JSON 데이터 모델링은 다음과 같은 문서 데이터베이스를 사용하는 데 있어 매우 중요한 부분입니다. 카우치베이스. 이 블로그 게시물에서 다룰 데이터 간의 관계를 모델링하는 두 가지 주요 접근 방식은 JSON의 기본 사항을 이해하는 것 외에도 두 가지입니다.
이 게시물의 예제는 다음에서 보여드린 인보이스 예제를 기반으로 합니다. 관계형에서 Couchbase로 마이그레이션하기 위한 CSV 도구.
가져온 데이터 새로 고침
이전 예제에서는 관계형 데이터베이스의 두 테이블로 시작했습니다: Invoices 및 InvoicesItems입니다. 각 인보이스 항목은 관계형 데이터베이스에서 외래 키로 처리되는 인보이스에 속합니다.
저는 이 데이터를 매우 간단하게(순진하게) Couchbase로 가져왔습니다. 각 행은 '스테이징' 버킷에 있는 문서가 되었습니다.

다음으로, JSON 데이터 모델링 디자인이 적절한지 여부를 결정해야 합니다(저는 그렇지 않다고 생각합니다. '스테이징'이라는 버킷이 이미 그것을 알려주지 않았기 때문이죠).
관계의 JSON 데이터 모델링에 대한 두 가지 접근 방식
관계형 데이터베이스의 경우, 데이터 정규화라는 한 가지 방법밖에 없습니다. 즉, 데이터를 서로 연결하는 외래 키가 있는 별도의 테이블을 만드는 것입니다.
문서 데이터베이스에는 두 가지 접근 방식이 있습니다. 데이터를 정규화된 상태로 유지하거나 상위 문서에 중첩하여 데이터를 비정규화할 수 있습니다.
정규화(별도 문서)
최종 상태의 예 정규화 접근 방식은 여러 문서에 분산된 단일 송장을 나타냅니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
key - invoice::1 { "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive" } key - invoiceitem::1811cfcc-05b6-4ace-a52a-be3aad24dc52 { "InvoiceId": "1", "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" } key - invoiceitem::29109f4a-761f-49a6-9b0d-f448627d7148 { "InvoiceId": "1", "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" } key - invoiceitem::bf9d3256-9c8a-4378-877d-2a563b163d45 { "InvoiceId": "1", "Price": "20.00", "Product": "Tire", "Quantity": "2" } |
이는 직접 CSV 가져오기와 일치합니다. 그리고 InvoiceId 필드는 각 송장 항목 문서의 유사 를 외래 키의 개념과 비슷하게 생각하실 수 있지만, 카우치베이스(및 일반적으로 분산 문서 데이터베이스)는 관계형 데이터베이스와 같은 방식으로 이 관계를 적용하지 않는다는 점에 유의하세요. 이는 분산 시스템의 유연성, 확장성, 성능 요구 사항을 충족하기 위한 절충안입니다.
이 예에서 "자식" 문서는 다음을 통해 부모를 가리키고 있습니다. InvoiceId. 하지만 그 반대일 수도 있습니다. '부모' 문서에는 각 '자식' 문서의 키 배열이 포함될 수도 있습니다.
비정규화(중첩)
최종 상태의 중첩 접근 방식은 인보이스를 나타내는 단일 문서만 있으면 됩니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
key - invoice::1 { "BillTo": "Lynn Hess", "InvoiceDate": "2018-01-15 00:00:00.000", "InvoiceNum": "ABC123", "ShipTo": "Herman Trisler, 4189 Oak Drive", "Items": [ { "Price": "1000.00", "Product": "Brake Pad", "Quantity": "24" }, { "Price": "10.00", "Product": "Steering Wheel", "Quantity": "5" }, { "Price": "20.00", "Product": "Tire", "Quantity": "2" } ] } |
"InvoiceId"가 더 이상 객체에 존재하지 않습니다. 항목 배열로 변경합니다. 이 데이터는 더 이상 외국 데이터가 아니라 국내 데이터이므로 해당 필드는 더 이상 필요하지 않습니다.
JSON 데이터 모델링 경험 법칙
여러분은 이미 second 옵션이 이 경우 자연스럽게 적합합니다. 이 시스템의 인보이스는 자연스럽게 집계-루트. 그러나 애플리케이션에서 이 두 가지 접근 방식 중 언제, 어떻게 선택해야 하는지 항상 간단하고 명확한 것은 아닙니다.
다음은 각 모델을 언제 선택해야 하는지에 대한 몇 가지 경험 법칙입니다:
| 만약 ... | 그렇다면 다음을 고려하세요... |
|---|---|
|
관계는 일대일 또는 일대다입니다. |
중첩된 개체 |
|
관계는 다대일 또는 다대다입니다. |
문서 분리 |
|
데이터 읽기는 대부분 상위 필드입니다. |
별도의 문서 |
|
데이터 읽기는 대부분 상위 + 하위 필드입니다. |
중첩된 개체 |
|
데이터 읽기는 대부분 상위 또는 자식(둘 다 아님) |
문서 분리 |
|
데이터 쓰기는 대부분 상위 그리고 자식(둘 다) |
중첩된 개체 |
모델링 예제
이를 더 자세히 살펴보기 위해 구축 중인 인보이스 시스템에 대해 몇 가지 가정을 해보겠습니다.
- 사용자는 일반적으로 전체 인보이스(인보이스 항목 포함)를 봅니다.
- 사용자가 인보이스를 생성(또는 변경)하면 '루트' 필드와 '항목'이 함께 업데이트됩니다.
- 다음이 있습니다. 일부 시스템에서 인보이스 루트 데이터에만 관심을 갖고 '항목' 필드를 무시하는 쿼리(많지는 않음)가 있습니다.
그런 다음 그 지식을 바탕으로 다음과 같은 사실을 알게 됩니다:
- 관계는 일대다(하나의 인보이스에 많은 항목이 있음)입니다.
- 데이터 읽기는 다음과 같습니다. 대부분 부모 + 자식 필드 함께
따라서 '중첩된 개체'가 적합한 디자인으로 보입니다.
이 규칙은 항상 적용되는 딱딱하고 빠른 규칙이 아니라는 점을 기억하세요. 이는 단순히 시작을 돕기 위한 가이드라인일 뿐입니다. 유일한 '모범 사례'는 자신의 지식과 경험을 활용하는 것입니다.
N1QL로 스테이징 데이터 변환하기
이제 몇 가지 JSON 데이터 모델링 연습을 수행했으므로 스테이징 버킷의 데이터를 관계형 데이터베이스에서 직접 가져온 개별 문서에서 중첩된 개체 디자인으로 변환할 차례입니다.
이에 대한 접근 방식은 여러 가지가 있지만, 저는 매우 단순하게 유지하고 Couchbase의 강력한 N1QL 언어 를 사용하여 JSON 데이터에 대한 SQL 쿼리를 실행할 수 있습니다.
데이터 준비하기
먼저, '작업' 버킷을 만듭니다. 데이터를 변환하여 '스테이징' 버킷(직접적인 CSV 가져오기)를 '작업' 버킷에 추가합니다.
다음으로 '루트' 문서에 '유형' 필드를 표시하겠습니다. 이것은 문서를 특정 유형으로 표시하는 방법으로 나중에 유용하게 사용할 수 있습니다.
|
1 2 3 |
UPDATE staging SET type = 'invoice' WHERE InvoiceNum IS NOT MISSING; |
루트 문서에는 "InvoiceNum"이라는 필드가 있고 항목에는 이 필드가 없다는 것을 알고 있습니다. 따라서 이 방법은 안전하게 구분할 수 있는 방법입니다.
다음으로 항목을 수정해야 합니다. 이전에는 숫자만 있는 외래 키가 있었습니다. 이제 해당 값이 새 문서 키를 가리키도록 업데이트해야 합니다.
|
1 2 |
UPDATE staging s SET s.InvoiceId = 'invoice::' || s.InvoiceId; |
값에 "invoice::"를 앞에 붙이기만 하면 됩니다. 루트 문서에는 InvoiceId 필드가 없으므로 이 쿼리의 영향을 받지 않습니다.
그런 다음 해당 필드에 인덱스를 만들어야 합니다.
색인 준비하기
|
1 |
CREATE INDEX ix_invoiceid ON staging(InvoiceId); |
이 인덱스는 다음에 예정된 변환 조인에 필요합니다.
이제 이 데이터를 작동하게 만들기 전에 선택 를 사용하여 미리 보고 데이터가 예상한 대로 조인되는지 확인하세요. N1QL의 NEST 작동합니다:
|
1 2 3 4 |
SELECT i.*, t AS Items FROM staging AS i NEST staging AS t ON KEY t.InvoiceId FOR i WHERE i.type = 'invoice'; |
이 쿼리의 결과는 총 3개의 루트 인보이스 문서여야 합니다.
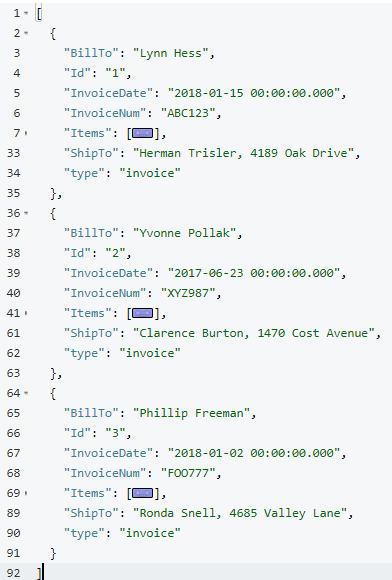
이제 인보이스 항목은 상위 인보이스 내의 '항목' 배열에 중첩되어야 합니다(간결성을 위해 위 스크린샷에서 축소했습니다).
스테이징에서 데이터 이동
올바르게 보이는지 확인했다면, 데이터를 '작업' 버킷으로 옮길 수 있습니다. 삽입 명령은 위의 명령에서 약간 변형된 것입니다. 선택 명령을 사용합니다.
|
1 2 3 4 5 |
INSERT INTO operation (KEY k, VALUE v) SELECT META(i).id AS k, { i.BillTo, i.InvoiceDate, i.InvoiceNum, "Items": t } AS v FROM staging i NEST staging t ON KEY t.InvoiceId FOR i where i.type = 'invoice'; |
N1QL을 처음 사용하는 경우 여기서 몇 가지 주의해야 할 사항이 있습니다:
삽입은 항상KEY그리고VALUE. 관계형 데이터베이스에서처럼 이 절에 모든 필드를 나열하지는 않습니다.META(i).id는 문서의 키에 액세스하는 방법입니다.- 리터럴 JSON 구문인 SELECTED AS v는 이동하려는 필드를 지정하는 방법입니다. 여기에는 와일드카드를 사용할 수 있습니다.
NEST는 루트 수준이 아닌 배열에 데이터를 중첩하는 조인 유형입니다.FOR i의 왼쪽을 지정합니다.키 켜기join. 이 구문은 아마도 N1QL에서 가장 비표준적인 부분이지만, 다음 주요 릴리스에는 훨씬 더 자연스럽게 읽고 쓸 수 있는 "ANSI JOIN" 기능이 포함될 예정입니다.
이 쿼리를 실행한 후에는 '작업' 버킷에 총 3개의 문서가 있어야 하며, 이는 3개의 송장을 나타냅니다.
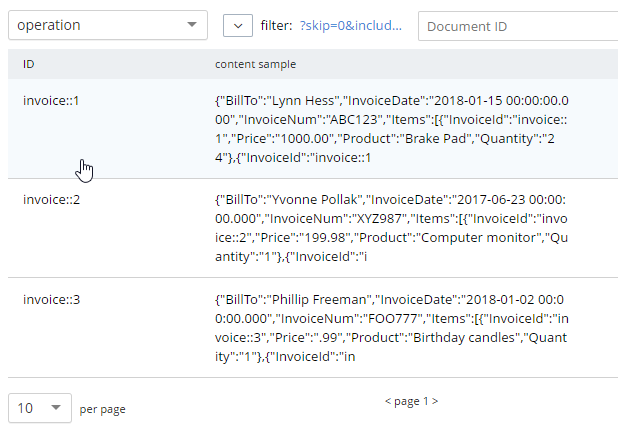
이제 스테이징 버킷에 오래된 데이터가 포함되어 있으므로 삭제하거나 플러시할 수 있습니다. 또는 더 많은 실험을 위해 계속 보관할 수도 있습니다.
요약
CSV를 통해 가져오고 몇 줄의 N1QL로 변환하는 것만큼이나 쉽게 데이터를 Couchbase Server로 바로 마이그레이션할 수 있습니다. 실제 모델링을 수행하고 의사 결정을 내리는 데는 가장 많은 시간과 생각이 필요합니다. 일단 모델링 방법을 결정하면, N1QL은 평면적이고 분산된 관계형 데이터를 집계 지향적인 문서 모델로 변환할 수 있는 유연성을 제공합니다.
더 많은 리소스:
- 해코레이드 사용 를 사용하여 JSON 데이터 모델링에 대해 협업할 수 있습니다.
- SQL Server 시리즈의 일부 에서는 동일한 유형의 JSON 데이터 모델링 결정에 대해 설명합니다.
- 카우치베이스가 오라클을 이기는 방법일부 데이터를 오라클에서 다른 곳으로 이전하려는 경우
- 관계형에서 NoSQL로 전환하기: 시작하는 방법 백서.