머신 러닝은 개발자와 데이터 과학자가 모든 종류의 작업을 수행하는 데 도움이 되는 도구입니다:
-
분류 - 데이터 정리 및 태그 지정
-
회귀 - 데이터 요소 간의 관계 찾기
-
예측 - 현재 데이터를 사용하여 미래를 예측합니다.
-
이상 징후 탐지 - 비정상적인 데이터 포인트 찾기
이 글에서는 Nexosis가 머신 러닝을 위해 제공하는 웹 기반 REST API를 Couchbase Server와 결합하는 방법을 보여드리려고 합니다.
머신 러닝을 시도할 때 가장 먼저 시작하는 곳이 바로 Kaggle입니다. Kaggle은 머신 러닝 애플리케이션에 적합한 다양한 데이터 세트를 제공합니다. 저는 감정 분석 데이터 세트에 대한 아마존 리뷰 (나는 이 게시물을 위해 잘라내고 약간 수정했습니다.).
이 세트의 데이터에는 아마존에 남겨진 리뷰의 텍스트와 "__label__1" 또는 "__label__2"의 레이블이 포함됩니다. 전자는 부정적인 리뷰(별 1개 또는 2개)를 의미하고 후자는 긍정적인 리뷰(별 4개 또는 5개)를 의미합니다. 3점은 중립적인 것으로 간주되어 이 트레이닝 세트에 포함되지 않지만, 이에 대해서는 나중에 자세히 살펴보도록 하겠습니다.
제 목표는 Nexosis에 다음과 같은 아마존 리뷰를 제공하는 것입니다. not 를 트레이닝 세트에 추가하고 Nexosis가 이를 "__label__1" 또는 "__label__2"로 분류하도록 합니다. 이러한 유형의 분류를 감정 분석. 예를 들어 부정적인 고객 경험을 조기에 경고하는 데 유용할 수 있습니다.
넥소시스 머신 러닝 계정 만들기
머신 러닝 설정
Nexosis를 설정하는 첫 번째 단계는 데이터 집합을 제공하는 것입니다. 저는 Kaggle에서 가져온 데이터 집합을 사용하고 있습니다. 데이터는 두 개의 열로 구성된 CSV 파일입니다. 이 데이터를 Nexosis로 가져오려면 다음과 같이 요청하면 됩니다(예: Postman과 같은 도구 사용):
|
1 2 3 4 5 6 |
POST https://ml.nexosis.com/v1/imports/url { "dataSetName" : "AmazonReviews", "url" : "https://raw.githubusercontent.com/couchbaselabs/blog-source-code/master/Groves/101MachineLearningNexosis/src/modified5000.csv" } |
헤더에 있는 API 키를 잊지 마세요!
이 요청이 성공하면 응답은 다음과 비슷하게 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 |
{ "importId": "< guid >", "type": "url", "status": "requested", "dataSetName": "AmazonReviews", "parameters": { "url": "https://raw.githubusercontent.com/" }, "requestedDate": "2018-02-19T19:04:13.012859+00:00", "statusHistory": [ { "date": "2018-02-19T19:04:13.012859+00:00", "status": "requested" } ], "messages": [], "columns": {}, "links": [ { "rel": "self", "href": "https://ml.nexosis.com/v1/imports/url" }, { "rel": "data", "href": "https://ml.nexosis.com/v1/data/AmazonReviews" } ] } |
가져오기에는 시간이 다소 걸릴 수 있습니다. https://ml.nexosis.com/v1/imports 으로 GET 요청을 보내 요청이 완료되었는지 확인할 수 있습니다. 이 데이터 세트가 '항목' 중 하나로 표시됩니다.
Nexosis 세션 만들기
다음 단계는 Nexosis 세션을 생성하는 것입니다. 이렇게 하면 이미 가져온 데이터에 대한 Nexosis 학습이 시작됩니다. 다음은 세션을 시작하는 샘플 POST입니다:
|
1 2 3 4 5 6 7 |
POST https://ml.nexosis.com/v1/sessions/model { "predictionDomain":"classification", "dataSourceName" : "AmazonReviews", "targetColumn": "review_sentiment", "extraParameters" : { "balance": true } } |
이 모든 것이 무엇을 의미하는지에 대한 몇 가지 참고 사항입니다:
-
"predictionDomain":"분류"- 제가 감성 분석에 '분류'를 사용하겠다고 말씀드린 것을 기억하시나요? -
"dataSourceName" : "AmazonReviews"- 데이터 원본에 이 이름을 지정했으므로 이 데이터 원본을 교육에 사용하도록 지시하고 있습니다. -
"targetColumn": "review_sentiment"- 'review_sentiment' 열에는 "__label__1" 또는 "__label__2" 값이 포함됩니다. 이 값은 넥소시스에서 생성 방법을 학습하기를 원하는 값입니다. -
"extraParameters" : { "balance": true }- 데이터 세트의 균형이 맞지 않는 경우(예: 긍정적인 리뷰보다 부정적인 리뷰가 훨씬 더 많이 포함되어 있는 경우) 머신 러닝에 불균형적인 영향을 미칠 수 있습니다. 이를 조정하려면 밸런스를 'true'로 설정하세요.
해당 요청의 응답은 다음과 같이 표시됩니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
{ "columns": { "text": { "dataType": "text", "role": "feature" }, "review_sentiment": { "dataType": "string", "role": "target", "imputation": "mode", "aggregation": "mode" } }, "sessionId": "< guid >", "type": "model", "status": "requested", "predictionDomain": "classification", "availablePredictionIntervals": [], "requestedDate": "2018-02-19T19:28:41.812052+00:00", "statusHistory": [ { "date": "2018-02-19T19:28:41.812052+00:00", "status": "requested" } ], "extraParameters": { "balance": true }, "messages": [], "name": "Classification on AmazonReviews", "dataSourceName": "AmazonReviews", "dataSetName": "AmazonReviews", "targetColumn": "review_sentiment", "isEstimate": false, "links": [ { "rel": "results", "href": "https://ml.nexosis.com/v1/sessions/< guid >/results" }, { "rel": "data", "href": "https://ml.nexosis.com/v1/data/AmazonReviews" }, { "rel": "vocabularies", "href": "https://ml.nexosis.com/v1/vocabulary?createdFromSessionid=< guid >" } ] } |
이러한 유형의 세션은 제작하는 데 다소 시간이 걸립니다. 세션이 준비되면 Nexosis로부터 이메일 알림을 받게 됩니다. 또한 수시로 "결과"(위 URL 참조)를 확인할 수도 있습니다.
완성된 모델
세션이 완료되면 다음을 받게 됩니다. modelId 를 입력하면 다른 GUID가 됩니다. 계속 진행하려면 이 정보가 필요합니다.
모델아이디를 받으면 모델이 얼마나 정확한지 확인할 수 있습니다. https://ml.nexosis.com/v1/sessions//results로 GET을 실행하고 메트릭 필드를 입력합니다. 제 결과는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 |
"metrics": { "macroAverageF1Score": 0.81341486902927584, "rocAreaUnderCurve": 0.88777613666838784, "accuracy": 0.814, "macroAveragePrecision": 0.81521331769769212, "macroAverageRecall": 0.81309365130828448, "matthewsCorrelationCoefficient": 0.62830339352567144 }, |
이를 통해 모델이 얼마나 신뢰할 수 있는지 알 수 있습니다. 필요한 임계값에 비해 충분히 높지 않은 경우 모델을 조정해 볼 수 있습니다.
를 사용하면 정확도를 높일 수 있습니다. 필요한 임계값을 충족할 때까지 학습 세트에서 필드를 추가/제거하는 것을 고려할 수 있습니다.
아직 완벽하지는 않으므로 이 분석이 영향력이 크고 중요한 작업에 사용된다면 프로세스의 일부에 사람을 참여시키는 것이 좋습니다.
81% 정확도로도 충분히 진행할 수 있습니다.
머신 러닝 모델 테스트
REST로 모델을 테스트해 보겠습니다. 저는 POST 요청을 통해 /predict 모델아이디를 사용하여 URL을 입력합니다:
POST https://ml.nexosis.com/v1/models//predict
이 요청의 본문에는 Nexosis의 의견을 듣고자 하는 아마존 리뷰가 포함됩니다. 별점 1점 리뷰의 텍스트를 제공하겠습니다.
|
1 2 3 4 5 6 7 8 |
{ "data":[{ "text" : "Junk! Don't waste your money! ... It worked great for about two weeks then progressively got worse for the next four until it now barely works" }], "extraParameters" :{ "includeClassScores" : false } } |
이를 제출하면 넥소시스에서 이를 검토한 후 다음과 같은 결과를 반환합니다:
|
1 2 3 4 5 6 7 8 9 10 |
{ "data": [ { "text": "Junk! Don't waste your money! ... It worked great for about two weeks then progressively got worse for the next four until it now barely works", "review_sentiment": "__label__1" } ], // ... etc ... } |
이는 두 가지를 의미합니다:
-
모델이 정상적으로 작동합니다!
-
방금 보낸 리뷰는 부정적인 리뷰일 가능성이 높습니다. 직접 읽어보니 저도 동의할 수밖에 없었습니다.
카우치베이스에서 넥소시스 사용
이러한 POST 요청을 수작업으로 생성하는 대신 Couchbase에서 직접 Nexosis를 사용할 수 있습니다.
참고: Nexosis는 Couchbase를 필요로 하지 않으며 그 반대의 경우도 마찬가지입니다. Nexosis는 단순히 JSON REST API를 노출하고 Couchbase는 이를 사용할 수 있습니다. 둘 다 공통 웹 표준을 따르기 때문에 함께 잘 작동합니다.
카우치베이스에서 넥소시스를 사용하려면, 카우치베이스 N1QL 쿼리에서 넥소시스 API에 CURL 요청을 하기만 하면 됩니다.
Couchbase에서 CURL 허용하기
먼저, 카우치베이스가 다음을 만들 수 있도록 설정해야 합니다. CURL 요청을 허용하지 않습니다. 임의의 CURL 요청을 허용하면 보안 위험이 있으므로 특정 요청을 허용하도록 옵트인해야 합니다. curl_whitelist.json 파일을 생성(또는 업데이트)하면 이 작업을 수행할 수 있습니다. 확인 CURL, N1QL로 출시 에서 자세한 내용을 확인하세요.
제가 사용하고 있는 curl_whitelist.json은 다음과 같습니다. Windows에서 이 파일은 C:\프로그램 파일\카우치베이스\서버\변수\lib\카우치베이스\n1qlcerts 폴더로 이동합니다.
|
1 2 3 4 5 |
{ "all_access":false, "allowed_urls":["https://ml.nexosis.com/v1/models/< modelId guid >/predict "], "disallowed_urls":[] } |
N1QL 쿼리 만들기
N1QL은 JSON을 쿼리하는 데 사용되는 카우치베이스의 SQL 구현입니다. 궁극적으로 Nexosis가 UPDATE 또는 INSERT 명령에 피드되기를 원할 수 있습니다. 하지만 이 글에서는 SELECT만 사용하겠습니다.
Couchbase에서 Amazon에서 수동으로 가져온 리뷰가 있는 버킷을 만들었습니다. (또한 리뷰에 기본 색인 만들기).
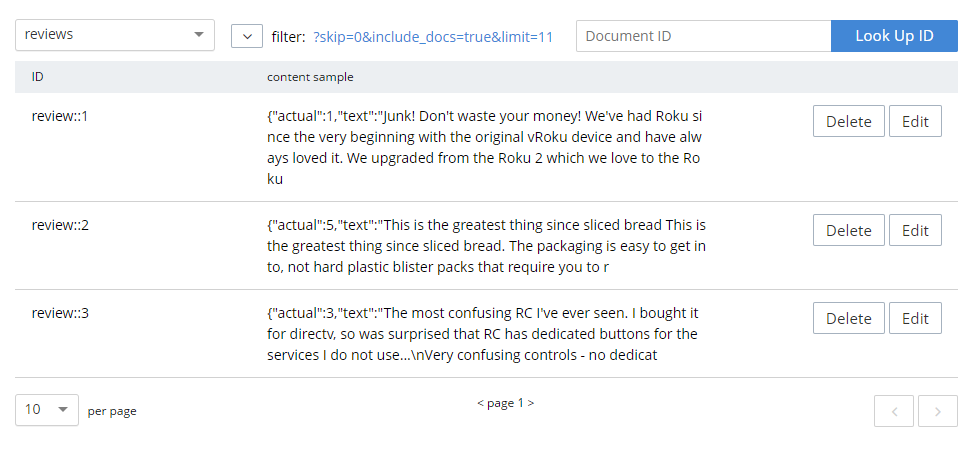
이는 학습 데이터의 일부가 아니므로 넥소시스에서 자체적으로 긍정 또는 부정 감정 점수를 부여합니다.
간단한 선택 를 클릭하고 거기서부터 구축하세요.
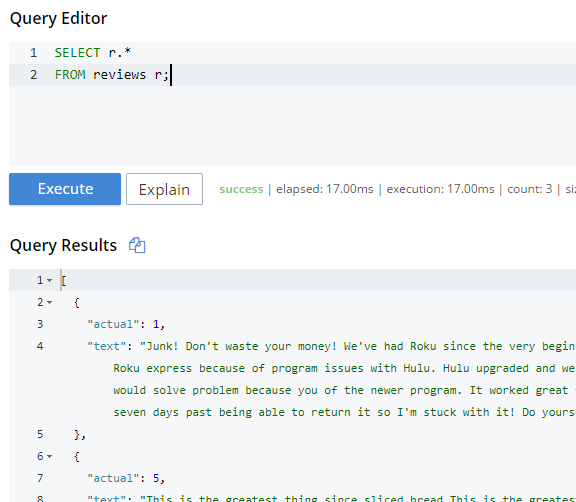
CURL을 사용하여 머신 러닝 도입하기
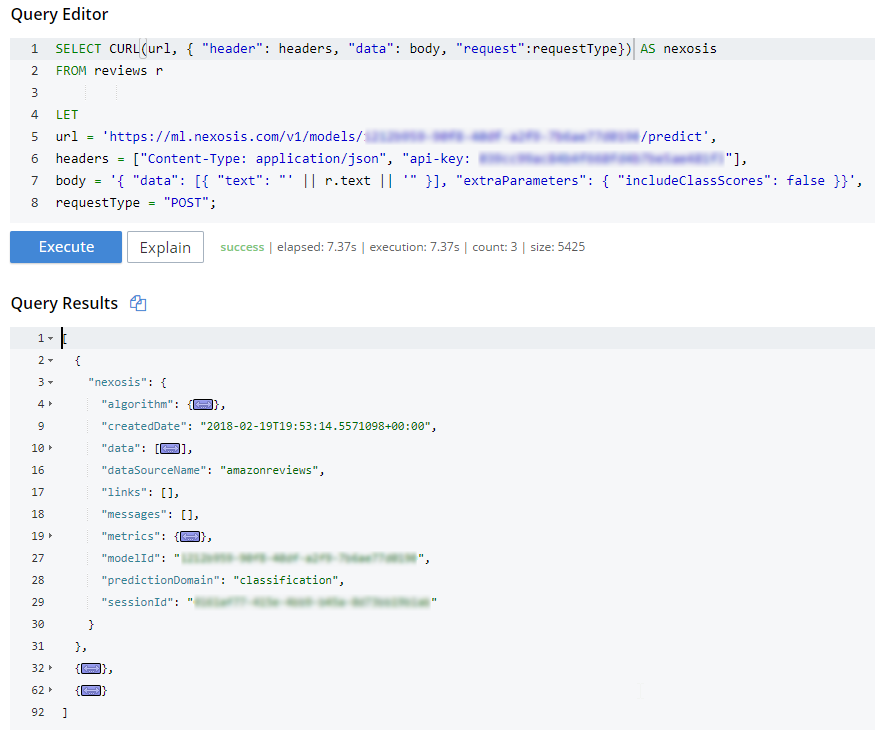
다음으로 CURL을 가져와 보겠습니다. 저는 LET 를 사용하여 쿼리의 가독성을 높입니다.
|
1 2 3 4 5 6 7 8 |
SELECT CURL(url, { "header": headers, "data": body, "request":requestType}) AS nexosis FROM reviews r LET url = 'https://ml.nexosis.com/v1/models/< modelId guid >/predict', headers = ["Content-Type: application/json", "api-key: < my API key >"], body = '{ "data": [{ "text": "' || r.text || '" }], "extraParameters": { "includeClassScores": false }}', requestType = "POST"; |
참고 body 는 Couchbase의 리뷰 문서에서 직접 텍스트를 가져오고 있습니다. (지금까지) 제가 선택한 유일한 것은 이와 비슷하게 보이는 Nexosis의 전체 응답입니다:
Nexosis의 결과를 더 자세히 분석하고 Amazon의 실제 점수와 나란히 배치하여 Nexosis가 어떻게 수행되었는지 확인할 수 있었습니다. 다음은 쿼리입니다:
|
1 2 3 4 5 6 7 8 |
SELECT r.actual, r.text, CURL(url, { "header": headers, "data": body, "request":requestType}).data[0].review_sentiment AS nexosis FROM reviews r LET url = 'https://ml.nexosis.com/v1/models/< modelId GUID >/predict', headers = ["Content-Type: application/json", "api-key: < my api key >"], body = '{ "data": [{ "text": "' || r.text || '" }], "extraParameters": { "includeClassScores": false }}', requestType = "POST"; |
결과는 다음과 같습니다(전문을 잘라버렸습니다):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
[ { "actual": 1, "nexosis": "__label__1", "text": "Junk! Don't waste your money..." }, { "actual": 5, "nexosis": "__label__2", "text": "This is the greatest thing since sliced bread..." }, { "actual": 3, "nexosis": "__label__1", "text": "The most confusing RC I've ever seen..." } ] |
결과
예상대로 Nexosis는 아마존의 별점 1점 리뷰를 보고 부정적인 리뷰("__label__1"로 분류)임을 올바르게 식별했습니다.
또한 별점 5개의 리뷰를 보고 긍정적인 리뷰임을 올바르게 식별했습니다("__label__2"로 분류).
저는 이 제품에 별점 3점짜리 "중립" 리뷰를 주기로 결정했습니다. 트레이닝 세트에는 이러한 기능이 없으므로 유효하지 않을 수도 있지만 궁금했습니다. 부정적인 리뷰로 분류했습니다. 언어만 놓고 보면 아마도 정확한 평가일 것입니다. 표면적으로 "중립적"인 리뷰를 살펴보고 어느 한쪽으로 기울어져 있는지를 식별하는 데 유용한 도구가 될 수 있습니다.
요약
N1QL에서 CURL을 사용할 때는 항상 주의하세요. CURL을 사용하면 쿼리를 제3자에 대한 HTTP 요청에 맡기게 됩니다. 이를 백그라운드에서 배치 프로세스로 실행하여 다음과 같은 작업을 수행할 수 있습니다. 업데이트 그리고 삽입 라이브 대신 선택 제가 하고 있는 것처럼요.
하지만 현명하게 CURL을 사용한다면 Nexosis와 같은 타사 도구를 사용하여 머신 러닝, 분류, 감성 분석 등을 수행할 수 있습니다. Nexosis를 사용하면 표준 CURL 명령으로 매우 쉽게 시작할 수 있고 매우 쉽게 사용할 수 있습니다.
넥시스에 관심이 있으시다면, 다음 내용을 확인하세요. 넥소시스 사용 사례 페이지에서 넥소시스가 여러분과 여러분의 비즈니스에 어떤 도움을 줄 수 있는지 알아보세요. 넥소시스 사용에 대해 궁금한 점이 있으시면 넥소시스 포럼.
질문이 있으신가요? I'm on 트위터 @mgroves.