Couchbase se ha convertido en una opción popular para Casos de uso de IoTgracias a su flexibilidad multimodelo capacidades de gestión de datos.
Recientemente, estuve trabajando con un cliente de la industria de cruceros que tenía un reto único - necesitaban Couchbase para recibir y almacenar actualizaciones frecuentes de muchos sensores que registran lecturas en su flota de barcos. Estas lecturas podrían llegar a Couchbase fuera de orden cronológico. ¿Cómo podían asegurarse de que una nueva lectura de un sensor sólo se almacenara si tenía una marca de tiempo posterior a la lectura anterior?
Cada sensor tiene una clave única que corresponde a la última lectura del sensor. Una lectura de las 10:43:00 AM no podría sobrescribir una lectura de las 10:42:30 AM, aunque esta última se hubiera recibido más tarde. A continuación se muestran algunas lecturas de ejemplo y su orden de procesamiento (tenga en cuenta que las marcas de tiempo no están necesariamente en orden cronológico):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
id: "C-DI_Nautical_Speed" { "speed": 15, "unit": "knots", "timeStamp": "2023-03-10 10:43:00 AM" } id: "C-DI_Nautical_Speed" { "speed": 15.1, "unit": "knots", "timeStamp": "2023-03-10 11:43:00 AM" }, id: "C-DI_Nautical_Speed" { "speed": 14.9, "unit": "knots", "timeStamp": "2023-03-10 10:42:30 AM" } |
En esta entrada de blog, exploraremos cómo las opciones multimodelo de Couchbase pueden ayudar a abordar este escenario y gestionar eficientemente las actualizaciones de datos de los sensores.
¿Qué es el multimodelo?
Couchbase es quizás la base de datos multimodelo original, ya que combina el almacenamiento en caché en memoria con la persistencia de datos JSON para proporcionar un enfoque flexible a la gestión de datos. Couchbase puede manejar múltiples tipos de datos, como datos estructurados, semiestructurados y no estructurados, en la misma instancia de base de datos.
Con el tiempo, Couchbase ha añadido SQL, Búsqueda de texto completo (FTS), Eventos, Analítica múltiples modelos para acceder, indexar e interactuar con el mismo conjunto de datos. Este enfoque multimodelo puede hacer que Couchbase sea más flexible que las bases de datos tradicionales, pero también puede requerir un poco más de reflexión sobre las compensaciones en comparación con los sistemas heredados (que sólo tienen una forma de interactuar con los datos).
Opciones multimodelo para actualizar las lecturas de los sensores
A la hora de actualizar las lecturas de los sensores para este caso de uso en la base de datos multimodelo de Couchbase, hay que tener en cuenta varios enfoques:
-
- API clave-valor con bloqueo optimista o pesimista
- API clave-valor con transacción ACID
- Sentencia UPDATE de SQL
- Función Eventing OnUpdate
Todas estas opciones tienen sus propias ventajas y desventajas en términos de rendimiento, complejidad y requisitos. La elección del mejor enfoque dependerá de factores como el tamaño y la frecuencia de las actualizaciones, el nivel de concurrencia y los requisitos generales de rendimiento.
En última instancia, el mejor enfoque sólo puede determinarse a través de pruebas en el mundo real con datos en vivo o una buena aproximación a los datos en vivo. Examinando las compensaciones y experimentando con las diferentes opciones, los desarrolladores pueden identificar el método más eficaz para actualizar las lecturas de los sensores en la base de datos multimodelo de Couchbase.
Es importante señalar que en muchos de estos escenarios, asumimos que el documento del sensor ya existe (que será el escenario más común en un estado estacionario). Cuando ese no sea el caso, podemos cambiar el sustituir o actualización operación a upsert para asegurarse de que el documento se crea si no existe. (Como alternativa, podría "sembrar" la colección con un documento para cada sensor).
Dicho esto, examinemos cada posibilidad.
API clave-valor con bloqueo optimista o pesimista
Una forma de actualizar las lecturas de los sensores en la base de datos multimodelo de Couchbase es mediante el bloqueo optimista o pesimista. Este mecanismo de bloqueo, presente en Couchbase desde hace mucho tiempo, utiliza una técnica llamada CAS (comparar e intercambiar) para garantizar la actualización condicional de documentos individuales.
El valor CAS es un número arbitrario que cambia cada vez que se modifica un documento. Al hacer coincidir los valores CAS, los desarrolladores pueden actualizar condicionalmente los datos de los sensores con una sobrecarga mínima. En esta sección, exploraremos cómo se puede utilizar el bloqueo optimista y pesimista para este caso de uso de datos de sensores.
Bloqueo optimista
El bloqueo optimista es un método sencillo para actualizar los datos de los sensores en Couchbase, con sólo tres pasos:
En primer paso consiste en recuperar el documento por clave, que incluye el valor del documento y sus metadatos (incluido el valor CAS).
Una vez recuperado, el segundo paso es comprobar si la marca de tiempo es más antigua que la marca de tiempo entrante.
Si es así, el tercer paso consiste en sustituir el documento por el nuevo valor y enviar con él el valor CAS.
Aquí es donde entra la parte "optimista". Si los valores CAS coinciden, la operación tiene éxito y los datos del sensor se actualizan. Sin embargo, si el valor CAS no coincide, significa que los datos del sensor han sido actualizados (por algún otro hilo/proceso) desde la última operación de lectura. En este caso, tiene la opción de reintentar la operación desde el principio. Si no espera que el documento del sensor específico se actualice con frecuencia, entonces el bloqueo optimista es el camino a seguir (ya que los reintentos serían poco frecuentes).
He aquí un ejemplo de bloqueo optimista con una lógica de reintento sencilla:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// get existing sensor reading var currentDoc = await _collection.GetAsync(sensorId); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); var retries = 3; while (retries > 0) { try { await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } catch (CasMismatchException) { Console.WriteLine($"CAS mismatch. Retries remaining: {retries}"); retries--; } } Console.WriteLine("Retry max exceeded. Sensor reading was not updated."); } else { Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
Bloqueo pesimista
Cierre pesimista es otra forma de abordar el mismo problema. Al igual que el bloqueo optimista, consta de tres pasos, pero con algunas ligeras diferencias.
En primer paso es obtener y bloquear un documento por clave, tomando nota del valor CAS. A diferencia del bloqueo optimista, en el que el documento simplemente se lee, en el bloqueo pesimista el documento se bloquea explícitamente. Esto significa que ningún otro proceso puede realizar cambios en el documento hasta que se desbloquee.
En el segundo pasoAl igual que en el bloqueo optimista, se comprueba si la marca de tiempo es más antigua que la marca de tiempo entrante.
Si lo es, entonces en el tercer pasoel documento se sustituye por el nuevo valor y se envía con el valor CAS.
En el paso 1 del bloqueo pesimista, también hay que especificar una ventana de tiempo de espera. ¿Por qué? Porque es posible que el paso 3 nunca llegue a producirse debido a un error o un bloqueo, y el documento tenga que desbloquearse finalmente.
Si espera que el documento del sensor se actualice mucho, pesimista podría ser el mejor enfoque. Pero debido al bloqueo, podría haber una latencia reducida en otros procesos esperando a que el documento se desbloquee.
Para ilustrarlo, he aquí un ejemplo de bloqueo pesimista en acción:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// get current sensor data var maxLockTime = TimeSpan.FromSeconds(30); var currentDoc = await _collection.GetAndLockAsync(sensorId, maxLockTime); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps against new reading if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } else { await _collection.UnlockAsync(sensorId, currentDocCas); Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
Ventajas y desventajas del bloqueo CAS
Cuando se trata del bloqueo CAS, hay que tener en cuenta ciertas ventajas y desventajas. El bloqueo optimista funciona bien cuando los conflictos son poco frecuentes, pero tendrás que implementar una lógica de reintento adecuada para gestionar los posibles reintentos.
Para ayudar con esta compensación, se podrían utilizar reintentos más avanzados o especializados. Por ejemplo, en este caso de uso, puede ser aceptable "rendirse" y descartar una lectura entrante del sensor si ha habido muchos reintentos y/o la lectura es muy antigua.
El bloqueo pesimista, por otro lado, es un enfoque "más seguro", pero requiere una comprensión clara de las implicaciones de rendimiento del bloqueo. El bloqueo puede aumentar la latencia en otros procesos que tengan que esperar a que se desbloquee el documento.
Transacción ACID
Otra posible solución al problema de la actualización del sensor es utilizar una transacción ACID. Este enfoque puede ser excesivo para la actualización de un solo documento en este caso de uso, pero podría ser útil en diferentes casos de uso donde múltiples documentos necesitan ser actualizados atómicamente.
Uno de los retos de los datos de los sensores es que pueden llegar a gran velocidad. En el tiempo que transcurre entre la comprobación de los datos actuales y la actualización con los datos entrantes del sensor, podría estar llegando otra lectura. Para evitar este problema, se puede utilizar una transacción ACID para actualizar los datos condicionalmente.
El ejemplo de código abajo demuestra como usar una transacción ACID para actualizar un documento de sensor. La transacción asegura que sólo una operación de actualización puede ocurrir a la vez por sensor, previniendo que múltiples lecturas de sensor entrantes interfieran unas con otras.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var transaction = Transactions.Create(_cluster, TransactionConfigBuilder.Create() .DurabilityLevel(DurabilityLevel.None)); // set to 'none' because I'm using a single-node dev cluster // for more details see: https://docs.couchbase.com/dotnet-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html await transaction.RunAsync(async (context) => { // get existing sensor reading var currentDoc = await context.GetAsync(_collection, sensorId); var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine("Incoming sensor reading is newer. Updating."); await context.ReplaceAsync(currentDoc, newSensorReading); } else { Console.WriteLine("Incoming sensor reading is not new. Ignoring."); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } }); |
Ventajas y desventajas de las transacciones ACID
La API key-value debería usarse siempre que sea posible para maximizar el rendimiento. Sin embargo, el uso de una transacción ACID distribuida en Couchbase conllevará cierta sobrecarga debido a las operaciones clave-valor adicionales ejecutadas (entre bastidores) para coordinar la transacción. Dado que los datos en Couchbase se distribuyen automáticamente, es probable que las operaciones se coordinen a través de una red a múltiples servidores.
Un beneficio de usar una transacción ACID sobre una operación CAS es que las librerías de transacciones de Couchbase ya tienen incorporada una sofisticada lógica de reintento. Esta puede ser una forma de evitar escribir tu propia lógica de reintento. Adicionalmente, una transacción ACID es recomendada (probablemente requerida, de hecho) si un caso de uso involucra actualizar múltiples documentos de sensores.
Operación de actualización SQL
Otro método para realizar actualizaciones condicionales es utilizar una consulta UPDATE de SQL++.
He aquí un ejemplo de aplicación:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var retries = 3; while (retries > 0) { try { await _cluster.QueryAsync<dynamic>(@"UPDATE sensordata s USE KEYS $sensorId SET s.speed = $newSpeed, s.unit = $newUnit, s.timeStamp = $newTimeStamp WHERE DATE_DIFF_STR($newTimeStamp, s.timeStamp, 'millisecond') > 0", options => { options.Parameter("sensorId", sensorId); options.Parameter("newSpeed", sensorReading.Speed); options.Parameter("newUnit", sensorReading.Unit); options.Parameter("newTimeStamp", sensorReading.TimeStamp); }); return; } c atch (CasMismatchException) { Console.WriteLine($"UPDATE CAS mismatch, tries remaining: {retries}"); retries--; } } Console.WriteLine("Max retries exceeded, sensor not updated"); |
(Por cierto, el uso de una marca de tiempo de época probablemente proporcionará un mejor rendimiento).
Como habrás adivinado por el código, la consulta SQL++ utiliza CAS entre bastidores, al igual que se hace con el ejemplo anterior de la API KV.
Ventajas y desventajas de SQL
El enfoque de SQL++ para las actualizaciones condicionales tiene algunas desventajas. Aunque la UTILIZAR TECLAS ayuda a eliminar la necesidad de un índice, la consulta aún debe ser analizada por el servicio de consulta, que implica muchos pasos. Esto puede suponer una presión añadida para el sistema si otros componentes ya están utilizando el servicio de consulta.
En general, dado que el enfoque SQL++ es muy similar a la API KV con la sobrecarga añadida de analizar la consulta, puede que no sea la mejor opción a menos que tenga una necesidad específica de lógica compleja expresada en SQL++ o si utilizar la API KV no es una opción.
Eventos
El último enfoque que quiero tratar es el uso del Eventing.
Eventing en Couchbase consiste en escribir funciones JavaScript que respondan a eventos de cambio de datos de forma asíncrona y desplegarlas en el cluster de Couchbase.
Para este caso de uso en particular, creo que el uso de una colección de "puesta en escena" como una ubicación para las lecturas del sensor inicialmente es el camino a seguir. Esta es la secuencia:
-
- Las lecturas entrantes de los sensores se escriben en una colección de "puesta en escena".
- Un evento OnUpdate responde a las nuevas lecturas de los sensores.
- En OnUpdate comprueba las marcas de tiempo con el documento correspondiente de la colección "actual
- Si la marca de tiempo es más actual, se actualiza el documento de la colección "actual".
OnUpdate se ejecutará cuando se cree un documento o actualizado, por lo que está bien dejar el documento antiguo en la puesta en escena (esto simplifica el código de eventos). Además, se puede establecer un TTL en la colección, de modo que si la lectura de un sensor no se actualiza en un tiempo, se limpiará automáticamente.
He aquí un ejemplo de una función eventing que funciona con este diseño:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
function OnUpdate(doc, meta) { // Only process documents with a "timestamp" if (doc.timestamp) { // Extract timestamp and sensor ID from the staged document var stagedTimestamp = doc.timestamp; // note that this will loop indefinitely // but you can also limit it to a certain number of reties if you wish while(true) { // Get the current document for the same sensor ID from the "destination" collection var currentDoc = dst_col[meta.id]; // If there is no current document, or the staged timestamp is later than the current timestamp, update the current document if (!currentDoc || stagedTimestamp > currentDoc.timestamp) { // dst_col is a READ+WRITE ALIAS dst_col[meta.id] = doc; // the whole document is overwritten, but you can also choose to override certain fields if you wish } // src_col is a READ ALIAS var result = couchbase.get(src_col, meta); if (result.success) { if (result.meta.cas == meta.cas) { // the document was unchanged in the stage collection we are done break; } doc = result.doc; stagedTimestamp = doc.timestamp; } else { if (result.error.key_not_found) { // this might be okay, assuming 'staging' collection gets cleaned up or has a TTL // again, this will depend on what kind of retry logic you have break; } else { log('failure could not read stage adv. get: id',meta.id,'result',result); } } } } } |
Y aquí está la configuración para esa función de eventos:
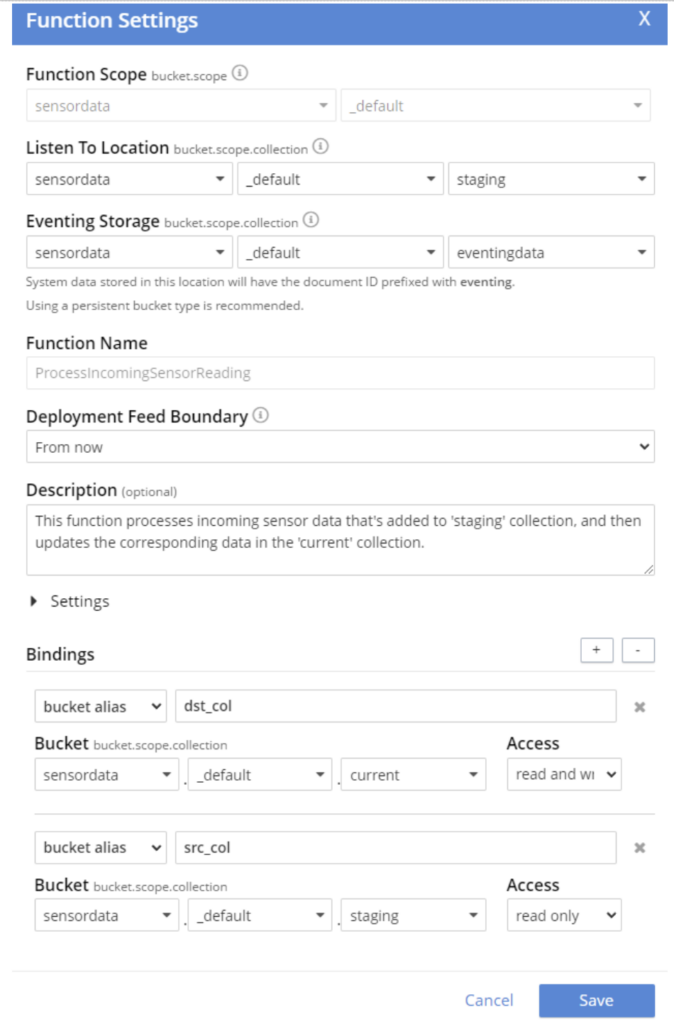
Compromisos en las pruebas
De nuevo, observe que en este código se utiliza un bloqueo CAS optimista. De hecho, casi se podría decir que se trata de una versión JavaScript del código que utiliza la API KV anterior.
Una diferencia clave es que esta función se ejecuta en el propio clúster de Couchbase. Y este es el beneficio clave de eventing: no importa de dónde vengan los datos del sensor, la función Eventing de Couchbase se asegurará de que sean procesados. Es mantener la lógica cerca de los datos. Si tienes dos o más clientes que usan la API KV en su lugar, eso significa que necesitas dos o más implementaciones del mismo código. Esto puede conducir a problemas cuando la lógica cambia, ya que tendrá que ser actualizado en varios lugares.
Sin embargo, al igual que con SQL++, Eventing tiene algunos gastos generales que están involucrados. En este caso, múltiples colecciones, y el propio servicio de eventing. Típicamente esto podría implicar un nodo adicional de Couchbase en producción. Además, Eventing no está disponible actualmente en Couchbase Server Community.
Resumen
Couchbase es una base de datos multimodelo que ofrece opciones y compensaciones para tu caso de uso. En este post, se cubrió el caso de uso de actualizaciones de datos de sensores con 4 patrones de acceso a datos diferentes, cada uno con sus pros y sus contras:
-
- API de KV: eficaz y sencilla, pero puede requerir cierta lógica de reintento.
- Transacciones ACID: fiables, pero con sobrecarga
- SQL++ - familiar, declarativo, pero tiene sobrecarga de análisis y ejecución de consultas
- Eventing: cerca de los datos, consolida la lógica, pero tiene la sobrecarga del servicio de eventing y las colecciones adicionales.
Todos los ejemplos de código son disponible en GitHub.
¿Has pensado en un enfoque diferente? Deja un comentario a continuación, o compártelo en el Couchbase Discord.