의 개발자 옹호자로서 카우치베이스저는 종종 여행을 다니면서 NoSQL이 무엇인지, 더 중요한 것은 Couchbase가 무엇인지 모르는 사람들을 만나곤 합니다. 이미 NoSQL에 익숙한 사람들에게 Couchbase는 종종 다른 솔루션과 비교되기도 합니다. NoSQL 데이터베이스 MongoDB 및 CouchDB와 같은 제품은 모두 Couchbase와 관련이 없습니다.
최근에 커뮤니티 작성자 Milan Milosevic이 작성한 MongoDB와 Couchbase 비교 시리즈를 보게 되었습니다. In 파트 1 그리고 파트 2 시리즈에서 그는 숙련된 MongoDB 개발자 출신으로 Couchbase를 사용하기까지 자신의 경험을 설명합니다. 타당한 의견이 공유되지만 간과할 수 있는 몇 가지 사항이 있습니다.
Couchbase가 NoSQL 분야에서 훌륭한 옵션이 되는 이유에 대한 몇 가지 우려를 해소하고 싶습니다.
버킷과 JSON 문서
Couchbase에서 데이터로 작업할 때는 JSON 형식의 데이터로 작업하게 됩니다. 이 JSON 데이터는 원하는 만큼 단순하거나 복잡하게 만들 수 있습니다. 예를 들어 다음은 매우 유효한 JSON 문서입니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
{ "이름": "Nic", "성": "라보이", "주소": [ { "city": "샌프란시스코", "state": "캘리포니아" }, { "city": "마운틴 뷰", "state": "캘리포니아" } ], "소셜": { "twitter": "https://www.twitter.com/nraboy", "blog": "https://www.thepolyglotdeveloper.com" } } |
위 문서에서 중첩된 객체뿐만 아니라 중첩된 객체 배열이 있는 것을 보셨나요? JSON 문서로 작업하면 관계형 데이터베이스에서보다 데이터에 대해 더 많은 유연성을 확보할 수 있습니다.
Couchbase에 저장된 각 JSON 문서에는 키라고도 하는 고유한 ID 값을 부여해야 합니다. Couchbase에서 이 키를 생성하지는 않지만 키 설계와 관련하여 사용할 수 있는 솔루션이 많이 있습니다. 예를 들어 다음은 키를 디자인하는 세 가지 가능한 방법입니다:
사람이 읽을 수 있는
|
1 |
nraboy |
컴퓨터 생성 또는 증가
|
1 |
caa80375-77e7-4714-b90a-1089e66a5fd5 |
조합 또는 복합
|
1 |
nraboy::1 |
키를 만드는 데 있어 옳고 그른 방법은 없습니다. 저장하려는 특정 문서에 필요한 것이 무엇인지에 따라 달라집니다. 나만의 키를 디자인할 수 있으면 데이터 관계를 설정하고 해당 데이터를 쿼리할 때 유용합니다.
고유 키가 있는 각 JSON 문서는 Couchbase 버킷이라고 하는 곳에 저장됩니다. 버킷은 말 그대로 물건을 저장할 수 있는 양동이처럼 생각하면 안전할 것입니다. 이 버킷에는 모양이나 크기에 상관없이 무엇이든 넣을 수 있습니다. 카우치베이스 버킷도 마찬가지입니다. 예를 들어 다음 두 개의 문서를 저장하고 싶다고 가정해 보겠습니다:
|
1 2 3 4 5 |
{ "type": "사람", "이름": "Nic", "성": "라보이" } |
위의 문서에 어떤 고유 키를 부여해도 상관없지만 이 예제에서는 중요하지 않습니다. 다음 문서에도 동일한 규칙이 적용됩니다:
|
1 2 3 4 5 |
{ "type": "위치", "city": "샌프란시스코", "state": "캘리포니아" } |
두 문서에서 각각 다음과 같은 유형 속성을 다른 값으로 설정할 수 있습니다. 또한 서로 속성 이름이 완전히 다르므로 이 문서들이 서로 다른 목적을 해결한다는 것을 나타냅니다. 완전히 필요한 것은 아니지만 유형 속성은 이러한 문서를 쿼리할 때 도움이 됩니다.
하나의 버킷에 문서 유형이 많으면 일이 더 복잡해지거나 지저분해지나요? 문서가 저장되는 방식이 아니라 쿼리가 중요하기 때문에 절대 그렇지 않습니다.
MongoDB의 경우 각 문서 유형을 자체 컬렉션에 저장하고, RDBMS의 경우 마찬가지로 각 문서 유형을 자체 테이블에 저장합니다. 그렇다면 MongoDB와 Oracle과 같은 관계형 데이터베이스가 Couchbase보다 잘못하고 있거나 더 낫다는 뜻인가요? 아니요, 단지 문제를 해결하는 방식이 다를 뿐입니다.
카우치베이스 셸(CBQ) 및 쿼리 워크벤치
따라서 Couchbase의 JSON 데이터를 사용하려면 데이터를 쿼리하거나 더 많이 만들어야 할 필요가 있습니다. Couchbase에서 여러 가지 도구를 사용하여 데이터를 쿼리하는 방법에는 여러 가지가 있습니다.
카우치베이스 엔터프라이즈 에디션 및 커뮤니티 에디션에는 다음과 같은 기능이 있습니다. 쿼리 워크벤치쿼리 실행을 위한 그래픽 도구로, phpMyAdmin이나 Oracle의 SQL Developer에서 볼 수 있는 것과 유사합니다.
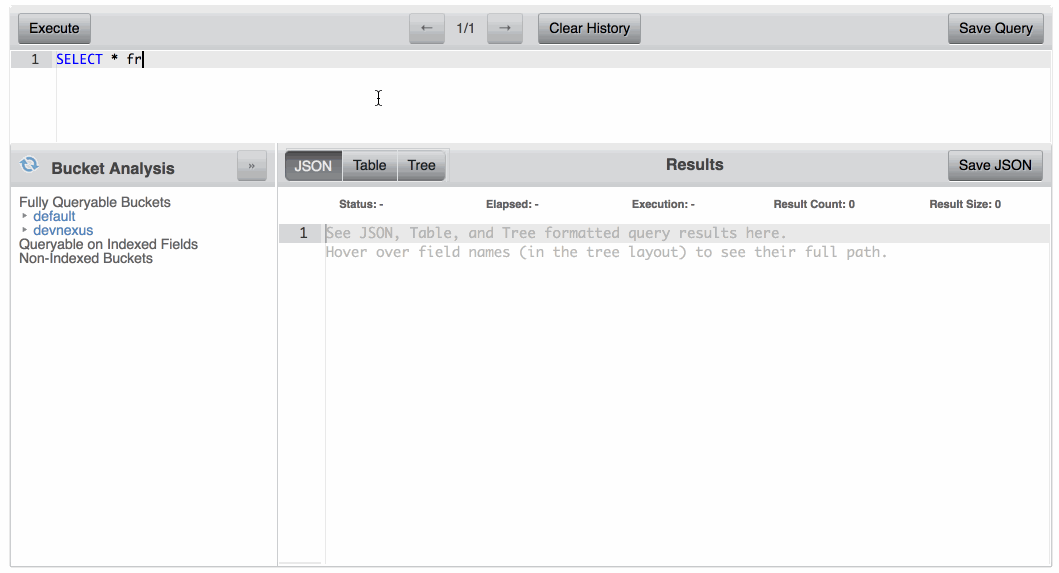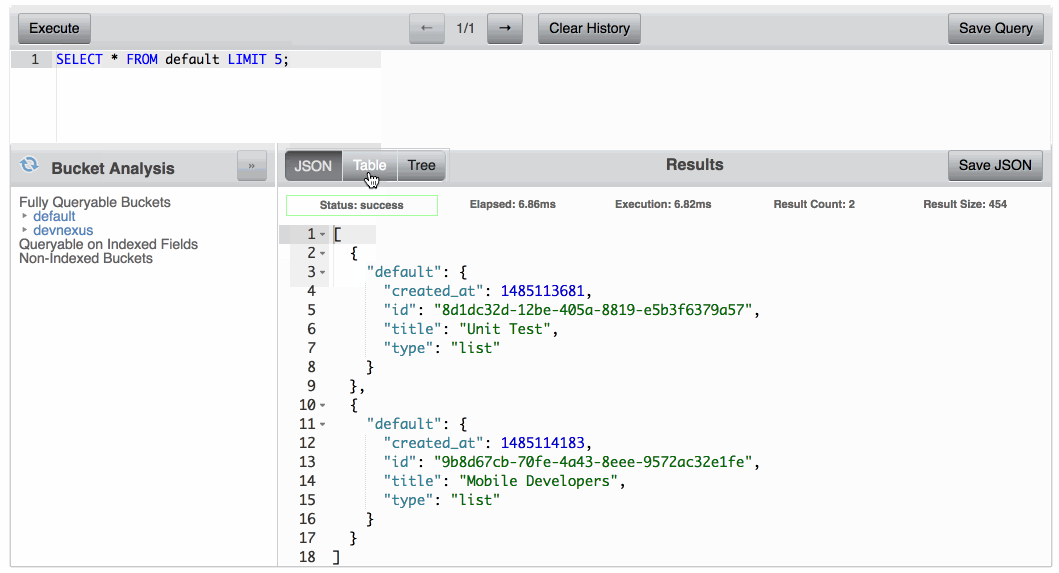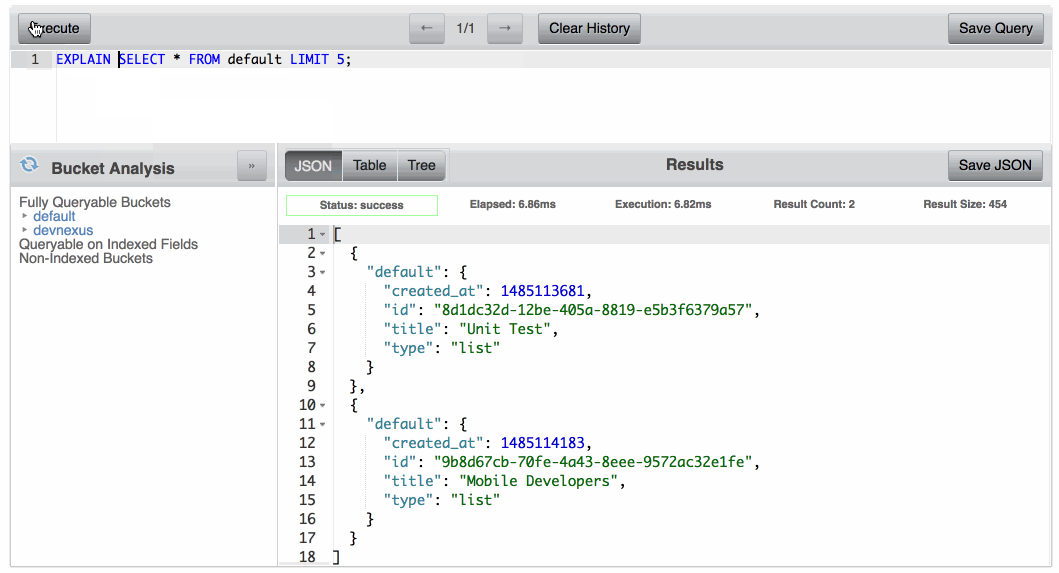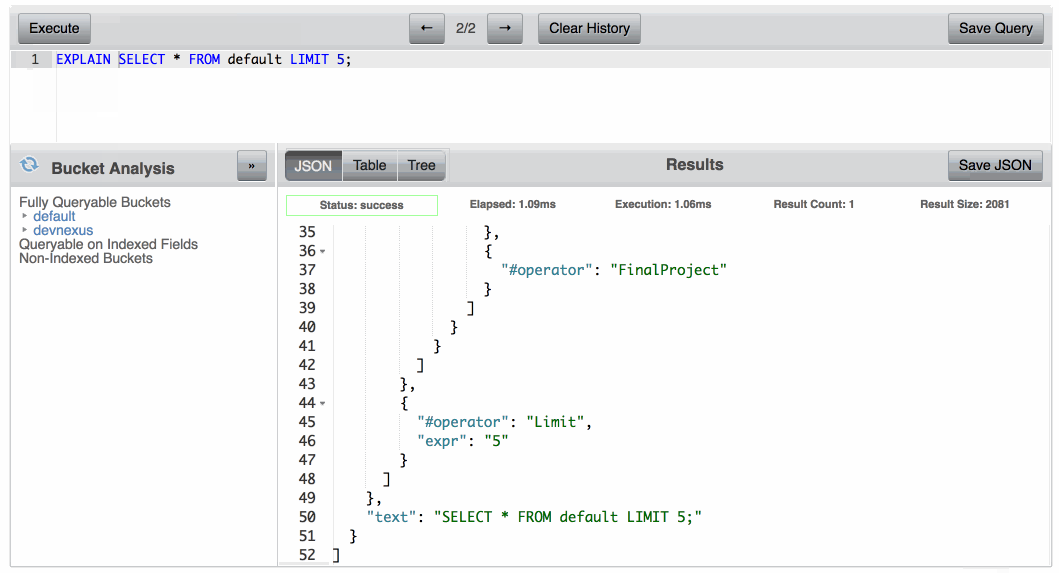
쿼리 워크벤치를 사용하면 각 버킷에 있는 문서에 대해 Couchbase N1QL 쿼리를 실행할 수 있습니다. 이러한 쿼리에는 다음이 포함될 수 있습니다. 선택, 삽입또는 SQL 기반 언어에서 널리 사용되는 다른 쿼리 명령을 사용할 수 있습니다. 예를 들어, 다음 쿼리는 Couchbase 버킷에 있는 모든 문서의 모든 속성을 반환합니다. 기본값:
|
1 |
선택 * FROM 기본값; |
모든 NoSQL 기술에는 데이터를 쿼리하는 고유한 방법이 있지만, N1QL은 사용하기 쉬울 뿐만 아니라 이미 SQL 경험이 있는 관계형 데이터베이스에서 벗어나고자 하는 사용자에게 더 편리합니다.
그렇다면 셸 클라이언트를 사용하는 것을 선호하는 개발자는 어떻게 해야 할까요? 바로 이 부분에서 Couchbase Shell(CBQ)이 등장합니다.
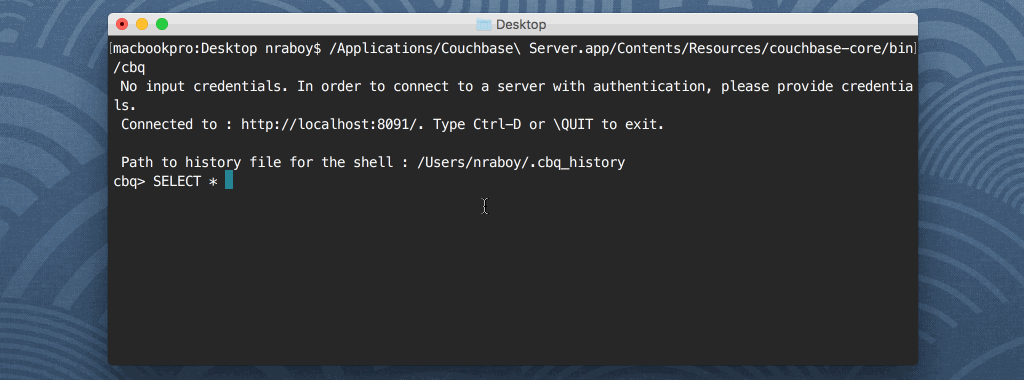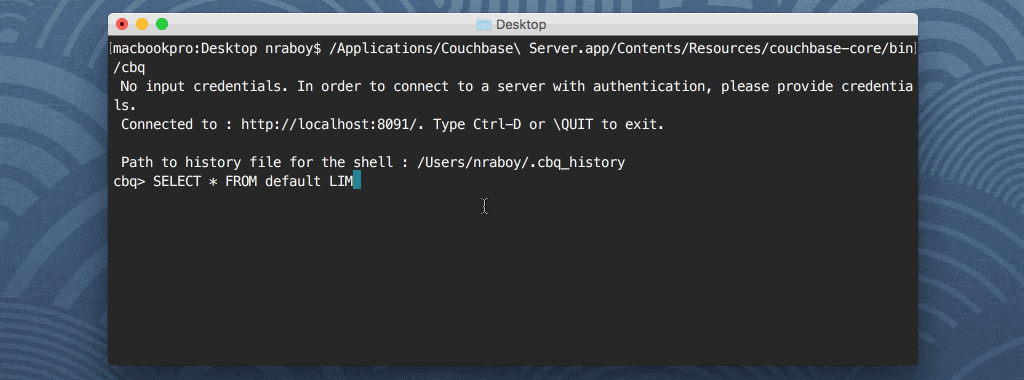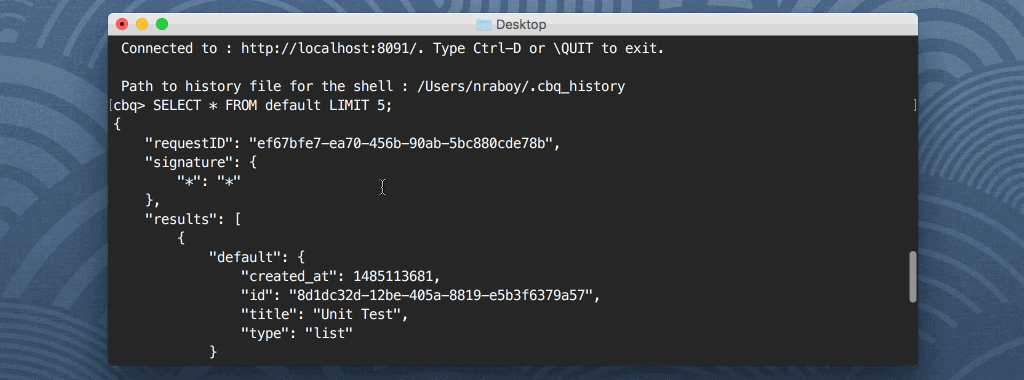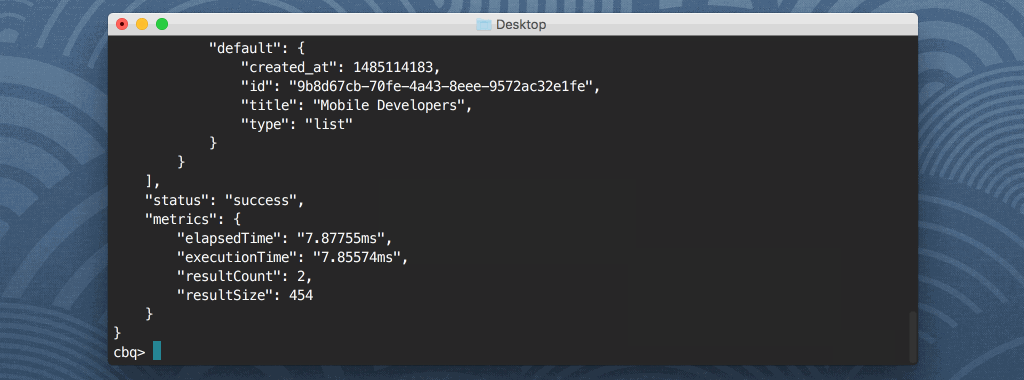
셸 클라이언트는 몽고DB나 다른 관계형 데이터베이스 기술에서 볼 수 있는 것과 비슷합니다. 쿼리 결과를 셸에 표시하지 않고 파일에 저장하려면 어떻게 해야 할까요? 다음과 같이 할 수 있습니다:
|
1 |
echo "SELECT * FROM default;" | /애플리케이션/카우치베이스 서버.앱/콘텐츠/리소스/카우치베이스-핵심/bin/cbq -u 관리자 -p 비밀번호 -o ~/데스크톱/출력.txt |
CBQ는 쿼리 실행에만 국한되지 않습니다. 연결 및 보안 관리 기능도 사용할 수 있습니다. 전체 기능 세트는 문서 뿐만 아니라 이 블로그 게시물 이전에 글을 쓴 적이 있습니다.
쿼리 워크벤치와 CBQ는 모두 목적이 있지만 대부분의 경우 다음 중 하나를 사용하여 문서를 쿼리하게 됩니다. 개발자 SDK 을 사용할 수 있습니다. Java, .NET, Node.js, Golang 등 널리 사용되는 개발자 기술을 위한 언어 지원이 제공되므로 애플리케이션 내에서 NoSQL을 사용하는 데 문제가 없습니다.
카우치베이스 서버에서 인덱싱
Couchbase를 쿼리하려면 Couchbase 클러스터 내에 인덱스를 만들어야 합니다. 만들 수 있는 인덱스에는 몇 가지 유형이 있으며, 애플리케이션 요구 사항에 따라 만들어집니다.
로컬 인덱스를 예로 들어보겠습니다. 클러스터에 로컬 인덱스가 생성되면 각 노드는 로컬로 보유하고 있는 데이터를 인덱싱합니다. 이것은 단일 노드 배포에서는 잘 작동하는 솔루션이지만, 클러스터의 노드 수가 증가하기 시작하면 쿼리 대기 시간이 길어지기 시작합니다. 이는 데이터를 클라이언트에 반환하기 전에 사용 가능한 노드 간에 분산 수집이 이루어져야 하기 때문입니다.
다중 노드 클러스터를 생성할 때는 글로벌 보조 인덱스(GSI)를 사용하는 것이 더 합리적입니다. 이 시나리오에서는 인덱스가 데이터 노드에서 멀리 떨어져 배치되고 더 적은 수량이 존재합니다. 각 로컬 인덱스에서 분산 수집을 사용하는 대신, 쿼리는 원하는 데이터를 알고 있는 글로벌 인덱스에 대해 수행한 다음 이를 반환합니다. 이렇게 하면 쿼리 대기 시간이 크게 개선됩니다.
그렇다면 클러스터에서 글로벌 보조 인덱스를 어떻게 생성할 수 있을까요? 다음과 같이 실행해 보세요:
|
1 |
만들기 INDEX 사람들 켜기 기본값(이름, 성) 어디 유형 = "사람" 사용 GSI; |
로컬 인덱스와 글로벌 보조 인덱스 모두 다음에서 읽을 수 있습니다. 블로그의 멋진 게시물.
이제 Couchbase의 새로운 인덱싱 기능 중 하나를 소개합니다. Couchbase 4.5부터 메모리 최적화된 글로벌 보조 인덱스(MOI)라는 것이 있습니다.
이제 인덱스가 디스크에 존재하고 디스크 속도로 실행되는 대신 훨씬 더 빠른 성능으로 메모리에 존재할 수 있습니다. 메모리 최적화 인덱스에 대한 자세한 내용은 다음에서 확인할 수 있습니다. 이 블로그 게시물.
그렇다면 쿼리가 어떤 인덱스를 사용하고 있는지 어떻게 알 수 있을까요? 쿼리에서 설명 를 입력하세요:
|
1 |
설명 선택 이름, 성 FROM 기본값 어디 유형 = "사람"; |
결과는 설명 는 쿼리가 사용한 인덱스와 프로세스에서 수행된 작업에 대한 다양한 메트릭 정보를 알려줍니다. 이 쿼리에 대해 생성한 인덱스를 사용하는 경우에는 설명 를 사용한다고 말해야 합니다. 사람들 색인.
강력한 고객 지원으로 프로덕션 준비 완료
카우치베이스 커뮤니티와 엔터프라이즈 에디션은 모두 프로덕션에 사용할 수 있으며 잘 알려진 조직에서 활발하게 사용되고 있습니다. 이름을 알릴 준비를 하세요.
LinkedIn, PayPal, eBay, United, Marriott, GE, Verizon과 같은 거대하고 존경받는 기업들이 조직의 데이터 계층을 강화하기 위해 수천 개의 Couchbase 노드를 사용하고 있습니다. 이러한 회사 중 일부는 Couchbase Connect에서 연설했으며, 녹화된 내용은 다음을 통해 시청할 수 있습니다. YouTube.
더 많은 Couchbase 고객 목록을 보려면 다음 목록을 확인하세요. 여기.
결론
Couchbase는 프로덕션에 바로 사용할 수 있는 풍부한 기능을 갖춘 NoSQL 문서 데이터베이스입니다. 유연한 JSON 데이터 모델과 고급 쿼리 및 도구 기능을 사용할 수 있는 Couchbase는 거의 모든 시나리오에 완벽한 데이터베이스가 될 수 있습니다.
카우치베이스 사용에 대한 자세한 내용은 다음을 참조하세요. 카우치베이스 개발자 포털 를 클릭해 튜토리얼 및 기타 문서를 확인하세요.