이 블로그 게시물에서는 다음에서 전체 텍스트 검색을 위한 미리보기 API를 살펴보겠습니다. Couchbase 4.5. 이 API는 최신 버전인 Java SDK (2.2.4), 여전히 실험적.
자세히 알아보겠습니다:
이 실험용 API는 Couchbase Server 4.5 개발자 프리뷰에서 사용할 수 있습니다. 2.2.4 Maven을 통해 얻을 수 있는 Java SDK 클라이언트입니다. 다음 종속성을 pom.xml:
|
1 2 3 4 5 |
com.카우치베이스.클라이언트 자바-클라이언트 2.2.4 |
카우치베이스에서 전체 텍스트 검색을 하시나요?
예! 곧 출시될 4.5 서버 릴리스(코드명 왓슨)에는 오픈 소스 기반의 전체 텍스트 인덱서(FTS, CBFT라고도 함)가 포함됩니다. Bleve 프로젝트입니다. Bleve는 Go의 전체 텍스트 검색과 인덱싱에 관한 것입니다. 마티 쇼흐 이 프로젝트를 시작하기 위해).
이 아이디어는 외부 소프트웨어(자체 클러스터에서 실행되는)에 대한 커넥터를 사용할 필요 없이 Bleve를 활용하여 Couchbase Server에서 기성품 전체 텍스트 검색을 제공하는 것입니다. 물론 이러한 상용 솔루션이 사용자의 요구 사항을 완전히 충족시키지 못하는 경우에도 다음을 사용할 수 있습니다. 커넥터하지만 간단한 요구사항은 단일 솔루션을 사용하는 것이 좋습니다.
FTS는 Bleve에서 제공하는 다양한 기능을 제공합니다: 텍스트 분석기, 토큰화기 및 이 글의 범위를 벗어나는 후처리 토큰 필터뿐만 아니라 다양한 유형의 쿼리 를 사용하여 결과 인덱스에서 실행할 수 있습니다. 이러한 유형이 무엇이며 Java SDK의 컨텍스트에서 어떻게 사용할 수 있는지 살펴 보겠습니다.
이 블로그 게시물의 나머지 부분에서는 곧 출시될 4.5 개발자 프리뷰에서 웹 관리 콘솔을 통해 구축할 수 있는 3개의 인덱스를 사용하겠습니다:

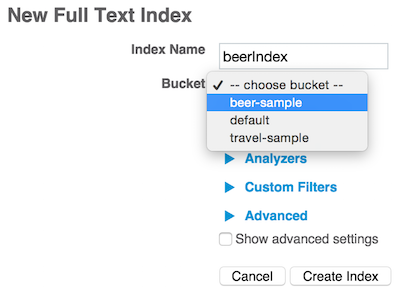
다음은 UI의 인덱스 목록입니다:
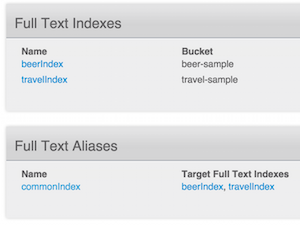
그렇습니다:
- a
맥주 인덱스에 있는 각 문서의 전체 콘텐츠를 색인화합니다.맥주 샘플버킷. - a
여행 인덱스에 있는 각 문서의 전체 콘텐츠를 색인화합니다.여행 샘플버킷. - 별칭 인덱스입니다,
commonIndex는 위의 두 인덱스가 합쳐진 값입니다.
Java API
Java SDK에서 전체 텍스트 검색 기능의 진입점은 버킷를 사용하여 쿼리(검색 쿼리 ftq) 메서드를 사용할 수 있습니다. 이는 API에 이미 존재하는 기존 쿼리 메서드와 일치합니다. ViewQuery 또는 N1qlQuery.
전체 텍스트 검색을 위한 API는 빌더 패턴을 사용합니다. 원하는 쿼리 유형을 식별하고 해당 빌더를 사용하여 쿼리를 구성하고, 해당 쿼리에서 검색 쿼리 를 사용하여 build() 를 사용하여 실행합니다. 버킷 쿼리(검색 쿼리).
(아주 간단한) 예를 들어 어떻게 소비될 수 있는지 살펴봅시다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
//이 클러스터와 버킷을 나머지 예제에서 사용하겠습니다. 클러스터 클러스터 = 카우치베이스클러스터.create("127.0.0.1"); 버킷 버킷 = 클러스터.오픈버킷("맥주 샘플"); //우리는 간단한 형태의 쿼리를 사용합니다: 검색 쿼리 ftq = 매치 쿼리.on("beerIndex").일치("national").limit(3).빌드(); //쿼리를 실행하고 결과를 확인합니다. 검색 쿼리 결과 결과 = 버킷.쿼리(ftq); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { 시스템.out.println(행); } |
각 섹션을 개별적으로 살펴보면 다음과 같습니다:
- 간단한
매치 쿼리한 번만 사용하세요. - 맥주 샘플에서 실행됩니다(
.on(beerIndex), "national"이라는 단어의 텍스트 발생을 찾습니다(.query("national")) 또는 종료 조건. - 결과 수를 3개로 제한하기 위해 추가 구성이 수행됩니다(
limit(3)) 및 실제 쿼리는 이 시점에서 생성됩니다(.build()). - 쿼리가 실행됩니다(
bucket.query(ftq))를 반환하고검색 쿼리 결과. - 결과는 다음과 같이 출력됩니다.
totalHits()및 개별 행(를 통해 목록으로 액세스할 수도 있습니다.hits()).
해당 코드를 실행하면 출력됩니다:
|
1 2 3 4 |
총 조회수: 31 검색 쿼리 히트{id='dc_brau', 점수=0.09068310490562362, 조각={}} 검색 쿼리 히트{id='브로워리_나시오날_발라시', 점수=0.12085760187148556, 조각={}} 검색 쿼리 히트{id='cervecera_nacional', 점수=0.09863195902067363, 조각={}} |
총 조회수는 제한이 적용되기 전의 실제 조회수입니다. 그리고 hits() 메서드는 3을 반환합니다. 검색 쿼리 행 객체를 요청에 따라 추가합니다.
각 히트에는 Couchbase에서 연결된 문서의 키가 포함되어 있습니다(id()), 매칭에 대한 자세한 정보(예: 매칭 점수(점수())... 원하는 경우 다음을 사용하여 관련 문서를 검색할 수 있습니다. bucket.get(row.id()):
|
1 2 3 4 5 6 |
결과 = 버킷.쿼리(ftq); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { 시스템.out.println(행); 시스템.out.println(버킷.get(행.id()).콘텐츠()); } |
이렇게 하면 첫 번째 히트작이 나옵니다:
|
1 2 3 |
검색 쿼리 히트{id='dc_brau', 점수=0.09068310490562362, 조각={}} {"country":"미국","웹사이트":"http://www.dcbrau.com/","code":"20018","주소":["3178-B 블라덴스버그 로드 NE"],"city":"워싱턴","전화":"","name":"DC Brau", "설명":"금주령 이후 미국 수도에 문을 연 최초의 양조장.","state":"DC","type":"양조장","업데이트됨":"2011-08-08 19:02:40"} |
문서의 JSON을 자세히 살펴보면 문서가 일치하는 부분을 확인할 수 있습니다. "설명' 필드에 이 문장이 있습니다:
최초의 양조장 오픈 국가금지령 이후 수도로 지정되었습니다.
또한 텍스트 쿼리가 요청된 단어와 같은 어근을 가진 파생어를 찾았음을 알 수 있습니다. 실제로는 2의 퍼지를 적용했습니다(다음 섹션 참조).
이 패턴은 다른 유형의 쿼리에도 적용할 수 있으므로 몇 가지를 더 살펴보고 어떤 종류의 검색을 수행할 수 있는지 살펴 보겠습니다.
다양한 유형의 쿼리
퍼지 쿼리
퍼지 쿼리는 다음을 사용하여 수행할 수 있습니다. 매치 쿼리를 지정하여 레벤슈타인 거리 를 최대 fuzziness() 를 사용하여 허용할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 |
결과 = 버킷.쿼리(매치 쿼리.on("beerIndex") .일치("sammar") .필드("name") .흐릿함(2) //실제로 기본값 .빌드()); 시스템.out.println("n퍼지 매치 쿼리"); 시스템.out.println("총 조회수(퍼지 = 2): " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { 시스템.out.println(버킷.get(행.id()).콘텐츠().get("name")); } |
흐릿하게 2를 입력하면 '망치', '맘마' 또는 '여름'과 같은 단어와 일치합니다:
|
1 2 3 4 5 |
퍼지 경기 쿼리 총 조회수 (흐릿함 = 2): 45 Mamma Mia! 피자 맥주 Redhook Long 해머 IPA 여름 밀 |
흐릿하게 1일치하는 항목이 없습니다:
|
1 2 |
퍼지 경기 쿼리 총 조회수 (흐릿함 = 1): 0 |
분석기를 적용하지 않고 퍼지 전용 쿼리 유형도 제공됩니다. 퍼지 쿼리.
여러 용어: MatchPhrase
앞서 살펴본 것처럼 매치 쿼리 는 용어 기반 쿼리로, 선택적으로 퍼지를 지정할 수 있으며 필드에 적용되었을 수 있는 검색된 용어(예: 어간 등)에도 동일한 필터를 적용할 수 있습니다:
|
1 2 3 4 |
매치 쿼리.on("beerIndex") .일치("세소날") .흐릿함(2) .필드("설명").빌드(); |
다음을 사용하여 단일 쿼리에서 여러 용어를 검색할 수 있습니다. 구문 일치 쿼리. 용어가 분석되고 선택적으로 퍼지 기능을 활성화할 수 있습니다:
|
1 |
매치구문 쿼리.on("beerIndex").matchPhrase("여름 시즌").필드("설명"); |
정규식 쿼리
A RegexpQuery 는 리터럴 매칭만 하는 것이 아니라 정규식을 사용하여 매칭할 수 있습니다. 이 예시를 살펴보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 |
결과 = 버킷.쿼리(RegexpQuery.on("beerIndex") .regexp("[tp]ale") .필드("name") .빌드()); 시스템.out.println("nRegexp 쿼리"); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { 시스템.out.println(버킷.get(행.id()).콘텐츠().get("name")); } |
이 쿼리는 json의 특정 필드(field("name")). "tale" 또는 "pale"이 포함된 모든 이름을 원합니다. 다음은 이 쿼리와 일치하는 몇 가지 이름입니다:
|
1 2 3 4 5 |
정규식 쿼리 총 조회수: 408 Tall 이야기 Pale 에일 Bard's 이야기 맥주 회사 Pale 에일 |
접두사 쿼리
A 접두사 쿼리 는 주어진 문자열로 시작하는 단어가 있는지 찾습니다:
|
1 2 3 4 5 6 7 8 9 10 |
결과 = 버킷.쿼리(접두사 쿼리.on("beerIndex") .접두사("weiss") .필드("name") .빌드()); 시스템.out.println("nPrefix 쿼리"); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { 시스템.out.println(버킷.get(행.id()).콘텐츠().get("name")); } |
다시 한 번 우리는 이름 필드에 "weiss"로 시작하는 단어를 입력합니다:
|
1 2 3 4 5 6 |
접두사 쿼리 총 조회수: 74 바이에른-와이즈비어 헤페바이스 / Weisser Hirsch Münchner Kindl 와이즈비어 / Münchner Weisse 프란치스카너 Hefe-와이즈비어 Hell / 프란치스카너 클럽-Weiss 바이센하이머 밀 |
범위 및 날짜 쿼리
FTS 는 텍스트가 아닌 데이터에도 유용합니다. 예를 들어 숫자 범위 쿼리 를 사용하면 제공된 범위 내에서 숫자 값을 찾을 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
결과 = 버킷.쿼리(숫자 범위 쿼리.on("beerIndex") .분(3) .최대(4) .필드("abv") .필드("name", "abv") .빌드()); 시스템.out.println("n숫자 범위 쿼리"); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { JsonDocument doc = 버킷.get(행.id()); 시스템.out.println(""" + doc.content().get("이름") + "", abv: " + doc.콘텐츠().get("abv")); } |
어떤 출력:
|
1 2 3 4 5 |
숫자 범위 쿼리 총 조회수: 62 "스터드 서비스 스타우트", abv: 3.1 "금발", abv: 3.0 "로크 마운틴 라이트", abv: 3.7 |
날짜는 날짜 범위 쿼리:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
캘린더 캘린더 = 캘린더.getInstance(); 캘린더.set(2011, 캘린더.MARCH, 1); 날짜 시작 = 캘린더.getTime(); 캘린더.set(2011, 캘린더.4월, 1); 날짜 끝 = 캘린더.getTime(); 결과 = 버킷.쿼리(날짜 범위 쿼리.on("beerIndex") .시작(시작) .끝(끝) .필드("업데이트됨") .필드("name", "업데이트됨") .빌드()); 시스템.out.println("nDate 범위 쿼리"); 시스템.out.println("총 조회수: " + 결과.총 조회수()); 에 대한 (검색 쿼리 행 행 : 결과) { JsonDocument doc = 버킷.get(행.id()); 시스템.out.println(""" + doc.content().get("이름") + "", 업데이트됨: " + doc.콘텐츠().get("업데이트됨")); } |
어떤 출력:
|
1 2 3 4 5 6 |
날짜 범위 쿼리 총 조회수: 4 "Dank", 업데이트: 2011-03-16 09:06:54 "Oso", 업데이트: 2011-03-16 09:05:15 "여름 치아", 업데이트: 2011-03-08 12:22:14 "콜럼버스 브루잉 컴퍼니", 업데이트: 2011-03-08 12:19:07 |
일반 쿼리
FTS 를 사용하여 구문, 용어 등을 결합하는 보다 일반적인 형태의 쿼리도 제공합니다. 문자열 쿼리 구문. 이는 API에서 문자열 쿼리.
결합
또한 다음과 같은 간단한 기준을 결합할 수 있습니다. 매치 쿼리 조합 쿼리를 사용합니다. 이 두 가지 간단한 용어 쿼리를 예로 들어 보겠습니다:
|
1 2 |
매치 쿼리 bitterQuery = 매치 쿼리.on("beerIndex").일치("쓴").필드("설명").빌드(); 매치 쿼리 maltyQuery = 매치 쿼리.on("beerIndex").일치("말티").필드("설명").빌드(); |
다양한 방식으로 조합할 수 있습니다:
- a
결합모든 용어를 찾습니다.
|
1 |
연결 쿼리.on("beerIndex").접속사(bitterQuery, maltyQuery) |
- a
분리적어도 하나의 용어를 찾습니다.
|
1 |
분리 쿼리.on("beerIndex").분리(bitterQuery, maltyQuery) |
- a
부울 쿼리를 사용하면 두 가지 접근 방식을 결합할 수 있습니다.
|
1 |
부울 쿼리.on("beerIndex").필수(bitterQuery).mustNot(maltyQuery) |
히트 설명 받기
특정 항목의 점수 및 매칭에 대한 인사이트를 얻고자 하는 경우 검색 쿼리 행를 사용하여 쿼리를 작성할 수 있습니다. .explain(true) 매개 변수를 사용하고 결과의 인덱스에서 세부 정보를 가져옵니다. 설명() 필드에 입력합니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 |
{"메시지":"합계:","children":[{"메시지":"제품:","children":[{"메시지":"합계:","children":[{"메시지":"제품:","children":[{"메시지":"합계:","children":[ { "메시지": "weight(_all:national^1.000000 in penn_brewery-penn_marzen), product of:", "children": [ { "메시지": "queryWeight(_all:national^1.000000), product of:", "children": [ { "메시지": "boost", "value": 1 }, { "메시지": "idf(docFreq=17, maxDocs=7303)", "value": 7.005668743723945 }, { "메시지": "queryNorm", "value": 0.1427415478209491 } ], "value": 0.9999999999999999 }, { "메시지": "fieldWeight(_all:국가별_펜_브루어리-펜_마르젠), product of:", "children": [ { "메시지": "tf(termFreq(_all:national)=1", "value": 1 }, { "메시지": "fieldNorm(field=_all, doc=penn_brewery-penn_marzen)", "value": 0.10000000149011612 }, { "메시지": "idf(docFreq=17, maxDocs=7303)", "value": 7.005668743723945 } ], "value": 0.7005668848116544 } ], "value": 0.7005668848116543 } ],"value":0.7005668848116543},{"메시지":"coord(1/1)","value":1}],"value":0.7005668848116543}],"value":0.7005668848116543},{"메시지":"coord(1/1)","value":1}],"value":0.7005668848116543}],"value":0.7005668848116543} |
결론
이번 API 미리보기가 여러분의 관심을 불러일으켰기를 바랍니다!
첫 번째 카우치베이스 4.5 개발자 프리뷰 전체 텍스트 검색 서비스가 내장되어 있습니다. 관련 링크를 사용하여 빠르게 검색을 시작할 수 있기를 바랍니다. Java SDK API.
그리고 그때까지는... 행복한 코딩!
– Java SDK 팀