SQL을 배우는 것은 쉽지만, SQL을 구현하는 것은 쉽지 않습니다.
할로윈은 지나갔습니다. 하지만 할로윈 문제의 트릭은 계속 남아 있습니다! 이 문제는 매일 데이터베이스를 통해 해결해야 합니다. SQL은 관계형 데이터베이스를 쉽고, 접근하기 쉽고, 성공적으로 만들었습니다. SQL은 작성하기는 쉽지만 구현에는 많은 복잡성이 숨어 있습니다. 과거부터 시스템 R 와 같은 SQL 및 SQL 기반 언어를 구현하는 우리 모두는 다음과 같습니다. N1QL선언적 쿼리 언어가 계속 유지되도록 하기 위한 규칙, 요구 사항을 학습해야 합니다. 탁월한 효과와 정확성을 제공합니다. 이러한 문제 중 하나는 할로윈 문제. 이 문제에 대해 간략하게 설명하겠습니다. 이 문제를 해결하려면 역사 컴퓨팅 역사에 대한 IEEE 연대기 - 아래 참고 문헌 섹션의 두 번째 링크에서 확인할 수 있습니다.
문제:
간단한 테이블과 인덱스를 생각해 보세요:
|
1 2 |
CREATE TABLE t (empid int primary key, salary int); CREATE INDEX i1 ON t(salary); |
일부 데이터를 로드했는데 인덱스 i1이 다음과 같이 보인다고 가정해 보겠습니다. 인덱스 항목에는 급여에 대한 숫자 값이 있고 그 뒤에 rowid가 있습니다.

이제 가진 자에게 더 많은 것을 준다는 정신으로 모든 직원(연봉 50만 원 이상)의 급여를 인상하고자 합니다.
UPDATE t SET 급여 = 급여 + 100 WHERE 급여 > 50;
쿼리 계획: 다음은 쿼리를 실행하는 일반적인 계획입니다. 이 경우 쿼리 플래너가 인덱스 i1을 사용하여 행을 한정하여 업데이트한다고 가정하겠습니다.
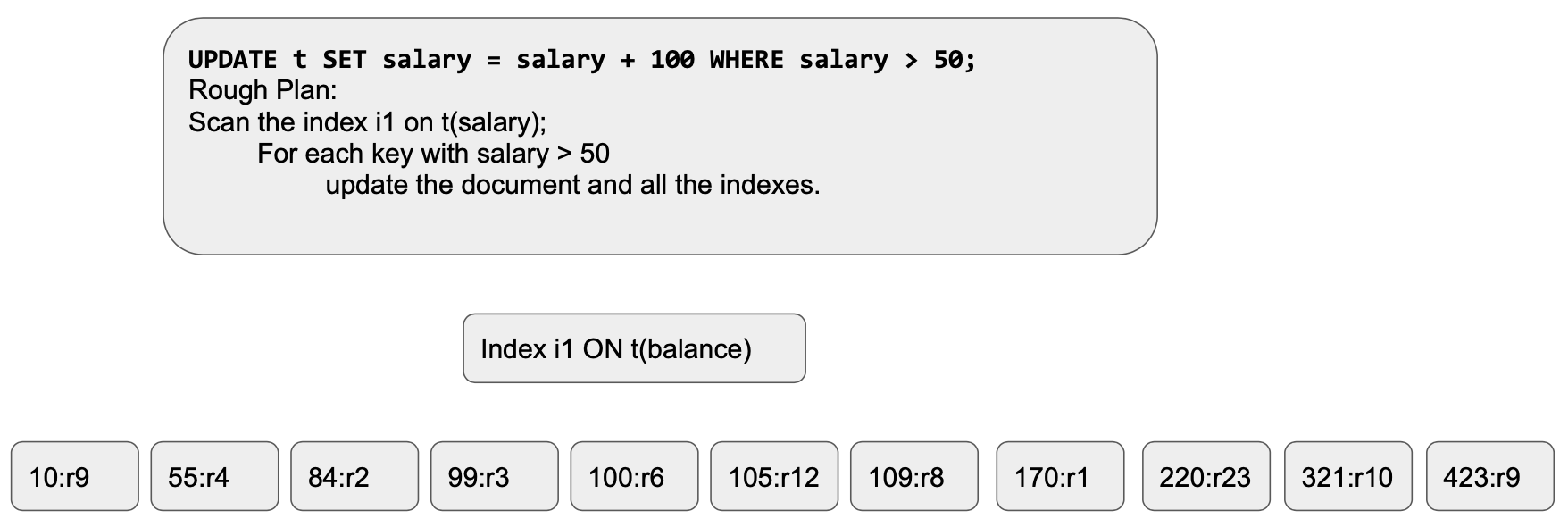
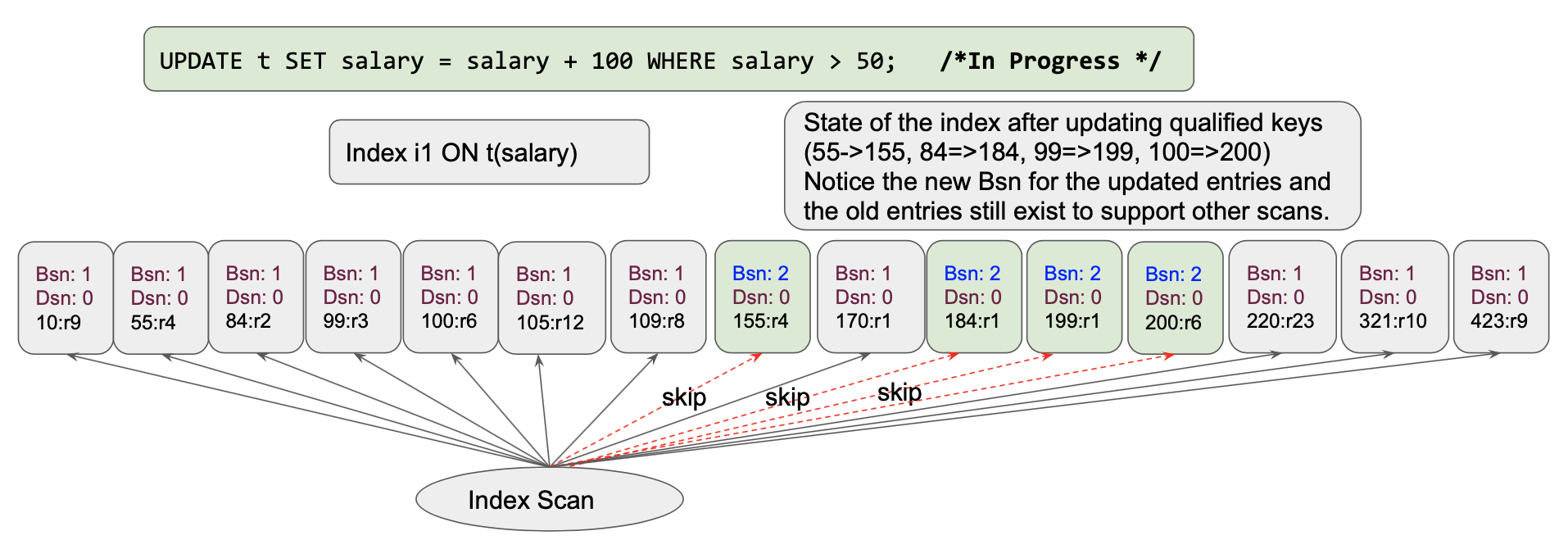
쿼리 실행: 실행이 시작되면 데이터 행이 업데이트되고 인덱스가 동시에 업데이트됩니다. 인덱스는 다음과 같이 보일 것입니다. 각 정규화된 키가 하나씩 업데이트됩니다[왼쪽에서 오른쪽으로 스캔 중]. 다음은 처음 4개의 항목을 업데이트한 후의 인덱스 상태입니다: (55->155, 84=>184, 99=>199, 100=>200)

몇 가지를 더 변경한 후 어떤 결과가 나타나는지 살펴봅시다.
다음 항목으로 이동하면 [155,r2]가 다시 [255,r2]로 업데이트됩니다. 이렇게 하면 여러 키를 여러 번 업데이트하는 것이 반복됩니다. 이는 테이블 t의 집합을 가져와 적격 급여를 100씩 업데이트하려는 의도가 있는 집합 조작 규칙을 위반하는 것입니다.

할로윈 문제의 추가 징후입니다.
INSERT INTO t SELECT * FROM t WHERE balance > 0;
솔루션:
기존 RDBMS(예: Informix)에서는 솔루션이 매우 간단합니다. 변형을 초래하는 각 DML 문에 대해 이 문 내에서 업데이트된 행 ID의 정렬된 목록을 유지합니다. 행을 업데이트하기 전에 이 행이 이미 업데이트되었는지 확인하고 건너뜁니다. 범위 스캔이 제한된 간단한 업데이트의 경우 이 읽기 오버헤드는 거의 눈에 띄지 않습니다. 대규모 업데이트의 경우 메모리에 큰 목록을 유지 관리하는 것이 문제가 될 수 있습니다. 일반적으로 목록이 충분히 커지면 목록이 디스크에 유출됩니다.
카우치베이스 N1QL 및 GSI 솔루션:
Couchbase는 여러 서비스가 포함된 분산 데이터베이스입니다. 쿼리 서비스 를 생성합니다.실행 계획을 수립하고 실행합니다. 솔루션의 개요는 다음과 같습니다.
인덱스가 있을 때의 쿼리를 살펴보겠습니다: t에 인덱스 i1 생성(급여)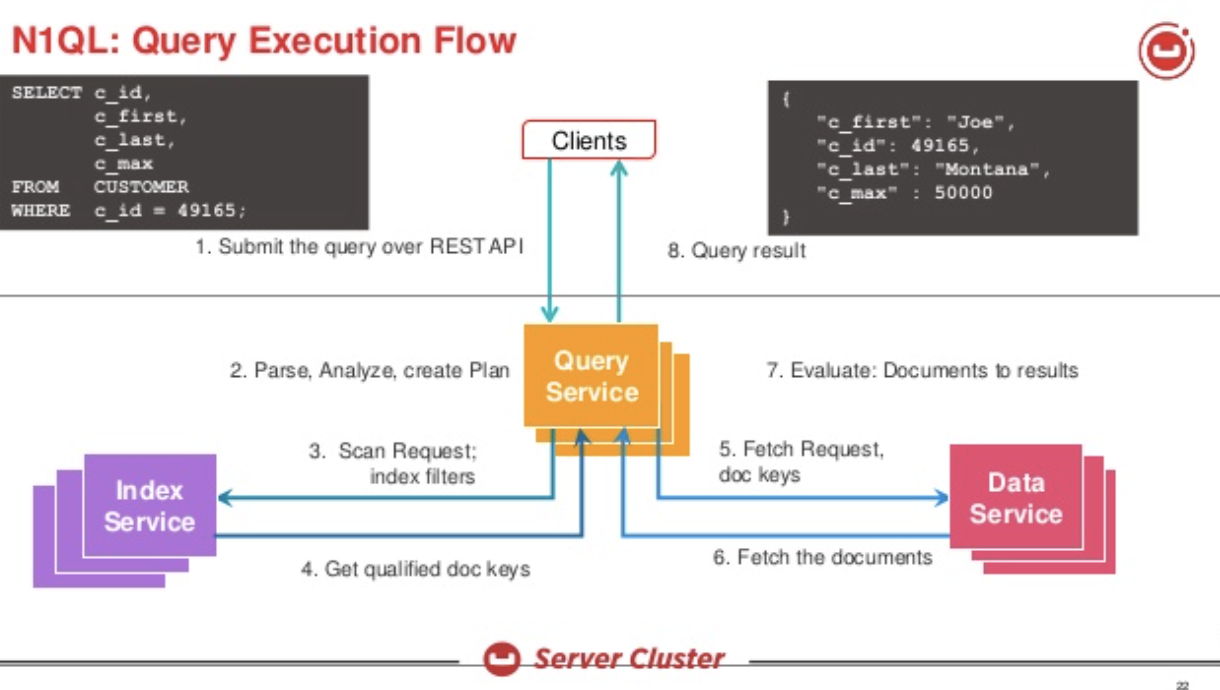 N1QL은 다음과 같은 플랜을 생성합니다: UPDATE 문을 사용하면 이 계획은 인덱스 스캔을 사용하여 업데이트할 문서를 식별하고, 문서를 가져와서 업데이트한 후 다시 씁니다. 이 업데이트는 문서에 동기적으로 수행된다는 점에 유의해야 합니다. 이러한 변경 사항은 DCP를 통해 흐르고 인덱스 업데이트는 비동기적으로 이루어집니다. 대규모 업데이트의 경우에도 인덱스 스캔과 업데이트가 진행되는 동안 스캔 중인 인덱스에 대한 업데이트가 완료될 수 있습니다.
N1QL은 다음과 같은 플랜을 생성합니다: UPDATE 문을 사용하면 이 계획은 인덱스 스캔을 사용하여 업데이트할 문서를 식별하고, 문서를 가져와서 업데이트한 후 다시 씁니다. 이 업데이트는 문서에 동기적으로 수행된다는 점에 유의해야 합니다. 이러한 변경 사항은 DCP를 통해 흐르고 인덱스 업데이트는 비동기적으로 이루어집니다. 대규모 업데이트의 경우에도 인덱스 스캔과 업데이트가 진행되는 동안 스캔 중인 인덱스에 대한 업데이트가 완료될 수 있습니다.
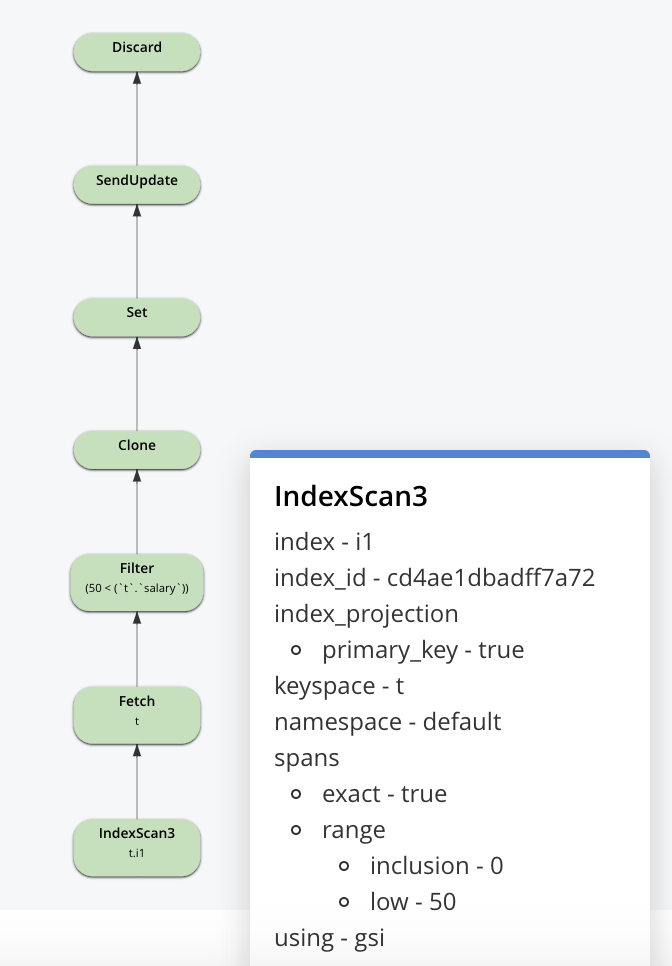
이제 인덱스 스캔 자체에 대해 살펴보겠습니다. 인덱스는 메모리 최적화 인덱스(MOI) 또는 표준 보조(플라즈마 스토리지 엔진 사용)를 기반으로 구축할 수 있습니다. 이 두 가지 모두 스냅샷이라는 개념이 있습니다. 값을 제자리에서 업데이트하는 대신, 필요한 기능과 성능을 제공하기 위해 MVCC를 사용합니다.
다음은 Nitro 종이.
변경 불가능한 스냅샷: 동시 작성자는 건너뛰기 목록에 항목을 추가하거나 제거합니다. 현재 항목의 스냅샷을 만들어 건너뛰기 목록의 특정 시점 보기를 제공할 수 있습니다. 이는 반복 가능한 안정적인 스캔을 제공하는 데 유용합니다. 사용자는 여러 개의 스냅샷을 만들고 관리할 수 있습니다. 애플리케이션에서 건너뛰기 목록 작업 일괄 처리에 원자성이 필요한 경우, 작업 일괄 처리를 적용하고 새 스냅샷을 만들 수 있습니다. 새 스냅샷이 생성될 때까지는 변경 사항이 보이지 않습니다.
빠르고 오버헤드가 적은 스냅샷: 스킵리스트의 리더는 스냅샷 핸들을 사용하여 모든 조회 및 범위 쿼리를 수행합니다. 인덱서 애플리케이션은 일반적으로 인덱스 쿼리를 서비스하기 위해 매초마다 많은 스냅샷을 생성해야 합니다. 따라서 높은 스냅샷 생성 속도를 서비스하기 위해서는 스냅샷 생성 및 유지 관리의 오버헤드가 최소화되어야 합니다. Nitro 스냅샷은 매우 저렴하며 O(1) 연산입니다.
이를 구현하기 위해 인덱스는 두 가지를 사용합니다: 본스냅샷 버전과 데드스냅샷 버전입니다. 초기 인덱스의 상태를 살펴보겠습니다.
 값이 변경되면 업데이트된 값, 태어난 스냅샷 및 죽은 스냅샷 값으로 스킵리스트에 새 노드를 추가하기만 하면 됩니다.
값이 변경되면 업데이트된 값, 태어난 스냅샷 및 죽은 스냅샷 값으로 스킵리스트에 새 노드를 추가하기만 하면 됩니다.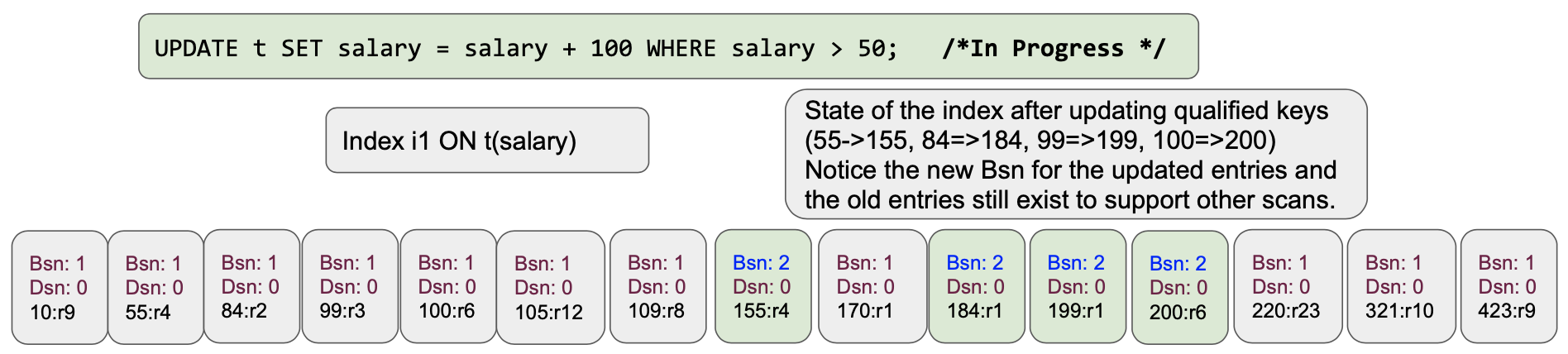
인덱스 스캐너(일명 반복기)는 항목의 bornSnapshot 및 deadSnapshot 버전을 사용하여 읽을 인덱스 항목의 자격을 부여할 올바른 항목을 선택하기만 하면 됩니다. 이렇게 해서 스냅샷을 생성하고 동일한 스캔에서 이전에 업데이트된 값을 읽지 않습니다. 이렇게 하면 안정적인 스캔을 제공할 뿐만 아니라 할로윈 문제도 완전히 방지할 수 있습니다! 또한 쿼리 서비스 내에서 업데이트된 문서 ID 목록을 유지 관리할 필요도 없습니다. 좋은 엔지니어링은 문제를 해결하고, 훌륭한 엔지니어링은 문제를 완전히 피합니다. :-)
마지막으로, 할로윈 아트는 데이비드 하이크니카우치베이스 고객 지원 담당 부사장! 전체 동영상을 시청하세요!
모두에게 행복한 할로윈@couchbase! 🎃 pic.twitter.com/vqwW7sk3v6
- 데이비드 하이크니 (@dhaikney) 2020년 10월 31일
참조
- 할로윈 문제
- 선의의 쿼리와 할로윈 문제, 로스 알라모스 국립 연구소, 일화, IEEE 컴퓨팅 역사 연대기
- 카우치베이스 글로벌 보조 인덱스
- Nitro: NoSQL 글로벌 보조 인덱스를 위한 빠르고 확장 가능한 인메모리 스토리지 엔진