개요
카우치베이스 버전 5.5에서는 N1QL에 ANSI JOIN 지원이 추가되었습니다. 이전 버전의 Couchbase에서는 조인 지원이 조회 조인 및 인덱스 조인으로 제한되어 있었는데, 이는 조인 한쪽의 문서 키를 다른 쪽에서 생성할 수 있는 경우, 즉 문서 키를 통해 부모-자식 또는 자식-부모 관계에 조인하는 경우에 유용하게 작동합니다.
이 접근 방식이 부족한 경우는 조인이 임의의 필드 또는 필드 표현식에 대한 것이거나 여러 조인 조건이 필요한 경우입니다. ANSI JOIN은 관계형 데이터베이스에서 널리 사용되는 표준화된 조인 구문입니다. ANSI JOIN은 조회 조인 및 인덱스 조인보다 훨씬 유연하여 문서의 모든 필드에 대한 임의의 표현식에 대해 조인을 수행할 수 있습니다. 따라서 조인 작업이 훨씬 간단하고 강력해집니다.
ANSI JOIN 구문:
lhs-expression [ 조인 유형 ] JOIN rhs-키 스페이스 ON [ 조인 조건 ]
조인의 왼쪽인 lhs-expression은 키 스페이스, N1QL 식, 하위 쿼리 또는 이전 조인일 수 있습니다. 조인의 오른쪽인 rhs-keyspace는 키 스페이스여야 합니다. ON 절은 조인 조건을 지정하며, 임의의 표현식이 될 수 있지만 오른쪽 키스페이스에서 인덱스 스캔을 허용하는 술어가 포함되어야 합니다. 조인 유형은 INNER, LEFT OUTER, RIGHT OUTER가 될 수 있습니다. INNER 및 OUTER 키워드는 선택 사항이므로 JOIN은 INNER JOIN과 동일하며, LEFT JOIN은 LEFT OUTER JOIN과 동일합니다. 관계형 데이터베이스에서 조인 유형은 FULL OUTER 또는 CROSS가 될 수도 있지만, 현재 N1QL에서는 FULL OUTER JOIN 및 CROSS JOIN이 지원되지 않습니다.
ANSI JOIN 지원 세부 정보
예제를 통해 ANSI JOIN 구문을 사용하여 쿼리를 실행하는 새로운 방법과 N1QL의 기존 조인 쿼리를 조회 조인 또는 인덱스 조인 구문에서 새로운 ANSI JOIN 구문으로 변환하는 방법을 보여드리겠습니다. 이전 버전과의 호환성을 위해 조회 조인 및 인덱스 조인은 N1QL에서 계속 지원되지만, 동일한 쿼리 블록에서 조회 조인 또는 인덱스 조인과 새로운 ANSI JOIN 구문을 혼합할 수 없으므로, 고객은 새로운 ANSI JOIN 구문으로 마이그레이션하는 것이 좋습니다.
따라하기, 여행 샘플 설치 샘플 버킷.
예 1: 임의의 조인 조건이 있는 ANSI JOIN
ANSI JOIN의 조인 조건(ON 절)은 조인되는 문서의 모든 필드를 포함하는 모든 표현식이 될 수 있습니다. 예를 들어
필수 색인입니다:
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
선택적 인덱스:
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(도시, 국가) WHERE type = "airport"; |
쿼리:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT route.destinationairport FROM `여행-샘플` 공항 JOIN `여행-샘플` 경로 ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "샌프란시스코" AND airport.country = "미국"; |
이 쿼리에서는 공항 문서의 필드("faa")를 경로 문서의 필드("sourceairport")와 조인하고 있습니다(조인의 ON 절 참조). 이러한 조인은 N1QL의 조회 조인이나 인덱스 조인에서는 불가능합니다. 왜냐하면 두 조인 모두 문서 키에 대해서만 조인이 필요하기 때문입니다.
ANSI JOIN을 사용하려면 오른쪽 키 공간에 적절한 인덱스가 필요합니다(위의 "필수 인덱스"). 쿼리 속도를 높이기 위해 다른 인덱스(예: 위의 "선택적 인덱스")를 생성할 수도 있습니다. 선택적 인덱스가 없으면 기본 스캔이 사용되며 쿼리는 계속 작동하지만 필수 인덱스가 없으면 쿼리가 작동하지 않고 오류가 반환됩니다.
설명을 살펴보세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 |
"plan": { "1TP5운영자": "시퀀스", "~어린이": [ { "1TP5운영자": "IndexScan3", "as": "공항", "index": "공항_도시_국가", "index_id": "8E782FD1B124EEC3", "index_projection": { "primary_key": true }, "키스페이스": "travel-sample", "네임스페이스": "기본값", "스팬": [ { "정확한": true, "범위": [ { "high": "\"샌프란시스코\"", "포함": 3, "low": "\"샌프란시스코\"" }, { "high": "\"미국\"", "포함": 3, "low": "\"미국\"" } ] } ], "사용": "gsi" }, { "1TP5운영자": "Fetch", "as": "공항", "키스페이스": "travel-sample", "네임스페이스": "default" }, { "1TP5운영자": "병렬", "~어린이": { "1TP5운영자": "시퀀스", "~어린이": [ { "#operator": "NestedLoopJoin", "별칭": "경로", "on_clause": "(((`에어포트`.`faa`) = 커버 ((`루트`.`소스에어포트`))) 및 (커버 ((`루트`.`타입`)) = \"루트\"))", "~어린이": { "1TP5운영자": "시퀀스", "~어린이": [ { "1TP5운영자": "IndexScan3", "as": "경로", "커버": [ "커버 ((`경로`.`소스공항`))", "커버 ((`경로`.`목적지공항`))", "커버 ((메타(`경로`).`ID`))" ], "filter_covers": { "커버 ((`경로`.`유형`))": "route" }, "index": "route_airports", "index_id": "F1F4B9FBE85E45FD", "키스페이스": "travel-sample", "네임스페이스": "기본값", "nested_loop": true, "스팬": [ { "정확한": true, "범위": [ { "high": "(`airport`.`faa`)", "포함": 3, "low": "(`airport`.`faa`)" } ] } ], "사용": "gsi" } ] } }, { "1TP5운영자": "필터", "조건": "((((`에어포트`.`유형`) = \"공항\") 및 ((`에어포트`.`도시`) = \"샌프란시스코\")) 및 ((`에어포트`.`국가`) = \"미국\"))"" }, { "1TP5운영자": "초기 프로젝트", "distinct": true, "결과_기간": [ { "expr": "커버 ((`경로`.`목적지공항`))" } ] }, { "1TP5운영자": "구별" }, { "1TP5운영자": "최종 프로젝트" } ] } }, { "1TP5운영자": "구별" } ] } |
NestedLoopJoin 연산자가 조인을 수행하는 데 사용되고, 그 아래에는 IndexScan3 연산자가 오른쪽 키 공간인 "route"에 액세스하는 데 사용되는 것을 볼 수 있습니다. 인덱스 스캔의 스팬은 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"스팬": [ { "정확한": true, "범위": [ { "high": "(`airport`.`faa`)", "포함": 3, "low": "(`airport`.`faa`)" } ] } ] |
오른쪽 키 공간("route")에 대한 색인 스캔은 왼쪽 키 공간("airport")의 필드("faa")를 검색 키로 사용합니다. 외부 키 공간 "airport"의 각 문서에 대해 NestedLoopJoin 연산자는 내부 키 공간 "route"에서 인덱스 스캔을 수행하여 일치하는 문서를 찾고 조인 결과를 생성합니다. 조인은 중첩 루프 방식으로 수행되며, 외부 루프는 외부 키스페이스에서 문서를 생성하고 중첩된 내부 루프는 현재 외부 문서에 대해 일치하는 내부 문서를 검색합니다.
쿼리 워크벤치에서 설명 버튼을 클릭한 다음 계획 버튼을 클릭하면 설명 정보를 그래픽으로 볼 수도 있습니다:
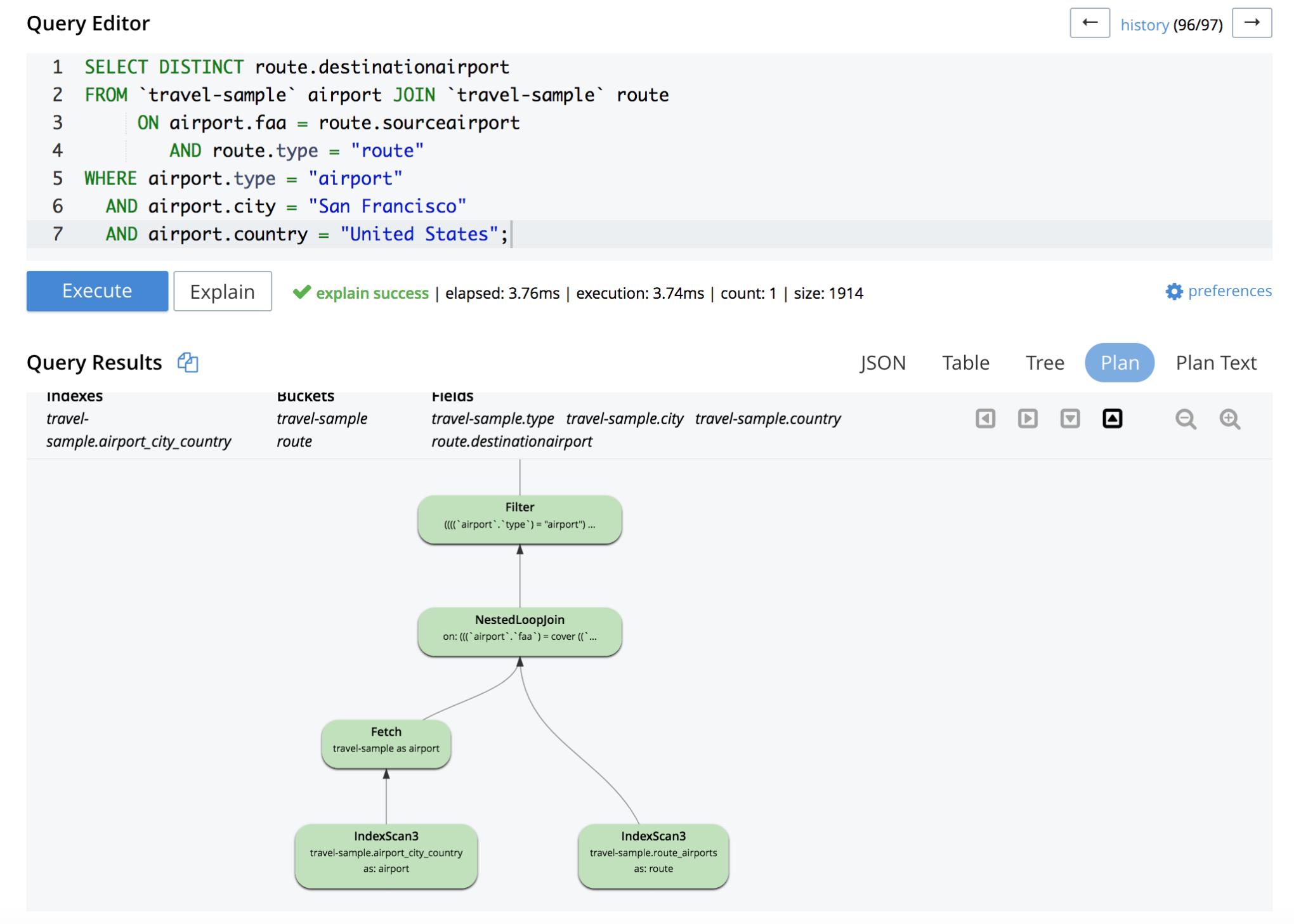
이 예에서 오른쪽 키 공간의 인덱스 스캔은 커버된 인덱스 스캔입니다. 인덱스 스캔이 덮여 있지 않은 경우 가져오기 연산자가 인덱스 스캔 연산자를 따라 문서를 가져오게 됩니다.
중첩 루프 조인에는 ANSI JOIN의 오른쪽 키 공간에 적절한 보조 인덱스가 필요하다는 점에 유의하세요. 기본 인덱스는 이 목적으로 고려되지 않습니다. 적절한 보조 인덱스를 찾을 수 없는 경우 쿼리에 대한 오류가 반환됩니다.
또한 다음과 같은 필터를 사용했을 수도 있습니다. route.type = "경로" 도 ON 절에 나타납니다. ON절은 조인의 일부로 평가되는 반면 WHERE절은 모든 조인이 완료된 후에 평가된다는 점에서 WHERE절과 다릅니다. 이 구분은 특히 외부 조인의 경우 중요합니다. 따라서 모든 조인 필터와 더불어 조인의 오른쪽 키 공간에 있는 필터도 ON 절에 포함하는 것이 좋습니다.
예 2: 다중 조인 조건이 있는 ANSI JOIN
조회 조인 및 인덱스 조인은 단일 조인 조건(문서 키의 동일성)에 대해서만 조인하지만, ANSI 조인의 ON 절은 여러 조인 조건을 포함할 수 있습니다.
필수 색인입니다:
|
1 |
CREATE INDEX landmark_city_country ON `travel-sample`(도시, 국가) WHERE type = "landmark"; |
선택적 인덱스:
|
1 |
CREATE INDEX hotel_title ON `travel-sample`(title) WHERE type = "hotel"; |
쿼리:
|
1 2 3 4 |
호텔명 호텔_이름, 랜드마크명 랜드마크_이름, 랜드마크.활동 SELECT FROM `여행-샘플` 호텔 JOIN `여행-샘플` 랜드마크 ON hotel.city = landmark.city AND hotel.country = landmark.country AND landmark.type = "landmark" WHERE hotel.type = "hotel" AND hotel.title = "요세미티%" AND array_length(hotel.public_likes) > 5; |
설명을 살펴보면 오른쪽 키 스페이스('랜드마크')의 인덱스('랜드마크_도시_국가')에 대한 인덱스 범위는 다음과 같습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
"스팬": [ { "정확한": true, "범위": [ { "high": "(`호텔`.`도시`)", "포함": 3, "low": "(`호텔`.`도시`)" }, { "high": "(`호텔`.`국가`)", "포함": 3, "low": "(`호텔`.`국가`)" } ] } ] |
따라서 여러 조인 술어가 잠재적으로 중첩 루프 조인의 내부 인덱스 스캔을 위한 여러 인덱스 검색 키를 생성할 수 있습니다.
예 3: 복잡한 조인 식이 포함된 ANSI JOIN
ON 절의 조인 조건은 복잡한 조인 표현식이 될 수 있습니다. 예를 들어, 'route' 문서의 'airlineid' 필드는 'airline' 문서의 문서 키에 해당하지만 'airline_'를 'airline' 문서의 'id' 필드와 연결하여 구성할 수도 있습니다.
필수 색인입니다:
|
1 |
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type = "route"; |
선택적 인덱스:
|
1 |
CREATE INDEX airline_name ON `travel-sample`(name) WHERE type = "airline"; |
쿼리:
|
1 2 3 4 |
SELECT count(*) FROM `여행-샘플` 항공사 JOIN `여행-샘플` 경로 ON route.airlineid = "airline_" || tostring(airline.id) AND route.type = "route" WHERE airline.type = "항공사" AND airline.name = "유나이티드 항공"; |
설명에는 오른쪽 키스페이스("경로")에 대한 인덱스 범위가 다음과 같이 포함되어 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 |
"스팬": [ { "정확한": true, "범위": [ { "high": "(\"airline_\" || to_string((`airline`.`id`))", "포함": 3, "low": "(\"airline_\" || to_string((`airline`.`id`))" } ] } ] |
이 표현식은 런타임에 평가되어 중첩 루프 조인의 내부에서 인덱스 스캔을 위한 검색 키를 생성합니다.
예 4: IN 절을 사용한 ANSI JOIN
조인 조건은 같음 조건일 필요는 없습니다. IN 절을 조인 조건으로 사용할 수 있습니다.
필수 색인입니다:
|
1 |
CREATE INDEX airport_faa_name ON `travel-sample`(faa, 공항명) WHERE type = "airport"; |
선택적 인덱스:
|
1 |
CREATE INDEX route_airline_distance ON `travel-sample`(항공사, 거리) WHERE type = "route"; |
쿼리:
|
1 2 3 4 |
공항.공항명 선택 FROM `여행-샘플` 경로 JOIN `여행-샘플` 공항 ON airport.faa IN [ route.sourceairport, route.destinationairport ] AND airport.type = "airport" WHERE route.type = "route" AND route.airline = "F9" AND route.distance > 3000; |
설명에는 오른쪽 키 스페이스("공항")에 대한 인덱스 범위가 다음과 같이 포함되어 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
"스팬": [ { "범위": [ { "high": "(`경로`.`소스공항`)", "포함": 3, "low": "(`경로`.`소스공항`)" } ] }, { "범위": [ { "high": "(`경로`.`목적지공항`)", "포함": 3, "low": "(`경로`.`목적지공항`)" } ] } ] |
예 5: OR 절을 사용한 ANSI JOIN
IN 절과 마찬가지로, ANSI JOIN의 조인 조건에는 OR 절도 포함될 수 있습니다. 적절한 인덱스가 존재하는 한, OR 절의 다른 암은 잠재적으로 오른쪽 키 공간의 다른 필드를 참조할 수 있습니다.
필수 인덱스(예제 1과 동일한 route_airports 인덱스):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX route_airports2 ON `travel-sample`(destinationairport, sourceairport) WHERE type = "route"; |
선택적 인덱스(예 1과 동일):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(도시, 국가) WHERE type = "airport"; |
쿼리:
|
1 2 3 4 |
SELECT count(*) FROM `여행-샘플` 공항 JOIN `여행-샘플` 경로 ON (route.sourceairport = airport.faa 또는 route.destinationairport = airport.faa) AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "덴버" AND airport.country = "미국"; |
이 설명은 NestedLoopJoin에서 UnionScan이 OR 절을 처리하는 데 사용되는 것을 보여줍니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 |
"1TP5운영자": "유니온스캔", "스캔": [ { "1TP5운영자": "IndexScan3", "as": "경로", "index": "route_airports", "index_id": "F1F4B9FBE85E45FD", "index_projection": { "primary_key": true }, "키스페이스": "travel-sample", "네임스페이스": "기본값", "nested_loop": true, "스팬": [ { "정확한": true, "범위": [ { "high": "(`airport`.`faa`)", "포함": 3, "low": "(`airport`.`faa`)" } ] } ], "사용": "gsi" }, { "1TP5운영자": "IndexScan3", "as": "경로", "index": "route_airports2", "index_id": "cdc9dca18c973bd3", "index_projection": { "primary_key": true }, "키스페이스": "travel-sample", "네임스페이스": "기본값", "nested_loop": true, "스팬": [ { "정확한": true, "범위": [ { "high": "(`airport`.`faa`)", "포함": 3, "low": "(`airport`.`faa`)" } ] } ], "사용": "gsi" } ] |
예 6: 힌트가 포함된 ANSI JOIN
조회 조인 및 인덱스 조인의 경우 힌트는 조인의 왼쪽 키 스페이스에만 지정할 수 있습니다. ANSI 조인의 경우 힌트를 오른쪽 키 스페이스에도 지정할 수 있습니다. 예 1과 동일한 쿼리를 사용합니다(USE INDEX 힌트 추가):
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` 공항 JOIN `travel-sample` 경로 USE INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "샌프란시스코" AND airport.country = "미국"; |
USE INDEX 힌트는 플래너가 조인을 수행할 때 고려해야 하는 인덱스의 수를 제한합니다.
힌트는 ANSI JOIN의 왼쪽 키 공간에 지정할 수도 있습니다.
|
1 2 3 4 5 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport USE INDEX(airport_city_country) JOIN `travel-sample` 경로 USE INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "샌프란시스코" AND airport.country = "미국"; |
예 7: ANSI 왼쪽 외부 조인
지금까지 내부 조인에 대해 살펴보았습니다. 조인 지정에서 JOIN 키워드 앞에 LEFT 또는 LEFT OUTER 키워드를 포함하기만 하면 LEFT OUTER JOIN을 수행할 수도 있습니다.
필수 인덱스(예제 1과 동일):
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
선택적 인덱스(예 1과 동일):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(도시, 국가) WHERE type = "airport"; |
쿼리:
|
1 2 3 4 |
공항.공항명, 노선.항공사명 선택 FROM `여행-샘플` 공항 LEFT JOIN `여행-샘플` 경로 ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "덴버" AND airport.country = "미국"; |
이 쿼리의 결과 집합에는 왼쪽 외부 조인의 의미론에 따라 조인된 모든 결과뿐만 아니라 오른쪽("공항") 문서와 조인되지 않은 왼쪽("노선") 문서가 포함됩니다. 따라서 공항.airportname만 포함되고 route.airlineid(누락됨)는 포함되지 않은 결과를 찾을 수 있습니다. 또한 오른쪽 키 공간("route")에 IS MISSING 술어를 추가하여 오른쪽("route") 문서와 조인하지 않는 왼쪽("airport") 문서만 선택할 수도 있습니다:
|
1 2 3 4 5 |
공항.공항명, 노선.항공사명 선택 FROM `여행-샘플` 공항 LEFT JOIN `여행-샘플` 경로 ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "덴버" AND airport.country = "미국" 그리고 route.airlineid가 누락되었습니다; |
예제 8: ANSI 오른쪽 외부 조인
ANSI 오른쪽 외부 조인은 조인이 발생하지 않는 경우 오른쪽 문서를 보존한다는 점을 제외하면 ANSI 왼쪽 외부 조인과 유사합니다. 예제 7의 쿼리는 왼쪽과 오른쪽 키 스페이스를 바꾸고 LEFT 키워드를 RIGHT 키워드로 바꾸어 수정할 수 있습니다:
|
1 2 3 4 |
공항.공항명, 노선.항공사명 선택 부터 `여행-샘플` 노선 오른쪽 조인 `여행-샘플` 공항 ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "덴버" AND airport.country = "미국"; |
조인 사양에서 공항과 경로를 전환했지만 경로가 이 외부 조인에서 여전히 종속적인 쪽에 있기 때문에 경로의 필터(이제 왼쪽 키 공간)가 조인의 ON 절에 여전히 나타납니다.
오른쪽 외부 조인은 내부적으로 왼쪽 외부 조인으로 변환됩니다.
쿼리에 여러 조인이 포함된 경우 RIGHT OUTER JOIN은 지정된 첫 번째 조인만 가능합니다. N1QL은 선형 조인만 지원하므로(즉, 각 조인의 오른쪽은 단일 키 스페이스여야 함), RIGHT OUTER JOIN이 지정된 첫 번째 조인이 아닌 경우 LEFT OUTER JOIN으로 변환한 후 조인의 오른쪽에 지원되지 않는 여러 키 스페이스가 포함되게 됩니다. 첫 번째 조인 이외의 위치에 RIGHT OUTER JOIN을 지정하면 구문 오류가 반환됩니다.
예 9: 해시 조인을 사용한 ANSI 조인
N1QL은 ANSI JOIN에 대해 두 가지 조인 방법을 지원합니다. ANSI JOIN의 기본 조인 방법은 중첩 루프 조인입니다. 다른 방법은 해시 조인입니다. 해시 조인은 해시 테이블을 사용하여 조인 양쪽의 문서를 일치시킵니다. 해시 조인에는 빌드 쪽과 프로브 쪽이 있으며, 빌드 쪽의 각 문서는 빌드 쪽의 동일 조인 식 값을 기반으로 해시 테이블에 삽입되고, 이후 프로브 쪽의 각 문서는 프로브 쪽의 동일 조인 식 값을 기반으로 해시 테이블에서 조회됩니다. 일치하는 항목이 발견되면 조인 작업이 수행됩니다.
해시 조인은 중첩 루프 조인에 비해 조인이 큰 경우, 예를 들어 조인의 왼쪽에 수만 개 이상의 문서가 있는 경우(필터 적용 후)에 더 효율적일 수 있습니다. 중첩 루프 조인을 사용하는 경우 왼쪽의 각 문서에 대해 오른쪽 인덱스에서 인덱스 스캔을 수행해야 합니다. 왼쪽에서 문서 수가 증가하면 중첩 루프 조인의 효율성이 떨어집니다.
해시 조인의 경우 조인의 작은 쪽은 해시 테이블을 작성하는 데 사용하고 조인의 큰 쪽은 해시 테이블을 프로빙하는 데 사용해야 합니다. 해시 조인은 인메모리 해시 테이블이 필요하므로 중첩 루프 조인보다 더 많은 메모리가 필요하다는 점에 유의해야 합니다. 필요한 메모리의 양은 빌드 측의 문서 수와 각 문서의 평균 크기에 비례합니다.
해시 조인은 다음에서 지원됩니다. 엔터프라이즈 에디션 전용. 해시 조인을 사용하려면 ANSI JOIN의 오른쪽 키 공간에 USE HASH 힌트를 지정해야 합니다. 예 1과 동일한 쿼리를 사용합니다:
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` 공항 JOIN `travel-sample` 경로 USE HASH(build) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
USE HASH(build) 힌트는 N1QL 플래너가 지정된 ANSI JOIN에 대해 해시 조인을 수행하도록 지시하며, 오른쪽 키 공간("경로")은 해시 조인의 빌드 측에서 사용됩니다. 설명을 보면 해시 조인 연산자가 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
{ "1TP5운영자": "해시조인", "build_aliases": [ "경로" ], "build_exprs": [ "커버 ((`경로`.`소스공항`))" ], "on_clause": "(((`에어포트`.`faa`) = 커버 ((`루트`.`소스에어포트`))) 및 (커버 ((`루트`.`타입`)) = \"루트\"))", "probe_exprs": [ "(`airport`.`faa`)" ], "~어린이": { "1TP5운영자": "시퀀스", "~어린이": [ { "1TP5운영자": "IndexScan3", "as": "경로", "커버": [ "커버 ((`경로`.`소스공항`))", "커버 ((`경로`.`목적지공항`))", "커버 ((메타(`경로`).`ID`))" ], "filter_covers": { "커버 ((`경로`.`유형`))": "route" }, "index": "route_airports", "index_id": "F1F4B9FBE85E45FD", "키스페이스": "travel-sample", "네임스페이스": "기본값", "스팬": [ { "범위": [ { "포함": 0, "low": "null" } ] } ], "사용": "gsi" } ] } } |
해시 조인 연산자의 자식 연산자("~child")는 항상 해시 조인의 빌드 쪽입니다. 이 쿼리의 경우, 오른쪽 키 공간 "route"에 대한 인덱스 스캔입니다.
"route" 문서에 액세스하는 경우 더 이상 왼쪽 키 공간("airport")의 정보를 인덱스 검색 키로 사용할 수 없습니다(위 설명 섹션의 "spans" 정보 참조). 중첩 루프 조인과 달리 "경로"에 대한 인덱스 스캔은 더 이상 왼쪽의 개별 문서에 연결되지 않으므로 "공항" 문서의 값을 "경로"에 대한 인덱스 스캔의 검색 키로 사용할 수 없습니다.
위 쿼리에 사용된 USE HASH(build) 힌트는 플래너가 오른쪽 키 공간을 해시 조인의 빌드 측으로 사용하도록 지시합니다. 플래너가 해시 조인의 프로브 측으로 오른쪽 키 스페이스를 사용하도록 USE HASH(probe) 힌트를 지정할 수도 있습니다.
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` 공항 JOIN `travel-sample` 경로 USE HASH(probe) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
설명을 보면 해시조인 연산자를 찾을 수 있습니다:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 |
{ "1TP5운영자": "해시조인", "build_aliases": [ "공항" ], "build_exprs": [ "(`airport`.`faa`)" ], "on_clause": "(((`에어포트`.`faa`) = 커버 ((`루트`.`소스에어포트`))) 및 (커버 ((`루트`.`타입`)) = \"루트\"))", "probe_exprs": [ "커버 ((`경로`.`소스공항`))" ], "~어린이": { "1TP5운영자": "시퀀스", "~어린이": [ { "1TP5운영자": "IntersectScan", "스캔": [ { "1TP5운영자": "IndexScan3", "as": "공항", "index": "공항_도시_국가", "index_id": "8E782FD1B124EEC3", "index_projection": { "primary_key": true }, "키스페이스": "travel-sample", "네임스페이스": "기본값", "스팬": [ { "정확한": true, "범위": [ { "high": "\"산호세\"", "포함": 3, "low": "\"산호세\"" }, { "high": "\"미국\"", "포함": 3, "low": "\"미국\"" } ] } ], "사용": "gsi" }, { "1TP5운영자": "IndexScan3", "as": "공항", "index": "airport_faa", "index_id": "c302afbf811470f5", "index_projection": { "primary_key": true }, "키스페이스": "travel-sample", "네임스페이스": "기본값", "스팬": [ { "정확한": true, "범위": [ { "포함": 0, "low": "null" } ] } ], "사용": "gsi" } ] }, { "1TP5운영자": "Fetch", "as": "공항", "키스페이스": "travel-sample", "네임스페이스": "default" } ] } } |
해시조인의 자식 연산자("~child")는 ANSI JOIN의 왼쪽 키 공간인 "공항"에서 교차 인덱스 스캔을 한 다음 가져 오기 연산자입니다.
USE HASH 힌트는 ANSI JOIN의 오른쪽 키 스페이스에만 지정할 수 있습니다. 따라서 오른쪽 키 공간을 해시 조인의 빌드 측으로 할지 아니면 프로브 측으로 할지 여부에 따라 오른쪽 키 공간에 USE HASH(빌드) 또는 USE HASH(프로브) 힌트를 지정해야 합니다.
해시 조인은 USE HASH(build) 또는 USE HASH(probe) 힌트가 지정된 경우에만 고려됩니다. 해시 조인이 작동하려면 동일성 조인 조건이 필요합니다. 중첩 루프 조인에는 오른쪽 키 공간에 적절한 보조 인덱스가 필요하지만 해시 조인에는 필요하지 않습니다(기본 인덱스 스캔은 해시 조인의 옵션입니다). 그러나 해시 조인이 작동하려면 인메모리 해시 테이블이 필요하므로 해시 조인은 중첩 루프 조인보다 더 많은 메모리가 필요합니다. 또한 해시 조인은 '차단' 작업으로 간주되므로 쿼리 엔진이 첫 번째 조인 결과를 생성하기 전에 해시 테이블 작성을 완료해야 하므로 처음 몇 개의 결과만 빠르게 필요한 쿼리(예: LIMIT 절 사용)의 경우 해시 조인이 적합하지 않을 수 있습니다.
USE HASH 힌트가 지정되었지만 해시 조인을 성공적으로 생성할 수 없는 경우(예: 동일성 조인 조건이 없는 경우) 중첩 루프 조인이 고려됩니다.
예 10: 여러 힌트가 있는 ANSI 조인
이제 ANSI JOIN의 오른쪽에 있는 키 스페이스에 대해 여러 힌트를 지정할 수 있습니다. 예를 들어 USE HASH 힌트를 USE INDEX 힌트와 함께 사용할 수 있습니다.
|
1 2 3 4 |
SELECT DISTINCT route.destinationairport FROM `travel-sample` airport JOIN `travel-sample` route USE HASH(probe) INDEX(route_airports) ON airport.faa = route.sourceairport AND route.type = "route" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
여러 힌트를 함께 사용할 때는 위의 예시처럼 "USE" 키워드를 한 번만 지정하면 됩니다.
해시 사용 힌트와 키 사용 힌트를 결합할 수도 있습니다.
예 11: 다중 조인을 사용하는 ANSI 조인
ANSI JOIN은 서로 연결할 수 있습니다. 예를 들어
필수 인덱스(예제 1과 동일한 route_airports 인덱스):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX airline_iata ON `travel-sample`(iata) WHERE type = "airline"; |
선택적 인덱스(예 1과 동일):
|
1 |
CREATE INDEX airport_city_country ON `travel-sample`(도시, 국가) WHERE type = "airport"; |
쿼리:
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `여행-샘플` 공항 INNER JOIN `여행-샘플` 경로 ON airport.faa = route.sourceairport AND route.type = "route" 내부 `여행 샘플` 항공사에 가입하기 ON route.airline = airline.iata AND airline.type = "항공사" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
쿼리에 USE HASH 힌트가 지정되어 있지 않으므로 설명에 두 개의 NestedLoopJoin 연산자가 표시되어야 합니다.
해시 조인과 중첩 루프 조인을 혼합하려면 ANSI 조인 체인에 있는 조인 중 하나에 USE HASH 힌트를 추가하면 됩니다.
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `여행-샘플` 공항 INNER JOIN `여행-샘플` 경로 ON airport.faa = route.sourceairport AND route.type = "route" INNER JOIN `travel-sample` 항공사 USE HASH(build) ON route.airline = airline.iata AND airline.type = "항공사" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
또는
|
1 2 3 4 5 6 7 |
SELECT DISTINCT airline.name FROM `travel-sample` 공항 INNER JOIN `travel-sample` 경로 USE HASH(probe) ON airport.faa = route.sourceairport AND route.type = "route" 내부 `여행 샘플` 항공사에 가입하기 ON route.airline = airline.iata AND airline.type = "항공사" WHERE airport.type = "공항" AND airport.city = "산호세" AND airport.country = "미국"; |
마지막 쿼리에 대한 시각적 설명은 다음과 같습니다:
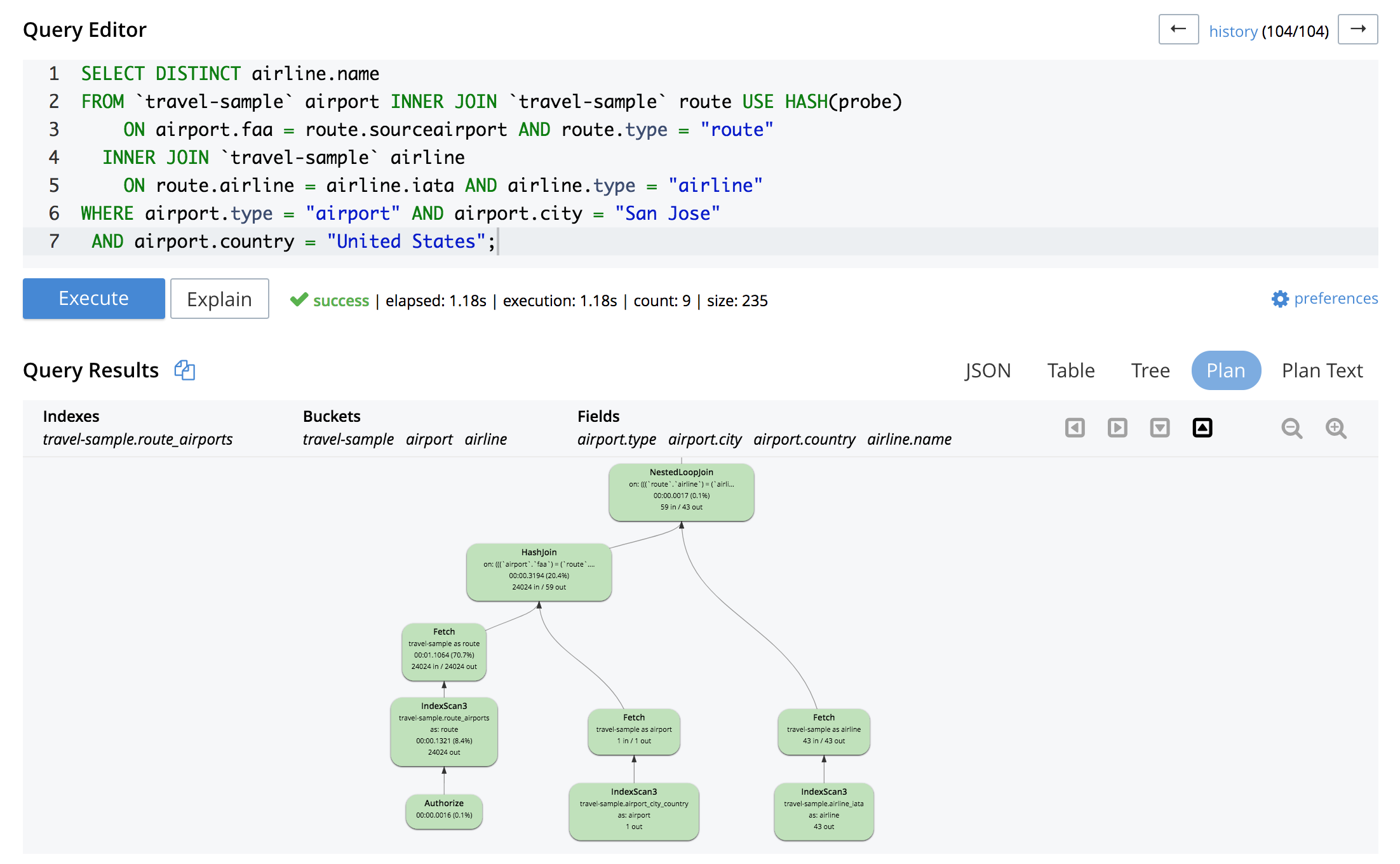
앞서 언급했듯이 N1QL은 선형 조인만 지원합니다. 즉, 각 조인의 오른쪽이 키 스페이스여야 합니다.
예 12: 오른쪽 배열을 포함하는 ANSI 조인
ANSI JOIN은 SQL 표준에서 비롯되었지만, Couchbase N1QL은 JSON 문서를 처리하고 배열은 JSON의 중요한 측면이기 때문에 배열에도 ANSI JOIN 지원을 확장했습니다.
배열 처리의 예는 "default" 버킷을 생성하고 다음 문서를 삽입하세요:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
INSERT INTO default (KEY,VALUE) VALUES("test11_ansijoin", {"c11": 1, "c12": 10, "a11": [ 1, 2, 3, 4 ], "type": "left"}), VALUES("test12_ansijoin", {"c11": 2, "c12": 20, "a11": [ 3, 3, 5, 10 ], "type": "left"}), VALUES("test13_ansijoin", {"c11": 3, "c12": 30, "a11": [ 3, 4, 20, 40 ], "type": "left"}), VALUES("test14_ansijoin", {"c11": 4, "c12": 40, "a11": [ 30, 30, 30 ], "type": "left"}); INSERT INTO default (KEY,VALUE) VALUES("test21_ansijoin", {"c21": 1, "c22": 10, "a21": [ 1, 10, 20], "a22": [ 1, 2, 3, 4 ], "type": "right"}), VALUES("test22_ansijoin", {"c21": 2, "c22": 20, "a21": [ 2, 3, 30], "a22": [ 3, 5, 10, 3 ], "type": "right"}), VALUES("test23_ansijoin", {"c21": 2, "c22": 21, "a21": [ 2, 20, 30], "a22": [ 3, 3, 5, 10 ], "type": "right"}), VALUES("test24_ansijoin", {"c21": 3, "c22": 30, "a21": [ 3, 10, 30], "a22": [ 3, 4, 20, 40 ], "type": "right"}), VALUES("test25_ansijoin", {"c21": 3, "c22": 31, "a21": [ 3, 20, 40], "a22": [ 4, 3, 40, 20 ], "type": "right"}), VALUES("test26_ansijoin", {"c21": 3, "c22": 32, "a21": [ 4, 14, 24], "a22": [ 40, 20, 4, 3 ], "type": "right"}), VALUES("test27_ansijoin", {"c21": 5, "c22": 50, "a21": [ 5, 15, 25], "a22": [ 1, 2, 3, 4 ], "type": "right"}), VALUES("test28_ansijoin", {"c21": 6, "c22": 60, "a21": [ 6, 16, 26], "a22": [ 3, 3, 5, 10 ], "type": "right"}), VALUES("test29_ansijoin", {"c21": 7, "c22": 70, "a21": [ 7, 17, 27], "a22": [ 30, 30, 30 ], "type": "right"}), VALUES("test30_ansijoin", {"c21": 8, "c22": 80, "a21": [ 8, 18, 28], "a22": [ 30, 30, 30 ], "type": "right"}); |
그런 다음 다음 인덱스를 만듭니다:
|
1 2 |
CREATE INDEX default_ix_left on default(c11, DISTINCT a11) WHERE type = "left"; CREATE INDEX default_ix_right on default(c21, DISTINCT a21) WHERE type = "right"; |
조인 조건에 ANSI JOIN의 오른쪽에 배열이 포함되는 경우 오른쪽 키 공간에 배열 인덱스를 만들어야 합니다.
쿼리:
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM 기본값 b1 JOIN 기본값 b2 ON b2.c21 = b1.c11 그리고 b2.a21의 모든 v가 v = b1.c12 END AND b2.type = "right" 만족합니다. WHERE b1.type = "left"; |
조인 조건의 일부는 왼쪽 필드 b1.c12가 오른쪽 배열 b2.a21의 모든 요소와 일치할 수 있음을 지정하는 ANY 절이라는 점에 유의하세요. 이 조인이 제대로 작동하려면 b2.a21에 대한 배열 인덱스(예: 위에서 만든 default_ix_right 인덱스)가 필요합니다.
설명 계획에는 배열 인덱스 default_ix_right에서 하위 연산자가 별개의 스캔인 NestedLoopJoin이 나와 있습니다.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
{ "#operator": "NestedLoopJoin", "alias": "b2", "on_clause": "((((`b2`.`c21`) = (`b1`.`c11`)) 및 (`b2`.`a21`)의 모든 `v`가 (`v` = (`b1`.`c12`)) 끝) 및 ((`b2`.`type`) = \"right\"))"를 만족합니다, "~어린이": { "1TP5운영자": "시퀀스", "~어린이": [ { "1TP5운영자": "DistinctScan", "scan": { "1TP5운영자": "IndexScan3", "as": "b2", "index": "default_ix_right", "index_id": "ef4e7fa33f33dce", "index_projection": { "primary_key": true }, "키 스페이스": "기본값", "네임스페이스": "기본값", "nested_loop": true, "스팬": [ { "정확한": true, "범위": [ { "high": "(`b1`.`c11`)", "포함": 3, "low": "(`b1`.`c11`)" }, { "high": "(`b1`.`c12`)", "포함": 3, "low": "(`b1`.`c12`)" } ] } ], "사용": "gsi" } }, { "1TP5운영자": "Fetch", "as": "b2", "키 스페이스": "기본값", "네임스페이스": "기본값", "nested_loop": true } ] } } |
예 13: 왼쪽 배열을 포함하는 ANSI 조인
왼쪽에 배열이 포함된 ANSI JOIN의 경우 조인을 수행하는 데는 두 가지 옵션이 있습니다.
옵션 1: UNNEST 사용
조인을 수행하기 전에 UNNEST 절을 사용하여 왼쪽 배열을 먼저 평평하게 만듭니다.
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM 기본값 b1 UNNEST b1.a11 AS ba1 JOIN 기본값 b2 ON ba1 = b2.c21 AND b2.type = "right" WHERE b1.c11 = 2 AND b1.type = "left"; |
UNNEST 이후 배열은 개별 필드가 되고 후속 조인은 양쪽의 필드가 있는 "일반" ANSI JOIN과 같습니다.
옵션 2: IN절 사용
또는 IN 절을 조인 조건으로 사용합니다.
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM 기본값 b1 JOIN 기본값 b2 ON b2.c21 IN b1.a11 AND b2.type = "right" WHERE b1.c11 = 2 AND b1.type = "left"; |
IN절은 왼쪽 키 공간("b1.a11")에 있는 배열의 요소가 오른쪽 필드("b2.c21")와 일치할 때 충족됩니다.
두 옵션 사이에는 의미상 차이가 있다는 점에 유의하세요. 배열에 중복된 문서가 있는 경우 UNNEST 옵션은 중복 여부를 고려하지 않고 배열의 요소 수만큼 왼쪽 문서를 평탄화하므로 중복된 결과가 나올 수 있지만, IN 절 옵션은 배열에 중복된 요소가 있는 경우 중복된 결과를 생성하지 않습니다. 또한 좌측 외부 조인을 수행하면 UNNEST 옵션으로 배열을 평탄화하기 때문에 보존되는 문서 수가 달라질 수 있습니다. 따라서 사용자는 쿼리에 필요한 의미를 반영하는 옵션을 선택하는 것이 좋습니다.
예 14: 양쪽의 배열을 포함하는 ANSI 조인
흔하지는 않지만 조인의 양쪽이 배열인 경우 ANSI JOIN을 수행할 수 있습니다. 이러한 경우 위에서 설명한 기술을 조합하여 사용할 수 있습니다. 오른쪽의 배열을 처리하려면 배열 인덱스를 사용하고, 왼쪽의 배열을 처리하려면 UNNEST 옵션 또는 IN절 옵션을 사용합니다.
옵션 1: UNNEST 절 사용
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM 기본값 b1 UNNEST b1.a11 AS ba1 JOIN 기본값 b2 ON b2.c21 = b1.c11 그리고 b2.a21의 모든 v가 v = ba1 END AND b2.type = "right"를 만족합니다. WHERE b1.type = "left"; |
옵션 2: IN절 사용
|
1 2 3 4 |
SELECT b1.c11, b2.c21, b2.c22 FROM 기본값 b1 JOIN 기본값 b2 ON b2.c21 = b1.c11 그리고 b2.a21의 모든 v가 b1.a11의 v를 만족하고 b2.type = "오른쪽" WHERE b1.type = "left"; |
다시 말하지만 두 옵션은 의미적으로 동일하지 않으며 서로 다른 결과를 제공할 수 있습니다. 원하는 의미를 반영하는 옵션을 선택하세요.
예 15: 조회 조인 마이그레이션
N1QL은 이전 버전과의 호환성을 위해 조회 조인 및 인덱스 조인을 계속 지원하지만, 동일한 쿼리에서 ANSI JOIN과 조회 조인 또는 인덱스 조인을 혼합할 수는 없습니다. 기존 쿼리를 조회 조인 및 인덱스 조인을 사용하는 것에서 ANSI JOIN 구문으로 변환할 수 있습니다. 이 예에서는 조회 조인을 ANSI JOIN 구문으로 변환하는 방법을 보여 줍니다.
쿼리 속도를 높이려면 다음 인덱스를 생성합니다(예제 1과 동일):
|
1 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; |
조회 조인 구문을 사용하는 쿼리입니다(ON KEYS 절을 참고하세요):
|
1 2 3 4 |
SELECT airline.name FROM `여행-샘플` 경로 JOIN `여행-샘플` 항공사 ON 키 route.airlineid WHERE route.type = "route" AND route.sourceairport = "SFO" AND route.destinationairport = "JFK"; |
조회 조인에서 조인의 왼쪽("route")은 조인의 오른쪽("airline")에 대한 문서 키를 생성해야 하며, 이는 ON KEYS 절을 통해 수행됩니다. 조인 조건(구문에서 암시됨)은 다음과 같습니다. route.airlineid = 메타(항공사).id를 사용하여 동일한 쿼리를 지정할 수 있으므로 ANSI JOIN 구문을 사용하여 동일한 쿼리를 지정할 수 있습니다:
|
1 2 3 4 |
SELECT airline.name FROM `여행-샘플` 경로 JOIN `여행-샘플` 항공사 ON route.airlineid = meta(항공사).id WHERE route.type = "route" AND route.sourceairport = "SFO" AND route.destinationairport = "JFK"; |
이 예제에서는 ON KEYS 절에 단일 문서 키가 포함되어 있습니다. ON KEYS 절에 문서 키 배열이 포함될 수 있으며, 이 경우 변환된 ON 절은 동등 절이 아닌 IN 절의 형태가 됩니다. 각 노선 문서에 항공사에 대한 문서 키 배열이 있다고 가정한 다음 원래의 ON KEYS 절을 가정해 보겠습니다:
|
1 |
온키즈 route.airlineids |
로 변환할 수 있습니다:
|
1 |
ON 메타(항공사).id IN route.airlineids |
예 16: 인덱스 조인 마이그레이션
이 예에서는 인덱스 조인을 ANSI JOIN 구문으로 변환하는 방법을 보여 줍니다.
필수 인덱스(예 3과 동일):
|
1 |
CREATE INDEX route_airlineid ON `travel-sample`(airlineid) WHERE type = "route"; |
선택적 인덱스(예 3과 동일):
|
1 |
CREATE INDEX airline_name ON `travel-sample`(name) WHERE type = "airline"; |
인덱스 조인 구문을 사용하여 쿼리합니다(ON KEY ... FOR ... 절을 참고):
|
1 2 3 4 |
SELECT count(*) FROM `여행-샘플` 항공사 JOIN `여행-샘플` 경로 ON 키 route.airlineid 항공사의 경우 WHERE airline.type = "항공사" AND route.type = "노선" AND airline.name = "유나이티드 항공"; |
인덱스 조인에서 왼쪽("airline")의 문서 키는 오른쪽("route")의 문서 키에 해당하는 표현식("route.airlineid", ON KEY 절에 나타남)의 인덱스를 검색하는 데 사용됩니다(FOR 절에 나타나는 "airline"). 조인 조건(구문에서 암시됨)은 다음과 같습니다. route.airlineid = 메타(항공사).id를 사용하여 동일한 쿼리를 지정할 수 있으므로 ANSI JOIN 구문을 사용하여 동일한 쿼리를 지정할 수 있습니다:
|
1 2 3 4 |
SELECT count(*) FROM `여행-샘플` 항공사 JOIN `여행-샘플` 경로 ON route.airlineid = meta(항공사).id WHERE airline.type = "항공사" AND route.type = "노선" AND airline.name = "유나이티드 항공"; |
예 17: ANSI NEST
Couchbase N1QL은 NEST 작업을 지원합니다. 이전에는 각각 조회 조인 및 인덱스 조인과 유사한 룩업 네스트 또는 인덱스 네스트를 사용하여 NEST를 수행할 수 있었습니다. ANSI JOIN을 지원하면 유사한 구문, 즉 ON KEYS(조회 네스트) 또는 ON KEY ... FOR ...(인덱스 네스트) 절 대신 ON 절을 사용하여 NEST 연산을 수행할 수도 있습니다. 이 새로운 변형을 ANSI NEST라고 합니다.
필수 인덱스(예제 1과 동일한 route_airports 인덱스, 예제 4와 동일한 route_airline_distance 인덱스):
|
1 2 |
CREATE INDEX route_airports ON `travel-sample`(sourceairport, destinationairport) WHERE type = "route"; CREATE INDEX route_airline_distance ON `travel-sample`(항공사, 거리) WHERE type = "route"; |
선택적 인덱스:
|
1 |
CREATE INDEX airline_country_iata_name ON `travel-sample`(국가, iata, 이름) WHERE type = "항공사"; |
쿼리:
|
1 2 3 4 |
SELECT airline.name, ARRAY {"destination": r.destinationairport} FOR 경로의 r을 목적지로 END FROM `여행-샘플` 항공사 NEST `여행-샘플` 경로 ON airline.iata = route.airline AND route.type = "route" AND route.sourceairport = "SFO" WHERE airline.type = "항공사" AND airline.country = "미국"; |
보시다시피 ANSI NEST의 구문은 ANSI JOIN의 구문과 매우 유사합니다. 하지만 중첩에는 한 가지 특이한 속성이 있습니다. 정의상 중첩 연산은 각 왼쪽 문서에 대해 일치하는 모든 오른쪽 문서의 배열을 생성하므로, 이 쿼리에서 오른쪽 키 공간에 대한 참조인 "route"는 참조 위치에 따라 다른 의미를 갖습니다. ON 절은 NEST 작업의 일부로 평가되므로 "route"에 대한 참조는 단일 문서를 참조하는 것입니다. 반면에 투영 절 또는 WHERE 절의 참조는 NEST 연산 후에 평가되므로 "route"에 대한 참조는 중첩된 배열을 의미하므로 배열로 취급해야 합니다. 위 쿼리의 투영 절에는 배열 내의 각 개별 문서에 액세스하기 위한 FOR 절이 있는 ARRAY 구문이 있습니다(즉, "route"에 대한 참조는 이제 배열 컨텍스트에 있습니다).
요약
이전에 지원되던 조회 조인 및 인덱스 조인(둘 다 문서 키로만 조인해야 함)에 비해, ANSI JOIN은 Couchbase N1QL에서 훨씬 더 유연하게 조인 작업을 수행할 수 있도록 해줍니다. 위의 예는 쿼리에서 ANSI JOIN을 사용할 수 있는 다양한 방법을 보여줍니다. ANSI JOIN은 관계형 세계에서 널리 사용되기 때문에, Couchbase N1QL에서 ANSI JOIN을 지원하면 관계형 데이터베이스에서 Couchbase N1QL로 애플리케이션을 훨씬 더 쉽게 마이그레이션할 수 있습니다.
드디어 :)
멋진 예시!