This post is the fourth part of a multi-part series exploring composite vector indexing in Couchbase. If you missed the previous posts, be sure to catch up on Part 1, Part 2 and Part 3.
The series will cover:
- Why composite vector indexes matter, including concepts, terminology, and developer motivation. A Smart Grocery Recommendation System will be used as a running example.
- How composite vector indexes are implemented inside the Couchbase Indexing Service.
- How ORDER BY pushdown works for composite vector queries.
- Real-world performance behavior and benchmarking results.
Part 4: Performance Analysis of Composite Vector Indexes
Agentic applications and AI workloads increasingly require efficient vector search. Traditional approximate nearest neighbor (ANN) search systems can struggle at scale, with challenges such as memory consumption, index build times, and real-time update mechanisms.
Composite Vector Indexes (CVI) are designed for filtered ANN workloads, where scalar predicates reduce the candidate set before approximate vector search. For pure vector workloads at a very large scale, Couchbase also provides Hyperscale Vector Indexes. For best practices check out our documentation here.
This post focuses on the performance behavior of Composite Vector Indexes for filtered ANN workloads. Building on the concepts and execution model introduced in Parts 1 through 3, we now look at how throughput and p95 latency change as scalar selectivity varies on large-scale datasets.
In this post, selectivity % refers to how much of the dataset remains relevant after the scalar portion of the query constrains the search space. Lower selectivity means a narrower slice of the dataset qualifies, which in turn reduces the amount of vector work the system must perform.
Build Performance
In an internal build benchmark, CVI was able to build an index on 1 billion 128-dimensional vectors in 7 hours. This demonstrates the indexing architecture and use of modern hardware.
The build performance was measured on the following infrastructure:
Processor: 32-core AMD-EPYC-7643
Memory: 128GB RAM
Storage: Samsung PM1743 Enterprise SSD 15.36TB
Dataset: SIFT benchmark data
This shows that indexing billions of vectors for production workloads is practical.
Query Performance: Speed and Precision Combined
CVI provides query performance with high recall. Using the 100M SIFT dataset with SQ8 quantization and one leading scalar field, CVI achieved 75% recall@10 across various selectivity percentages, with measured throughput and latency characteristics.
Throughput improves as selectivity narrows
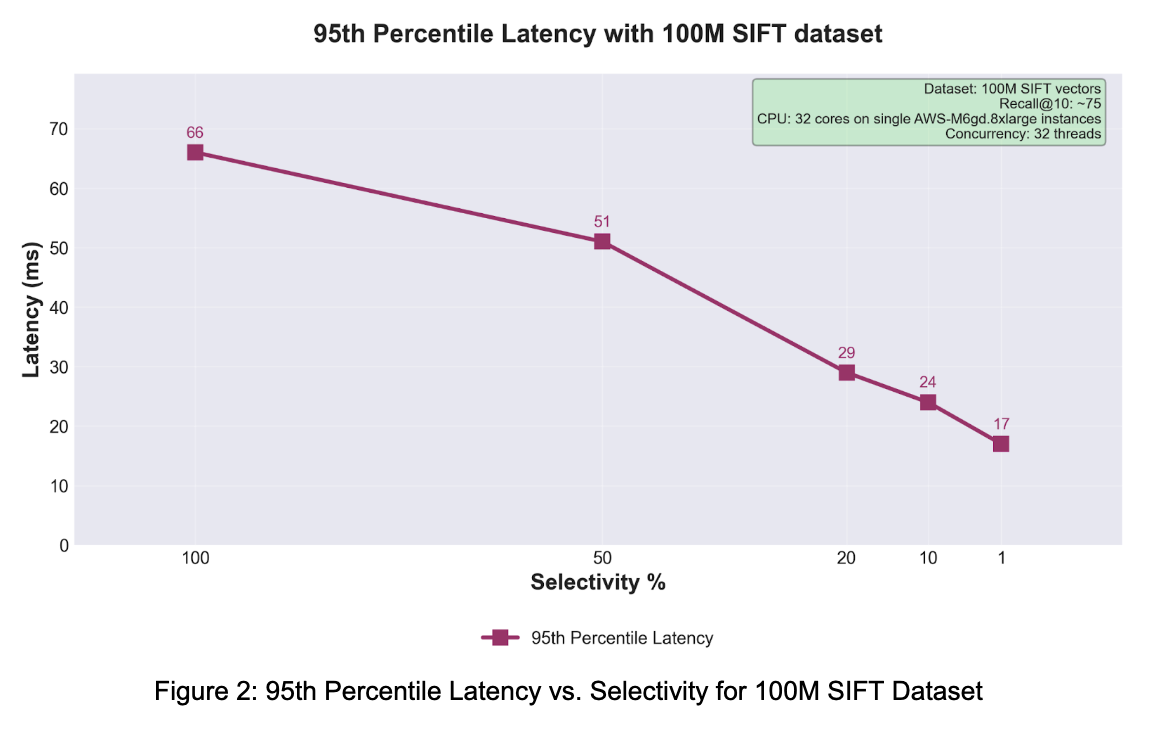
The throughput and latency curves tell the same story from two angles. Narrower scalar constraints reduce the amount of work flowing through the execution path, which improves both system throughput and tail behavior. For applications that naturally include hard constraints such as category, brand, tenant, region, language, or compliance boundary this behavior is exactly where Composite Vector Indexes become compelling.
Test Setup
Definition
|
1 |
CREATE INDEX `vector-idx` on `bucket-1`.`_default`.`_default` (scalar, emb Vector) WITH {'dimension':128, 'similarity':'L2', 'description':'IVF,SQ8'} |
Query
|
1 2 3 4 |
SELECT meta().id FROM `bucket-1`.`_default`.`_default` WHERE scalar = 'eligible' ORDER BY ANN_DISTANCE(emb, , 'L2', ) LIMIT 10 |
The scalar field is populated in the data as needed for the selectivity and <nprobes> is adjusted to get expected recall.
Why the Curves Look This Way
CVI’s performance is influenced by several architectural features:
- Order-aware scanning
- CVI uses an order-aware scan pipeline that leverages scalar predicates combined with vector similarity search, enabling efficient access patterns and minimizing I/O operations.
- Parallel processing architecture
- The system uses parallelism across centroids, allowing multiple scan workers to operate concurrently on different partitions of the vector space.
- SIMD-accelerated distance computation
- CVI uses SIMD operations through the FAISS library to accelerate similarity evaluations and minimize computational overhead.
- HNSW routing layer
- The Hierarchical Navigable Small World (HNSW) routing layer enables identification of relevant centroids, reducing the search space.
Example Applications
CVI’s performance characteristics are applicable to a range of use cases:
- E-commerce and product recommendations
- Product similarity search with price, brand, and category filters
- Content discovery and search
- Document and media similarity search with metadata constraints
- Fraud detection and risk assessment
- Anomaly detection in transaction patterns with temporal constraints
- Personalized marketing
- Customer segmentation and targeted recommendations
Conclusion
The first three parts of this series explained why Composite Vector Indexes matter, how they are implemented, and how they enable flexible ORDER BY pushdown for mixed scalar-plus-vector queries. This final part shows the performance payoff of that design.
On the 100M SIFT benchmark with SQ8 quantization, throughput increased from 800 QPS at 100% selectivity to 2853 QPS at 1% selectivity, while p95 latency improved from 66 ms to 17 ms. In a separate internal build benchmark, Composite Vector Indexes built an index over 1 billion 128-dimensional vectors in about 7 hours on modern commodity server hardware.
For filtered ANN workloads, that is the core value proposition of Composite Vector Indexes: they let applications combine scalar constraints and semantic similarity in one index structure, while still delivering strong throughput and low tail latency at scale.