지난 10년 동안 우리가 정보를 검색하고 상호 작용하는 방식은 극적으로 변화했습니다. 기존의 키워드 기반 검색 엔진은 문서나 답변을 찾는 데 유용했지만, 오늘날의 비즈니스 과제에는 정확한 키워드 일치 이상의 것이 요구됩니다. 소비자든 기업이든 현대의 사용자들은 다음과 같은 시스템을 기대합니다. 이해 의도, 해석 컨텍스트 및 전달 가장 관련성 높은 인사이트를 즉시 확인할 수 있습니다.
여기에서 벡터 검색 가 들어옵니다. 벡터 검색은 데이터를 고차원 수학적 표현(임베딩)으로 변환함으로써 시스템이 단순한 어휘 중첩이 아닌 의미론적 의미를 포착할 수 있게 해줍니다. 그 의미는 검색 엔진을 훨씬 뛰어넘습니다. 에이전트 애플리케이션 - 자율적으로 인식하고 추론하며 행동할 수 있는 시스템은 지식의 근간이 되는 벡터 검색에 크게 의존합니다. 벡터 검색이 없으면 AI 에이전트는 상황에 맞는 문제 해결자가 아니라 얕은 대응자가 될 위험이 있습니다.
이 블로그에서는 벡터 검색이 필수적인 요소가 된 이유, 벡터 검색이 재편하고 있는 비즈니스 영역, 그리고 Couchbase가 전체 텍스트 검색(FTS)과 Eventing을 통해 이러한 변화를 어떻게 지원하고 있는지 살펴봅니다. 통신 업계의 실제 사례 연구를 살펴보고 실무에 도움이 되는 지침을 제공합니다.
벡터 검색이 중요한 이유
벡터 검색의 핵심은 다음과 같습니다. 임베딩 - 단어, 문서 또는 멀티미디어 파일의 숫자 표현입니다. 키워드와 달리 임베딩은 다음을 인코딩합니다. 의미 관계. 예를 들어, '네트워크 중단'과 '통화 끊김'은 키워드를 많이 공유하지는 않지만 의미적으로는 비슷한 문제를 가리킵니다. 벡터 임베딩을 사용하면 쿼리와 데이터가 모두 동일한 다차원 공간에 투영되며, 여기서 유사성은 거리 메트릭(코사인 유사성, 도트 곱 등)에 의해 결정됩니다.
이러한 변화에는 중대한 의미가 있습니다:
-
- 문자 그대로에서 문맥에 맞게: 검색 시스템은 더 이상 단어만 검색하는 것이 아니라 의미까지 파악합니다.
- 정적에서 동적으로: 데이터의 증가와 컨텍스트의 변화에 따라 벡터 공간이 적응합니다.
- 검색에서 추론까지: 에이전트 애플리케이션은 단순히 데이터를 검색하는 것뿐만 아니라 의도를 해석하고 의사 결정을 내리기 위해 임베딩에 의존합니다.
간단히 말해, 벡터 검색은 키워드 검색의 기능 업그레이드가 아니라 패러다임 전환 차세대 지능형 자율 시스템을 구현할 수 있습니다.
벡터 검색 도입을 촉진하는 비즈니스 사용 사례
통신(PCAP 분석)
통신 네트워크는 엄청난 양의 패킷 캡처(PCAP) 데이터를 생성합니다. 기존의 분석은 키워드 필터, 정규식 검색, 기가바이트 단위의 로그에 대한 수동 상관관계를 포함하며, 실시간 문제 해결을 위해서는 너무 느린 경우가 많습니다. 벡터 검색은 이 판도를 바꿉니다. PCAP 추적을 포함하면 이상 징후와 패턴을 의미론적으로 클러스터링하고 검색할 수 있어 엔지니어가 통화 품질 저하나 패킷 손실과 같은 문제를 즉시 식별할 수 있습니다.
고객 지원 코파일럿
컨택 센터는 스크립트화된 FAQ 봇에서 인간 상담원을 보조하는 지능형 코파일럿으로 전환하고 있습니다. 벡터 검색은 사용자 쿼리가 표현이 다르더라도 올바른 지식창고 답변에 매핑되도록 보장합니다. 예를 들어 "내 전화가 계속 끊겨요"라는 질문은 키워드 검색으로는 놓칠 수 있는 "네트워크 혼잡 문제"에 대한 문서로 매핑될 수 있습니다.
금융 분야 사기 탐지
금융 사기는 교묘하기 때문에 패턴이 항상 키워드를 따르지 않습니다. 임베딩을 사용하면 거래 행동을 벡터로 표현할 수 있어 시스템이 '정상' 패턴에서 벗어난 이상값을 탐지할 수 있습니다. 이를 통해 기관은 비정상적이지만 키워드로는 보이지 않는 이상 징후를 표시할 수 있습니다.
헬스케어
의학 연구와 환자 기록에는 다양한 용어가 포함되어 있습니다. 벡터 검색은 '흉통'을 '협심증' 또는 '심장 불편함'과 연결하여 임상 의사 결정 지원 시스템을 더욱 효과적으로 만들 수 있습니다. 연구, 진단, 약물 발견을 가속화합니다.
리테일 및 추천 엔진
추천 시스템은 의미적 유사성을 기반으로 작동합니다. 벡터 검색을 사용하면 제품 태그를 일치시키는 것뿐만 아니라 의도, 스타일 또는 사용자 행동 패턴을 일치시키는 등 보다 심층적인 수준에서 "이 제품을 구매한 사람들이 이것도 좋아했습니다"라는 추천이 가능합니다.
엔터프라이즈 지식 관리
조직은 데이터 사일로로 인해 어려움을 겪습니다. 직원들은 여러 시스템에서 관련 인사이트를 검색하는 데 많은 시간을 낭비합니다. 벡터 검색은 형식이나 문구에 관계없이 가장 맥락에 적합한 정보를 표시하는 통합 지식 시스템을 지원합니다.
사례 연구: 벡터 검색을 사용한 통신 분야의 PCAP 분석
도전 과제
통신 사업자는 매일 수십억 개의 패킷을 캡처합니다. 기존의 패킷 분석은 수동 필터링, 문자열 검색 또는 정적 규칙을 사용하여 이상 징후를 탐지합니다. 이러한 접근 방식:
-
- 의미적 유사성을 캡처하지 못함(예: 동일한 루트 이슈의 다른 표현)
- 엄청난 데이터 양으로 인한 규모에 따른 어려움
- 느린 문제 해결과 고객 불만으로 이어짐
벡터 검색의 이점
PCAP 데이터를 벡터에 삽입합니다:
-
- 이상 징후가 자연스럽게 클러스터링 를 벡터 공간에 배치합니다(예: 모든 드롭된 콜 트레이스가 서로 가깝게 배치).
- 시맨틱 쿼리 가 가능해집니다('지연 시간 급증'을 검색하여 패킷 지터 또는 재전송이 있는 로그를 발견할 수 있습니다).
- 근본 원인 분석 가속화관련 문제를 수동으로 조합하지 않고 자동으로 표시할 수 있기 때문입니다.
결과
통신 엔지니어는 사후 대응적인 로그 구문 분석에서 사전 예방적인 이상 징후 탐지로 전환합니다. 고객 문제를 실시간으로 파악하여 만족도를 높이고 고객 이탈을 줄입니다. 몇 시간이 걸리던 수동 분석 작업을 몇 분 만에 완료할 수 있습니다.
Couchbase가 시맨틱 및 에이전트 앱에 대한 벡터 검색을 지원하는 방법
전체 텍스트 검색(FTS) 요약
Couchbase FTS는 오랫동안 기업들이 구조화된 쿼리를 넘어 자연어 및 전체 텍스트 기능을 지원할 수 있도록 해왔습니다. 그러나 FTS 자체는 여전히 어휘 검색에 뿌리를 두고 있습니다.
벡터 검색 추가
카우치베이스는 다음을 통해 FTS를 확장합니다. 벡터 인덱싱 및 유사도 검색. 즉, 기업은 데이터(로그, 문서, 쿼리 등)를 벡터에 임베드하여 의미론적 검색을 위해 Couchbase에 저장할 수 있습니다. 이제 FTS는 키워드 일치 검색을 반환하는 대신 문맥과 관련된 결과를 표시할 수 있습니다.
하이브리드 검색
진정한 파워는 다음과 같습니다. 하이브리드 검색 - 키워드와 벡터 유사성을 혼합합니다. 예를 들어, 통신 엔지니어는 "뉴욕에서 통화 끊김"을 검색하여 정확한 위치 일치(키워드)와 의미적으로 유사한 PCAP 이상 징후(벡터)를 결합한 결과를 얻을 수 있습니다.
이벤트 실행 중
카우치베이스 이벤트는 이 에코시스템에 실시간 트리거를 추가합니다. 다음과 같은 이벤트 함수를 상상해 보세요:
-
- 패킷 임베딩의 이상 징후를 감시합니다.
- 유사성 임계값을 초과하면 자동으로 알림을 표시합니다.
- 워크플로를 시작합니다(예: Jira 티켓을 열거나 운영팀에 알림).
이 조합 - FTS + 벡터 검색 + 이벤트 - 는 검색을 수동적인 정보 검색에서 능동적 인텔리전스 제공.
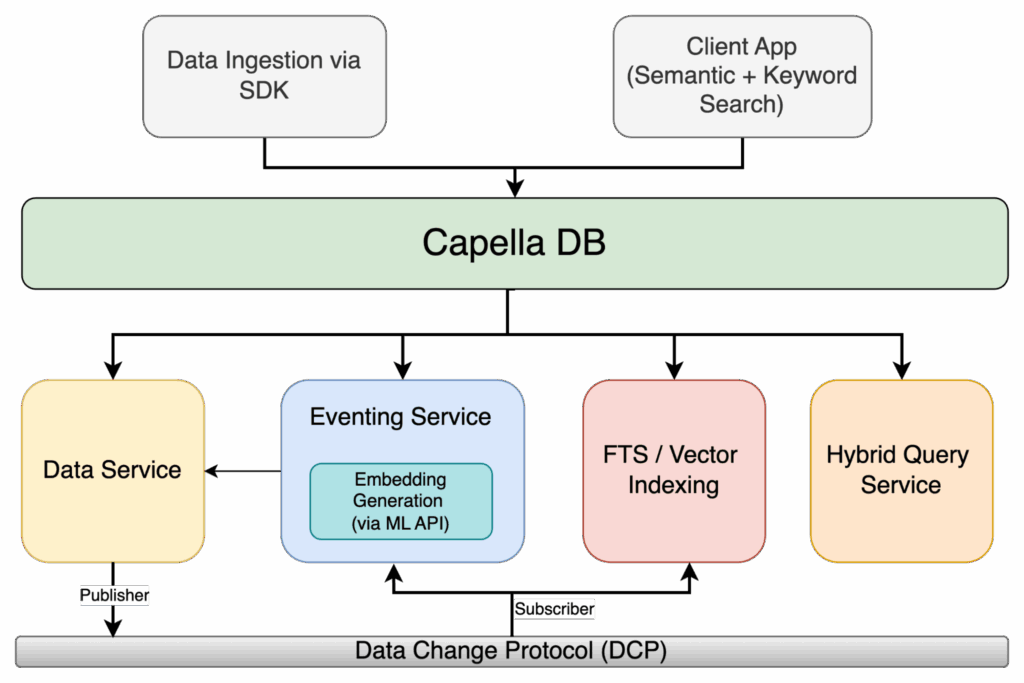
그림 1: 이벤트, ML 임베딩, FTS/벡터 인덱싱이 포함된 카펠라 하이브리드 검색 아키텍처
실습 단계별 안내: Couchbase를 사용한 벡터 검색
지금까지 벡터 검색이 중요한 이유와 카우치베이스가 이를 지원하는 방법에 대해 설명했습니다. 이제 이 모든 것을 한데 모아 실제 사례.
우리의 시나리오는 다음과 같습니다. 통신사 PCAP(패킷 캡처) 분석. 패킷 세션 요약의 방대한 스트림이 Couchbase로 유입된다고 상상해 보세요. 이 데이터를 수동적으로 저장하는 대신 Couchbase가 저장하기를 원합니다:
-
- 자동으로 embed 를 사용하여 각 세션 요약을 벡터로 변환합니다. OpenAI 임베딩.
- 이러한 임베딩을 원시 메타데이터와 함께 저장하세요.
- 다음에서 색인화 카우치베이스 FTS 를 사용하여 빠른 벡터 유사성 쿼리를 수행할 수 있습니다.
- 다음을 수행할 수 있습니다. 이상 징후 감지 또는 '비정상적으로 보이는 세션'을 실시간으로 확인할 수 있습니다.
가장 좋은 점은? 이 작업을 수동으로 수행하지 않습니다. 이벤트 는 전체 파이프라인을 자동화합니다. 새 PCAP 세션 문서가 도착하는 순간 Couchbase는 임베딩을 통해 이를 보강하고 벡터 인덱스에 바로 푸시합니다.
전제 조건
빌드에 들어가기 전에 환경이 준비되었는지 확인해 보겠습니다. 이는 단순히 체크박스에 체크하는 것이 아니라 원활한 개발자 환경을 위한 단계를 설정하는 것입니다.
카우치베이스 서버 또는 카펠라
실행 중인 Couchbase 환경이 필요합니다. 이벤트 그리고 FTS(전체 텍스트 검색) 서비스를 활성화합니다. 자동화 및 검색을 지원하는 엔진입니다.
PCAP 세션 데이터를 저장하는 버킷
이 안내에서는 버킷 PCAP이라고 부르겠습니다. 그 안에서 데이터를 범위와 컬렉션으로 정리하여 깔끔하게 유지하겠습니다.
이벤트 서비스 사용
이벤트 기능은 "반응형 접착제"입니다. 새 PCAP 세션 요약이 수집되는 즉시 Eventing이 작동하여 임베딩을 통해 문서를 보강하고 선택적으로 이상 알림을 트리거합니다.
FTS 서비스 사용
이를 통해 벡터 인덱스 를 추가하여 세션 임베딩에서 유사성 검색을 수행할 수 있습니다. 이 기능이 없으면 임베딩은 JSON에 있는 숫자에 불과합니다.
임베딩 API 엔드포인트
임베딩 모델과 API 키에 액세스할 수 있어야 합니다. 이 블로그에서는 OpenAI의 텍스트 임베딩-3-small 또는 텍스트 임베딩-3-large를 가정하지만, 고정 차원 벡터를 반환하는 모든 API를 가리킬 수 있습니다. 이벤트는 curl()을 사용하여 이 엔드포인트를 호출합니다.
PCAP 세션 수집 - 데이터 모델
모든 PCAP 캡처는 수많은 패킷을 생성합니다. 데모에서는 너무 크고 노이즈가 많은 원시 패킷을 저장하는 대신 다음과 같이 작업합니다. 세션 요약. 이 요약에는 소스/대상 IP, 프로토콜, 지터, 패킷 손실, 재전송, 세션의 모습에 대한 간단한 자연어 설명 등 중요한 사실들이 요약되어 있습니다.
단일 세션 문서는 다음과 같이 보일 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
{ "type": "pcap_session", "sessionId": "sess-2025-08-21-001", "ts": "2025-08-21T09:10:11Z", "srcIP": "10.1.2.3", "dstIP": "34.201.10.45", "srcPort": 5060, "dstPort": 5060, "proto": "SIP", "region": "us-east-1", "carrier": "cb-telecom", "durationMs": 17890, "packets": 3412, "lossPct": 0.7, "jitterMs": 35.2, "retransmits": 21, "summaryText": "SIP call with intermittent RTP loss and elevated jitter, user reported call drops", "embedding_vector": null, // <-- Eventing will fill this "qualityLabel": "unknown" // <-- Eventing/alerts will update this } |
주요 필드:
-
- 요약 텍스트 → 임베딩이 캡처할 자연어 시놉시스입니다.
- 품질 레이블 → 휴리스틱 상태 레이블(건강, 저하)를 할당할 수 있습니다.
이 단계에서는 임베딩_벡터가 비어 있습니다. 이때 이벤트가 필요합니다.
버킷/범위/컬렉션 만들기
파이프라인을 논리적 컨테이너로 구성합니다:
-
- 버킷: pcap
- 범위: 통신사
- 컬렉션:
- 세션 (원시 수집된 PCAP 세션 요약)
- 알림 (이벤트에서 발생하는 이상 알림의 경우)
- 메타데이터 (이벤트 메타데이터 정보 작성용)
예제 N1QL:
|
1 2 3 |
CREATE SCOPE `pcap`.`telco`; CREATE COLLECTION `pcap`.`telco`.`sessions`; CREATE COLLECTION `pcap`.`telco`.`alerts`; |
몇 가지 샘플 PCAP 세션 문서 시드하기
파이프라인을 테스트하기 위해 몇 개의 정상 세션과 성능 저하 세션을 삽입해 보겠습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INSERT INTO `pcap`.`telco`.`sessions` (KEY, VALUE) VALUES ("sess::1", { "type":"pcap_session","sessionId":"sess::1","ts":"2025-08-21T09:00:00Z", "srcIP":"10.0.0.1","dstIP":"52.0.0.5","srcPort":16384,"dstPort":16384, "proto":"RTP","region":"us-east-1","carrier":"cb-telecom","durationMs":600000, "packets":100000,"lossPct":0.05,"jitterMs":2.5,"retransmits":0, "summaryText":"Stable RTP media stream, negligible packet loss and low jitter", "embedding_vector":null,"qualityLabel":"unknown" }), ("sess::2", { "type":"pcap_session","sessionId":"sess::2","ts":"2025-08-21T09:05:00Z", "srcIP":"10.0.0.2","dstIP":"52.0.0.5","srcPort":5060,"dstPort":5060, "proto":"SIP","region":"us-east-1","carrier":"cb-telecom","durationMs":120000, "packets":12000,"lossPct":0.7,"jitterMs":35.2,"retransmits":21, "summaryText":"SIP negotiation with intermittent media loss and elevated jitter, multiple retransmits", "embedding_vector":null,"qualityLabel":"unknown" }); |
컬렉션 아래에서 문서를 보는 모습은 다음과 같습니다. 세션:
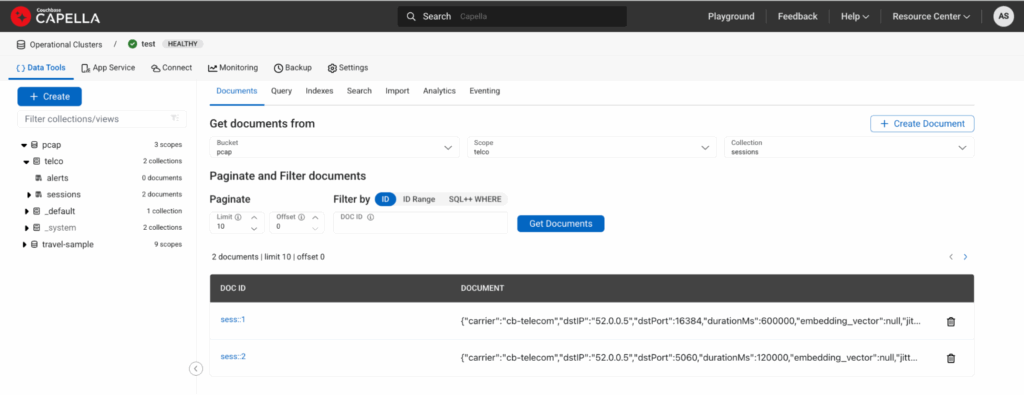
그림 2: 위의 DML을 통해 수집된 두 개의 문서를 보여주는 Capella UI.
이벤트 발생: 수집 시 자동 임베드
여기서 마법이 일어납니다. 문서가 작성될 때마다 pcap.telco.sessions이벤트 기능을 사용할 수 있습니다:
-
- 다음을 사용하여 OpenAI 임베딩 API를 호출합니다. 요약 텍스트 + 프로토, 손실, 지터, 지역, 캐리어와 같은 구조화된 기능.
- 반환된 벡터를 임베딩_벡터.
- 세션에 다음과 같이 태그를 지정합니다. 건강 또는 저하.
- 보강된 문서를 다시 세션.
- 다음 대상으로 이상 알림을 전송합니다. 알림.
바인딩을 다음과 같이 정의하겠습니다:
-
- 이름: pcap임베딩
- 출처: pcap.telco.sessions
- 메타데이터: pcap.telco.metadata
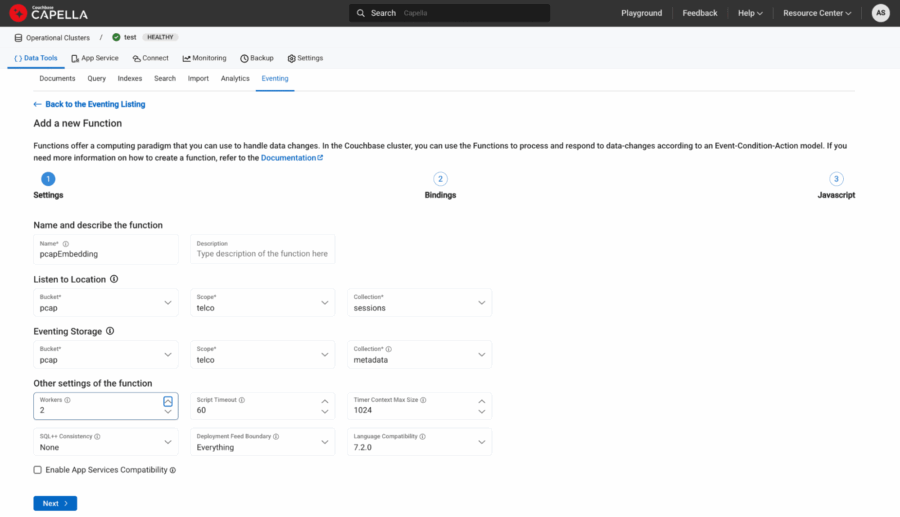
그림 3: 소스 및 메타데이터 바인딩.
-
- 버킷 별칭:
- dst → pcap.telco.sessions 와 함께 읽기 및 쓰기 권한
- 알림 → pcap.telco.alerts 와 함께 읽기 및 쓰기 권한
- URL 별칭:
- EMBEDDING_API → "https://api.openai.com/v1/embeddings“
- 상수 별칭:
- embedding_model → "텍스트 임베딩-3-소형"
- 버킷 별칭:
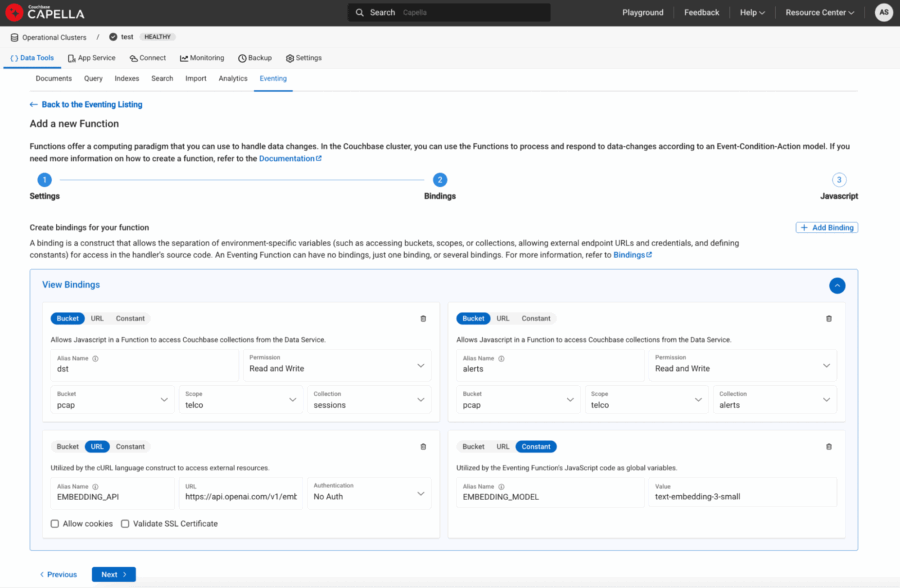
그림 4: 이벤트 함수에 대한 바인딩으로 정의된 URL 및 상수.
이벤트 자동화를 통한 인사이트 강화
지금이 바로 마법 같은 순간입니다. 대부분의 데이터베이스에서 임베딩으로 데이터를 보강하려면 외부 ETL 파이프라인이나 사용자 정의 작업자가 필요합니다. Couchbase Eventing을 사용하면 데이터베이스 자체가 지능적으로 변합니다.
아이디어는 간단합니다:
-
- 새 세션 문서가 새 세션 문서에 도착하자마자 세션 수집하면 이벤트가 실행됩니다.
- 그러면 OpenAI 임베딩 API (텍스트 임베딩-3-small 또는 텍스트 임베딩-3-large 은 이를 위한 훌륭한 모델입니다).
- 반환된 벡터는 동일한 문서에 다시 추가됩니다.
결과는? 이제 버킷에 다음이 저장됩니다. PCAP 세션 + 시맨틱 지문를 클릭하고 색인화할 준비가 되었습니다.
업데이트된 이벤트 핸들러는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 |
function OnUpdate(doc, meta) { log("Eventing function started for doc id:", meta.id); try { if (doc.type !== "pcap_session") { log("Skipping doc: type is", doc.type); return; } var OPENAI_KEY = "YZX"; // <-- your OpenAI key // 1) Build enriched input text for embedding // Combine free-text + structured context so embeddings capture richer semantics var text = doc.summaryText || ""; text += " Proto:" + (doc.proto || ""); text += " LossPct:" + (doc.lossPct || 0); text += " JitterMs:" + (doc.jitterMs || 0); text += " Retransmits:" + (doc.retransmits || 0); text += " Region:" + (doc.region || ""); text += " Carrier:" + (doc.carrier || ""); log("Emritched text before embedding is: " + text); // 2) Call OpenAI Embeddings API var request = { headers: { "Authorization": "Bearer " + OPENAI_KEY, "Content-Type": "application/json" }, body: JSON.stringify({ "input": text, "model": EMBEDDING_MODEL }) }; try { var response = curl("POST", EMBEDDING_API, request); var body = response.body; log("Response body parsed"); if (typeof body === "string") { var result = JSON.parse(body); } else if (typeof body === "object") { // If already parsed, just assign var result = body; } else { log("Unexpected response.body type:", typeof body); } // Extract the embedding vector from first data element if (result && result.data && result.data.length > 0 && result.data[0].embedding) { var embeddingVector = result.data[0].embedding; log("Embedding vector length:", embeddingVector.length); // 3) Write back embedding + quality heuristic doc.embedding_vector = embeddingVector; doc.embedding_model = EMBEDDING_MODEL; doc.qualityLabel = (doc.lossPct > 0.5 || doc.jitterMs > 30 || doc.retransmits > 10) ? "degraded" : "healthy"; // Update destination collection dst[meta.id] = doc; } else { log("Embedding not found in response:", JSON.stringify(result)); } } catch (e) { log("Curl threw exception:", e); } // 4) Raise anomaly alert if degraded if (doc.qualityLabel === "degraded") { var alertDoc = { type: "pcap_alert", sessionId: doc.sessionId, ts: new Date().toISOString(), reason: "Heuristic threshold exceeded", lossPct: doc.lossPct, jitterMs: doc.jitterMs, retransmits: doc.retransmits, region: doc.region, carrier: doc.carrier }; var alertKey = "alert::" + doc.sessionId; alerts[alertKey] = alertDoc; } log("Document enriched with embedding + quality label:", meta.id); } catch (e) { log(" Eventing exception", e); } } function OnDelete(meta, options) { // No-op for deletes } |
이제 모든 새로운 PCAP 세션 요약 셀프 리치 를 실시간으로 확인할 수 있습니다.
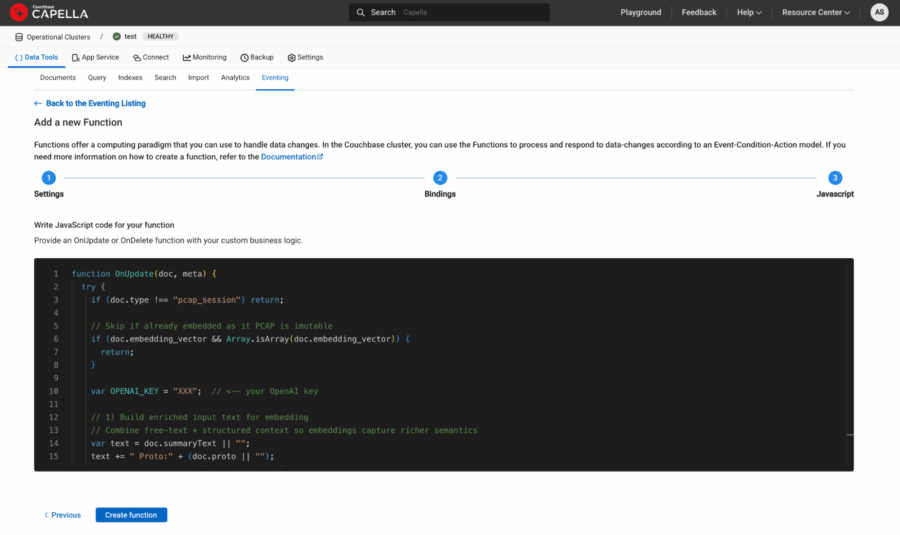
그림 5: 함수 정의의 마지막 단계에서 이벤트 함수 자바스크립트 복사/붙여넣기.
마지막으로 기능을 배포하면 준비가 완료되면 녹색으로 바뀝니다.
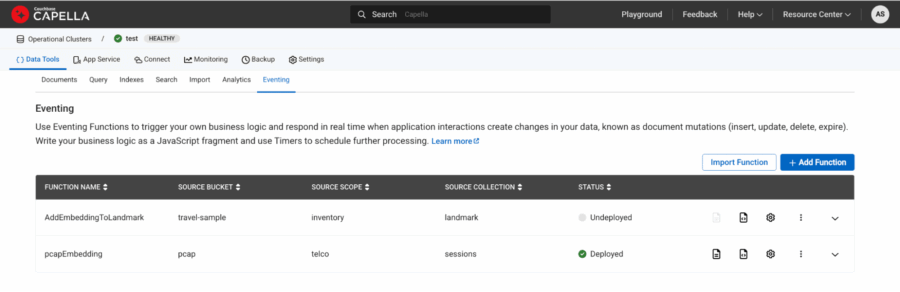
그림 6: pcap임베딩 함수가 배포되고 상태 아래에 녹색으로 표시됩니다.
문서를 확인하면 이제 추가 임베딩_벡터 그리고 embedding_model 필드를 다른 필드와 함께 사용할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
{ "carrier": "cb-telecom", "dstIP": "52.0.0.5", "dstPort": 16384, "durationMs": 600000, "jitterMs": 2.5, "lossPct": 0.05, "packets": 100000, "proto": "RTP", "qualityLabel": "healthy", "region": "us-east-1", "retransmits": 0, "sessionId": "sess::1", "srcIP": "10.0.0.1", "srcPort": 16384, "summaryText": "Stable RTP media stream, negligible packet loss and low jitter", "ts": "2025-08-21T09:00:00Z", "type": "pcap_session", "embedding_model": "text-embedding-3-small", "embedding_vector": [-0.004560039, -0.0018385303, 0.033093546, 0.0023359614, ...] } |
카우치베이스에서 벡터 인식 FTS 인덱스 만들기
이제 각 PCAP 세션 문서에는 다음 두 가지가 모두 포함됩니다. 임베딩 벡터 그리고 강화된 메타데이터 (지역, 프로토, 캐리어, 지터, 손실, 재전송) 필드를 검색할 수 있도록 하는 것이 다음 단계입니다. Couchbase의 전체 텍스트 검색(FTS) 엔진은 이제 다음을 지원합니다. 벡터 인덱싱를 사용하여 기존의 키워드 및 숫자 필드와 함께 고차원 임베딩을 저장할 수 있습니다.
이것이 왜 중요한가요?
이를 통해 다음을 실행할 수 있기 때문입니다. 시맨틱 쿼리 같은 "아시아에서 LTE로 전송된 이 품질 저하 통화와 유사한 세션 찾기" - 결합 의미적 유사성 (벡터 검색을 통해) 구조화된 필터링 (지역, 프로토, 이동 통신사).
다음은 이러한 인덱스에 대한 간단한 JSON 정의입니다(FTS 콘솔에서 새 인덱스를 생성하여 붙여넣으면 됩니다):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 |
{ "type": "fulltext-index", "name": "pcap.telco.pcapEmbeddingIndex", "uuid": "2fd519311de37177", "sourceType": "gocbcore", "sourceName": "pcap", "sourceUUID": "a576b1ee361c33974e47371d03098b72", "planParams": { "maxPartitionsPerPIndex": 1024, "indexPartitions": 1 }, "params": { "doc_config": { "docid_prefix_delim": "", "docid_regexp": "", "mode": "scope.collection.type_field", "type_field": "type" }, "mapping": { "analysis": {}, "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "dynamic": false, "enabled": false }, "default_type": "_default", "docvalues_dynamic": false, "index_dynamic": true, "store_dynamic": true, "type_field": "_type", "types": { "telco.sessions": { "dynamic": false, "enabled": true, "properties": { "carrier": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "carrier", "store": true, "type": "text" } ] }, "embedding_vector": { "dynamic": false, "enabled": true, "fields": [ { "dims": 1536, "index": true, "name": "embedding_vector", "similarity": "dot_product", "type": "vector", "vector_index_optimized_for": "recall" } ] }, "jitterMs": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "jitterMs", "store": true, "type": "number" } ] }, "lossPct": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "lossPct", "store": true, "type": "number" } ] }, "proto": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "proto", "store": true, "type": "text" } ] }, "qualityLabel": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "qualityLabel", "store": true, "type": "text" } ] }, "region": { "dynamic": false, "enabled": true, "fields": [ { "analyzer": "en", "index": true, "name": "region", "store": true, "type": "text" } ] }, "retransmits": { "dynamic": false, "enabled": true, "fields": [ { "index": true, "name": "retransmits", "store": true, "type": "number" } ] } } } } }, "store": { "indexType": "scorch", "segmentVersion": 16 } }, "sourceParams": {} } |
쉬운 영어로 설명해 보겠습니다:
-
- 임베딩_벡터 → 유사성 쿼리가 발생하는 벡터 필드인 시맨틱 백본입니다. 우리는 도트 제품 를 유사성 메트릭으로 사용하는데, 이는 OpenAI 임베딩과 잘 작동하기 때문입니다.
- 지역, proto, 캐리어 → 통신 지역, 패킷 프로토콜 또는 통신사별로 필터링할 수 있도록 텍스트 필드로 색인화됩니다.
- lossPct, jitterMs, 재전송 → 범위 쿼리를 허용하는 숫자 필드(예: "지터가 50ms를 초과하는 세션").
- 품질 레이블 → 이벤트 기능에서 이미 호출에 '정상' 또는 '성능 저하'라는 태그가 지정되어 있어 이제 검색 가능한 필드가 됩니다.
이 이중 구조는 벡터 + 메타데이터 - 이 솔루션을 강력하게 만드는 이유입니다. 의미적 유사성과 구조화된 필터링 중 하나를 선택해야 하는 것이 아니라 단일 쿼리에서 두 가지를 혼합하여 사용할 수 있습니다.
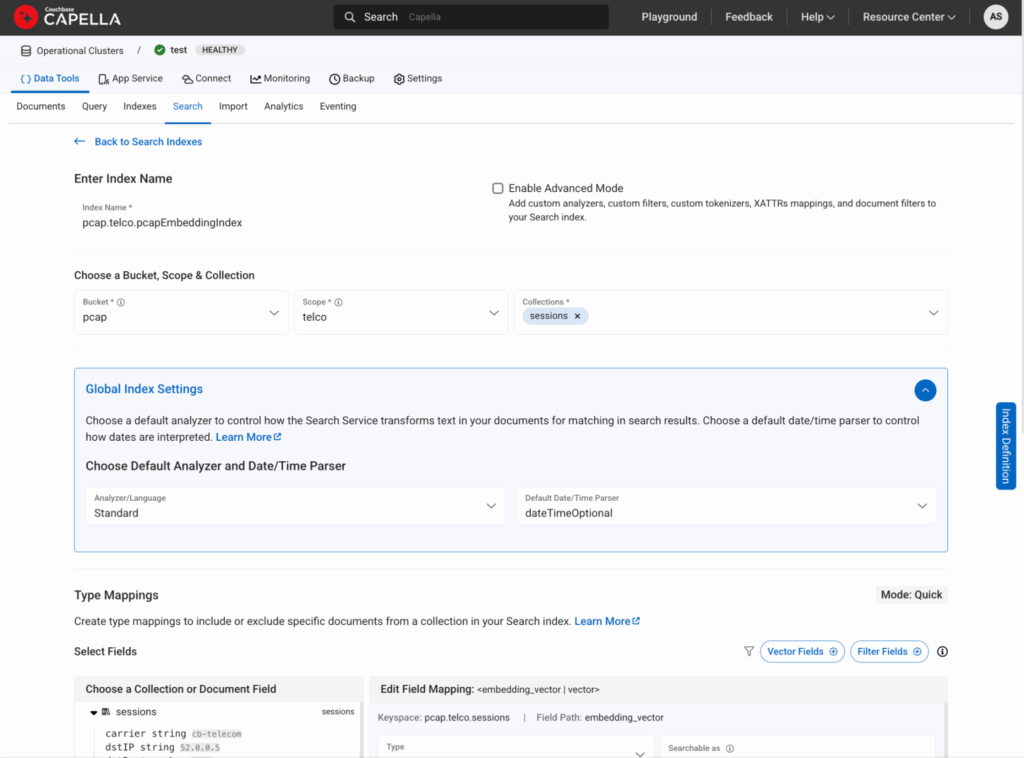
그림 7: 검색 탭에서 벡터 인덱스를 생성하는 방법은 다음과 같습니다.
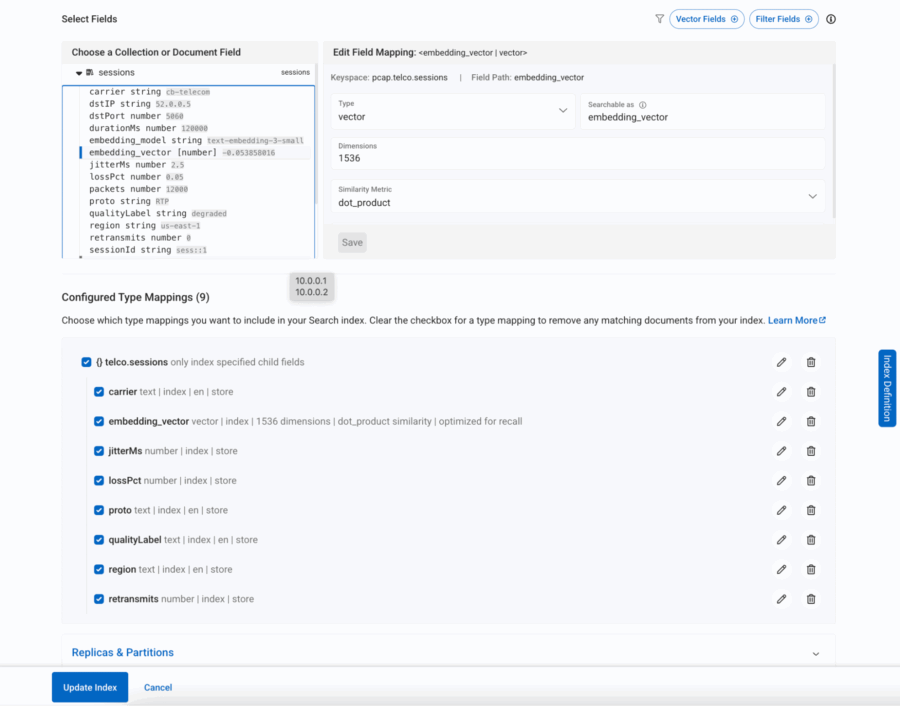
그림 8: 모든 필수 필드 세션 문서가 검색에 포함됩니다.
하이브리드 검색으로 이상 징후 탐지 강조하기
마지막으로, 다음과 같은 이상 징후 탐지를 통해 얻을 수 있는 실질적인 혜택을 살펴보겠습니다. 하이브리드 벡터 검색.
뉴욕에서 통화 끊김에 대한 불만이 쇄도하고 있다고 가정해 보세요. 다음과 같은 쿼리를 실행할 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
SELECT META(s).id, s.sessionId, s.summaryText, s.qualityLabel, s.region, s.proto, s.carrier FROM `pcap`.`telco`.`sessions` AS s WHERE SEARCH(s, { "fields": ["*"], "knn": [ { "k": 10, "field": "embedding_vector", "vector": [/* ... fill with your actual embedding ... */], "filter": { "conjuncts": [ { "match": "degraded", "field": "qualityLabel" }, { "match": "us-east-1", "field": "region" }, { "match": "SIP", "field": "proto" }, { "match": "cb-telecom", "field": "carrier" } ] } } ] }); |
이 쿼리는 이렇게 말합니다:
-
- 가장 유사한 세션 10개를 찾아주세요. 저하 SIP 통화(의미적 유사성)
- 그러나 다음에서 발생한 경우에만 US-EAST-1는 SIP 통화였습니다.
돌아오는 것은 단순한 '불량 통화' 목록이 아니라 다음과 같은 정보입니다. 의미론적으로 관련된 이상 징후 클러스터 를 통해 근본 원인을 정확히 파악할 수 있습니다. 이러한 문제가 모두 한 통신사에서 발생한다면 통신사 문제를 격리한 것입니다. 특정 시간대에 트래픽이 급증한다면 라우팅 병목 현상일 수 있습니다.
벡터 검색이 '멋진 수학'을 넘어 다음과 같은 결과를 제공하기 시작하는 곳입니다. 실제 운영 인사이트.
에이전트 애플리케이션의 근간이 되는 벡터 검색
에이전트 애플리케이션은 정보를 검색할 뿐만 아니라 정보를 해석하고 조치를 취하도록 설계되었습니다. 고객 지원 부조종사, 사기 탐지 엔진, 통신 이상 징후 탐지기 등 이러한 시스템에는 에이전트 애플리케이션이 필요합니다:
-
- 컨텍스트 리콜: 검색 오른쪽 문자 그대로 일치하는 정보뿐만 아니라
- 추론 기능: 관계와 의도를 이해합니다.
- 자율성: 사람의 개입 없이 워크플로와 의사 결정을 트리거하세요.
세 개의 기둥은 모두 벡터 검색. 임베딩이 없으면 에이전트는 메모리가 부족합니다. 유사성 검색이 없으면 추론 능력이 부족합니다. 시맨틱 컨텍스트가 없으면 효과적으로 행동할 수 없습니다.
그렇기 때문에 벡터 검색은 새로운 검색 방법 그 이상의 의미를 지닙니다. 지식 백본 에이전트 시대를 열었습니다.
결론 및 다음 단계
벡터 검색은 검색을 키워드에서 컨텍스트로 전환하여 업계를 변화시키고 있습니다. 통신 이상 징후 탐지부터 고객 지원 코파일럿 및 사기 탐지에 이르기까지 모든 것을 지원합니다. 그 핵심은 다음과 같은 기반을 마련합니다. 에이전트 애플리케이션 - 기억하고, 추론하고, 행동할 수 있는 지능형 시스템입니다.
카우치베이스는 다음과 같은 조합을 통해 이를 실현합니다. 전체 텍스트 검색, 벡터 인덱싱 및 이벤트 처리를 통해 기업이 시맨틱 검색을 실시간으로 운영할 수 있도록 지원합니다.
다음 편에서는 한 단계 더 나아가 다음과 같은 방법을 살펴보겠습니다. LLM + 벡터 검색 컨텍스트를 이해할 뿐만 아니라 인사이트를 생성하고 사전 조치를 취하는 진정한 자율 에이전트 애플리케이션을 구축할 수 있습니다.