spread across multiple tables and multiple rows. SQL Server does have the ability to use optimistic locking as well, through a variety of transaction levels.
Couchbase also offers two options to deal with concurrency: optimistic and pessimistic.
Optimisitic. This is called “optimistic” because it works best when it’s unlikely that a document will be in contention very often. You are making an optimistic assumption. On Couchbase, this is done with CAS (Compare And Swap). When you retrieve a document, it comes with meta data, including a CAS value (which is just a number). When you go to update that document, you can supply the CAS value. If the values match, then your optimism paid off, and the changes are saved. If they don’t match, then the operation fails, and you’ll have to handle it (a merge, an error message, etc). If you don’t supply a CAS value, then the changes will be saved no matter what.
Pessimistic. This is called “pessimistic” because it works best when you know a document is going to be mutated a lot. You are making a pessimistic assumption, and are forcibly locking the document. If you use GetAndLock in the .NET SDK, the document will be locked, which means it can’t be modified. Documents are locked for a maximum of 15 seconds. You can set a lower value. You can also explicitly unlock a document, but you must keep track of the CAS value to do so.
For more detail, check out the documentation on Concurrent Document Mutations.
Autonumber
Couchbase Server does not currently offer any sort of automatic key generation or sequential key numbering.
However, you can use the Counter feature to do something similar. The idea is that a document is set aside as a special counter document. This document can be incremented as an atomic operation, and the number can be used as a partial or whole key of the new document being created.
Ratnopam Chakrabarti, a developer for Ericsson, recently wrote a guest blog post about how to create sequentially numbered keys with Couchbase Server. His example is in Java, but it easy enough to follow, so I won’t repeat his example here.
OR/Ms and ODMs
If you are using SQL Server, you might be familiar with OR/Ms (Object-relational mappers). Entity Framework, NHibernate, Linq2SQL, and many others are OR/Ms. OR/Ms attempt to bridge the gap between structured data in C# and normalized data in relational databases. They also typically provide other capabilities like Linq providers, unit of work, etc. I believe that OR/Ms follow the 80/20 rule. They can be very helpful 80% of the time, and a pain in the neck the other 20%.
For document databases, there is a much lower impedence mismatch, since C# objects can be serialized/deserialized to JSON, and don’t have to be broken up into a normalized set of tables.
However, the other functionality that OR/Ms provide can still be helpful in document databases. The equivalent tool is called an ODM (Object Document Model). These tools help you define a set of classes to map to documents. Ottoman and Linq2Couchbase are popular ODMs for Couchbase, for Node and .NET respectively.
Linq2Couchbase has a Linq provider. It’s not an officially supported project (yet), but it is one of the most complete Linq providers I’ve ever used, and is used in production by Couchbase customers.
Below is an example from the Linq2Couchbase documentation that should look somewhat familiar for users of Entity Framework and NHibernate.Linq:
|
1 2 3 4 5 |
var context = new BucketContext(ClusterHelper.GetBucket("travel-sample")); var query = (from a in context.Query<AirLine>() where a.Country == "United Kingdom" select a). Take(10); |
I also used Linq2Couchbase in the sample code for this blog series. Here’s an example for Shopping Carts:
|
1 2 3 4 5 6 7 |
var query = from c in _context.Query<ShoppingCart>() where c.Type == "ShoppingCart" // could use DocumentFilter attribute instead of this Where orderby c.DateCreated descending select new {Cart = c, Id = N1QlFunctions.Meta(c).Id}; var results = query.ScanConsistency(ScanConsistency.RequestPlus) .Take(10) .ToList(); |
Beyond being a great Linq provider, Linq2Couchbase also has an experimental change tracking feature. It’s definitely worth checking out. Brant Burnett is one of the key contributers to the project, and he’s also a Couchbase Expert. He presented a session at Couchbase Connect 2016 called LINQing to data: Easing the transition from SQL.
[youtube https://www.youtube.com/watch?v=X__mC2FArp4&w=560&h=315]
Transactions
I’ve already covered pessimistic and optimistic locking for transactions on a single document. Because of those, we can say that Couchbase supports ACID transactions on a per-document level. Couchbase does not, at this time, support ACID transactions among multiple documents.
Thinking back to the first blog post on data modeling, the need for multi-document transactions is often reduced or eliminated, compared to a relational model. A concept (like shopping cart) may require rows in multiple tables in a relational model, but a single document model in Couchbase.
If you are following a referential model, as in the social media example from the first blog post, you might be concerned about the lack of transactions. This highlights the importance of thinking about your use cases while creating your data model. If transactions are vital to your use case, the data model can often be structured to accomodate. We are happy to help you through this, just ask!
Multi-document transaction support may come in the future if enough Couchbase developers and customers ask for it or need it. So, if you go through the exercise of designing a document database data model, and transactions are still a vital part of your project, then Couchbase may not be the best “system of record” for at least part of your project. Couchbase may still be the best “system of engagement”, able to help with scaling, caching, performance, and flexibility where needed.
As a side note, it may be worth checking out the NDescribe project, as it includes an SDK that works on top of the Couchbase SDK and provides a transaction system. (Note that this is not an officially supported tool).
SSIS, SSAS, SSRS
Not everyone uses SQL Server Integration Services (SSIS), SQL Server Analysis Services (SSAS), and SQL Server Reporting Services (SSRS), but these are powerful features that SQL Server has for integration, reporting, and analysis.
I can’t give you a blanket “use X instead of Y” for these, because it depends very much on your use case. I can point you in the direction of some of the tools available for Couchbase that revolve around data processing, data transformation, reporting, and analysis.
- Kafka is an open source data streaming tool. Some of the popular use cases for Kafka include messaging, website activity tracking, metrics, and more.
- Spark is a data procesessing engine, intended for large-scale data processing and ETL.
- Hadoop is a big data framework for distributed storage and processing.
Couchbase has connectors that support each of these three popular tools.
Finally, Couchbase Analytics is currently in developer preview. It is intended as a data management engine that runs parallel to Couchbase Server. It’s a developer preview, and is not yet recommended to be used in production, but you can download Couchbase Analytics and Kafka, Spark, Hadoop extensions (click the Extensions tab) and try them out.
Summary
We’ve covered data modeling, data migration, and application migration through the lens of SQL Server. This is a good starting point for your next project, and will give you something to think about if you are considering migrating.
The Couchbase Developer Portal contains more details and information about every aspect of Couchbase Server.
I want to hear from you about what Couchbase can do to make your transition easier, whether you’re migrating or starting fresh. Did I miss something? Do you have a tool or system that you recommend? Have questions? Check out the Couchbase Forums, email me at matthew.groves@couchbase.com or find me on Twitter @mgroves.
[…] Applications using the data […]
[…] on March 6, 2017 submitted by /u/mgroves [link] [comments] Leave a […]