Si es usted un desarrollador que trabaja con Couchbase o Capella, le interesará saber más sobre Capella DataStudio. Es una herramienta gratuita, apoyada por la comunidad, con una interfaz de usuario de un solo panel de cristal para gestionar Capella Operativa, Capella Columnary Clústeres de servidores Couchbase. No sólo aumenta la productividad de los desarrolladores, sino que también hace que tu experiencia sea mucho más fluida (y fresca).
Ahora, viene con una nueva función: Generador de datos sintéticos.
Generador de datos sintéticos de Capella DataStudio está diseñado para ofrecer a los desarrolladores una forma sencilla y sin código de crear datos realistas y significativos para sus proyectos. Ya se trate de probar aplicaciones, entrenar modelos de aprendizaje automático o simular sistemas a gran escala, esta función proporciona una flexibilidad y una potencia sin precedentes.
¿Qué son los datos sintéticos?
Los datos sintéticos no son simplemente datos "falsos"; están diseñados para imitar las propiedades, distribuciones y relaciones de los datos del mundo real. Mientras que los datos falsos pueden generar valores aleatorios sin contexto, los datos sintéticos pretenden:
-
- Mantener relaciones lógicas entre los campos (por ejemplo, la ciudad y el estado son coherentes)
- Seguir distribuciones realistas, como generar valores que se ajusten a distribuciones normales o ponderadas.
- Ser estadísticamente relevante para pruebas, análisis y simulaciones.
- Esto hace que los datos sintéticos sean increíblemente útiles en situaciones en las que los datos reales no están disponibles, son delicados o insuficientes.
Siga leyendo para profundizar en la generación de datos sintéticos o vea este vídeo para verlo en acción.
Características principales del generador de datos sintéticos de Capella DataStudio
Datos realistas y correlacionados
Nuestro generador garantiza que las relaciones entre los datos sean significativas. Por ejemplo, las direcciones incluyen valores coincidentes de ciudad, estado, código postal, latitud y longitud. Los nombres y datos demográficos son lógicamente coherentes.
Tipos de letra integrados, totalmente configurables
Elija entre una amplia gama de tipos incorporados para poner en marcha la generación de datos. Cada tipo puede personalizarse para adaptarse a sus necesidades específicas, ya sean nombres, ubicaciones, fechas o campos numéricos.
Ampliable: traiga sus propios tipos de letra
¿Tiene sus propios conjuntos de datos o requisitos específicos? Importe conjuntos de tipos personalizados para ampliar las capacidades del generador y crear datos a medida que se adapten a su caso de uso exclusivo.
Relación clave primaria / clave externas
Modele conjuntos de datos complejos con facilidad definiendo relaciones entre campos. Las claves foráneas pueden hacer referencia a datos de clave primaria, lo que permite crear estructuras de datos relacionales realistas.
Manejo de expresiones con potentes funciones
Aproveche las funciones integradas para crear expresiones complejas sin escribir una sola línea de código. Combine y manipule campos dinámicamente para tener el máximo control sobre sus datos.
Sin restricciones en el tamaño de los datos
Genere datos a cualquier escala, desde unas pocas filas para pequeñas pruebas hasta millones de documentos para simulaciones a gran escala. No hay límites a lo que puedes crear.
Perfecta integración con Capella Operational y Couchbase Server
Lleve sus datos sintéticos más allá importándolos directamente a Capella Operational o Couchbase Server. Esto garantiza un flujo de trabajo optimizado desde la generación hasta el despliegue.
¿Por qué elegir Capella DataStudio para la generación de datos sintéticos?
Con su intuitiva interfaz de usuario y su sólido conjunto de funciones, el generador de datos sintéticos de Capella DataStudio es la herramienta definitiva para crear conjuntos de datos significativos y de alta calidad. Tanto si eres desarrollador, científico de datos o tester, esta función te ahorrará tiempo, reducirá la complejidad y mejorará tus proyectos con datos realistas. Explore sus infinitas posibilidades y redefina su experiencia de creación de datos.
Generación de datos sintéticos
Veamos cómo funciona el generador de datos sintéticos.
Creador de esquemas
El esquema se construye campo por campo, fila por fila. Cada fila tiene un mínimo de dos atributos:
-
- El nombre del campo
- Tipo de datos del campo - tsu podría venir de la núcleo o usuario composición tipográfica
Dependiendo del tipo de datos, se pueden exponer más atributos:
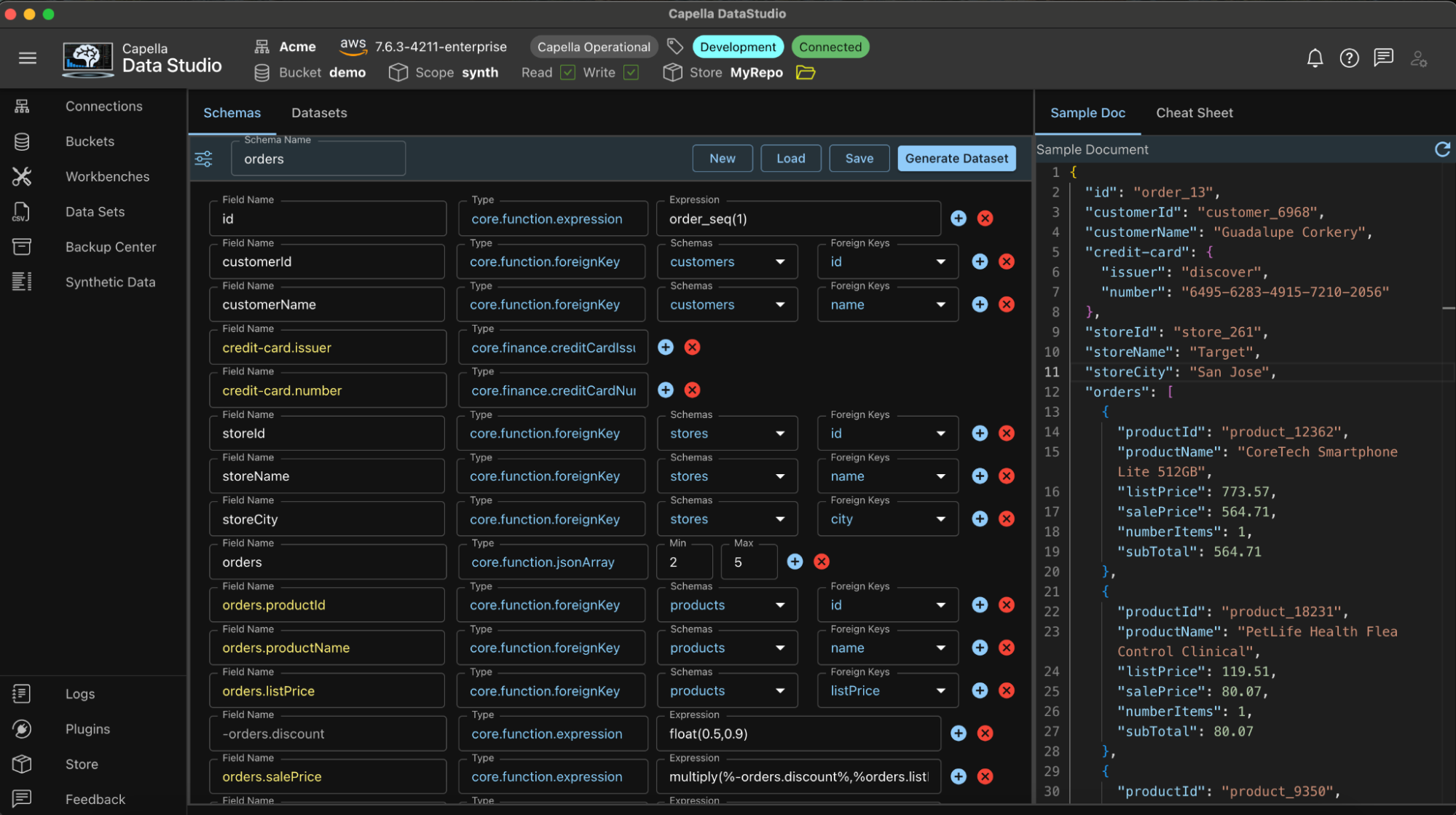
Ejemplo de esquema de pedidos
Nombre del campo
-
- Los nombres de campo pueden ser cualquier nombre de campo compatible con JSON
- Los objetos JSON anidados se especifican mediante el formato de puntos
- Admite JSON anidado en profundidad
- Los nombres de campo con un prefijo de guión doble se tratarán como clave principal.
- Al generar conjuntos de datos, estas claves también se exportarán y se guardarán como localStore/SyntheticData/DataSets/schemaName.pk archivo
- Las claves primarias sólo pueden especificarse en los campos del documento raíz
- Los objetos JSON, los campos anidados y los campos ocultos no pueden ser claves primarias.
- Los nombres de campo con un guión como prefijo se tratarán como campos ocultos.
- Los campos ocultos se utilizan como almacenamiento temporal utilizado en la referencia de campo
- Los campos ocultos no pueden ser claves primarias
- Los campos ocultos no aparecerán en el documento JSON
- Los objetos JSON no pueden ocultarse
- Los campos anidados pueden ocultarse
Tipo de datos
El tipo de datos se selecciona en un cuadro de diálogo:

La imagen muestra los tipos de letra básicos y un tipo de letra suministrado por el usuario (acme.pizzas).
Tipos de letra básicos
Proporcionado por Capella DataStudio:

Tipos de usuario
Proporcionado por usted para ampliar la funcionalidad del Generador de datos. Debe proporcionar dos archivos:
-
- Un archivo CSV con datos
- Un archivo de manifiesto que describe el Typeset
Proceso de composición tipográfica del usuario
Cuando se genera un documento con tipografías de usuario, ocurre lo siguiente:
-
- Se lee una fila aleatoria del fichero
- La fila se almacena en una caché de filas
- A continuación, los campos se leen desde esta caché de filas
- Una vez leído cualquier campo, éste se anula en la caché de filas
- Si el campo es nulo, se invalida toda la caché de filas y se lee una nueva fila aleatoria
- Los campos se leen de la caché de filas y, para un documento determinado, los datos se correlacionan
- Cada documento comienza con una nueva fila-cache
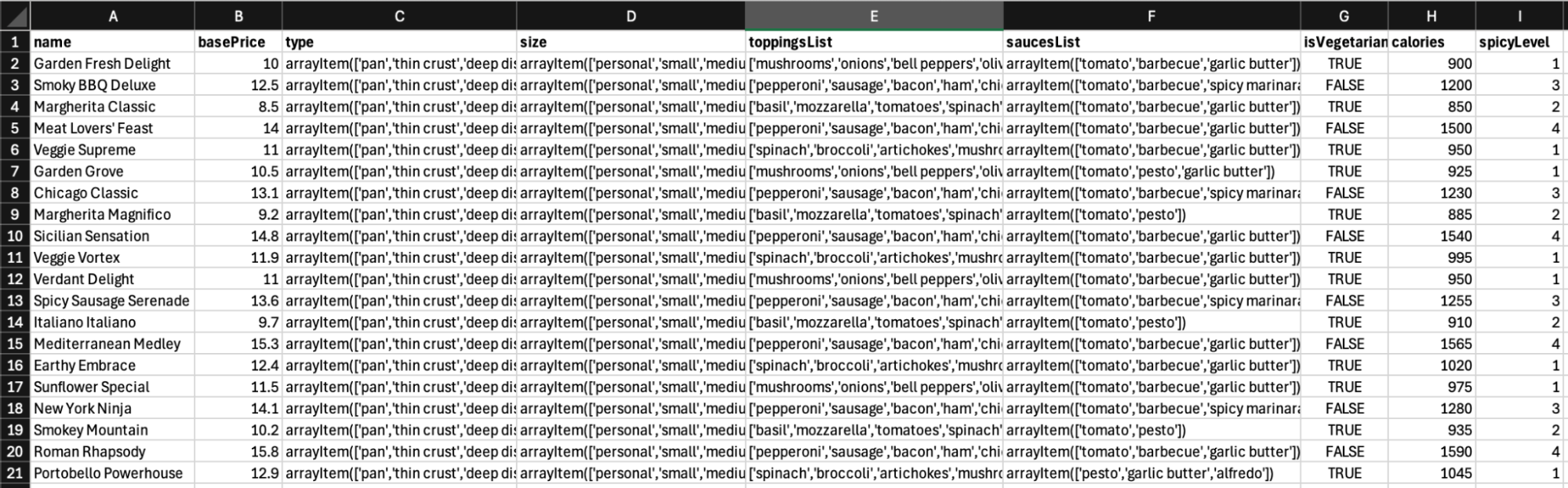
Ejemplo de composición tipográfica de pizzas

Función principal
Existen tres tipos de datos especiales:
-
- expresión
- foreignKey
- jsonArray
1. core.function.expression
Las expresiones son una potente forma de personalizar el esquema:
-
- Las expresiones son sólo cadenas
- Pueden tener incrustados referencias (incluido en %%) y funciones
Arquitectura de documentos y expresiones
Veamos cómo se construye el documento:
-
- El documento se construye, de arriba abajo, fila por fila.
- Siempre tenemos un documento parcial en cada etapa de la fila.
- En primer lugar, la expresión es una cadena
- Va a un Evaluador de expresiones
- El documento parcial, con sus campos y valores, se suministra al evaluador.
- Esto significa que los campos anteriores y sus valores evaluados están ahora disponibles.
- El documento parcial, con sus campos y valores, se suministra al evaluador.
- A continuación, se examina la cadena en busca de referencias
- Las referencias son nombres de campos, utilizados anteriormente, y sus valores, del documento parcial.
- Las referencias se sustituyen por los valores
- Esto significa que las referencias también pueden estar dentro de funciones
- A continuación, se examina la cadena en busca de funciones
- A continuación, las funciones se ejecutan y sus valores se sustituyen en el documento parcial.
- Finalmente, el evaluador devuelve el resultado.
- El documento se construye, de arriba abajo, fila por fila.
2. core.function.foreignKey
Claves foráneas y correlación de datos
Cuando se trabaja con datos relacionales, es crucial mantener la integridad referencial mediante claves foráneas. Así es como nuestro generador de datos sintéticos gestiona las relaciones de clave foránea:
Cómo funcionan las claves externas
En primer lugar, tendrá que generar su conjunto de datos primario. Supongamos que tiene un esquema para Departamentos que genera un archivo CSV con los ID y los nombres de los departamentos. Estos ID de departamento sirven como claves primarias en el conjunto de datos Departamentos.
Cuando cree otro esquema, por ejemplo para Empleadospuede especificar campos que hagan referencia a estas claves primarias existentes. El generador de esquemas ofrece dos menús desplegables:
-
- Un desplegable para seleccionar el conjunto de datos de origen (por ejemplo, "Departamentos")
- Un desplegable para seleccionar el campo de clave primaria al que se hará referencia (por ejemplo, "id")
Proceso de generación de datos
Al generar datos con referencias de clave externa, el sistema:
-
- Selecciona aleatoriamente una fila del conjunto de datos de origen
- Lee el valor o valores de la clave primaria de esa fila
- Utiliza estos valores en el nuevo conjunto de datos que se está generando
Mantener la correlación de datos
Una característica importante es cómo gestionamos las referencias a múltiples claves externas. Si el esquema hace referencia a varias columnas del mismo conjunto de datos de origen, los valores se extraen de la misma fila para mantener la correlación lógica.
Por ejemplo, si su esquema Empleado hace referencia tanto a department_id como a department_location del conjunto de datos Departamentos, ambos valores procederán del mismo registro de departamento. Esto garantiza que los datos sintéticos mantengan relaciones realistas entre los campos relacionados.
Este enfoque ayuda a crear conjuntos de datos sintéticos más realistas al preservar la integridad referencial y las relaciones lógicas presentes en los datos del mundo real.
3. core.function.jsonArray
Configuración de matrices JSON
Al configurar un campo de matriz JSON, puede especificar:
-
- Número mínimo de objetos en la matriz
- Número máximo de objetos en la matriz
El generador creará entonces matrices con un número aleatorio de objetos dentro del rango especificado.
Estructura y limitaciones
Las matrices JSON siguen estas reglas:
-
- Cada matriz contiene objetos JSON simples y planos
- No se admite el anidamiento de matrices (no hay matrices dentro de matrices).
- Cada objeto de la matriz sigue la misma estructura
Generación de datos
Una vez que el esquema se ha construido a su satisfacción, es el momento de generar datos.
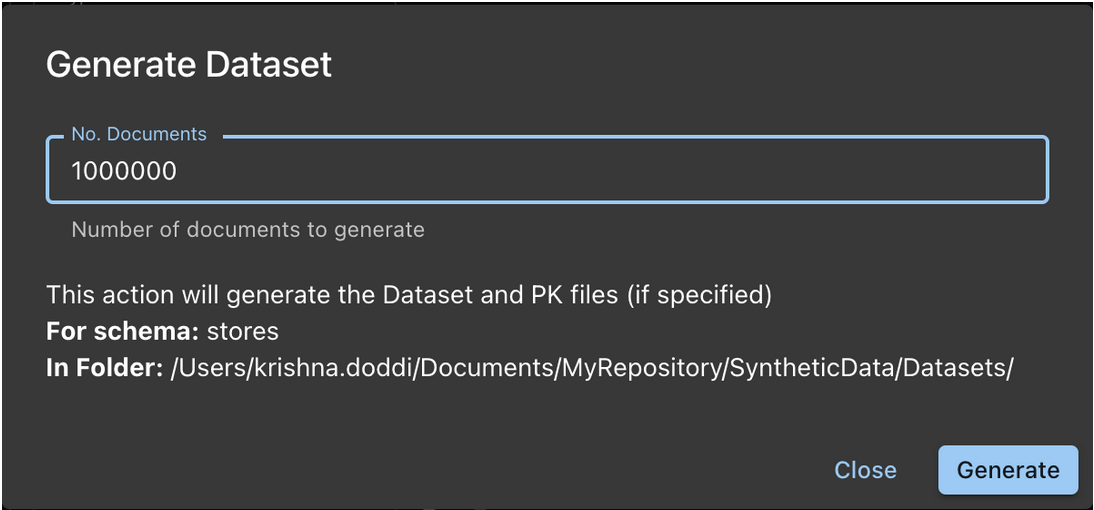
La imagen muestra la generación de un conjunto de datos sintéticos
-
- El conjunto de datos se genera y se escribe en LocalStore/SyntheticData/DataSets/
- El nombre de archivo del conjunto de datos es schemaName.json
- Se trata de un Líneas JSON archivo
- Si el documento tiene campos marcados como Clave Primaria (prefijados con doble guión), entonces, un schemaName.pk también se produce
- El archivo .pk es un archivo CSV
- Si algún campo tiene el valor seq() las secuencias se incrementan en 1
- No hay límite en el número de documentos
Ejemplos de conjuntos de datos
cliente.json
|
1 2 3 4 5 6 7 8 9 |
[ {"id":"customer_1","name":"Lula Kuhic","gender":"Demi-man","age":65,"email":"Electa29@yahoo.com","address":{"street":"46938 VonRueden Village Suite 474","city":"Los Angeles","state":"California","zip":"90001","geo":{"latitude":33.7423,"longitude":-117.4412}},"phones":{"home":"(310) 788-5382","cell":"(310) 923-5319"}}, {"id":"customer_2","name":"Chelsea Wilderman","gender":"Transsexual female","age":58,"email":"Augusta_Mann27@yahoo.com","address":{"street":"8409 Jesse Mill Apt. 289","city":"Sacramento","state":"California","zip":"95814","geo":{"latitude":38.8607,"longitude":-121.0356}},"phones":{"home":"(916) 879-6009","cell":"(916) 503-2269"}}, … ] |
cliente.pk
|
1 2 3 4 |
id,name "customer_1","Lula Kuhic" "customer_2","Chelsea Wilderman" … |
Vista previa del conjunto de datos
Puede previsualizar los conjuntos de datos generados. El panel de vista previa permite previsualizar los datos en formato JSON o en formato de tabla.
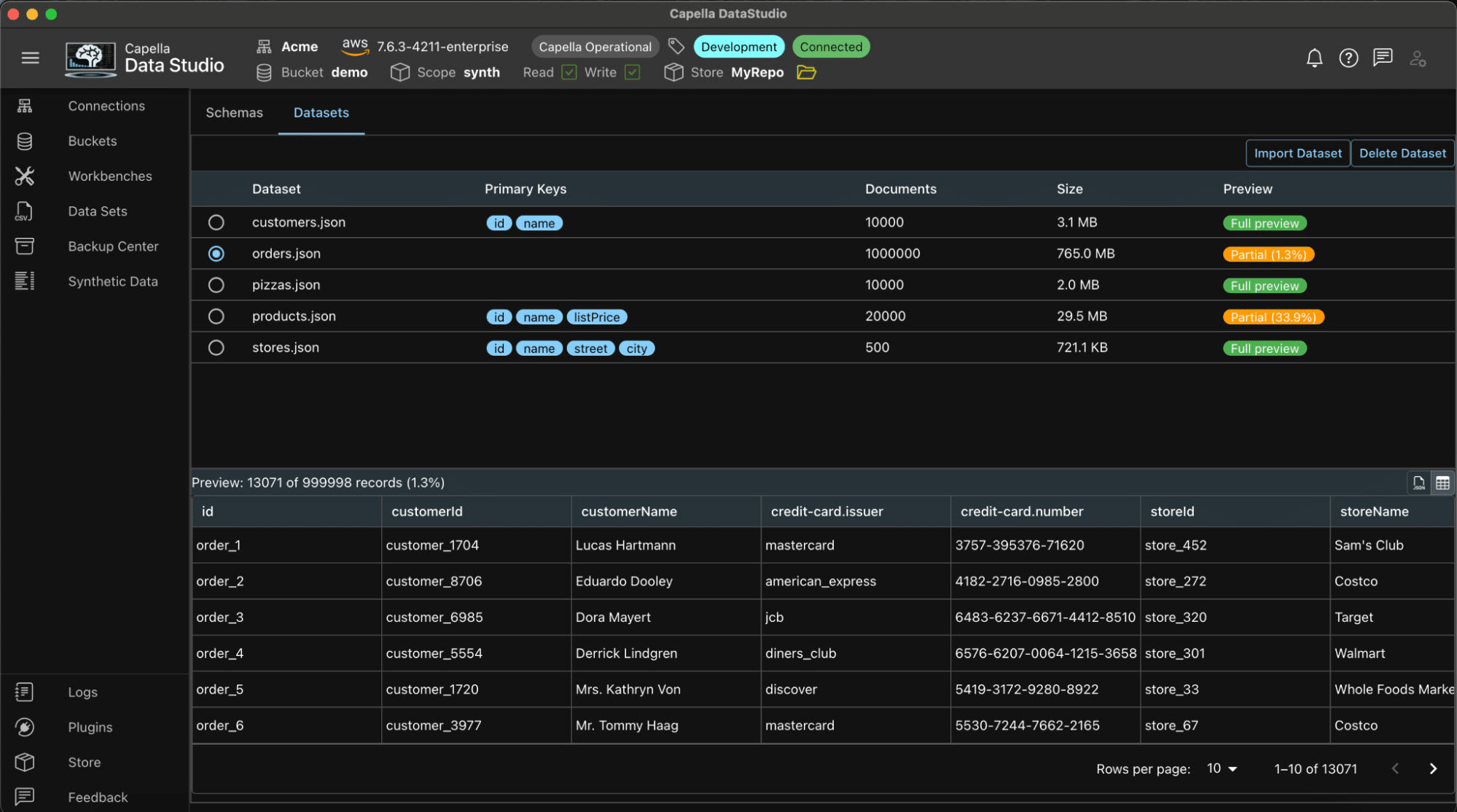
La imagen muestra el panel de vista previa y la vista previa de la tabla
Importar
Puede importar el conjunto de datos generado a su colección Couchbase:
-
- Import utiliza la utilidad cbimport y ofrece todas sus opciones de importación
- No hay límite de archivos para importar
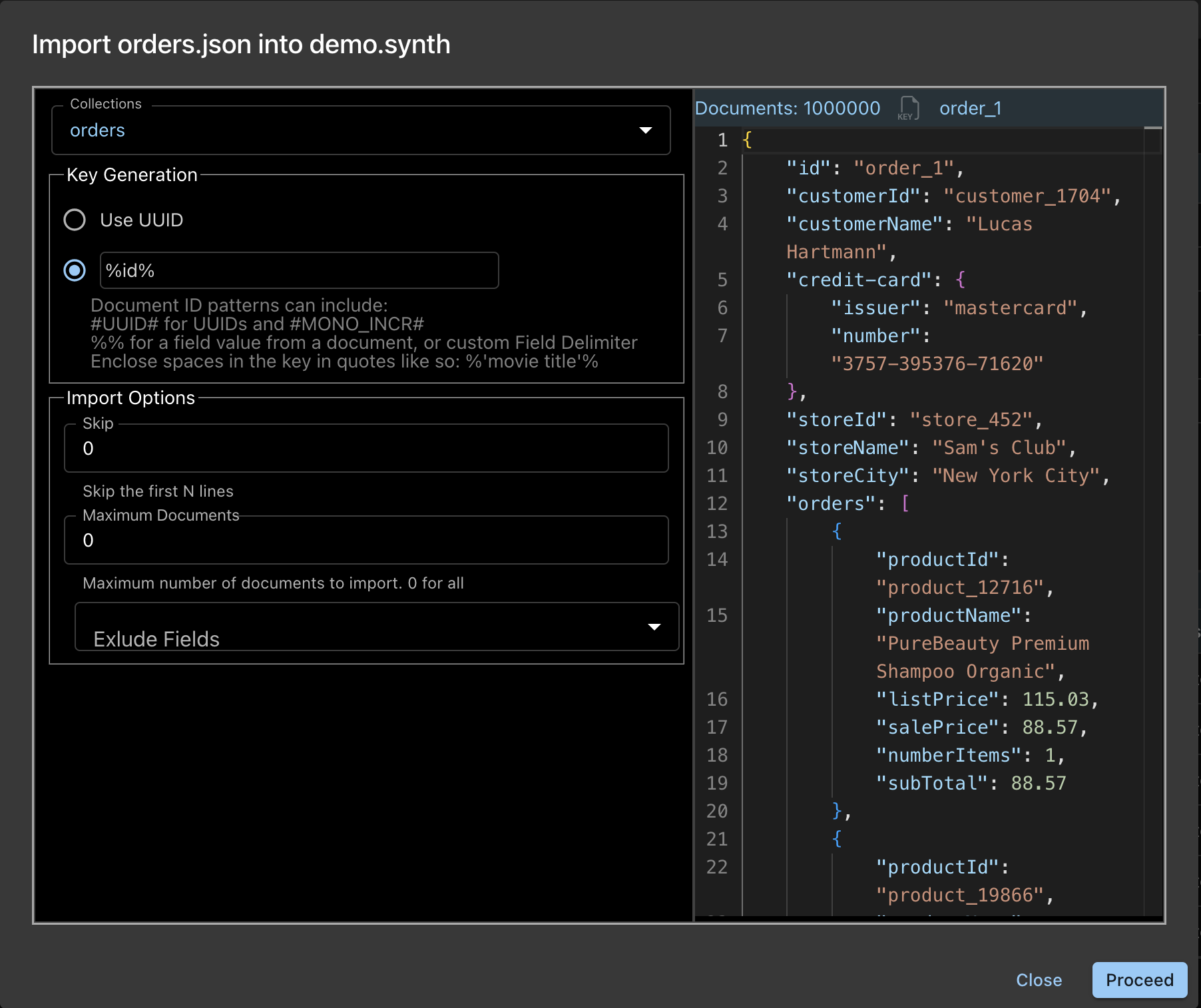
La imagen muestra el cuadro de diálogo de importación y las opciones
¿Listo para aumentar su productividad?
Capella DataStudio es la herramienta que los desarrolladores estaban esperando. Ya sea que esté administrando Couchbase Server, Capella Operational o clústeres Capella Columnar, esta aplicación hace que su trabajo sea más fácil, más rápido y sí, más fresco.
Pruebe Capella DataStudio gratis y consulte nuestro vídeos tutoriales:
Con Capella DataStudio, la gestión de datos nunca ha sido tan divertida ni productiva.
Apéndice - funciones admitidas en las expresiones
La tabla muestra la lista de funciones disponibles para utilizar en las expresiones:
| Tipo | Ejemplo | Salida |
| int(mín,máx) | int(1,10) | 6 |
| float(min,max) | float(1.234,10.587) | 5.824 |
| float(min,max,dec) | float(1,10,2) | 5.82 |
| normal(media,std,dec) | normal(50,10,3) | 56.48 |
| bool() | bool() | FALSO |
| bool(sesgo) | bool(0.8) | TRUE |
| fecha(desde,hasta) | date(01/01/2024,12/31/2024) | “02/02/2024” |
| tiempo(desde,hasta) | hora(08:00 am, 5:00 pm) | "08:47 AM" |
| arrayItem(array) | arrayItem(["gato", "ratón", "perro"]) | "gato" |
| arrayItem(array) | arrayItem(["gato:2″, "ratón:1″, "perro:7"]) | "perro" |
| arrayItems(array,longitud) | arrayItems(["gato", "ratón", "perro"],2) | ["gato", "ratón"] |
| arrayItems(array,longitud) | arrayItems(["gato:2″, "ratón:1″, "perro:7"]) | ["gato", "perro"] |
| arrayKV(array,campo) | arrayKV(["gato:2″, "ratón:1″, "perro:7″], "gato") | 2 |
| gps(latitud,longitud) | gps(37.3382,-121.8863) | gpsObject |
| gpsCerca(gps,radio) | gpsCerca(%gps%,20) | gpsObject |
| seq(númeroInicial) | seq(1000) | 1030 |
| uuid() | uuid() | "e46b493a-..." |
| add(num1,num2) | add(1.23,3.45) | 4.68 |
| resta(num1,num2) | resta(1.23,3.45) | -2.22 |
| multiplicar(num1,num2) | multiplicar(1.23,3.45) | 4.24 |
| por ciento(num,den) | por ciento(1.23,3.45) | “35.65%” |
| acumular(num,nombre) | accumulate(1TP3Pedidos.subTotal%,venta) | 1304.84 |