Couchbase를 처음 사용하든 노련한 수의사라면 스코프와 컬렉션에 대해 들어보셨을 것입니다. 직접 사용해 볼 준비가 되셨다면 이 도움말을 참조하세요.
범위 및 컬렉션은 다음 버전에 도입된 새로운 기능입니다. 카우치베이스 서버 7.0 릴리즈 를 사용하여 Couchbase 내에서 데이터를 논리적으로 구성할 수 있습니다. 자세히 알아보기, 범위 및 컬렉션에 대한 다음 소개를 읽어보세요..
레거시 RDBMS를 문서 데이터베이스에 매핑하거나 수백 개의 마이크로서비스 및/또는 테넌트를 단일로 통합하려는 경우 범위 및 컬렉션을 활용해야 합니다. 카우치베이스 클러스터(결과적으로 TCO가 훨씬 낮아집니다).
이 문서에서는 이전 CouchBase 버전에서 CouchBase 7.0의 범위 및 컬렉션 사용으로 마이그레이션을 계획하는 방법에 대해 설명합니다.
높은 수준의 마이그레이션 단계
다음은 Couchbase 7.0에서 범위 및 컬렉션으로 마이그레이션하는 높은 수준의 단계입니다.
모든 단계가 필수적인 것은 아니며 사용 사례와 특정 기술 요구 사항에 따라 다릅니다. 다음 섹션에서 이러한 각 단계에 대한 자세한 내용을 안내해 드리겠습니다.
- Couchbase Server 7.0으로 업그레이드하기
- 범위 및 컬렉션 전략 계획: 필요한 버킷, 범위, 컬렉션 및 인덱스를 결정합니다. 기존 버킷에서 새 버킷/범위/컬렉션으로의 매핑을 결정합니다. 범위, 컬렉션 및 인덱스를 만드는 스크립트를 작성합니다.
- 애플리케이션 코드를 마이그레이션하세요: 이 애플리케이션 코드는 N1QL 쿼리를 포함한 카우치베이스 SDK 코드입니다.
- 데이터 마이그레이션: 오프라인 전략이 배포에 적합한지 또는 온라인 마이그레이션이 필요한지 결정합니다. 그에 따라 조치를 취하세요.
- 데이터베이스 보안 전략을 계획하고 구현하세요: 필요한 사용자 및 역할 할당을 결정합니다. 이러한 할당을 관리하기 위한 스크립트를 만듭니다.
- 새로운 컬렉션 인식 애플리케이션을 사용해 보세요.
- 카우치베이스 데이터베이스의 XDCR 설정 및 백업 설정
Couchbase 7로 업그레이드
업그레이드를 위해 알아야 할 사항은 다음과 같습니다. 카우치베이스 서버 7.0:
-
- 7.0 이상의 모든 버킷에는
_기본값범위가 있는_기본값컬렉션을 수집합니다. - Couchbase 7.0으로 업그레이드하면 버킷에 있는 모든 데이터를
_기본값버킷 수집. - 다음이 있습니다. 기존 애플리케이션에 영향 없음. 예를 들어, Bucket에 대한 SDK 2.7 레퍼런스
B로 자동 해결됩니다.B._default._default(참조_기본값범위 및 컬렉션).
- 7.0 이상의 모든 버킷에는
아래 다이어그램은 Couchbase 6에서 Couchbase 7로 데이터를 마이그레이션한 후 데이터가 버킷, 범위 및 컬렉션에서 어떻게 구성되는지 보여줍니다.
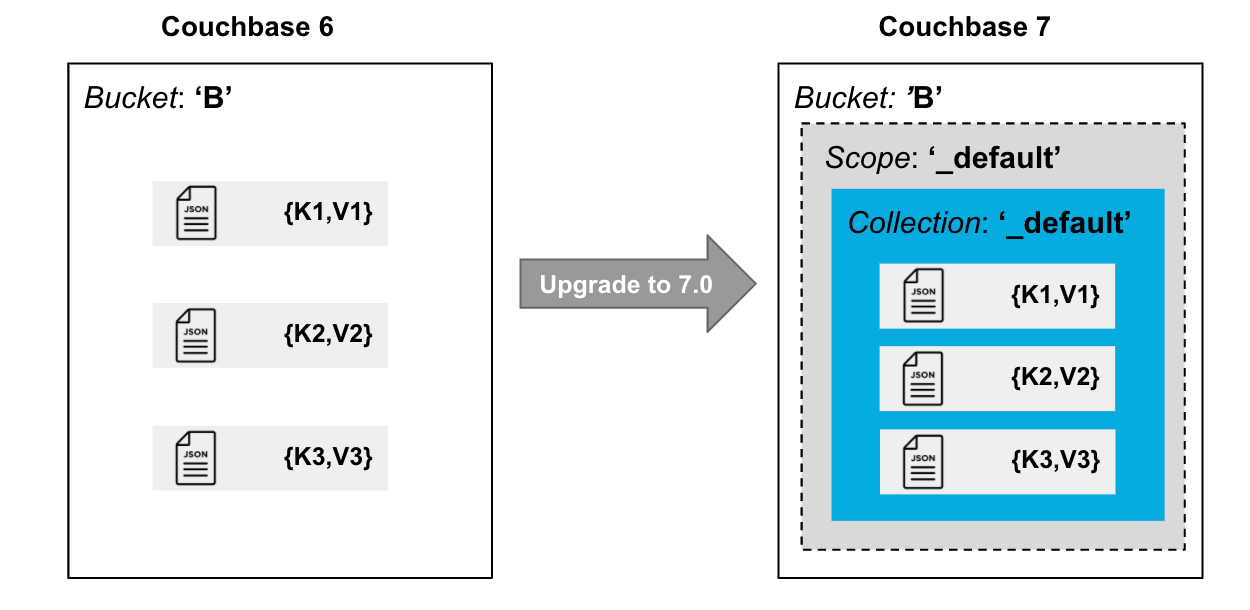
명명된 범위 및 컬렉션을 사용하지 않으려면 여기서 멈추세요.
하지만 이 새로운 데이터 정리 기능을 사용할 준비가 되셨다면 계속 읽어보세요.
범위 및 컬렉션 전략 계획
다음은 제가 경험한 가장 일반적인 데이터베이스 마이그레이션 시나리오입니다. 마이그레이션 시나리오는 다를 수 있으며 마일리지도 다를 수 있습니다.
통합: 여러 버킷에서 단일 버킷의 컬렉션으로 통합하기
일반적인 시나리오 중 하나는 여러 개의 버킷을 하나의 버킷으로 통합하여 총소유비용(TCO)을 낮추고자 하는 경우입니다.
클러스터당 최대 30개의 버킷만 보유할 수 있는 반면, 컬렉션은 클러스터당 1000개까지 보유할 수 있으므로 훨씬 더 높은 집적도를 허용합니다. 이는 마이크로서비스 통합의 일반적인 시나리오입니다.
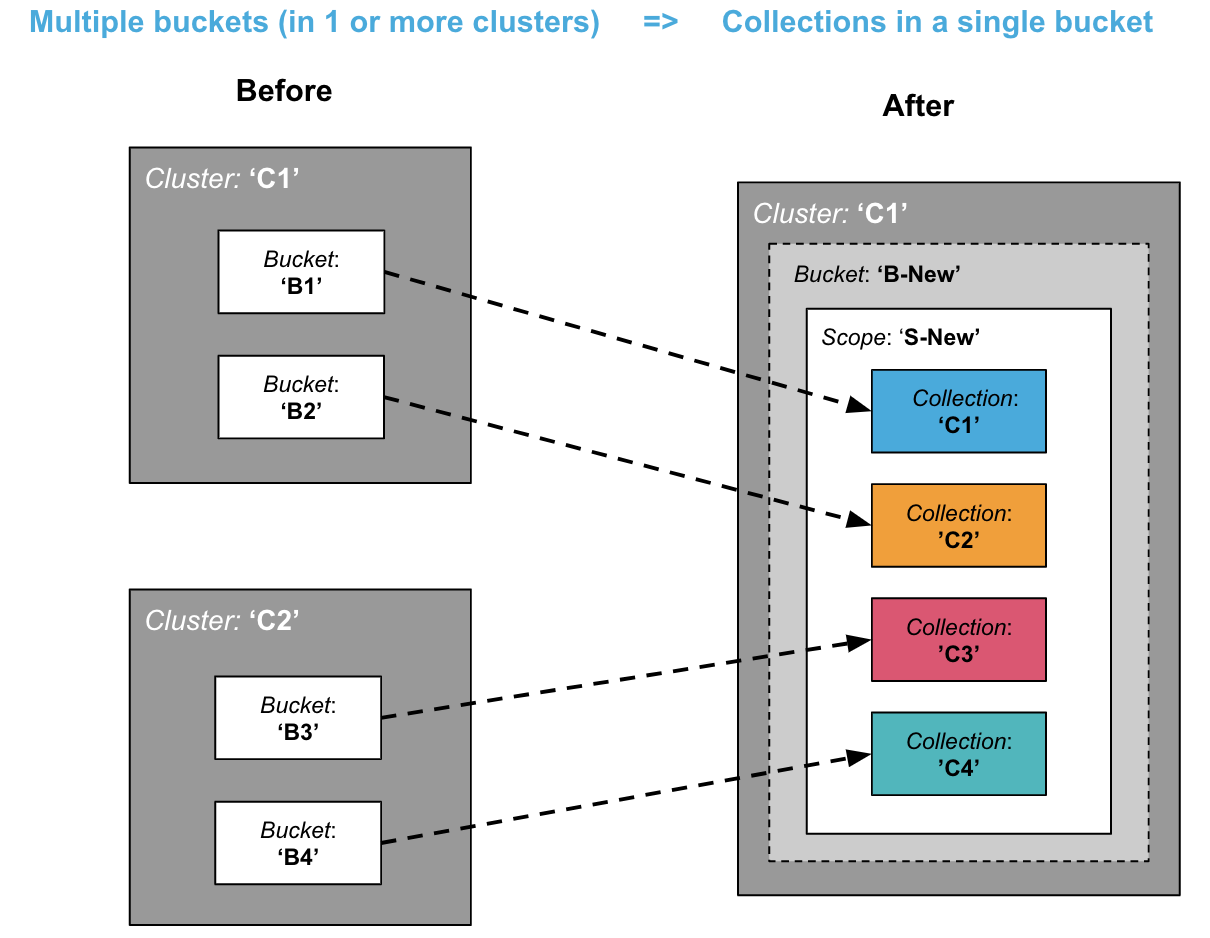
위의 다이어그램은 동일한 범위에 속하는 모든 대상 컬렉션을 보여줍니다. 그러나 대상 컬렉션을 다른 범위에 속하게 할 수도 있습니다.
분할: 단일 버킷에서 버킷 내 여러 컬렉션으로 분할하기
또 다른 일반적인 시나리오는 단일 버킷 내에 있는 데이터를 마이그레이션하여 여러 컬렉션(동일한 버킷 내)으로 분할하는 것입니다.
이전에 다른 유형의 데이터에 대해 유형 = foo 필드 또는 다음과 같은 키 접두사를 사용하여 foo_key. 이제 이러한 데이터 유형은 각각 고유한 컬렉션에 저장할 수 있으므로 논리적 격리, 보안 격리, 복제 및 액세스 제어의 이점을 누릴 수 있습니다.
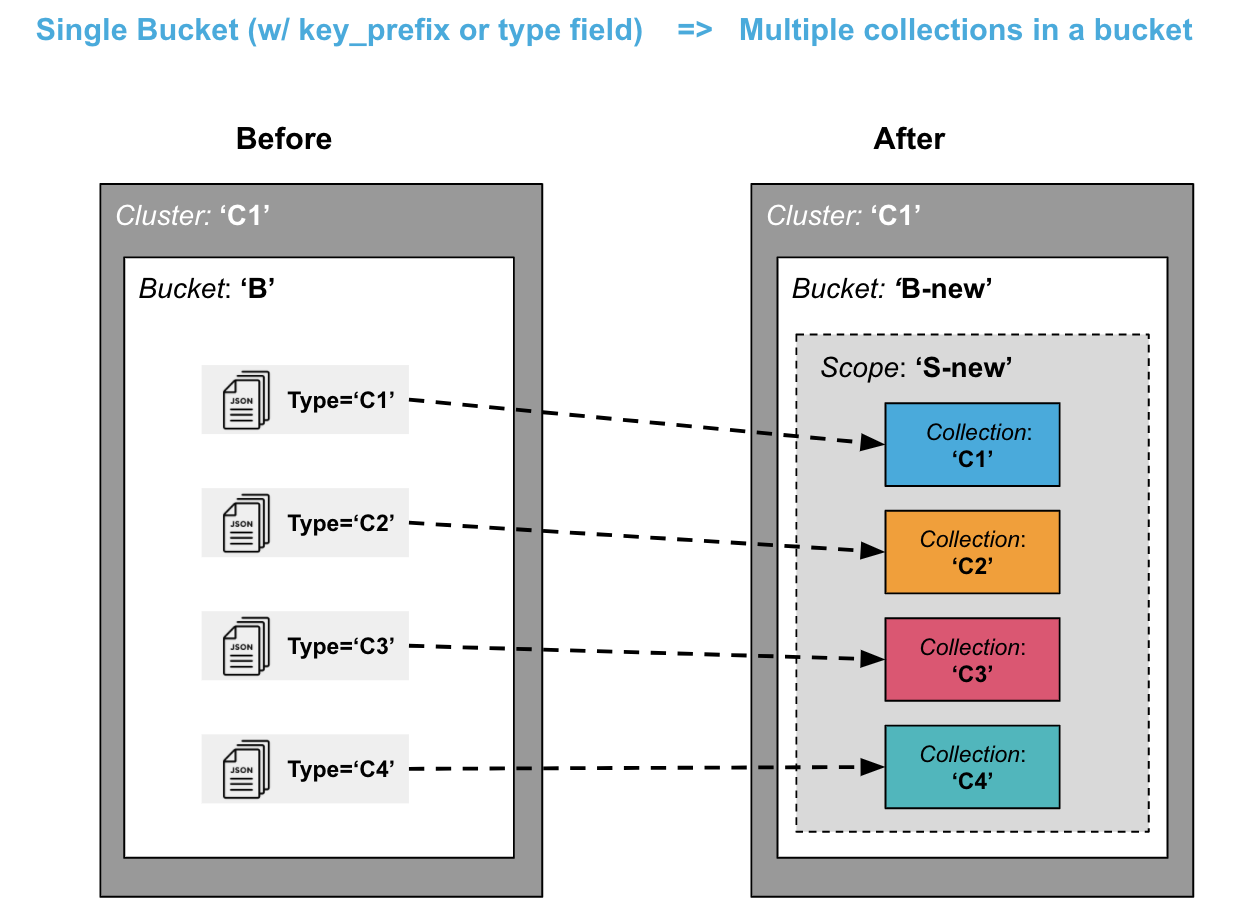
이 시나리오는 특히 키 접두사 또는 유형 필드를 제거하려는 경우 이전의 '통합' 시나리오보다 조금 더 복잡할 수 있습니다. 보다 간단한 마이그레이션을 위해 키 접두사 및 유형 데이터 필드는 컬렉션과 다소 중복될 수 있지만 그대로 둘 수 있습니다.
범위, 컬렉션 및 색인 만들기
원하는 범위, 컬렉션 및 인덱스를 계획한 후에는 이러한 엔티티를 만들기 위한 스크립트를 만들어야 합니다. 다음을 사용할 수 있습니다. 카우치베이스 SDK 를 선택합니다, couchbase-cli, REST API를 직접 사용하거나 N1QL 스크립트를 사용할 수도 있습니다. 를 클릭합니다.
다음은 CLI(couchbase-cli 및 cbq 셸)를 사용하여 범위, 컬렉션 및 인덱스를 만드는 예제입니다.
|
1 2 3 4 5 6 7 8 |
// create a Scope called 'myscope' using couchbase-cli ./couchbase-cli collection-manage -c localhost -u Administrator -p password --bucket testBucket --create-scope myscope // create a Collection called mycollection in myscope ./couchbase-cli collection-manage -c localhost -u Administrator -p password --bucket testBucket --create-collection myscope.mycollection // create an index on mycollection using cbq ./cbq --engine=localhost:8093 -u Administrator -p password --script="create index myidx1 on testBucket.myscope.mycollection(field1,field2);" |
참고 인덱스 생성 문은 not 를 사용하여 데이터의 유효성을 검사해야 합니다. 유형 = foo 또는 키 접두사 한정 절을 더 이상 사용하지 않습니다.
애플리케이션 코드 마이그레이션
명명된 범위 및 컬렉션을 사용하려면 애플리케이션 코드( N1QL 쿼리)를 마이그레이션해야 합니다.
이전에 유형 필드 또는 키 접두사를 사용했다면(분할 시나리오에서와 같이) 다음과 같이 됩니다. not 더 이상 필요하지 않습니다.
SDK 코드 샘플
SDK 코드에서 클러스터에 연결하고, Bucket을 열고, 문서를 저장하고 검색하기 위해 Collection 개체에 대한 참조를 얻어야 합니다. 컬렉션 이전에는 모든 키-값 연산을 버킷에서 직접 수행했습니다.
참고: Couchbase SDK 3.0으로 마이그레이션한 경우 컬렉션을 사용하기 위한 일부 작업을 이미 완료한 것입니다(지금까지는 기본 컬렉션만 사용할 수 있었지만).
다음은 간단한 Java SDK 컬렉션에 문서를 저장하고 검색하기 위한 코드 스니펫입니다:
|
1 2 3 4 5 6 7 8 9 10 |
Cluster cluster = Cluster.connect("127.0.0.1", "Administrator", "password"); Bucket bucket = cluster.bucket("bucket-name"); Scope scope = bucket.scope("scope-name"); Collection collection = scope.collection("collection-name"); JsonObject content = JsonObject.create().put("author", "mike"); MutationResult result = collection.upsert("document-key", content); GetResult getResult = collection.get("document-key"); |
N1QL 쿼리
이제 실행하려면 N1QL 쿼리 을 클릭하고 위의 Java 예제에서 컬렉션에 대해 다음을 수행합니다:
|
1 2 3 |
//run a N1QL using the context of the Scope scope.query("select * from collection-name"); |
스코프에서 직접 쿼리할 수 있다는 점에 주목하세요. 범위 개체에 대한 위의 쿼리는 자동으로 다음과 같이 매핑됩니다. 버킷 이름.범위 이름.컬렉션 이름에서 *를 선택합니다..
N1QL에 경로 컨텍스트를 제공하는 또 다른 방법은 다음과 같이 설정하는 것입니다. 쿼리 옵션. 예를 들어
|
1 2 |
QueryOptions qo = QueryOptions.queryOptions().raw("query_context", "bucket-name.scope-name"); cluster.query("select * from collection-name", qo); |
범위에는 여러 개의 컬렉션이 있을 수 있으며, 범위 내에서 컬렉션 이름을 참조하여 컬렉션에 직접 가입할 수 있습니다. 여러 범위(또는 여러 버킷)에 걸쳐 쿼리해야 하는 경우에는 클러스터 개체를 사용하여 쿼리하는 것이 좋습니다.
N1QL 쿼리는 더 이상 자격을 부여할 필요가 없습니다. 유형 = foo 필드 (또는 키_프리픽스 한정자), 해당되는 경우.
예를 들어, 이 오래된 N1QL 쿼리는...
|
1 2 3 4 5 6 |
SELECT r.destinationairport FROM Travel a JOIN Travel r ON a.faa = r.sourceairport AND r.type = "route" WHERE a.city = "Toulouse" AND a.type = "airport"; |
...이 됩니다:
|
1 2 3 4 |
SELECT r.destinationairport FROM Airport a JOIN Route r ON a.faa = r.sourceairport WHERE a.city = "Toulouse"; |
컬렉션으로 데이터 마이그레이션
다음으로, 기존 데이터를 새 이름의 범위 및 컬렉션으로 마이그레이션해야 합니다.
가장 먼저 결정해야 할 것은 오프라인 마이그레이션(애플리케이션이 몇 시간 동안 오프라인 상태인 경우)을 수행할 수 있는지 아니면 애플리케이션 다운타임을 최소화하면서 대부분 온라인 마이그레이션을 수행해야 하는지 여부입니다.
오프라인 마이그레이션은 전반적으로 더 빠르며 추가 디스크 공간이나 노드 측면에서 추가 리소스가 덜 필요할 수 있습니다.
오프라인 마이그레이션
오프라인 마이그레이션을 선택하는 경우 N1QL 또는 백업/복원을 사용할 수 있습니다. 두 가지 옵션에 대해 자세히 살펴보겠습니다.
오프라인 마이그레이션에 N1QL 사용
전제 조건: 클러스터에 디스크 여유 공간이 있어야 하며 쿼리 서비스를 사용 중이어야 합니다.
이 접근 방식을 따르면 마이그레이션은 다음과 같은 모양이 됩니다:
- 새 범위, 컬렉션 및 인덱스를 만듭니다.
- 기존 애플리케이션을 오프라인으로 전환합니다.
- 명명된 각 컬렉션에 대해:
- 삽입-다음에서 선택
_기본값컬렉션을 명명된 컬렉션으로 변경합니다(적절한 필터 사용). - 다음에서 데이터 삭제
_기본값위 단계에서 마이그레이션한 컬렉션(공간 절약을 위해, 또는 공간이 문제가 되지 않는 경우 마지막에 이 작업을 수행할 수 있음)을 삭제합니다.
- 삽입-다음에서 선택
- 마이그레이션된 데이터를 확인합니다.
- 오래된 버킷을 삭제합니다.
- 새 신청서를 온라인으로 제출하세요.
오프라인 마이그레이션을 위한 백업/복원 사용
전제 조건: 백업 파일을 저장하려면 디스크 공간이 필요합니다.
이 접근 방식을 사용하면 마이그레이션은 다음과 같이 진행됩니다:
- 새 범위, 컬렉션 및 인덱스 만들기
- 애플리케이션을 오프라인으로 전환
- 백업하기(
cbbackupmgr) 7.0 클러스터의 - 명명된 컬렉션에 명시적 매핑을 사용하여 복원합니다. 사용
--필터 키그리고--map-data(아래 예 1 및 2 참조). - 새 신청서를 온라인으로 제출하세요.
예 1: 복원 중 필터링 없음
이 예제는 전체 _기본값 컬렉션을 명명된 컬렉션에 추가합니다. (이는 통합 시나리오의 경우입니다).
|
1 2 3 4 5 6 7 8 |
// Backup the default Scope of a Bucket upgraded to 7.0 cbbackupmgr config -a backup -r test-01 --include-data beer-sample._default cbbackupmgr backup -a backup -r test-01 -c localhost -u Administrator -p password // Restore above backup to a named Collection cbbackupmgr restore -a backup -r test-01 -c localhost -u Administrator -p password --map-data beer-sample._default._default=beer-sample.beer-service.service_01 |
예 2: 필터링을 통한 복원
이 예제에서는 다음 중 일부를 이동합니다. _기본값 컬렉션을 다른 이름의 컬렉션에 추가합니다(분할 시나리오의 경우에 해당).
|
1 2 3 4 5 6 7 8 9 10 |
// Backup the travel-sample Bucket from a cluster upgraded to 7.0 cbbackupmgr config -a backup -r test-02 --include-data travel-sample cbbackupmgr backup -a backup -r test-02 -c localhost -u Administrator -p password // Restore type=’airport’ documents to a Collection travel.booking.airport cbbackupmgr restore -a backup -r test-02 -c localhost -u Administrator -p password --map-data travel-sample._default._default=travel.booking.airport --auto-create-buckets --filter-values '"type":"airport"' // Restore key_prefix =’airport’ documents to a Collection travel.booking.airport cbbackupmgr restore -a backup -r test-02 -c localhost -u Administrator -p password --map-data travel-sample._default._default=travel.booking.airport --auto-create-buckets --filter-keys airport_* |
XDCR을 사용한 온라인 마이그레이션
대부분 온라인 마이그레이션을 수행하려면 데이터 센터 간 복제(XDCR)를 사용해야 합니다.
기존 클러스터의 여유 용량에 따라 소스 및 대상 버킷이 같은 클러스터에 있는 경우 자체-XDCR을 수행하거나 별도의 클러스터를 설정하여 복제할 수 있습니다.
따라야 할 단계는 다음과 같습니다:
- 소스 클러스터에서 대상 클러스터로 XDCR을 설정합니다(원본 클러스터에 여유 디스크 공간과 컴퓨팅 리소스가 있는 경우 자체 XDCR을 수행할 수 있습니다).
- 새 버킷, 범위 및 컬렉션을 만듭니다.
- 버킷에서 다른 버킷으로 직접 복제를 설정하거나
bucket.scope.collection를 사용하거나, 하나의 버킷의 기본 컬렉션을 여러 컬렉션으로 분할해야 하는 경우 마이그레이션 모드(자세한 내용은 아래 참조)를 사용하세요. - 각 대상에 대해 명시적 매핑 규칙을 지정하여 데이터의 하위 집합을 지정할 수 있습니다.
- 복제 대상이 파악되면 이전 애플리케이션을 오프라인으로 전환하세요.
- 새 애플리케이션을 온라인에서 새 클러스터(또는 자체-XDCR을 사용하는 경우 새 버킷)로 지정합니다.
- 기존 클러스터(또는 자체-XDCR을 사용하는 경우 기존 버킷)를 삭제합니다.
XDCR을 사용하여 여러 버킷에서 단일 버킷으로 마이그레이션하기
이 단계는 통합 시나리오를 위한 것입니다.
XDCR 설정은 다음과 같이 표시됩니다:
-
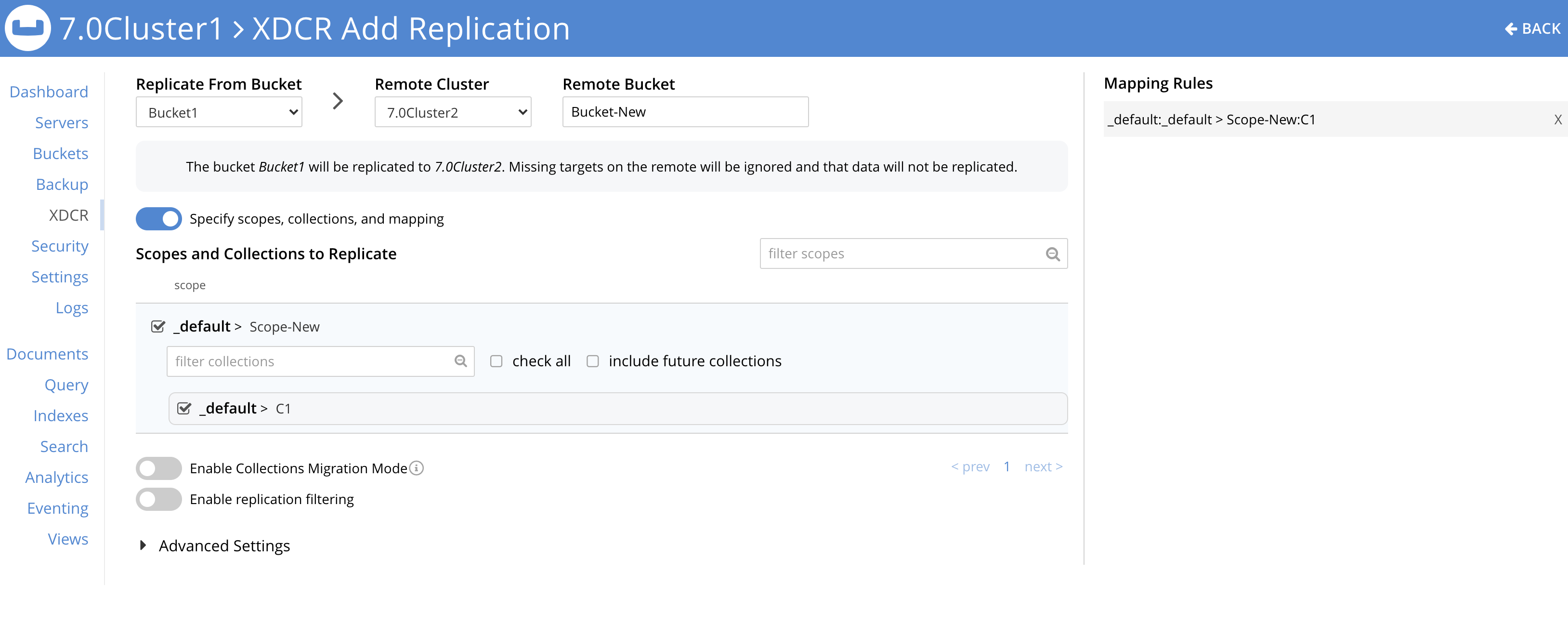
- 각 소스 버킷에 대해 대상 버킷 및 범위에서 명명된 컬렉션에 대한 복제를 설정합니다.
다음 스크린샷은 하나의 소스 버킷에 대해 설정된 XDCR을 보여줍니다:
XDCR을 사용하여 단일 버킷 내에서 여러 컬렉션으로 분할하기
이 단계는 분할 시나리오를 위한 것입니다.
소스를 매핑하려면 _기본값 컬렉션을 여러 대상 컬렉션으로 마이그레이션하려면 XDCR에서 제공하는 마이그레이션 모드를 사용해야 합니다.
아래 XDCR 화면은 마이그레이션 모드가 사용 중인 것을 보여줍니다:
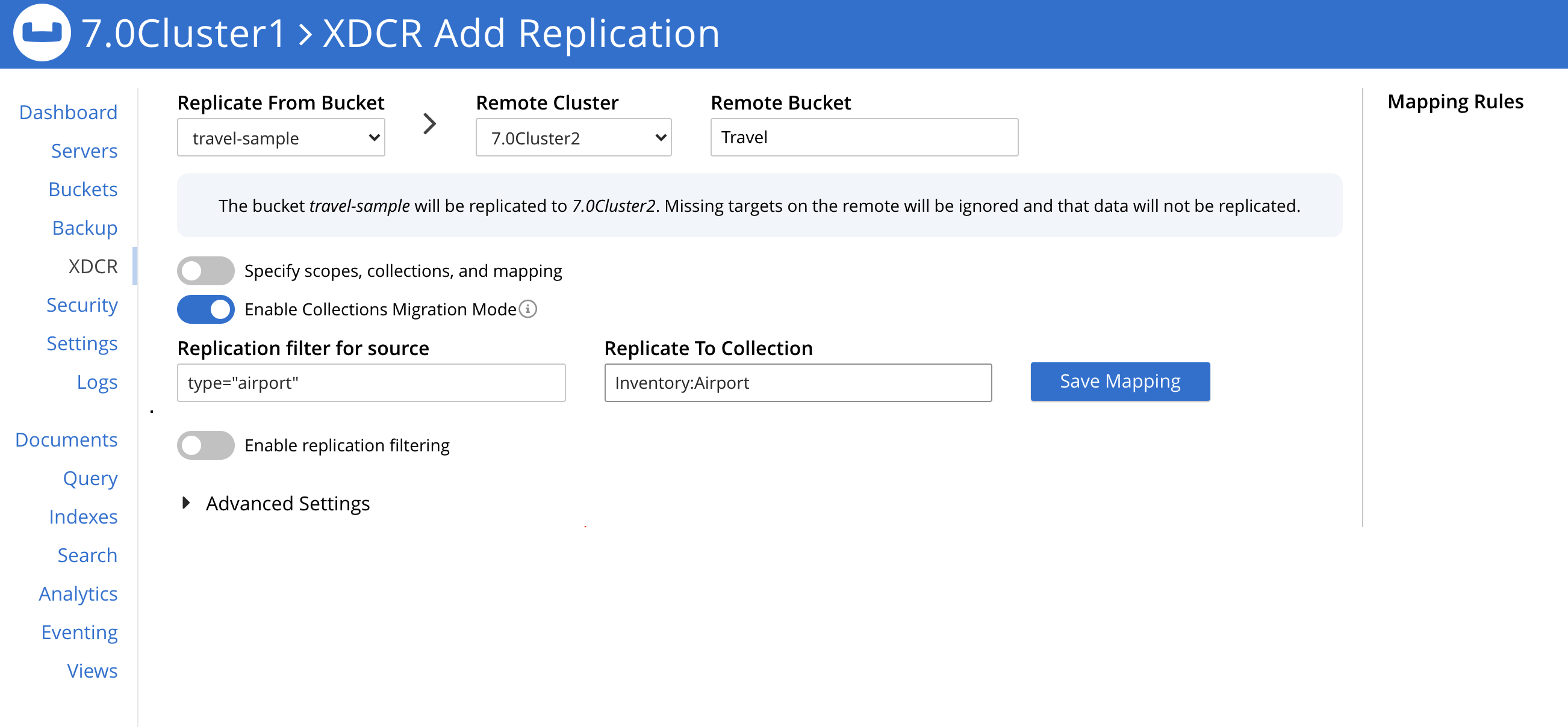
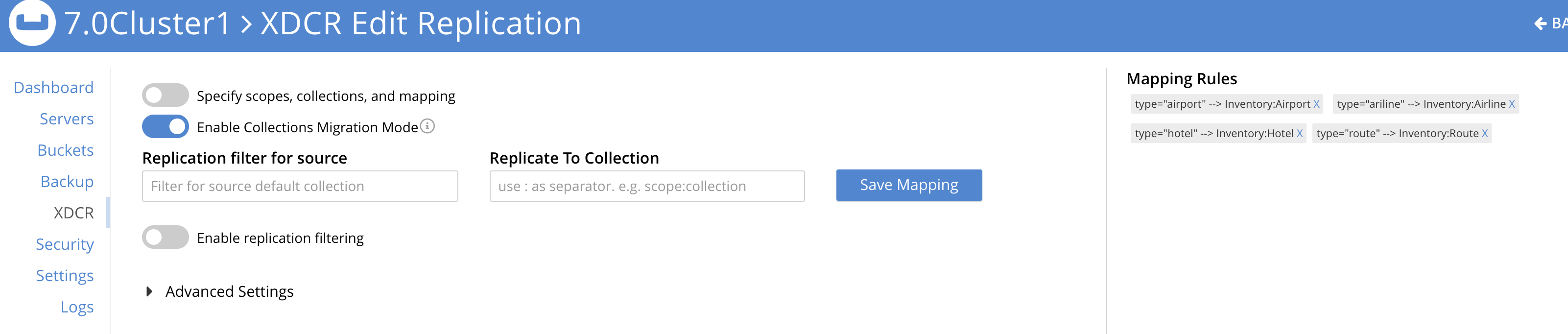
설정해야 하는 필터는 다음과 같은 네 가지입니다.여행 샘플._기본값._기본값 가 소스입니다. 새 버킷은 여행 가 대상입니다.)
-
- 필터
유형="공항"로 복제하여인벤토리:공항 - 필터
유형="항공사"로 복제하여인벤토리:항공사 - 필터
유형="호텔"로 복제하여인벤토리:호텔 - 필터
유형="경로"로 복제하여인벤토리:경로
- 필터
데이터베이스 보안 전략 계획 및 구현
이제 모든 데이터를 명명된 범위와 컬렉션에 넣었으므로 어떤 데이터에 권한을 할당할지 더 세밀하게 제어할 수 있습니다. 이전에는 버킷 수준에서만 그렇게 할 수 있었습니다.
범위 및 컬렉션에 대한 역할 기반 액세스 제어(RBAC) 보안에 대한 자세한 내용은 이 문서를 참조하세요: 컬렉션을 위한 RBAC 보안 소개 를 참조하거나 RBAC 관련 문서.
Couchbase 7의 범위 및 컬렉션 수준에서 사용할 수 있는 역할은 다음과 같습니다.
관리자 역할:
-
- 범위 관리자 역할은 범위 수준에서 사용할 수 있습니다. 범위 관리자는 자신의 범위에서 컬렉션을 관리할 수 있습니다.
데이터 리더 역할:
-
- 데이터 리더
- 데이터 라이터
- 데이터 DCP 리더
- 데이터 모니터링
쿼리 역할:
-
- FTS 검색기
- 쿼리 선택
- 쿼리 업데이트
- 쿼리 삽입
- 쿼리 삭제
- 쿼리 색인 관리
- 쿼리 관리 기능
- 쿼리 실행 함수
결론
이 가이드가 Couchbase 7의 범위 및 컬렉션으로 성공적으로 마이그레이션하는 데 도움이 되었기를 바랍니다.
7.0 릴리스에 대한 자세한 내용을 확인하세요, 새로운 기능 문서를 확인하세요. 또는 릴리스 노트 살펴보기.
새로운 범위 및 컬렉션 기능에 대해 어떻게 생각하시나요? 다음에 대한 여러분의 피드백을 기다리겠습니다. 카우치베이스 포럼.
지금 바로 Couchbase 7 살펴보기
Shivani 님, 동기화 게이트웨이에서 동기화할 범위와 컬렉션을 구성할 수 있나요? 특정 범위/컬렉션의 문서만 동기화되도록 제한하고 싶어요.
동기화 게이트웨이 지원은 추후 제공될 예정입니다. 따라서 7.0에서는 동기화 게이트웨이를 사용하여 기본 컬렉션의 문서도 받을 수 있습니다.
위의 오타가 죄송합니다. 7.0에서는 동기화 게이트웨이를 사용하여 기본 컬렉션의 문서만 받을 수 있다는 뜻입니다.
범위와 컬렉션을 사용하여 멀티테넌트 애플리케이션을 분류할 계획이었습니다. 컬렉션 또는 범위를 기준으로 동기화할 수 있는 동기화 게이트웨이가 있었으면 좋았을 텐데요. 동기화 게이트웨이 지원은 언제쯤 기대할 수 있나요?
몇 가지 질문이 더 있습니다.
1. 동일한 문서가 기본 컬렉션과 다른 사용자 지정 컬렉션에 포함될 수 있나요?
2. 여러 범위가 기본 컬렉션을 참조할 수 있나요?
동기화 게이트웨이 지원 기간은 미정입니다.
1) 두 개의 다른 컬렉션(기본값과 사용자 지정 또는 두 개의 다른 사용자 지정)에 있는 '동일한' 문서는 본질적으로 두 개의 다른 문서입니다. 두 개의 다른 컬렉션에서 동일한 문서 키를 사용할 수 있는지 묻는다면 대답은 '예'입니다.
2) 이 질문이 이해가 되지 않습니다. 기본 컬렉션은 기본 범위에만 존재합니다. 다른 범위에는 기본 컬렉션이 없습니다. 사용자는 기본 컬렉션을 만들 수 없습니다(카우치베이스에서만 기본 컬렉션을 만듭니다).
Shivani 님, 동기화 게이트웨이에서 범위 및 컬렉션 지원 여부에 대한 업데이트가 있나요?
사용자 @GaneshN은 Couchbase 서버 7.0을 사용하여 멀티테넌트 애플리케이션을 설계하고 있으며, 해당 기능을 기반으로 클라이언트 동기화를 구현해야 합니다.
가네쉬 게시물이 거의 1 년이 지났으니 좋은 소식이 있기를 바랍니다.