이 게시물은 Couchbase의 복합 벡터 인덱싱을 살펴보는 여러 부분으로 구성된 시리즈 중 네 번째 파트입니다. 이전 포스팅을 놓치셨다면 다음 포스팅도 놓치지 마세요. 1부, 파트 2 그리고 파트 3.
이 시리즈에서 다룰 내용입니다:
- 개념, 용어, 개발자의 동기 부여 등 복합 벡터 인덱스가 중요한 이유에 대해 알아보세요. 스마트 식료품 추천 시스템을 실행 예제로 사용합니다.
- 카우치베이스 인덱싱 서비스 내에서 복합 벡터 인덱스가 구현되는 방식입니다.
- 복합 벡터 쿼리에서 ORDER BY 푸시다운이 작동하는 방식입니다.
- 실제 성능 동작 및 벤치마킹 결과.
4부: 복합 벡터 인덱스의 성능 분석
에이전트 애플리케이션과 AI 워크로드는 점점 더 효율적인 벡터 검색을 필요로 하고 있습니다. 기존의 근사 근사 이웃(ANN) 검색 시스템은 메모리 소비, 인덱스 구축 시간, 실시간 업데이트 메커니즘과 같은 문제로 인해 규모에 따라 어려움을 겪을 수 있습니다.
복합 벡터 인덱스(CVI)는 스칼라 술어가 대략적인 벡터 검색 전에 후보 집합을 줄이는 필터링된 ANN 워크로드를 위해 설계되었습니다. 매우 큰 규모의 순수 벡터 워크로드의 경우, Couchbase는 하이퍼스케일 벡터 인덱스도 제공합니다. 모범 사례는 다음 설명서를 참조하세요. 여기.
이 게시물에서는 필터링된 ANN 워크로드에 대한 복합 벡터 인덱스의 성능 동작에 초점을 맞춥니다. 1~3부에서 소개한 개념과 실행 모델을 기반으로, 이제 대규모 데이터 세트에서 스칼라 선택성이 달라질 때 처리량과 p95 지연 시간이 어떻게 변하는지를 살펴봅니다.
이 게시물에서 선택도 %는 쿼리의 스칼라 부분이 검색 공간을 제약한 후에도 데이터 세트의 관련성이 얼마나 남아 있는지를 나타냅니다. 선택성이 낮을수록 적격 데이터 세트의 범위가 좁아져 시스템이 수행해야 하는 벡터 작업의 양이 줄어듭니다.
성능 구축
내부 구축 벤치마크에서 CVI는 7시간 만에 10억 개의 128차원 벡터에 대한 인덱스를 구축할 수 있었습니다. 이는 인덱싱 아키텍처와 최신 하드웨어의 사용을 보여줍니다.
빌드 성능은 다음 인프라에서 측정되었습니다:
프로세서: 32코어 AMD-EPYC-7643
메모리: 128GB RAM
저장소: 삼성 PM1743 기업용 SSD 15.36TB
데이터 세트: SIFT 벤치마크 데이터
이는 프로덕션 워크로드를 위해 수십억 개의 벡터를 인덱싱하는 것이 실용적이라는 것을 보여줍니다.
쿼리 성능: 속도와 정확성의 결합
CVI는 높은 회수율로 쿼리 성능을 제공합니다. SQ8 양자화 및 하나의 주요 스칼라 필드가 있는 100M SIFT 데이터 세트를 사용하여 CVI는 다양한 선택도 비율에서 75% recall@10을 달성했으며, 처리량 및 지연 시간 특성을 측정했습니다.
선택성이 좁아짐에 따라 처리량 향상
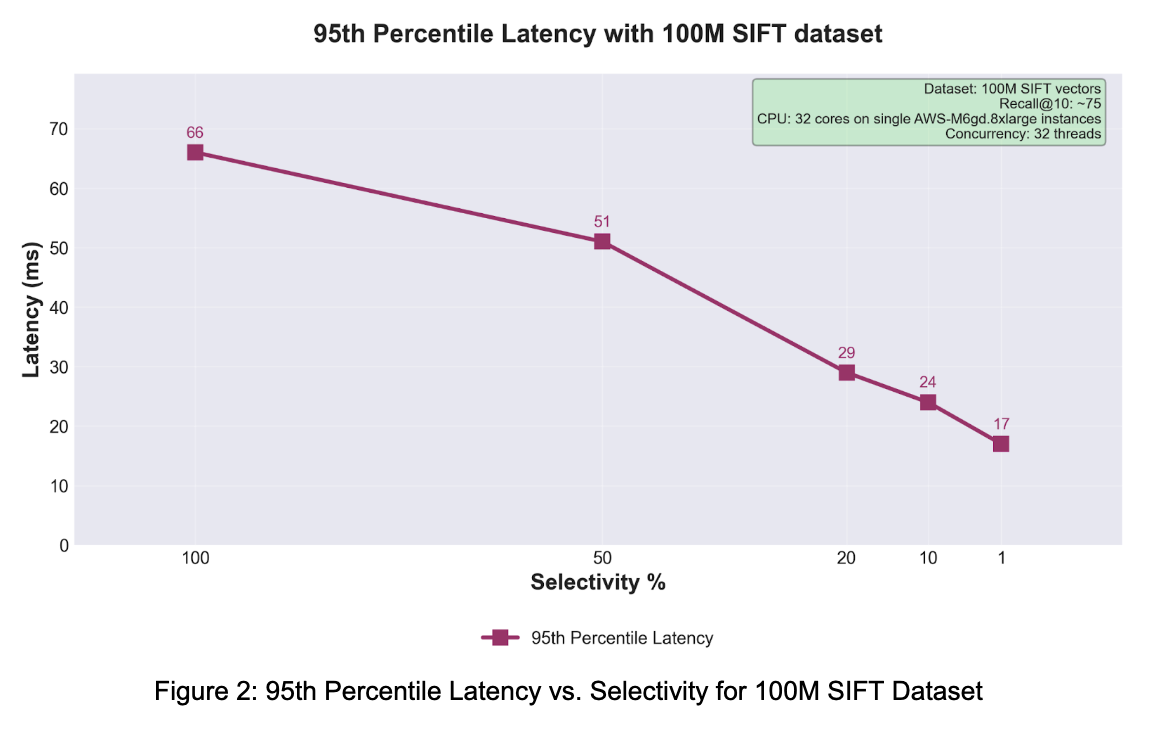
처리량과 지연 시간 곡선은 두 가지 각도에서 동일한 이야기를 들려줍니다. 스칼라 제약 조건이 좁을수록 실행 경로를 통해 흐르는 작업의 양이 줄어들어 시스템 처리량과 테일 동작이 모두 개선됩니다. 카테고리, 브랜드, 테넌트, 지역, 언어 또는 규정 준수 경계와 같은 엄격한 제약 조건을 자연스럽게 포함하는 애플리케이션의 경우 이러한 동작이 바로 복합 벡터 인덱스의 강점이 되는 부분입니다.
테스트 설정
정의
|
1 |
CREATE INDEX `vector-idx` on `bucket-1`.`_default`.`_default` (scalar, emb Vector) WITH {'dimension':128, 'similarity':'L2', 'description':'IVF,SQ8'} |
쿼리
|
1 2 3 4 |
SELECT meta().id FROM `bucket-1`.`_default`.`_default` WHERE scalar = 'eligible' ORDER BY ANN_DISTANCE(emb, , 'L2', ) LIMIT 10 |
그리고 스칼라 필드는 선택도에 따라 데이터에 채워지고 는 예상 회수율을 얻기 위해 조정됩니다.
커브가 이런 식으로 보이는 이유
CVI의 성능은 여러 아키텍처 기능의 영향을 받습니다:
- 주문 인식 스캔
- CVI는 벡터 유사성 검색과 결합된 스칼라 술어를 활용하는 순서 인식 스캔 파이프라인을 사용하여 효율적인 액세스 패턴을 구현하고 I/O 작업을 최소화합니다.
- 병렬 처리 아키텍처
- 이 시스템은 중심점 간 병렬 처리를 사용하여 여러 스캔 작업자가 벡터 공간의 서로 다른 파티션에서 동시에 작업할 수 있습니다.
- SIMD 가속 거리 계산
- CVI는 유사성 평가를 가속화하고 계산 오버헤드를 최소화하기 위해 FAISS 라이브러리를 통한 SIMD 연산을 사용합니다.
- HNSW 라우팅 계층
- 계층적 탐색 가능한 작은 세계(HNSW) 라우팅 계층을 사용하면 관련 중심을 식별하여 검색 공간을 줄일 수 있습니다.
애플리케이션 예시
CVI의 성능 특성은 다양한 사용 사례에 적용할 수 있습니다:
- 전자상거래 및 제품 추천
- 가격, 브랜드, 카테고리 필터를 사용한 제품 유사성 검색
- 콘텐츠 검색 및 검색
- 메타데이터 제약 조건이 있는 문서 및 미디어 유사성 검색
- 사기 탐지 및 위험 평가
- 시간적 제약이 있는 트랜잭션 패턴의 이상 징후 탐지
- 개인 맞춤형 마케팅
- 고객 세분화 및 타겟팅된 추천
결론
이 시리즈의 첫 세 부분에서는 복합 벡터 인덱스가 중요한 이유, 구현 방법, 그리고 복합 스칼라+벡터 쿼리에 대해 유연한 ORDER BY 푸시다운을 가능하게 하는 방법을 설명했습니다. 이 마지막 파트에서는 이러한 설계의 성능에 대한 보상을 보여드립니다.
SQ8 양자화를 사용한 100M SIFT 벤치마크에서 처리량은 100% 선택성에서 800 QPS에서 1% 선택성에서 2853 QPS로 증가했으며, p95 지연 시간은 66ms에서 17ms로 개선되었습니다. 별도의 내부 빌드 벤치마크에서는 최신 상용 서버 하드웨어에서 10억 개가 넘는 128차원 벡터 인덱스를 약 7시간 만에 구축했습니다.
복합 벡터 인덱스는 애플리케이션이 하나의 인덱스 구조에서 스칼라 제약 조건과 의미적 유사성을 결합하는 동시에 강력한 처리량과 낮은 테일 레이턴시를 대규모로 제공할 수 있다는 점에서 필터링된 ANN 워크로드의 경우, 이것이 바로 복합 벡터 인덱스의 핵심 가치 제안입니다.