
Couchbase has become a popular choice for IoT use cases, thanks to its flexible multi-model data management capabilities.
Recently, I was working with a customer in the cruise industry that had a unique challenge – they needed Couchbase to receive and store frequent updates from many sensors that record readings on their fleet of ships. These readings could potentially come to Couchbase out of chronological order. How can they ensure that a new sensor reading could only be stored if it had a later timestamp than the previous reading?
Each sensor has a unique key that corresponds to the latest sensor reading. A reading from 10:43:00 AM could not overwrite a reading from 10:42:30 AM, even if the latter had been received later. Below are some sample readings and their order of processing (note the timestamps are not necessarily in chronological order):
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
id: “C-DI_Nautical_Speed” { “speed”: 15, “unit”: “knots”, “timeStamp”: “2023-03-10 10:43:00 AM” } id: “C-DI_Nautical_Speed” { “speed”: 15.1, “unit”: “knots”, “timeStamp”: “2023-03-10 11:43:00 AM” }, id: “C-DI_Nautical_Speed” { “speed”: 14.9, “unit”: “knots”, “timeStamp”: “2023-03-10 10:42:30 AM” } |
In this blog post, we’ll explore how Couchbase’s multi-model options can help tackle this scenario and efficiently manage sensor data updates.
What is Multi-Model?
Couchbase is perhaps the original multi-model database, as it combines memory-first caching with JSON data persistence to provide a flexible approach to data management. Couchbase can handle multiple data types, such as structured, semi-structured, and unstructured data, in the same database instance.
Over time, Couchbase has added SQL++, Full Text Search (FTS), Eventing, Analytics tools: multiple models for accessing, indexing, and interacting with the same pool of data. This multi-model approach can make Couchbase more flexible than traditional databases, but it can also require a little more thought about tradeoffs compared to those legacy systems (that might only have one way to interact with data).
Multi-Model Options for Updating Sensor Readings
When it comes to updating sensor readings for this use case in Couchbase’s multi-model database, there are several approaches to consider:
- Key-value API with optimistic or pessimistic locking
- Key-value API with ACID transaction
- SQL++ UPDATE statement
- Eventing OnUpdate function
All of these options have their own set of advantages and trade-offs in terms of performance, complexity, and requirements. Choosing the best approach will depend on factors such as the size and frequency of the updates, the level of concurrency, and the overall performance requirements.
Ultimately, the best approach can only be determined through real-world testing with live data or a good approximation of live data. By examining the trade-offs and experimenting with the different options, developers can identify the most effective method for updating sensor readings in Couchbase’s multi-model database.
It’s important to note that in many of these scenarios, we assume that the sensor document already exists (which will be the most common scenario in a steady state). When that’s not the case, we can change the replace or update operation to upsert to ensure that the document is created if it does not exist. (Alternatively, you could “seed” the collection with a document for each sensor).
All that being said, let’s examine each possibility.
Key-value API with Optimistic or Pessimistic Locking
One approach to updating sensor readings in Couchbase’s multi-model database is through optimistic or pessimistic locking. This locking mechanism, which has been present in Couchbase for a long time, uses a technique called CAS (compare and swap) to ensure conditional updates of individual documents.
The CAS value is an arbitrary number that changes every time a document changes. By matching CAS values, developers can conditionally update sensor data with minimal overhead. In this section, we will explore how optimistic and pessimistic locking can be used for this sensor data use case.
Optimistic Locking
Optimistic locking is a straightforward approach to updating sensor data in Couchbase, with only three steps required:
The first step involves retrieving the document by key, which includes the document value and its metadata (including the CAS value).
Once retrieved, the second step is to check if the timestamp is older than the incoming timestamp.
If it is, the third step involves replacing the document with the new value and submitting the CAS value with it.
Here’s where the “optimistic” part comes in. If the CAS values match, the operation is successful, and the sensor data is updated. However, if the CAS value doesn’t match, it means that the sensor data has been updated (by some other thread/process) since the last read operation. In this case, you have the option to retry the operation from the beginning. If you don’t expect the specific sensor document to get updated frequently, then optimistic locking is the way to go (as retries would be infrequent).
Here’s an example of optimistic locking with simple retry logic:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
// get existing sensor reading var currentDoc = await _collection.GetAsync(sensorId); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine(“Incoming sensor reading is newer. Updating.”); var retries = 3; while (retries > 0) { try { await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } catch (CasMismatchException) { Console.WriteLine($“CAS mismatch. Retries remaining: {retries}”); retries—; } } Console.WriteLine(“Retry max exceeded. Sensor reading was not updated.”); } else { Console.WriteLine(“Incoming sensor reading is not new. Ignoring.”); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
Pessimistic Locking
Pessimistic locking is another way to approach the same problem. Like optimistic locking, it has three steps, but with some slight differences.
The first step is to get and lock a document by key, making note of the CAS value. Unlike optimistic locking, where the document is simply read, in pessimistic locking, the document is explicitly locked. This means that no other process can make changes to the document until it becomes unlocked.
In the second step, just like optimistic locking, the timestamp is checked to see if it’s older than the incoming timestamp.
If it is, then in the third step, the document is replaced with the new value and submitted with the CAS value.
In step 1 of pessimistic locking, you also have to specify a timeout window. Why? It’s possible that step 3 might never happen due to an error or crash, and the document needs to eventually unlock.
If you expect the sensor document to be updated a lot, pessimistic might be the better approach. But because of the lock, there could be a reduced latency in other processes waiting for the document to become unlocked.
To illustrate, here’s an example of pessimistic locking in action:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
// get current sensor data var maxLockTime = TimeSpan.FromSeconds(30); var currentDoc = await _collection.GetAndLockAsync(sensorId, maxLockTime); var currentDocCas = currentDoc.Cas; var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps against new reading if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine(“Incoming sensor reading is newer. Updating.”); await _collection.ReplaceAsync(sensorId, newSensorReading, options => options.Cas(currentDocCas)); return; } else { await _collection.UnlockAsync(sensorId, currentDocCas); Console.WriteLine(“Incoming sensor reading is not new. Ignoring.”); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } |
CAS Locking Tradeoffs
When it comes to CAS locking, there are trade-offs to consider. Optimistic locking works well when conflicts are infrequent, but you’ll need to implement appropriate retry logic to handle possible retries.
To help with this tradeoff, more advanced or specialty retries could be used. For instance, in this use case, it may be acceptable to “give up” and discard an incoming sensor reading if there have been a lot of retries and/or the reading is very old.
Pessimistic locking, on the other hand, is a “safer” approach but requires a clear understanding of the performance implications of locking. Locking can increase latency in other processes that need to wait for the document to become unlocked.
ACID transaction
Another potential solution to the sensor update problem is using an ACID transaction. This approach may be overkill for updating a single document in this use case, but it could be useful in different use cases where multiple documents need to be updated atomically.
A challenge with sensor data is that it can be coming in at a fast rate. In the time between checking the current data and updating with incoming sensor data, another reading could be coming in. To avoid this issue, an ACID transaction can be used to conditionally update data.
The sample code below demonstrates how to use an ACID transaction to update a sensor document. The transaction ensures that only one update operation can occur at a time per sensor, preventing multiple incoming sensor readings from interfering with each other.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var transaction = Transactions.Create(_cluster, TransactionConfigBuilder.Create() .DurabilityLevel(DurabilityLevel.None)); // set to ‘none’ because I’m using a single-node dev cluster // for more details see: https://docs.couchbase.com/dotnet-sdk/current/howtos/distributed-acid-transactions-from-the-sdk.html await transaction.RunAsync(async (context) => { // get existing sensor reading var currentDoc = await context.GetAsync(_collection, sensorId); var currentReading = currentDoc.ContentAs<NauticalSpeed>(); // check timestamps if (newSensorReading.TimeStamp > currentReading.TimeStamp) { // incoming reading is newer, update the record Console.WriteLine(“Incoming sensor reading is newer. Updating.”); await context.ReplaceAsync(currentDoc, newSensorReading); } else { Console.WriteLine(“Incoming sensor reading is not new. Ignoring.”); // incoming reading is not newer, so do nothing // (or possibly update a log, or whatever else you want to do) } }); |
ACID Transaction Trade-offs
The key-value API should be used whenever possible to maximize performance. However, using a distributed ACID transaction in Couchbase will come with some overhead because of the additional key-value operations executed (behind the scenes) to coordinate the transaction. Since data in Couchbase is automatically distributed, operations will likely be coordinated across a network to multiple servers.
One benefit of using an ACID transaction over a CAS operation is that the Couchbase Transaction libraries already have sophisticated retry logic built into them. This can be a way to avoid writing your own retry logic. Additionally, an ACID transaction is recommended (probably required, in fact) if a use case involves updating multiple sensor documents.
SQL++ Update Operation
Another approach to performing conditional updates is to use a SQL++ UPDATE query.
Here’s an example implementation:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
var retries = 3; while (retries > 0) { try { await _cluster.QueryAsync<dynamic>(@“UPDATE sensordata s USE KEYS $sensorId SET s.speed = $newSpeed, s.unit = $newUnit, s.timeStamp = $newTimeStamp WHERE DATE_DIFF_STR($newTimeStamp, s.timeStamp, ‘millisecond’) > 0″, options => { options.Parameter(“sensorId”, sensorId); options.Parameter(“newSpeed”, sensorReading.Speed); options.Parameter(“newUnit”, sensorReading.Unit); options.Parameter(“newTimeStamp”, sensorReading.TimeStamp); }); return; } c atch (CasMismatchException) { Console.WriteLine($“UPDATE CAS mismatch, tries remaining: {retries}”); retries—; } } Console.WriteLine(“Max retries exceeded, sensor not updated”); |
(By the way, using an epoch timestamp will likely provide better performance).
As you might have guessed from the code, the SQL++ query is actually using CAS behind the scenes, just as is being done with the KV API example earlier.
SQL++ tradeoffs
The SQL++ approach for conditional updates does come with some trade-offs. Although the USE KEYS clause helps to eliminate the need for an index, the query still needs to be parsed by the query service, which involves many steps. This can put added pressure on the system if other components are already using the query service.
Overall, since the SQL++ approach is very similar to the KV API with the added overhead of parsing the query, it may not be the best choice unless you have a specific need for complex logic expressed in SQL++ or if using the KV API is not an option.
Eventing
The last approach I want to cover is the use of Eventing.
Eventing in Couchbase consists of writing JavaScript functions that respond to data change events asynchronously and deploying them to the Couchbase cluster.
For this particular use case, I think that using a “staging” collection as a location for the sensor readings initially is the way to go. Here’s the sequence:
- Incoming sensor readings are written to a “staging” collection.
- An Eventing OnUpdate function responds to new sensor readings.
- The OnUpdate function checks timestamps against the corresponding document in the “current” collection
- If timestamp is more current, the document in the “current” collection gets updated.
OnUpdate will run when a document is created or updated, so it’s okay to leave the old document in staging (this simplifies the eventing code). Also, a TTL can be set on the collection, so that if a sensor reading isn’t updated in a while, it will be automatically cleaned up.
Here’s an example of an eventing function that works with this design:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 |
function OnUpdate(doc, meta) { // Only process documents with a “timestamp” if (doc.timestamp) { // Extract timestamp and sensor ID from the staged document var stagedTimestamp = doc.timestamp; // note that this will loop indefinitely // but you can also limit it to a certain number of reties if you wish while(true) { // Get the current document for the same sensor ID from the “destination” collection var currentDoc = dst_col[meta.id]; // If there is no current document, or the staged timestamp is later than the current timestamp, update the current document if (!currentDoc || stagedTimestamp > currentDoc.timestamp) { // dst_col is a READ+WRITE ALIAS dst_col[meta.id] = doc; // the whole document is overwritten, but you can also choose to override certain fields if you wish } // src_col is a READ ALIAS var result = couchbase.get(src_col, meta); if (result.success) { if (result.meta.cas == meta.cas) { // the document was unchanged in the stage collection we are done break; } doc = result.doc; stagedTimestamp = doc.timestamp; } else { if (result.error.key_not_found) { // this might be okay, assuming ‘staging’ collection gets cleaned up or has a TTL // again, this will depend on what kind of retry logic you have break; } else { log(‘failure could not read stage adv. get: id’,meta.id,‘result’,result); } } } } } |
And here is the config for that eventing function:
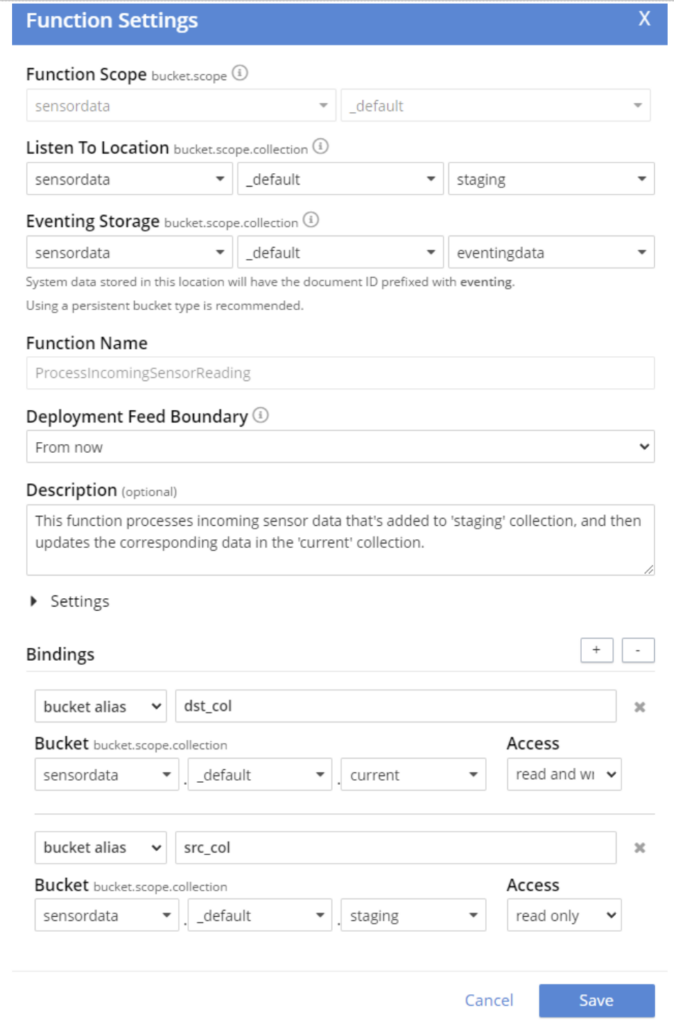
Eventing Trade-offs
Again, notice that an optimistic CAS lock is being used in this code. In fact, you could almost say that this was a JavaScript version of the code using the KV API earlier.
One key difference is that this function is running on the Couchbase cluster itself. And this is the key benefit to eventing: no matter where the sensor data is coming from, Couchbase’s Eventing function will ensure that it gets processed. It’s keeping the logic close to the data. If you have two or more clients that use the KV API instead, that means you need two or more implementations of the same code. This can lead to problems when logic changes, as it will need to be updated in multiple places.
However, just as with SQL++, Eventing has some overhead that’s involved. In this case, multiple collections, and the eventing service itself. Typically this could involve an additional node of Couchbase in production. Further, Eventing is not currently available in Couchbase Server Community.
Summary
Couchbase is a multi-model database that offers options and tradeoffs for your use case. In this post, the use case of sensor data updates was covered with 4 different data access patterns, each with their pros and cons:
- KV API – performant, simple, but may require some retry logic
- ACID transactions – reliable, but has overhead
- SQL++ – familiar, declarative, but has query parsing and execution overhead
- Eventing – close to the data, consolidates logic, but has overhead of eventing service and extra collections
All the code samples are available on GitHub.
Have you thought of a different approach? Leave a comment below, or share it on the Couchbase Discord.
Leave a comment
You must be logged in to post a comment.