Cuando estoy en eventos y hablo con usuarios y defensores de NoSQL, a menudo escucho historias sobre por qué la gente ha decidido empezar a usar Couchbase después de haber venido de MongoDB. Tomemos, por ejemplo, un entrevista que le hice a Tom Coates de Nuance. Una de las principales razones por las que Nuance decidió abandonar MongoDB es su incapacidad para escalar de forma simplificada. No es la primera vez que oigo esta historia.
Vamos a explorar lo que implica escalar un clúster NoSQL con MongoDB y luego lograr lo mismo con Couchbase.
Para MongoDB, la fragmentación es una forma popular de scale. Otras bases de datos enfocan el proceso de clustering NoSQL de forma diferente. En todos los casos, nos interesa crear un clúster de múltiples nodos que incluya la replicación de datos.
Creación de un clúster MongoDB de múltiples nodos
MongoDB es una base de datos de documentos NoSQL que tiene una arquitectura maestro-esclavo. Cuando se crea un clúster y se escala, hay que crear y gestionar un clúster maestro-esclavo. clúster fragmentado y un conjunto de réplicasque es otro nombre para un cluster de replicación. Estas son piezas de un rompecabezas potencialmente grande, y verás cómo puede complicarse fácilmente.
Como planeamos hacerlo todo localmente, Docker se convierte en un buen candidato para el trabajo. Vamos a desplegar varios contenedores Docker de MongoDB y escalarlos como parte de un clúster.
La primera orden del día es desplegar todos los nodos necesarios para nuestro clúster. Usando la CLI de Docker, ejecuta los siguientes comandos:
|
1 2 3 |
docker run -d -p 27017-27019:27017-27019 -p 28017:28017 --name mongocfg1 mongo mongod --configsvr --replSet rs0 docker run -d -p 37017-37019:27017-27019 -p 38017:28017 --name mongoshd1 mongo mongod --shardsvr --replSet rs1 docker run -d -p 47017-47019:27017-27019 -p 48017:28017 --name mongoshd2 mongo mongod --shardsvr --replSet rs1 |
Los comandos anteriores crearán un nodo de configuración que utiliza un rs0 así como dos nodos shard que utilizan un conjunto de réplica rs1 conjunto de réplica. Acabamos de iniciar nuestras instancias de MongoDB y ya tenemos dos tipos de nodo y conjuntos de réplica diferentes de los que preocuparnos.
Ahora tenemos que conectarlos todos juntos para conseguir la replicación y la fragmentación en un estado funcional.
Empecemos por inicializar la replicación en los dos nodos shard que utilizan el módulo rs1 conjunto de réplicas. Necesitaremos determinar las direcciones IP de sus contenedores para realizar el trabajo. Desde la CLI de Docker, ejecuta lo siguiente:
|
1 2 |
docker inspect mongoshd1 docker inspect mongoshd2 |
Una vez obtenidas las direcciones IP, conéctese a uno de los nodos shard mediante el siguiente comando:
|
1 |
docker exec -it mongoshd1 bash |
Esto nos permite controlar el contenedor con el shell interactivo. Para inicializar la replicación en estos nodos, necesitamos lanzar el shell de Mongo desde el contenedor conectado:
|
1 |
mongo --port 27018 |
Una vez conectado a través del shell de Mongo, ejecute lo siguiente:
|
1 2 3 4 5 6 7 |
rs.initiate({ _id : "rs1", miembros: [ { _id : 1, host : "172.17.0.3:27018" }, { _id : 2, host : "172.17.0.4:27018" } ] }); |
En el comando anterior, recuerde intercambiar las direcciones IP de los contenedores con los nodos shard que realmente desea utilizar.
Una vez ejecutado, podrá comprobar el estado de los nodos a través de la función rs.status() mando.
Ahora necesitamos preparar el nodo de configuración. En primer lugar determinar la IP del contenedor como se ha demostrado anteriormente y conectarse a él a través de:
|
1 |
docker exec -it mongocfg1 bash |
Una vez conectado con la shell interactiva, tendrás que conectarte a MongoDB usando la shell de Mongo, pero esta vez a través de un puerto diferente ya que se trata de un nodo de configuración:
|
1 |
mongo --port 27019 |
Una vez conectado al nodo de configuración a través del shell de Mongo, ejecuta el siguiente comando para inicializar el conjunto de réplicas:
|
1 2 3 4 5 6 |
rs.initiate({ _id : "rs0", miembros: [ { _id : 0, host : "172.17.0.2:27019" }, ] }); |
En este punto deberíamos poder empezar a configurar los nodos shard. Recuerda que anteriormente sólo configuramos las réplicas en los nodos shard. Sal del shell de Mongo en el nodo de configuración, pero no salgas del shell interactivo. Necesitamos ejecutar un nuevo comando llamado mongospara realizar aún más configuraciones. Ejecute lo siguiente:
|
1 |
mongos --configdb rs0/172.17.0.2:27019 |
Esto nos permitirá añadir shards a través del shell de Mongo. A menos que elijas ejecutar mongos en segundo plano, necesitarás abrir una nueva Terminal para usar el shell de Mongo.
Conectar con mongocfg1 desde un nuevo Terminal y luego conéctate usando el shell de Mongo. Esta vez en lugar de usar el puerto 27019 utilizará el puerto 27017.
Una vez conectado, ejecute los siguientes comandos para añadir los fragmentos:
|
1 2 |
sh.addShard("rs1/172.17.0.3:27018"); sh.addShard("rs1/172.17.0.4:27018"); |
En lo anterior, recuerda, estamos usando las direcciones IP de los nodos shard y el puerto del nodo shard.
Con las funciones de fragmentación de MongoDB configuradas, ahora podemos habilitarlas para una base de datos en particular. Esta puede ser cualquier base de datos MongoDB que desees. Habilitar la fragmentación se puede hacer con lo siguiente:
|
1 |
sh.enableSharding("ejemplo"); |
Pero aún no hemos terminado. En MongoDB, las opciones de fragmentación existen en una gama que incluye Sharding a distancia y Fragmentación Hashed. Determine cómo fragmentará las colecciones de datos teniendo en cuenta tu objetivo es conseguir que los datos de tu base de datos se distribuyan lo más uniformemente posible por este clúster NoSQL.
Tomemos como ejemplo el siguiente comando:
|
1 |
sh.shardCollection("ejemplo.personas", { "_id": "hashed" }); |
El comando anterior creará una clave de fragmento en _id para la gente colección. ¿Es la mejor manera de hacer las cosas, tal vez o tal vez no, que depende de usted para decidir cómo desea fragmentar sus datos en MongoDB.
Si alguna vez quieres comprobar la distribución de los fragmentos puedes ejecutar:
|
1 |
db.people.getShardDistribution(); |
Como se puede ver en todos los pasos que hemos dado, no ha sido una tarea fácil conseguir que la replicación y la fragmentación funcionen en un clúster de nodos MongoDB. A medida que necesitas escalar tu clúster hacia arriba y hacia abajo, la tarea se vuelve aún más engorrosa y es algo que frustra a las empresas.
Aquí es donde entra en juego Couchbase.
Creación de un cluster Couchbase de múltiples nodos
Aunque Couchbase es una base de datos de documentos como MongoDB, las cosas son un poco diferentes en su arquitectura. Couchbase utiliza un diseño peer-to-peer (P2P) que elimina el diseño maestro-esclavo. Además, cada nodo en un cluster tiene el mismo diseño, lo que significa que tendrá datos, indexación y servicios de consulta disponibles. Esto elimina la necesidad de crear clústeres especializados de replicación o fragmentados.
Así que vamos a echar un vistazo a la creación de un clúster de múltiples nodos Couchbase. Como vamos a hacer todo localmente, tiene sentido usar Docker para esta tarea.
Ejecute los siguientes comandos desde su CLI de Docker:
|
1 2 3 |
docker run -d -p 7091-7093:8091-8093 --name couchbase1 couchbase docker run -d -p 8091-8093:8091-8093 --name couchbase2 couchbase docker run -d -p 9091-9093:8091-8093 --name couchbase3 couchbase |
Los comandos anteriores crearán tres contenedores Couchbase Server mapeando los puertos del contenedor a un conjunto diferente de puertos del host.
Como se trata de Docker, cada contenedor será una instalación nueva de Couchbase. El objetivo de esta guía no es poner en marcha Couchbase, por lo que no vamos a revisar cómo pasar por cada uno de los cinco pasos de configuración.
Hay múltiples formas de establecer un cluster en Couchbase, así que veremos unas cuantas. De los tres contenedores, configura dos de ellos como nuevos clusters.
El nodo no configurado, digamos couchbase1 será el primero que añadamos al clúster. Vamos a añadirlo al mismo cluster que el couchbase2 nodo. Desde su navegador, vaya a http://localhost:7091 y elija unirse a un clúster.
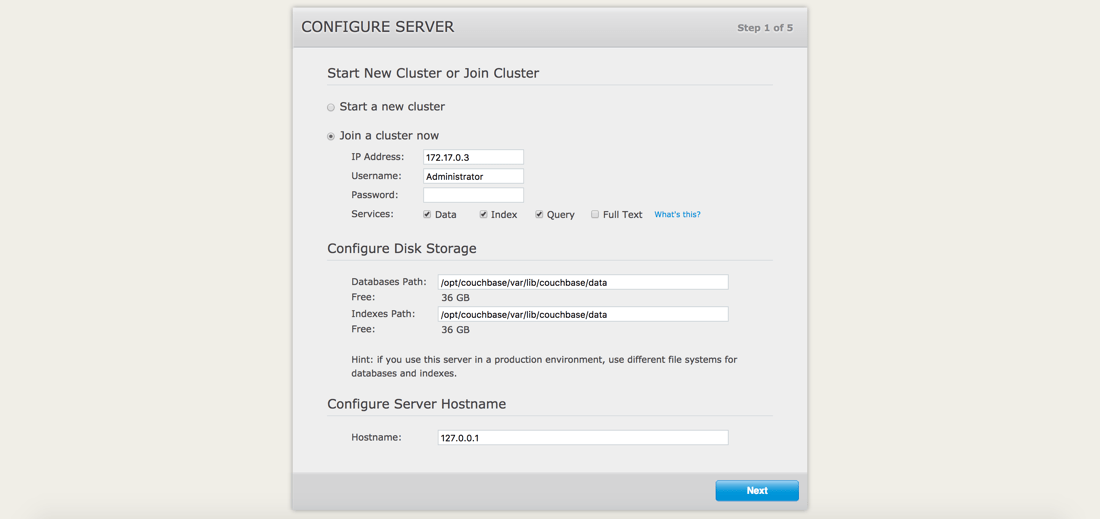
Lo que importa aquí es la dirección IP, el nombre de usuario y la contraseña administrativos del otro nodo, y los servicios que desea que estén disponibles.
Dado que estamos utilizando Docker, es importante que utilicemos la dirección IP correcta del couchbase2 nodo. Para encontrar esta dirección IP, ejecute el siguiente comando:
|
1 |
docker inspect couchbase2 |
Busque la dirección IP en los resultados. Es muy importante que no intentes usar localhost ya que esa es solo la dirección vinculada, no la dirección real del contenedor.
Después del couchbase1 se añade al nodo couchbase2 el cluster necesita ser reequilibrado.
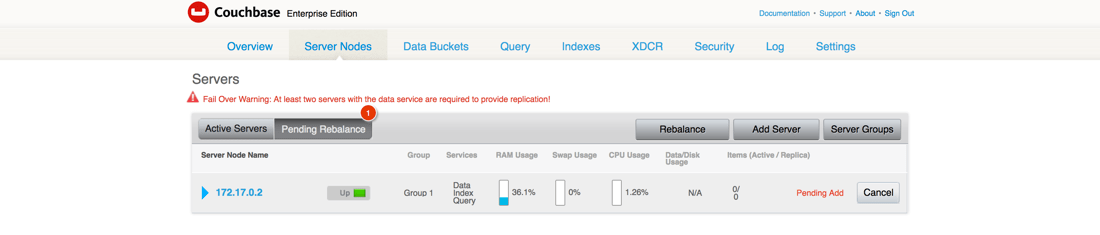
Reequilibrar el clúster distribuirá los datos de Bucket uniformemente por todo el clúster. Es necesario reequilibrar cada vez que se añaden o eliminan nodos del clúster.
Ahora tienes un cluster de dos nodos con replicación y fragmentación automática de datos. Ahora vamos a comprobar cómo añadir ese tercer nodo, ya configurado, al clúster.
Dado que Couchbase es peer-to-peer, conéctese a couchbase1 o couchbase2 y elija añadir un nuevo servidor al clúster.
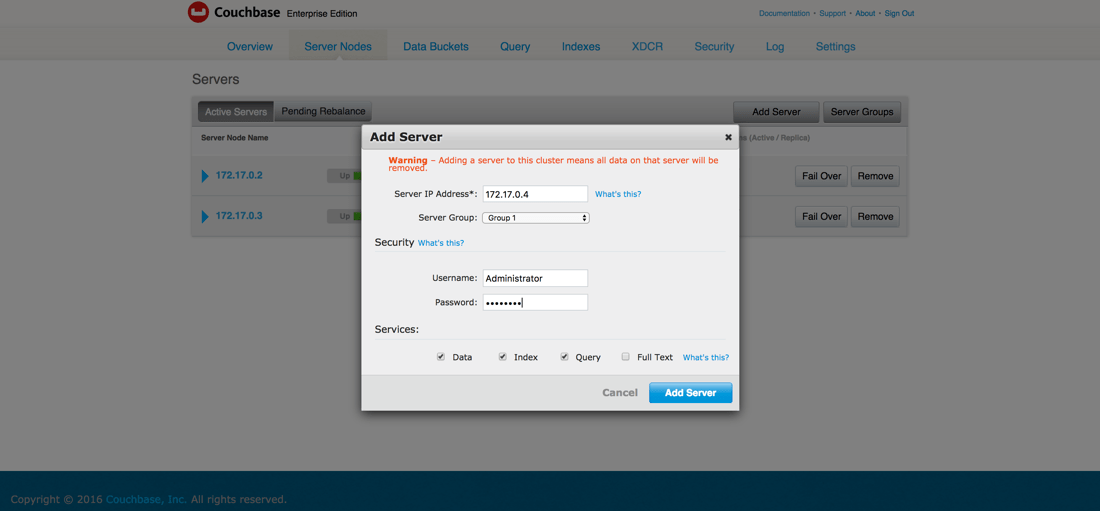
Tendrá que introducir la información del nodo para couchbase3de forma similar a como lo hicimos anteriormente. Recuerde utilizar la dirección IP del contenedor apropiado.
Acabas de añadir un tercer nodo al cluster. No olvides reequilibrar para finalizar el proceso.
Hay una forma CLI de añadir nodos a un cluster o unirse a un cluster, pero no vamos a entrar en eso ya que no es más difícil de lo que ya hemos visto. Escalar Couchbase es un proceso de dos pasos sin importar si tienes tres nodos o cincuenta nodos.
Si te gusta mucho Docker, escribí una guía sobre la automatización de este proceso para Couchbase en un artículo anterior sobre el tema.
Conclusión
Acabas de ver lo mucho más fácil que es crear y escalar un clúster de Couchbase Server que con MongoDB. La complejidad extra en tu base de datos NoSQL es una carga con la que ninguna persona orientada a operaciones o desarrollo quiere lidiar.
Si estás interesado en seguir comparando Couchbase contra MongoDB, he escrito otros artículos orientados a desarrolladores sobre el tema. Por ejemplo, si quieres transferir tus datos de MongoDB a Couchbase, puedes echa un vistazo a un tutorial de Golang que escribío si desea convertir su API RESTful de Node.jstambién puede encontrar material sobre el tema.
Para obtener más información sobre el uso de Couchbase, consulte la página Portal para desarrolladores de Couchbase.