Durante años, la gente ha utilizado memcached para escalar grandes sitios. Originalmente, se utilizaba un sencillo algoritmo hash de selección de módulos. Todavía se usa bastante en realidad y es bastante fácil de entender (aunque, se demuestra regularmente que algunas personas no lo entienden realmente cuando se aplica a su sistema completo). El algoritmo es básicamente este:
servidor_para_clave(clave) = servidores[hash(clave) Servidores %.longitud]
Es decir, dado un algoritmo hash, se hace un hash de la clave y se mapea a una posición en la lista de servidores y se contacta con ese servidor para esa clave. Esto es realmente fácil de entender, pero conlleva algunos problemas.
- Algunos servidores tienen mayor capacidad que otros.
- Las pérdidas de caché se disparan cuando muere un servidor.
- Configuración frágil/confusa (las cosas rotas pueden parecer que funcionan)
Ignorando la ponderación (que básicamente puede "resolverse" añadiendo el mismo servidor varias veces a la lista), el mayor problema que se plantea es qué hacer cuando un servidor muere, o usted desea añadir uno nuevoo incluso quieres sustituir uno.
En 2007, Richard Jones y su equipo en last.fm creó una nueva forma de resolver algunos de estos problemas llamada ketama. Se trataba de una biblioteca y un método para hacer "hashing consistente", es decir, una forma de reducir en gran medida la probabilidad de hacer hashing en un servidor que no tiene los datos que buscas cuando cambia la lista de servidores.
Es un sistema impresionante, pero no estoy aquí para escribir sobre él, así que no entraré en detalles. Todavía tiene un defecto que lo hace inadecuado para proyectos como membranaes sólo probabilísticamente más probable que te lleve al servidor con tus datos. Visto de otro modo, está casi garantizado que a veces te lleve al servidor equivocado, pero con menos frecuencia que el método del módulo descrito anteriormente.
Una nueva esperanza
A principios de 2006, Anatoly Vorobey presentó algún código para crear algo a lo que se refería como "cubos gestionados". Este código vivió allí hasta finales de 2008. Fue retirado porque nunca estaba completo, no se entendía del todo, y habíamos creado un protocolo más nuevo que facilitaba la construcción de esas cosas.
Lo hemos recuperado, y voy a contarte por qué existe y por qué lo quieres.
En primer lugar, un breve resumen de lo que queríamos conseguir:
- Nunca atienda una solicitud en el servidor equivocado.
- Permitir la ampliación y a voluntad.
- Los servidores rechazan órdenes que no deben atender, pero
- Los servidores siguen sin conocerse.
- Podemos pasar conjuntos de datos de un servidor a otro de forma atómica, pero
- No hay restricciones temporales.
- La coherencia está garantizada.
- En el caso normal, no se introduce ninguna sobrecarga de red.
Para ampliar un poco el último punto en relación con otras soluciones que hemos visto, no hay proxies, servicios de localización, conocimiento de servidor a servidor, o cualquier otra cosa mágica que requiera sobrecarga. Una petición consciente de vbucket no requiere más operaciones de red para encontrar los datos que para realizar la operación sobre los datos (ni siquiera es un byte más grande).
Hay otros objetivos de menor importancia, como "debería ser posible añadir servidores en picos de carga", pero son objetivos que caen por su propio peso.
Presentación: El VBucket
Un vbucket es conceptualmente un subconjunto calculado de todas las claves posibles.
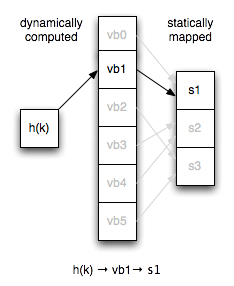
Si alguna vez has implementado una tabla hash, puedes pensar en ella como un cubo de tabla hash virtual que es el primer nivel de hash para todas las búsquedas de nodos. En lugar de asignar claves directamente a los servidores, asignamos vbuckets a los servidores de forma estática y tenemos un cálculo coherente de clave → vbucket.
El número de vbuckets en un cluster permanece constante independientemente de la topología del servidor. Esto significa que la clave x siempre se asigna al mismo vbucket dado el mismo hash.
Las configuraciones de cliente tienen que crecer un poco para este concepto. En lugar de ser una simple secuencia de servidores, la configuración ahora también tiene la asignación explícita de vbucket a servidor.
En la práctica, modelamos la configuración como una secuencia de servidores, una función hash y un mapa de vbuckets. Dados tres servidores y seis vbuckets (un número muy pequeño para la ilustración), un ejemplo de cómo funciona esto en relación con el código de módulo anterior sería el siguiente:
vbuckets = [0, 0, 1, 1, 2, 2]
servidor_para_clave(clave) = servidores[vbuckets[hash(clave) % vbuckets.longitud]]
Debería ser obvio al leer ese código cómo la introducción de vbuckets proporciona una tremenda potencia y flexibilidad, pero seguiré por si no lo es.
Terminología
Antes de entrar en demasiados detalles, veamos la terminología que se va a utilizar aquí.
- Grupo:
- Una colección de servidores colaboradores.
- Servidor:
- Una máquina individual dentro de un clúster.
- vbucket:
- Un subconjunto de todas las claves posibles.
Además, cualquier vbucket estará en uno de los siguientes estados en cualquier servidor:

- Activa:
- Este servidor está atendiendo todas las peticiones para este vbucket.
- Muerto:
- Este servidor no es en modo alguno responsable de este vbucket
- Réplica:
- No se gestionan peticiones de clientes para este vbucket, pero puede recibir comandos de replicación.
- Pendiente:
- Este servidor bloqueará todas las peticiones para este vbucket.
Operaciones con clientes
Cada solicitud debe incluir el identificador del vbucket calculado por el algoritmo hash. Hemos utilizado los campos reservados del protocolo binario para crear hasta 65.536 vbuckets (lo que es mucho decir).
Dado que todo lo que se necesita para elegir sistemáticamente el vbucket correcto es que los clientes se pongan de acuerdo sobre el algoritmo hash y el número de vbuckets, es significativamente más difícil configurar mal un servidor de forma que te estés comunicando con el servidor equivocado para un vbucket determinado.
Además, con libvbucket hemos hecho que distribuir configuraciones y distribuir configuraciones, acordar algoritmos de mapeo y reaccionar ante configuraciones erróneas sea un problema que no tenga que resolverse repetidamente. Se está trabajando para conseguir ports de libvbucket a java y .net, y mientras tanto moxi realizará todas las traducciones por ti si tienes un cliente no persistente o no puedes esperar a que tu cliente favorito se ponga al día.
Un servidor activo
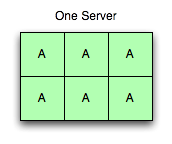
Aunque los despliegues suelen tener 1.024 o 4.096 vbuckets, vamos a seguir con este modelo con seis porque es mucho más fácil de pensar y de dibujar.
En la imagen de la derecha, hay un servidor funcionando con seis buckets activos. Todas las peticiones con todos los vbuckets posibles van a este servidor, y responde para todos ellos.
Un servidor activo, un nuevo servidor
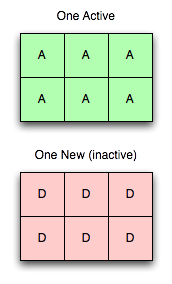
Añadamos ahora un nuevo servidor. Aquí está la primera parte de la magia: Añadir un servidor no desestabiliza el árbol (como se ve a la derecha).
Añadir un servidor al clúster, e incluso enviarlo en la configuración a todos los clientes, no implica que se vaya a utilizar inmediatamente. El mapeo es un concepto aparte, y todos los vbuckets siguen estando exclusivamente mapeados al servidor antiguo.
Para que este servidor sea útil, transferiremos vbuckets de un servidor a otro. Para realizar una transferencia, seleccionamos un conjunto de los vbuckets que queremos que posea el nuevo servidor y los ponemos todos en estado pendiente en el servidor receptor. A continuación, empezamos a extraer los datos y a colocarlos en el nuevo servidor.
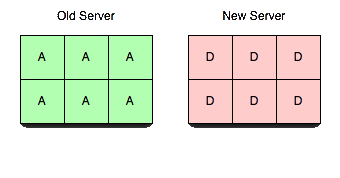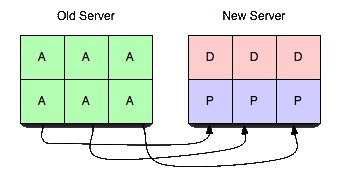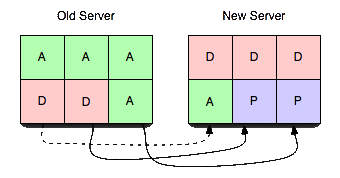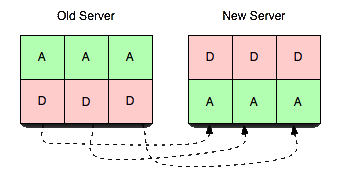 Realizando los pasos en este orden exacto, podemos garantizar que no hay más de un servidor activo para cualquier vbucket en un momento dado. sin sin tener en cuenta la cronología real. Es decir, puedes tener horas de desviación de reloj y transferencias de vbucket que tarden varios minutos y nunca dejar de ser coherente. También está garantizado que los clientes nunca recibirán incorrecto respuestas.
Realizando los pasos en este orden exacto, podemos garantizar que no hay más de un servidor activo para cualquier vbucket en un momento dado. sin sin tener en cuenta la cronología real. Es decir, puedes tener horas de desviación de reloj y transferencias de vbucket que tarden varios minutos y nunca dejar de ser coherente. También está garantizado que los clientes nunca recibirán incorrecto respuestas.
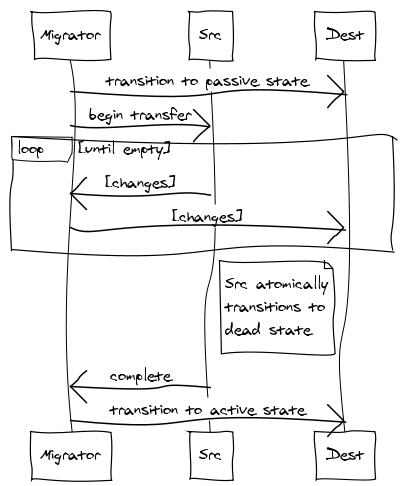
- El vbucket del nuevo servidor se coloca en estado pendiente.
- Un extracto de vbucket pulse se inicia el flujo.
- El flujo de toma de vbucket establece atómicamente el estado a muerto cuando la cola está en un estado de drenaje suficiente.
- El nuevo servidor sólo pasa de pendiente a activo una vez que ha recibido la confirmación de que el servidor antiguo ya no está atendiendo peticiones.Dado que las subsecciones se transfieren de forma independiente, ya no tiene que limitarse a pensar en un servidor moviéndose a la vez, sino en una pequeña fracción de un servidor moviéndose a la vez. Esto permite empezar a migrar lentamente el tráfico de los servidores ocupados. en el pico a servidores menos ocupados con un impacto mínimo (con 4.096 vbuckets en 10 servidores cada uno con 10M de claves, estarías moviendo unas 20k claves a la vez con una transferencia de vbucket al subir tu undécimo servidor).
Usted puede notar que hay un período de tiempo en el que un vbucket tiene no servidor activo en absoluto. Esto ocurre al final del mecanismo de transferencia y provoca el bloqueo. En general, debería ser raro observar a un cliente bloqueado. Esto sólo ocurre cuando un cliente recibe un error del servidor antiguo indicando que ha terminado de preparar la transferencia y puede llegar al nuevo servidor antes de que éste reciba el último elemento. En ese caso, el nuevo servidor sólo bloquea al cliente hasta que ese elemento se entrega y el vbucket puede pasar de pendiente a activo estado.
Aunque el vbucket en el servidor antiguo entra automáticamente en el muerto estado cuando avanza lo suficiente, se no borrar datos automáticamente. Esto se hace explícitamente después de confirmación de que el nuevo nodo se ha ido activo. Si el nodo de destino falla en algún punto antes de que lo fijemos activopodemos abortar la transferencia y dejar el servidor antiguo activo (o ponerlo en activo si estuviéramos lo suficientemente avanzados).
¿Qué es eso del Estado de réplica?
La salud humana es un tema recurrente, así que nos hemos asegurado de cubrirlo. A réplica vbucket es similar a un muerto vbucket en que desde la perspectiva de un cliente normal. Es decir, se rechazan todas las peticiones, pero se permiten los comandos de replicación. Esto también es similar a la pendiente en que se almacenan los registros, pero contrastado en que los clientes no se bloquean.
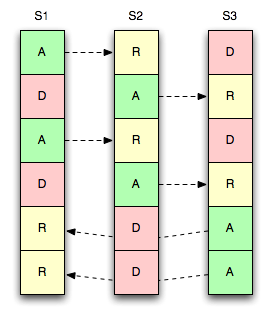
Considera la imagen de la derecha donde tenemos tres servidores, seis vbuckets y una única réplica por vbucket.
Al igual que los maestros, cada réplica también se asigna estáticamente, por lo que pueden moverse en cualquier momento.
En este ejemplo, replicamos el vbucket al "siguiente" servidor de la lista. es decir, un activo vbucket en S1 replica a un réplica cubo en S2 - lo mismo para S2 → S3 y S3 → S1.
Múltiples réplicas
También permitimos estrategias para disponer de más de una copia de sus datos en nodos.
El siguiente diagrama muestra dos estrategias para que tres servidores tengan una réplica activa y dos réplicas de cada bucket.
1:n Replicación
La primera estrategia (1:n) se refiere a un maestro que da servicio a varios esclavos simultáneamente. El concepto es familiar para cualquiera que haya trabajado con software de almacenamiento de datos que permita múltiples réplicas.
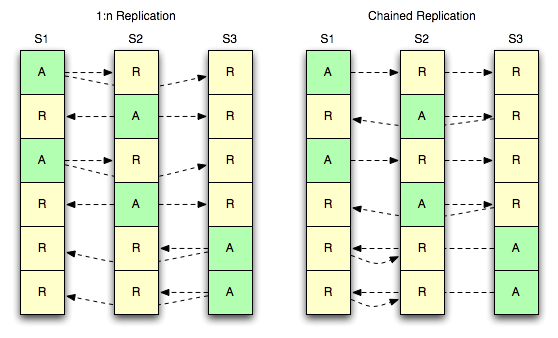
Replicación encadenada
La segunda estrategia (encadenado) se refiere a un único maestro que da servicio a un único esclavo, pero que tiene un esclavo posterior propio. Esto ofrece la ventaja de tener un único flujo de eventos de mutación saliendo de un servidor, mientras se mantienen dos copias de todos los registros. Esto tiene la desventaja de que la latencia de replicación se agrava a medida que se atraviesa la cadena.
Por supuesto, con más de dos copias adicionales, usted podría mezclarlos de tal manera que usted hace un solo flujo fuera del maestro y luego tener el segundo eslabón de la cadena V fuera un 1:n a otros dos servidores.
Todo depende de cómo se planifiquen las cosas.
Agradecimientos
Gracias a Dormando por ayudar a descifrar el código original del "cubo gestionado", la intención y los flujos de trabajo, y Jayesh José y al resto de la gente de Zynga por descubrirlo de forma independiente y trabajar en un montón de casos de uso.
Fantastic blog post. Me ha ayudado a entender muchos conceptos básicos sobre clientes inteligentes, vBuckets y estados de vBucket.
Pregunta: ¿Cómo evitamos que las claves vayan al mismo servidor después de ser hasheadas?