XDCR es un sistema de replicación de datos asíncrono de alto rendimiento utilizado principalmente para replicar datos entre sus clusters Couchbase desplegados en diferentes centros de datos. Varias empresas de Fortune 500 confían en XDCR para sus aplicaciones de misión crítica. Alta disponibilidad, recuperación de desastres y localización de datos son las principales aplicaciones en las que XDCR es la solución a la que acudir.
XDCR está diseñado para ofrecer un alto rendimiento y un rendimiento resistente para la mayoría de los casos de uso, pero podría haber casos en los que es necesario ajustarlo para un rendimiento óptimo. Hemos introducido la configuración avanzada para permitir este ajuste y personalización del rendimiento.
El siguiente contenido pretende proporcionar una guía genérica sobre el ajuste XDCR a través de la Configuración Avanzada que es accesible a través de la Consola del Administrador de Couchbase y las APIs soportadas.
Cuando añada una replicación por primera vez, puede hacer clic en "Mostrar configuración avanzada" para mostrar las opciones como se muestra a continuación:
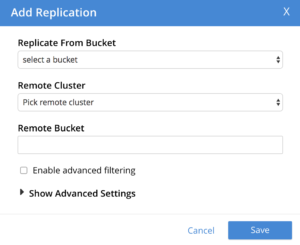
A continuación se indica un subconjunto de los ajustes XDCR más relevantes para el ajuste. Estos ajustes se pueden utilizar para mejorar el rendimiento o para conservar el ancho de banda de la red.
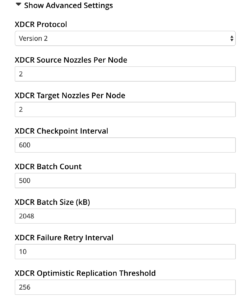
Configuración avanzada de XDCR
|
Ajuste del rendimiento
Algunos factores que influyen en el rendimiento pueden ser la naturaleza de los datos, la tasa de mutación de datos, la carga de trabajo en los clusters, la configuración de la red, etc. En función de estos parámetros, la replicación debe ajustarse para obtener el rendimiento deseado.
A continuación se indican algunas de las mejores prácticas para mejorar el rendimiento o conservar el ancho de banda:
a.Mejora del rendimiento:
- Dado el margen de recursos en los clusters de origen y destino, recomendamos un rango superior al predeterminado para Source Nozzle y Target Nozzle
- Si sus datos se componen de documentos de tamaño superior a 10K, le recomendamos que ajuste el Recuento de lotes y el Tamaño de lote a un valor superior al predeterminado.
b.Conservación del ancho de banda de la red:
- Utilice un valor de Umbral de Replicación Optimista superior al tamaño medio del documento.
Hemos realizado varios experimentos para demostrar el comportamiento, que se muestra a continuación.
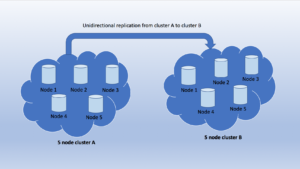
Configuración del experimento: El clúster A y el clúster B son dos clústeres con replicación unidireccional en curso (activo los datos se replican del clúster de origen al clúster de destino).
Configuración del entorno de prueba:
- Dos clústeres de Couchbase ejecutándose en AWS
- Grupo de origen: región West1, grupo de destino: región East1
- Latencia media de la red entre los clusters en el momento de la prueba : 72ms
- Tamaño del clúster : 5 nodos ejecutándose en instancias dedicadas m4.4xlarge
- Configuración de Couchbase Bucket : Tipo de cubo - Couchbase; Cuota de memoria del cubo por nodo = 60 GB; (configuración predeterminada para réplicas, resolución de conflictos y método de expulsión)
- Couchbase Server Enterprise R5.0 ejecutándose en Amazon Linux
- Replicación XDCR unidireccional creada yendo del bucket de origen al bucket de destino
Test1: Establecer una base de referencia
Configuración : Valores por defecto para todos los ajustes avanzados
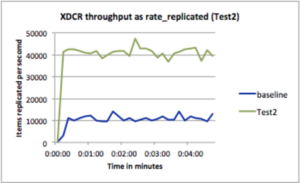
Prueba2: Demostrar el aumento del rendimiento mediante la paralelización
Configuración : Source Nozzle = 8, Target Nozzle = 8 (ambos 4x), average doc size=1KB
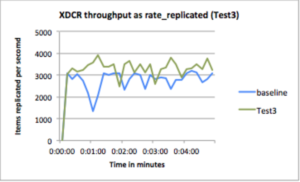
Prueba3: Demuestre un mayor rendimiento con cargas útiles de red más grandes
Configuración: Recuento de lotes = 4000, Tamaño de lote = 8192, tamaño medio del documento = 20 KB.
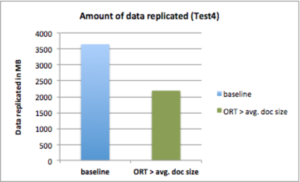
Test4: Demostrar una menor utilización del ancho de banda
Configuración : Umbral de replicación optimista > tamaño medio del documento
Nota :
- Los resultados de las pruebas que se muestran en los gráficos no deben considerarse absolutos, ya que podría observarse una variación de 3-5% en las repeticiones de estas pruebas en una configuración idéntica debido a los caprichos de los entornos de nube de AWS.
- La utilización media de la CPU fue igual o inferior a 40% en todas las pruebas.
Aunque queremos que experimentes y ajustes la replicación a tus necesidades de rendimiento deseadas, te aconsejamos que consultes con Couchbase antes de cambiar la configuración de XDCR para casos de uso que sean muy especializados o muy críticos para tu negocio.
Nirvair Singh es el ingeniero de soluciones que ha llevado a cabo este experimento. No dude en ponerse en contacto conmigo o con Nirvair para cualquier aclaración u orientación adicional.
Como siempre, estamos deseando conocer sus experimentos y experiencias.