벡터란 무엇인가요?
벡터는 현실 세계의 아이템을 부동 소수점 배열.
현실 세계의 각 항목은 벡터 형식(배열)으로 표현되며, 그 특성에 따라 객체와 연관된 여러 차원(속성)이 있습니다.
예를 들어 색상을 벡터 형식으로 표현하려면 속성 값의 배열을 만들면 됩니다. 예시 [ "R","G","B"]
RGB 이미지의 각 색상은 빨간색, 녹색, 파란색 빛의 양이라는 세 가지 값으로 표현됩니다. 이 값은 일반적으로 0에서 255까지의 범위로 각 색상 구성 요소의 강도를 나타냅니다.
순수한 빨간색= [ "255","0","0"]
Where:
-
- R은 빨간색의 강도를 나타냅니다(이 경우 최대 강도, 255),
- G는 녹색의 강도를 나타냅니다(이 경우 0이므로 녹색이 없음),
- B는 파란색의 강도를 나타냅니다(이 경우 0이므로 파란색이 없음).
마찬가지로, 각 색상 채널에 대해 0에서 255까지의 값을 사용하여 이 RGB 벡터 형식을 사용하여 모든 색상을 표현할 수 있습니다.
빨간색과 가까운 일치 항목을 찾으려면 색상의 첫 번째 속성 값을 기준으로 찾을 수 있습니다.
실제 오브젝트에는 표현해야 하는 다른 많은 속성이 있을 수 있으므로 실제 오브젝트를 나타내는 벡터는 512, 1028, 1536 또는 2048 속성 값의 큰 배열로 표현됩니다.
벡터 검색이란 무엇인가요?
벡터 검색은 항목의 벡터 표현을 기반으로 항목을 찾는 방법입니다. 벡터 검색에서 각 항목은 다차원 공간으로 표현되며, 각 차원은 항목의 속성 값을 나타냅니다.
자세한 내용은 여기에서 확인할 수 있습니다:
산업 전반의 사용 사례
벡터 검색은 산업 전반에 걸쳐 다양한 사용 사례에 사용될 수 있으며, 그 중 몇 가지를 소개합니다:
-
- 콘텐츠 생성
- 이상 징후 탐지
- 하이브리드 검색
- AI 기반 챗봇.
벡터 검색과 전체 텍스트 검색?
벡터 검색과 전체 텍스트 검색은 모두 데이터 컬렉션을 검색하는 데 사용되는 방법이지만, 작동 방식이 다르고 데이터 유형과 사용 사례에 따라 적합합니다.
전체 텍스트 검색: 은 정보 검색에서 문서나 데이터베이스 내의 텍스트 콘텐츠를 검색하고 분석하는 데 사용되는 기술입니다. 정확한 구문이나 키워드를 일치시키는 기존의 검색 방법과 달리, 전체 텍스트 검색 엔진은 문서나 레코드의 콘텐츠를 분석하여 단어의 의미와 문맥에 따라 검색 쿼리를 일치시킵니다..
| 비교 영역 | 전체 텍스트 검색 | 벡터 검색 | |
| 1 | 데이터 표현 | 데이터는 텍스트 또는 문자열 문서로 표시됩니다. | 데이터는 다차원 공간에서 벡터로 표현됩니다. |
| 2 | 매칭 기준 | 정확하거나 흐릿한 일치 | 가장 가까운 이웃 경기 |
| 3 | 검색 | 텍스트 검색 또는 비교 | 개체의 속성을 기반으로 한 문맥 검색 또는 비교. |
| 4 | 사용 사례 | 문서, 웹 페이지, 이메일 콘텐츠 등을 검색합니다. | 오디오, 비디오, 이미지, 텍스트 등을 검색합니다. |
왜 벡터 검색을 위한 카우치베이스인가요?
-
- 제품 전반의 벡터: 업계 최초로 클라우드, 온프레미스, 모바일의 3가지 배포를 모두 지원한다고 발표했습니다.
- 광범위한 기능: 캐시, 전체 텍스트 검색, 분석 검색, 시계열, 키-값, 이벤트 및 기타 기능을 벡터 검색과 함께 단일 플랫폼에 통합했습니다.
- 에코시스템 통합: LangChain 그리고 LlamaIndex 통합.
- 검증된 속도와 유연성: 인메모리 아키텍처, 유연한 json 형식 및 파워풀한 인덱싱.
자세한 내용은 벡터 검색 릴리스 발표.
전제 조건
- 카우치베이스 카펠라 또는 카우치베이스 서버 7.6 EE
- 이미 데이터베이스를 만들었습니다.
- 샘플 데이터:
- 파일 다운로드 color_data_2vectors.zip
- 이 예제에서는 rgb.json 파일
- 색인 파일: color-index.json
- color-index.json:
123456789101112131415161718192021222324252627282930313233343536373839404142434445464748495051525354555657585960616263646566676869707172737475767778798081828384858687888990919293949596979899100101102103104105106107108109110111112113114115116117118119120121122123124{"type": "fulltext-index","name": "color-index","sourceType": "gocbcore","sourceName": "vector-sample","sourceUUID": "789365cccdf940ee2814a5dd2752040a","planParams": {"maxPartitionsPerPIndex": 512,"indexPartitions": 1},"params": {"doc_config": {"docid_prefix_delim": "","docid_regexp": "","mode": "scope.collection.type_field","type_field": "type"},"mapping": {"analysis": {},"default_analyzer": "standard","default_datetime_parser": "dateTimeOptional","default_field": "_all","default_mapping": {"dynamic": false,"enabled": false},"default_type": "_default","docvalues_dynamic": false,"index_dynamic": false,"store_dynamic": false,"type_field": "_type","types": {"color.rgb": {"dynamic": false,"enabled": true,"properties": {"brightness": {"dynamic": false,"enabled": true,"fields": [{"index": true,"name": "brightness","store": true,"type": "number"}]},"color": {"dynamic": false,"enabled": true,"fields": [{"analyzer": "en","index": true,"name": "color","store": true,"type": "text"}]},"colorvect_dot": {"dynamic": false,"enabled": true,"fields": [{"dims": 3,"index": true,"name": "colorvect_dot","similarity": "dot_product","type": "vector"}]},"colorvect_l2": {"dynamic": false,"enabled": true,"fields": [{"dims": 3,"index": true,"name": "colorvect_l2","similarity": "l2_norm","type": "vector"}]},"description": {"dynamic": false,"enabled": true,"fields": [{"analyzer": "en","index": true,"name": "description","store": true,"type": "text"}]},"embedding_vector_dot": {"dynamic": false,"enabled": true,"fields": [{"dims": 1536,"index": true,"name": "embedding_vector_dot","similarity": "dot_product","type": "vector"}]}}}}},"store": {"indexType": "scorch","segmentVersion": 16}},"sourceParams": {}}
- color-index.json:
- 샘플 검색 정의:
{ "fields": ["*"], "쿼리": { "match_none": "" }, "knn": [ { "k": 2, "field": "colorvect_l2", "vector": [ 0, 0, 128 ] } ] }
단계
샘플 데이터 만들기
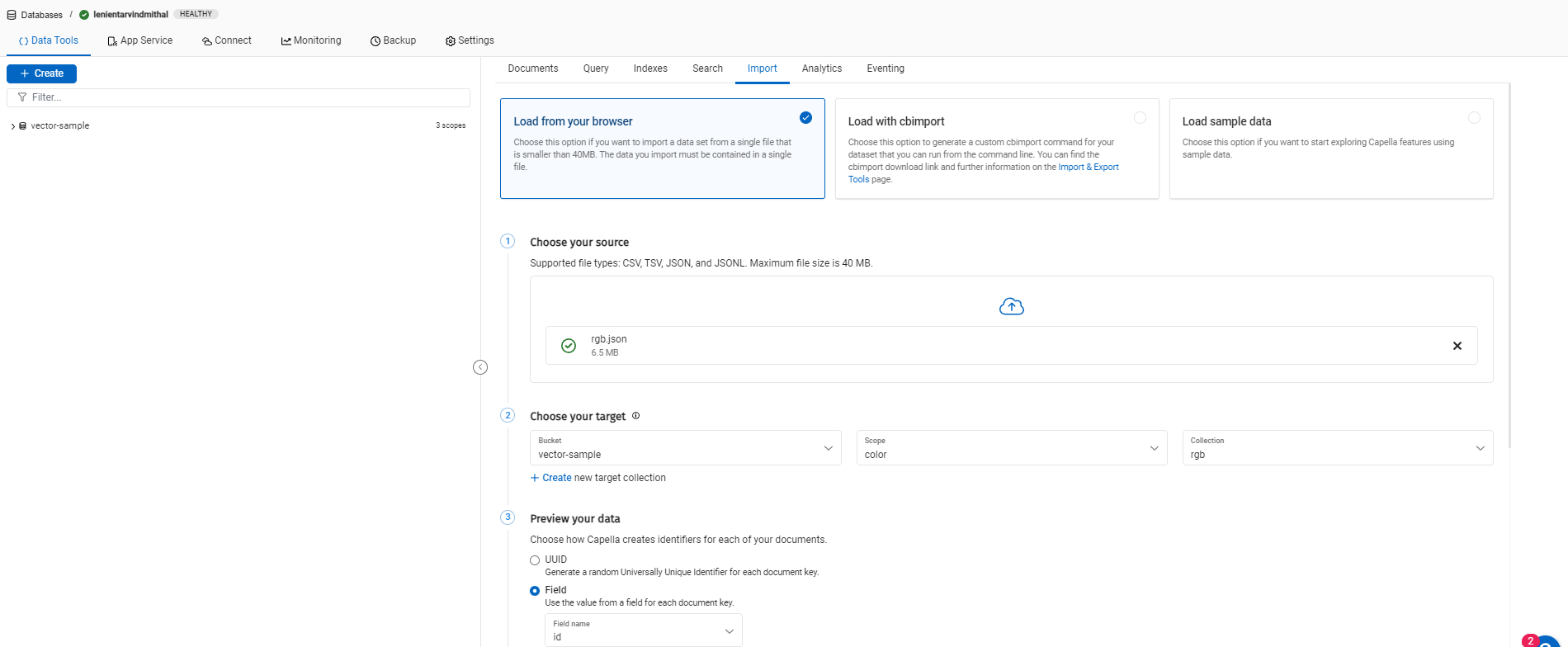
오픈 카펠라 UI, 다음으로 이동 데이터베이스를 클릭하고 데이터 도구를 사용하여 브라우저에서 가져오기를 사용하여 데이터 가져오기를 시작합니다:
-
- 필수 구성 요소에 제공된 샘플 rgb.json 데이터 파일을 사용합니다.
- 옵션 선택 브라우저에서 로드.
- 파일을 선택합니다: rgb.json
- 새 버킷에 이름을 지정합니다: 벡터 샘플
- 이름으로 새 범위를 지정합니다: 색상
- 이름으로 새 컬렉션을 지정합니다: rgb
- 3단계에서 미리 보기 데이터,
Capella가 각 문서에 식별자를 생성하는 방법을 선택합니다. 필드 옵션을 선택하고 필드를 지정합니다: Id 아래 스크린샷과 같이 식별됩니다. - 가져오기를 클릭합니다.


벡터 검색 색인 생성
아래의 검색 옵션에서 데이터 도구:
-
- 검색 색인 만들기

- 선택 고급 모드
- 를 클릭합니다. 색인 정의 UI 오른쪽에 있는
- 옵션 선택 파일에서 가져오기
- 파일 선택 color-index.json 전제 조건에 지정된
- 인덱스 이름을 다음과 같이 지정합니다: color-index.json
- 버킷을 선택합니다: 벡터 샘플
- 범위는 다음과 같이 자동으로 채워집니다. 색상
- 를 클릭합니다. 색인 만들기
- 검색 색인 만들기


벡터 검색 수행
를 선택하고 검색 옵션의 색상 색인 행(맨 오른쪽 근처 버튼)
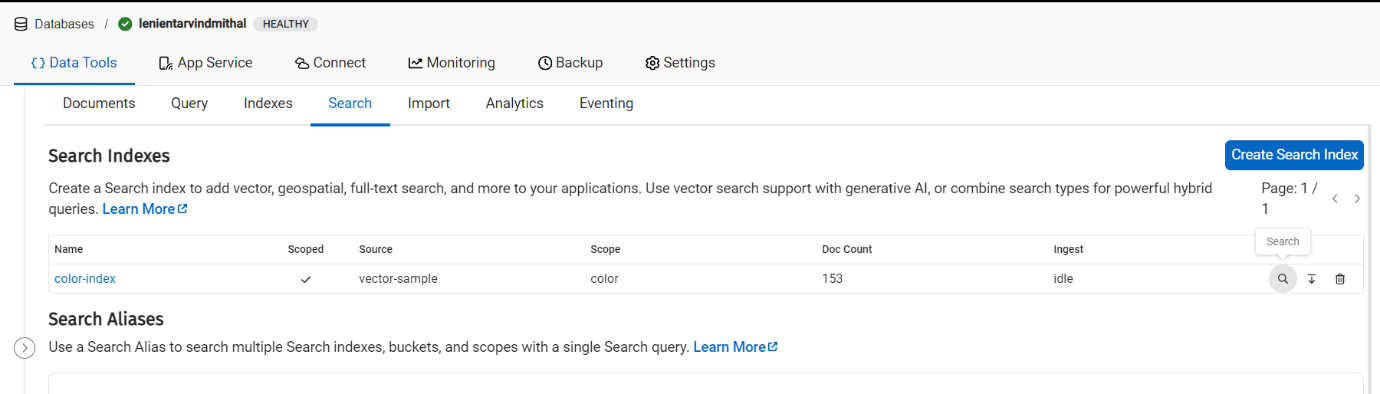
전제 조건 단계의 검색 텍스트를 검색 창에 붙여넣습니다.
를 클릭합니다. 검색 를 클릭하여 결과를 얻습니다(검색 텍스트 아래 창에 표시됨).

결론
이 게시물에서는 벡터 검색이 무엇인지, 그리고 Couchbase를 사용하여 벡터 검색을 빠르게 시작하는 방법에 대한 기본 사항을 살펴봤습니다.
기본 벡터 검색을 실행한 후에는 Couchbase에서 SQL 쿼리와 벡터 검색을 쉽게 결합하여 데이터베이스 스택을 통합하고 애플리케이션에 의미 있는 단일 결과를 얻기 위해 여러 쿼리를 작성하지 않도록 할 수 있습니다.
무료로 시작하기
-
- 시작하기 카펠라 30일 평가판 계정 를 클릭해 오늘 첫 실험을 실행하세요!
참조
