데이터 마이그레이션은 도전으로 가득합니다.
SQL Server나 Oracle과 같은 관계형 데이터베이스(RDBMS)에서 마이그레이션하는 경우, 대상 데이터 모델에 따라 마이그레이션된 문서를 비정규화하는 것이 가장 큰 과제입니다. 스코프와 컬렉션이 도입되면서 카우치베이스 서버 7.0 릴리즈 를 사용하면 버킷 내에서 문서를 쉽게 분류하고 정리할 수 있습니다.
SQL Server 또는 Oracle에서 Couchbase로 데이터를 마이그레이션하는 데 사용할 수 있는 옵션은 다음과 같습니다:
-
- CSV/JSON을 Couchbase로 가져오기 사용
cbimport. - 사용자 지정 ETL 코드를 작성하여 RDBMS에서 Couchbase로 데이터를 이동합니다.
- CSV/JSON을 Couchbase로 가져오기 사용
대부분의 경우 cbimport 그 자체만으로도 Oracle 또는 SQL Server 데이터베이스에서 카우치베이스 왜냐하면 cbimport 필요한 범위와 컬렉션으로 문서를 가져올 수 있습니다.
이 글에서는 다음과 같은 방법을 사용하는 방법에 대해 설명합니다. SQL++ 쿼리 (이하 N1QL이라고 함)을 사용하여 범위 내의 여러 컬렉션에서 가져온 문서를 병합/표준화할 수 있습니다.
배경 정보
먼저, Couchbase Server 7.0에서 RDBMS 엔티티와 그에 상응하는 엔티티 간의 유사점을 검토해 보겠습니다:
| RDBMS 엔티티 | 카우치베이스 등가물 |
| 데이터베이스 | 버킷 |
| 스키마 | 범위 |
| 표 | 컬렉션 |
| 행 | 문서 |
| 칼럼 | 속성 |
RDBMS에서 Couchbase로의 데이터 마이그레이션에는 두 가지 변형이 있을 수 있습니다:
- 일대일 매핑: 각 RDBMS 테이블을 Couchbase의 컬렉션으로 가져오면 해당 테이블의 각 행은 다음과 같이 됩니다. JSON 문서. 이 마이그레이션은 비정규화가 필요하지 않고 전체 프로세스를 다음을 사용하여 완료할 수 있으므로 가장 간단한 마이그레이션입니다.
cbimport만 해당됩니다. - 다대일 매핑: RDBMS 데이터베이스의 여러 테이블을 하나의 Couchbase 문서로 결합하거나 정규화된 RDBMS 테이블을 Couchbase 문서로 비정규화한다고 할 수 있습니다. 비정규화를 달성하기 위해 다음과 같은 여러 가지 옵션이 있습니다:
- 소스에서 비정규화: 즉, Oracle/SQL Server에서 JSON 형식으로 데이터를 내보내고 해당 JSON의 구조가 대상 Couchbase 데이터 모델과 일치해야 합니다. 그런 다음 내보낸 JSON 문서를 다음을 사용하여 Couchbase로 가져옵니다.
cbimport. 그러나 대상 데이터 모델을 생성하려면 복잡한 쿼리 작업을 수행해야 하므로 항상 가능한 것은 아닙니다. 게다가 모든 데이터베이스에서 JSON 내보내기가 항상 지원되는 것은 아닙니다. - 중간 레이어에서의 비정규화: 이는 사용자 정의 코드(C#, Java 등과 같은 모든 프로그래밍 언어)를 사용하여 RDBMS에서 Couchbase로 데이터를 이동하는 경우에만 가능합니다. 이렇게 하면 코드가 소스 데이터베이스에 연결하고, 소스에서 데이터를 읽고, 대상 Couchbase 데이터 모델에 따라 데이터를 수정한 다음, Couchbase에 데이터를 씁니다. 하지만 각 대상 데이터 모델에 대한 코드를 작성해야 하므로 많은 개발 작업이 필요합니다.
- 목적지에서의 비정규화: 이 옵션에서는 다음 중 하나를 사용하여 RDBMS에서 Couchbase로 데이터를 이동합니다.
cbimport또는 다른 방법으로 정규화합니다. 그런 다음 사용자 지정 N1QL 쿼리를 작성하여 Couchbase 수준에서 비정규화를 수행합니다. 이 옵션은 대상 데이터 모델에 최대 3~4단계의 하위 중첩이 있는 경우에 적합한 옵션입니다. 중첩이 3~4개 수준 이상인 경우에도 이 옵션을 선택할 수 있지만, 이 경우 복잡성이 더 커집니다.
- 소스에서 비정규화: 즉, Oracle/SQL Server에서 JSON 형식으로 데이터를 내보내고 해당 JSON의 구조가 대상 Couchbase 데이터 모델과 일치해야 합니다. 그런 다음 내보낸 JSON 문서를 다음을 사용하여 Couchbase로 가져옵니다.
연습 예제: N1QL을 사용하여 대상에서 비정규화를 사용하여 RDBMS에서 카우치베이스로 데이터 마이그레이션하기
이 마이그레이션 및 비정규화 작업을 시연하기 위해 SQL Server에 5개의 테이블 이름이 포함된 샘플 데이터베이스를 만들었습니다: [고객], [주소], [주문], [주문 세부 정보]및 [제품 세부 정보]. 아래는 관계와 열 세부 정보를 보여주는 데이터베이스 다이어그램입니다:
아래는 각 테이블에 로드된 샘플 데이터입니다:
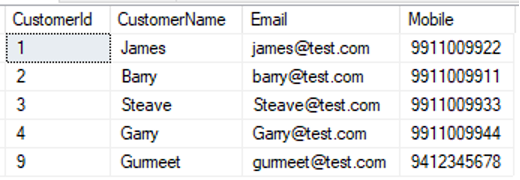
dbo].[고객]에서 *를 선택합니다. |
 |
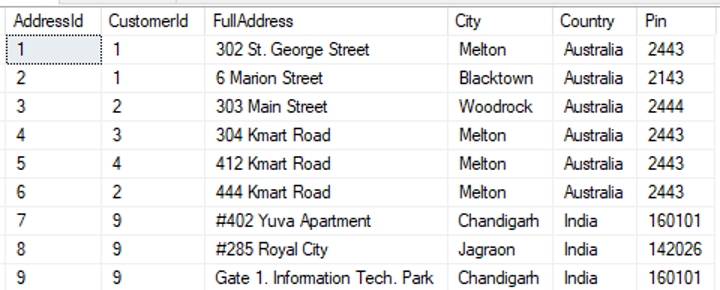
dbo].[주소]에서 *를 선택합니다. |
 |
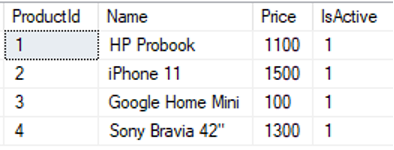
dbo].[제품 세부 정보]에서 *를 선택합니다. |
 |
dbo].[주문]에서 *를 선택합니다. |
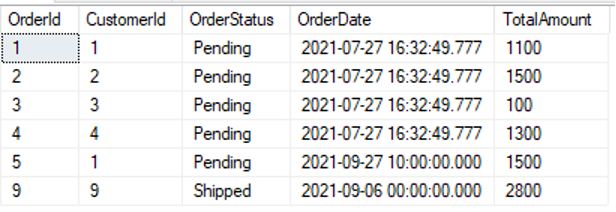 |
dbo].[주문 세부 정보]에서 *를 선택합니다. |
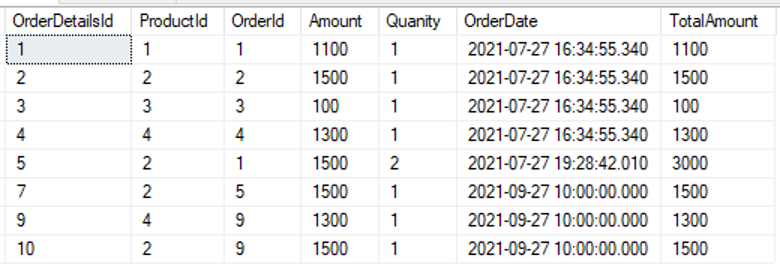 |
Couchbase 7.0 설정: Windows 머신에 Couchbase 7.0을 설치했고 테스트 클러스터가 준비되었습니다. 다음과 같은 이름의 버킷 하나를 만들었습니다. testBucket. 또한 다음과 같은 이름의 범위를 만들었습니다. dbo 에 해당하는 컬렉션을 생성한 다음, RDBMS 스키마에 해당하는 dbo 범위로 설정합니다. 여기서는 컬렉션 이름을 RDBMS 테이블 이름과 동일하게 유지했습니다. 그러나 이는 필수는 아니며 범위 및 컬렉션 이름은 원하는 대로 지정할 수 있습니다.
다음으로 모든 RDBMS 테이블을 이 범위로 가져옵니다(dbo)를 사용하여 cbimport.
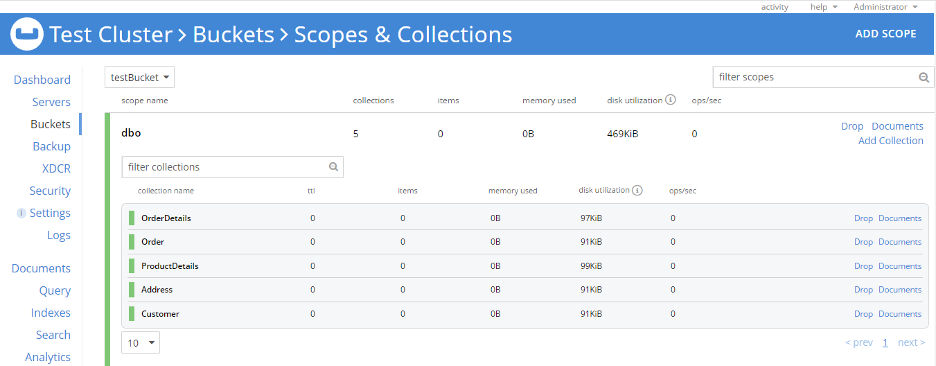
Couchbase로 데이터 가져오기를 준비해 보겠습니다:
1단계: SQL Server 내보내기 마법사를 사용하여 테이블 데이터를 CSV로 내보냅니다.
2단계: 다음을 사용하여 Couchbase로 문서 가져오기 cbimport:
Windows 명령 프롬프트를 열고 다음 주소로 리디렉션합니다. C:\프로그램 파일\Couchbase\서버\bin 를 클릭하고 cbimport 명령을 사용합니다. 제발 에 대한 자세한 내용은 이 문서를 참조하십시오. cbimport 구문. 아래는 Customer.csv 경로에 위치한 파일 D:/CSV 를 dbo 범위 및 고객 수집. 여기서 문서 키는 다음과 같습니다. 고객 ID CSV 열 이름에서 선택된 CustomerId.

마찬가지로 다음을 가져올 수 있습니다. 주소, 제품 세부 정보, 주문 그리고 주문 세부 정보 CSV를 해당 컬렉션 내의 dbo 범위입니다. 현재 5개의 컬렉션이 있습니다. dbo 범위로 설정하고 각 컬렉션에 문서를 포함합니다(아래 강조 표시).
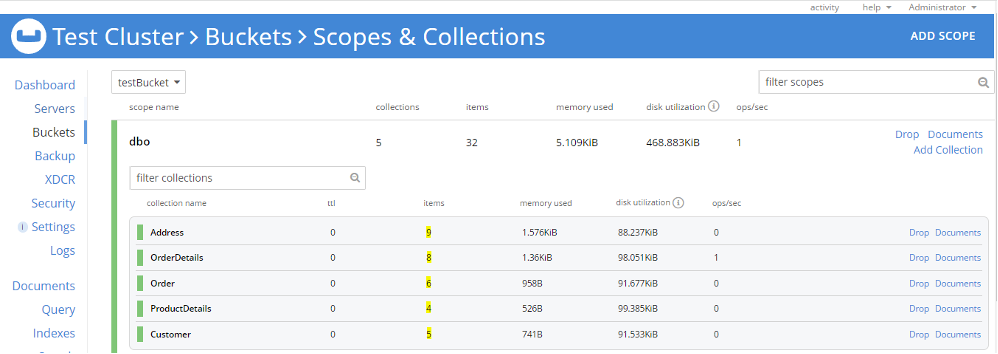
3단계: 가져온 데이터를 확인해 봅시다. 이 단계는 UI를 통해 문서를 확인하거나 N1QL을 사용하여 문서 구조를 확인할 수 있습니다. 5개의 기본 인덱스 를 사용하여 각 컬렉션에 대해 문서 검증을 위한 N1QL 쿼리를 실행할 수 있습니다. 가져온 문서의 수와 문서 구조, 속성 및 데이터를 일치시켜 검증을 수행할 수 있습니다.
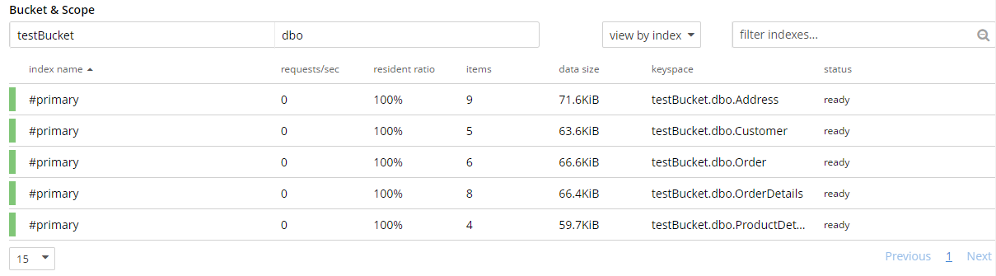
참고: N1QL 쿼리를 실행하려면 해당 컬렉션에 대한 인덱스(기본 또는 보조)가 있어야 합니다.
아래는 각 컬렉션에 대한 N1QL 쿼리 결과입니다(쿼리 결과 보기를 '테이블'로 변경했습니다):
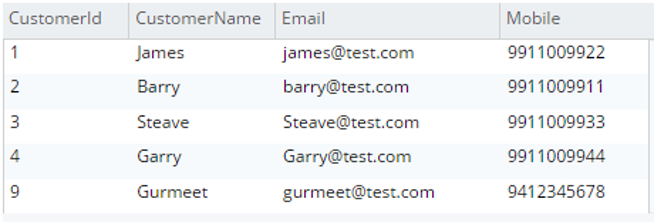
testBucket.dbo에서 c.*를 선택합니다.고객 c |
 |
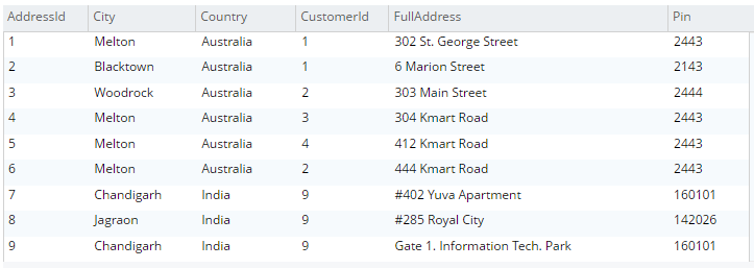
testBucket.dbo에서 a.*를 선택합니다.주소 a |
 |
testBucket.dbo에서 p.*를 선택합니다.제품 세부 정보 |
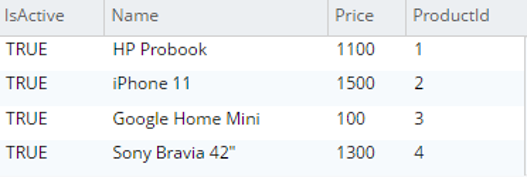 |
testBucket.dbo에서 o.*를 선택합니다.주문 o |
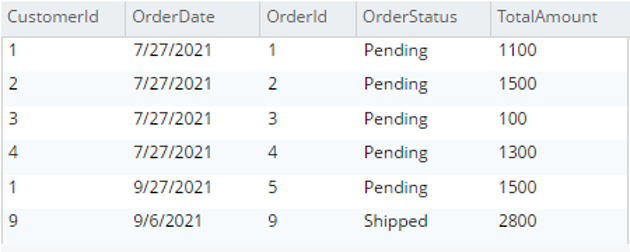 |
testBucket.dbo에서 od.*를 선택합니다.주문 세부 정보 |
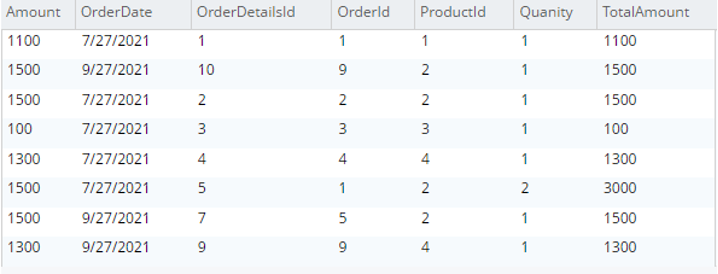 |
문서를 성공적으로 가져오지만 일대일 매핑, 즉 각 테이블을 컬렉션으로 가져오는 것입니다. 일대일 매핑만 필요한 테이블(예:, 제품 세부 정보); 이 단계에서 데이터 마이그레이션이 완료됩니다.
그러나 비정규화를 수행해야 하는 테이블의 경우 최종 데이터 모델을 얻기 전에 몇 가지 단계가 더 필요합니다. 예를 들어, RDBMS 테이블 고객, 주소, 주문 그리고 주문 세부 정보 를 단일 문서로 병합해야 합니다. 대상 데이터 모델의 모습은 다음과 같아야 합니다:
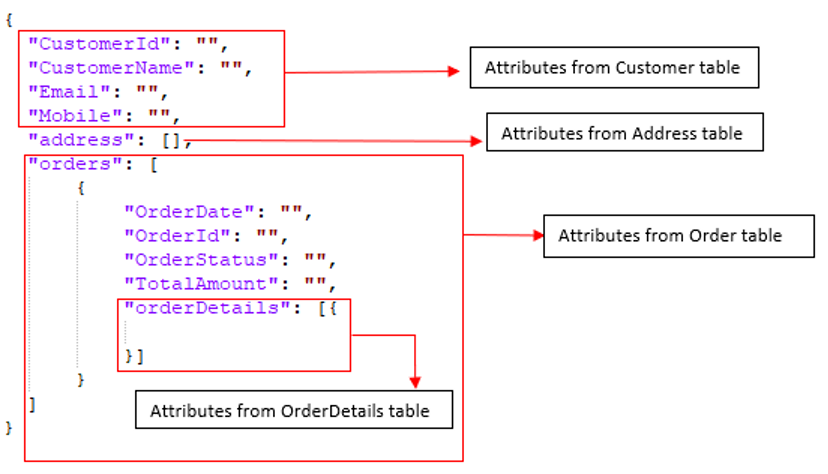
4단계: 대상 대상의 비정규화를 위해(예, 카우치베이스 서버), 상향식 접근 방식을 따르겠습니다. 먼저 주문 세부 정보 에 주문를 병합합니다. 주문 그리고 주소 에 고객.
병합할 N1QL 쿼리를 준비해 보겠습니다. 주문 세부 정보 를 주문 문서에 추가합니다. 이를 위해 다음을 사용합니다. 그룹화 기준 그리고 ARRAY_AGG 를 입력하면 쿼리는 다음을 기준으로 그룹화된 주문 세부 정보 배열을 반환합니다. 주문 ID.
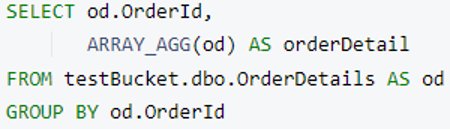
참고: 다음을 사용할 수 있습니다. 제한 키워드 이후 그룹화 기준 를 사용하여 결과 크기를 제한하여 대용량 데이터에서 더 빠르게 실행할 수 있습니다.
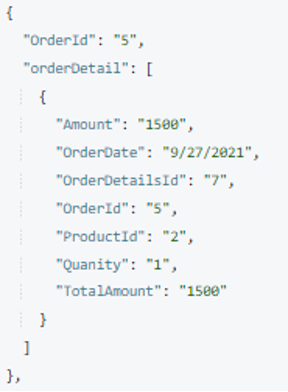
이제 우리는 주문 세부 정보 배열이 준비되었습니다. 이제 이 배열을 주문 문서에 저장합니다. 다음을 사용합니다. 카우치베이스 MERGE 문 를 사용하여 이 작업을 수행합니다. 여기에서는 새 속성을 추가합니다. 주문 세부 정보 모든 주문 문서에 Order.OrderId 그리고 OrderDetails.OrderId 가 일치합니다.
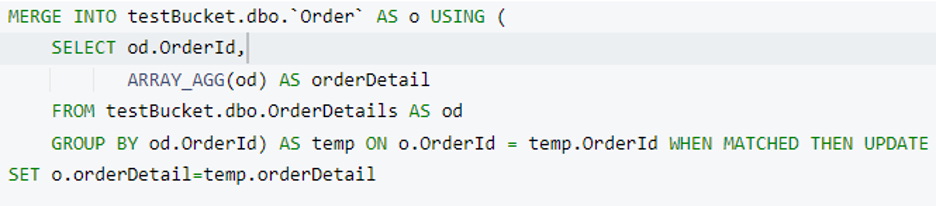
이 쿼리를 실행하기 전에 쿼리에 필요한 인덱스를 살펴보겠습니다. 이전 쿼리는 기본 인덱스에서 작동해야 하지만 병합 부분에서는 보조 인덱스를 만들어야 합니다. Couchbase 인덱스 어드바이저가 도와줄 테니 걱정하지 마세요.
쿼리 워크벤치에서 위의 쿼리를 복사하고 "인덱스 어드바이저" 버튼을 클릭합니다. 그러면 자동으로 인덱스 생성 문이 이 쿼리를 실행하는 데 필요합니다.
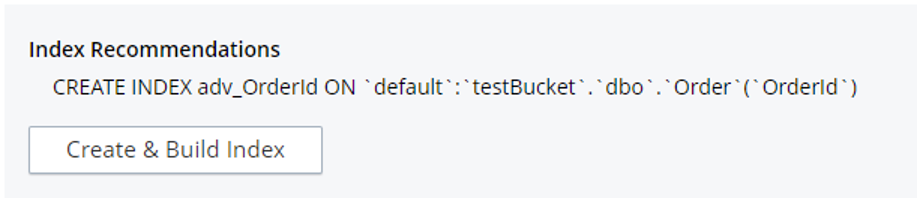
인덱스 어드바이저의 레퍼런스를 가져와서 다음을 추가합니다. 어디 절에 부분 인덱스를 생성하기 위해 주문 컬렉션.

이 부분 색인에는 다음과 같은 항목만 포함됩니다. 주문 문서에서 주문 세부 정보 속성이 누락되었습니다. 수백만 개의 주문 문서를 실행하면 이 인덱스의 문서 수가 줄어들기 시작합니다. 병합 문을 덩어리로 묶어 ( LIMIT 키워드). 예를 들어, 현재 이 색인에는 6개의 문서가 포함되어 있습니다.
에 보조 인덱스 만들기 주문 세부 정보 컬렉션도 아래와 같이 비슷합니다.

이제 두 개의 인덱스가 준비된 상태입니다.

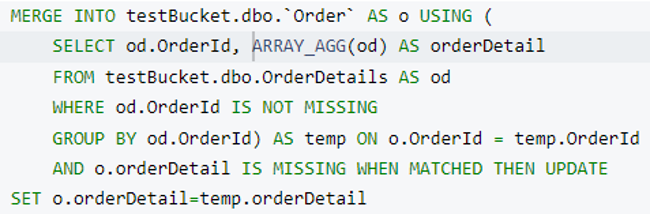
다음으로 병합 문을 사용하여 limit 절을 추가합니다. 업데이트했습니다. 어디 절(하위 쿼리에서 od.OrderId 가 누락되지 않음)를 사용하여 실행 중에 적절한 인덱스를 선택합니다.
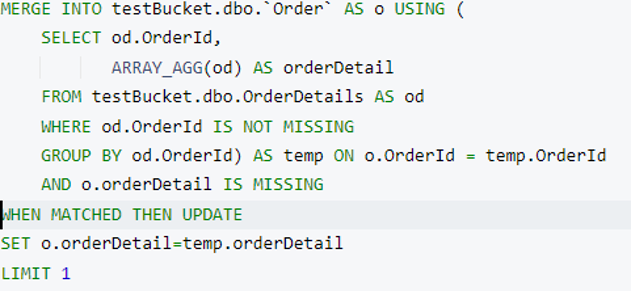
이 문은 다음 중 하나를 업데이트합니다. 주문 문서를 추가하고 관련 주문 세부 정보 를 하위 문서로 선택합니다. 제 경우에는 주문 문서와 함께 orderId=2 를 클릭하고 업데이트했습니다. 주문 ID 2 에는 단 하나의 주문 세부 정보 문서를 배열로 추가했습니다.
색인을 살펴봅시다. 문서 수가 6개에서 5개로 줄었습니다. 문서 하나가 부분 인덱스의 조건을 충족하지 않기 때문입니다. 이 인덱스는 다음과 같이 업데이트됩니다. 주문 문서가 업데이트됩니다.

이제 제한 절을 실행하고 병합 쿼리를 사용하여 모든 주문 문서.
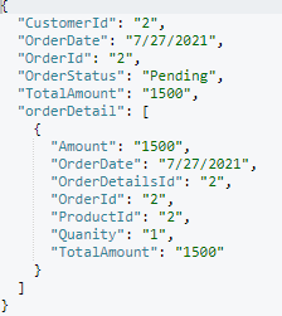
이 성명서는 adv_OrderId 색인 문서 수를 모두 0으로 설정합니다. 주문 문서에 이제 속성이 있습니다. 주문 세부 정보.

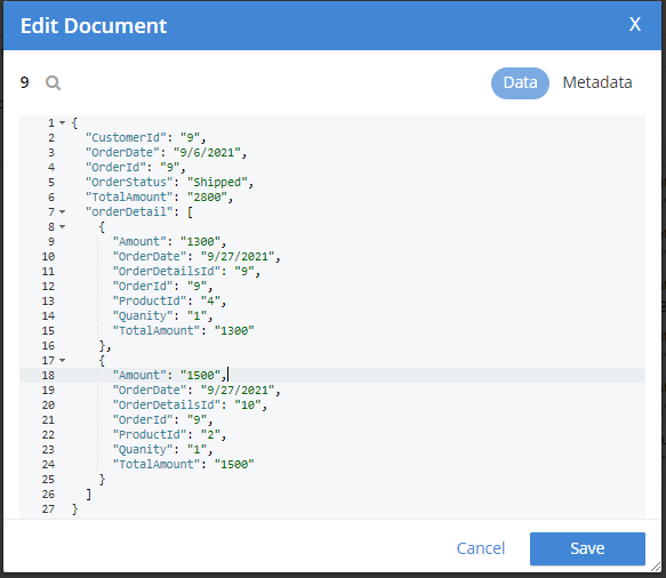
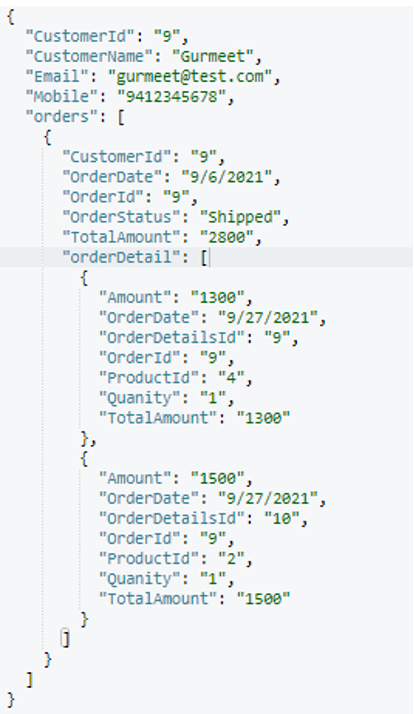
무작위로 하나를 골랐습니다. 주문 문서 (orderId=9)를 클릭하고 아래 출력을 포함시켰습니다.
이제 우리는 주문 문서에 병합할 자식과 함께 준비된 고객. 를 수정해 보겠습니다. 병합 쿼리하고 쿼리 실행을 위한 적절한 인덱스를 생성합니다:
내부 쿼리/서브쿼리에 대한 인덱스입니다:

에 대한 부분 인덱스 고객 컬렉션:
![]()
그리고 병합 병합할 쿼리 주문 에 고객:
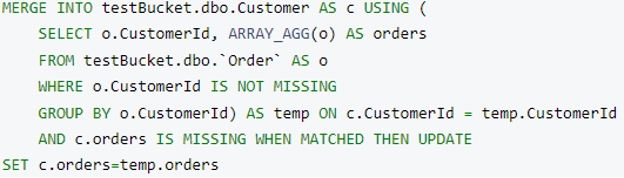
실행 후, 이것이 최종 고객 문서 구조(무작위로 선택):
지금까지 우리는 주문, 주문 세부 정보 그리고 고객 테이블을 만듭니다. 이제 다음을 병합해 보겠습니다. 주소 를 배열로 고객 다른 사람들과 마찬가지로요.
에 대한 인덱스 만들기 고객 컬렉션:
![]()
에 대한 인덱스 만들기 주소 컬렉션:

그리고 병합 병합할 쿼리 주소 에 고객:
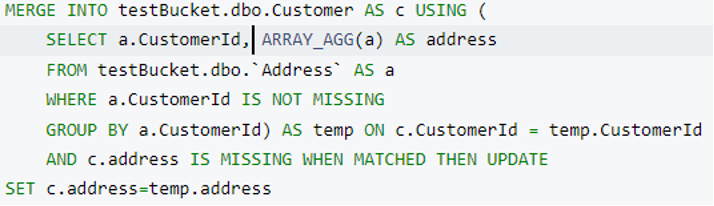
이 쿼리를 실행하면 4개의 RDBMS 테이블로 구성된 최종 데이터 모델을 얻을 수 있습니다.
-
고객가 상위 문서가 됩니다.주소에 포함된 객체의 배열이 될 것입니다.고객.주문에 포함된 객체의 배열이 될 것입니다.고객.주문 세부 정보는 각 객체에 포함된 객체 배열이 될 것입니다.주문객체입니다.
최종 구조의 고객 문서:

마지막으로, N1QL 쿼리를 사용하여 목표 데이터 모델에 따라 비정규화를 달성했습니다.
대신 여러 속성/열을 선택하도록 하위 쿼리를 수정할 수 있습니다. *. 또한 다음을 사용할 수 있습니다. 카우치베이스 객체 함수 를 클릭하여 하위 쿼리/부모 결과에서 속성을 추가/제거할 수 있습니다.
5단계 (선택 사항): 이제 정리할 차례입니다. 대상 데이터 모델을 가지고 있으므로 고객 컬렉션을 삭제하면 나머지 세 컬렉션(주소, 주문 그리고 주문 세부 정보).
결론
요약하면, 목적지에서의 비정규화는 적절한 인덱스와 함께 N1QL 쿼리 언어를 사용하여 달성할 수 있습니다. 데이터 모델에서 가장 아래쪽 하위 데이터부터 시작하여 요구 사항에 따라 모든 수준의 중첩에 사용할 수 있습니다.
