En blogs anteriores se explicaba mejor nuestro enfoque de la Observabilidad en tiempo real (RTO) en general ayuda a solucionar los problemas de los sistemas distribuidos y por qué elegimos OpenTracing como base y API pública. Si aún no lo ha hecho, puede consultar estos blogs aquí y aquí.
En este blog, aprenderá cómo funciona RTO con el SDK de Java y cómo puede utilizarlo hoy en su beneficio.
Primeros pasos
En cuanto se publique la versión 2.6.0 (o posterior) del SDK de Java, podrá obtenerla por los medios habituales descritos a continuación aquí. Dado que esta versión se encuentra ahora mismo en estado de versión preliminar, es necesario acceder a ella desde nuestro propio repositorio maven. A través de un maven pom.xml:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
<dependencies> <dependency> <groupId>com.couchbase.client</groupId> <artifactId>java-client</artifactId> <version>2.6.0-dp1</version> </dependency> </dependencies> <repositories> <repository> <id>cb-pre</id> <name>Couchbase Prerelease Repo</name> <url>https://files.couchbase.com/maven2</url> </repository> </repositories> |
La única diferencia que notará es una nueva dependencia llamada opentracing-api de la que hablaremos más adelante. Dado que no se trata de una versión mayor, todo el código anterior funcionará como antes y te beneficiarás de las mejoras de inmediato.
Si necesita personalizar el propio trazador o parte de su configuración, puede hacerlo a través de la función CouchbaseEntorno.Builder como con el resto de ajustes. Este es un ejemplo de cómo personalizar nuestro trazador predeterminado para reducir el intervalo de tiempo en el que se registra la información:
|
1 2 3 4 5 6 7 |
Tracer tracer = ThresholdLogTracer.create(ThresholdLogReporter.builder() .logInterval(10, TimeUnit.SECONDS) // log every 10 seconds .build()); CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); |
Explicación del registro de umbrales
Para mojarnos los pies con el rastreador de registro de umbrales (que está activado por defecto) vamos a personalizar un poco su configuración y bajar los umbrales tan bajos que prácticamente todas las peticiones y respuestas estén cubiertas. Obviamente esto no es una buena idea para producción, pero nos ayudará a llegar a la salida de registro deseada rápidamente y afirmar su funcionalidad.
Aplique la siguiente configuración como se ha indicado anteriormente:
|
1 2 3 4 5 6 |
Tracer tracer = ThresholdLogTracer.create(ThresholdLogReporter.builder() .kvThreshold(1) // 1 micros .logInterval(1, TimeUnit.SECONDS) // log every second .sampleSize(Integer.MAX_VALUE) .pretty(true) // pretty print the json output in the logs .build()); |
Esto fijará nuestro umbral para las operaciones clave/valor en un microsegundo, registrará las operaciones encontradas cada segundo y fijará el tamaño de la muestra en un valor muy grande para que se registre todo. Por defecto, se registrará cada minuto (si se encuentra algo) y sólo se muestrearán las 10 operaciones más lentas. El umbral por defecto para las operaciones clave/valor es de 500 milisegundos.
Con estas configuraciones en su lugar estamos listos para ejecutar algunas operaciones. Siéntase libre de ajustar la siguiente configuración para que apunte a su servidor y aplique las credenciales apropiadas:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 |
// Connect CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); Cluster cluster = CouchbaseCluster.create(env, "127.0.0.1"); Bucket bucket = cluster.openBucket("travel-sample"); // Load a couple of docs and write them back for(int i = 0; i < 5; i++) { JsonDocument doc = bucket.get("airline_1" + i); if (doc != null) { bucket.upsert(doc); } } Thread.sleep(TimeUnit.MINUTES.toMillis(1)); |
En este sencillo código estamos leyendo algunos documentos de la base de datos viaje-muestra y si lo encuentra lo escribe de vuelta con un upsert. Esto nos permite de forma sencilla realizar operaciones tanto de lectura como de escritura. Una vez ejecutado el código, verás una salida (similar) en los logs:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 |
Apr 04, 2018 9:42:57 AM com.couchbase.client.core.tracing.ThresholdLogReporter logOverThreshold WARNING: Operations over threshold: [ { "top" : [ { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x6", "dispatch_us" : 315, "remote_address" : "127.0.0.1:11210", "total_us" : 576 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x5", "dispatch_us" : 319, "remote_address" : "127.0.0.1:11210", "total_us" : 599 }, { "server_us" : 8, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x4", "dispatch_us" : 332, "remote_address" : "127.0.0.1:11210", "total_us" : 632 }, { "server_us" : 11, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x3", "dispatch_us" : 392, "remote_address" : "127.0.0.1:11210", "total_us" : 762 }, { "server_us" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 9579, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 16533 }, { "server_us" : 56, "encode_us" : 12296, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "upsert:0x2", "dispatch_us" : 1280, "remote_address" : "127.0.0.1:11210", "total_us" : 20935 } ], "service" : "kv", "count" : 6 } ] |
Este es nuestro informador de umbrales en acción. Para cada servicio (sólo kv basado en esta carga de trabajo) le mostrará la cantidad total de operaciones registradas (a través de cuente) y te dará las operaciones más lentas ordenadas por su latencia. Dado que sólo aerolínea_10 existe en el cubo, se ven 5 búsquedas de documentos pero sólo se produce una mutación.
Veamos una operación concreta y hablemos de cada campo con un poco más de detalle:
|
1 2 3 4 5 6 7 8 9 10 |
{ "server_us" : 23, "local_id" : "41837B87B9B1C5D1/000000004746B9AA", "local_address" : "127.0.0.1:55011", "operation_id" : "get:0x1", "decode_us" : 1203, "dispatch_us" : 947, "remote_address" : "127.0.0.1:11210", "total_us" : 1525 } |
Nos dice lo siguiente:
total_us: El tiempo total que se tardó en realizar la operación completa: aquí alrededor de 1,5 milisegundos.servidor_us: El servidor informó de que su trabajo realizado tardó 23 microsegundos (esto no incluye el tiempo de red ni el tiempo en el búfer antes de ser recogido en el clúster).decodificar_nos: El cliente tardó 1,2 milisegundos en descodificar la respuesta.enviar_nos: El tiempo en que el cliente envió la solicitud y obtuvo la respuesta fue de aproximadamente 1 milisegundo.dirección_local: El socket local utilizado para esta operación.dirección_remota: El socket remoto en el servidor utilizado para esta operación. Útil para averiguar qué nodo está afectado.operation_id: Una combinación de tipo de operación e id (en este caso el valor opaco), útil para diagnosticar y solucionar problemas en combinación con la funciónlocal_id.local_id: Con Server 5.5 y posteriores, este id se negocia con el servidor y se puede utilizar para correlacionar la información de registro en ambos lados de una manera más sencilla.
Tenga en cuenta que el formato exacto de este registro es todavía un poco en flujo y va a cambiar entre dp1 y beta / GA versiones.
Se puede ver que si los umbrales se fijan de la forma correcta en función de los requisitos de producción, sin mucho esfuerzo se pueden registrar y localizar las operaciones lentas con más facilidad que antes.
Sin embargo, hay una pieza que falta en el rompecabezas y que vamos a tratar a continuación: cómo se relaciona esto con el temido TimeoutException.
Tiempo de espera Visibilidad
Anteriormente, cuando una operación tardaba más de lo que permitía el tiempo de espera especificado, aparecía un TimeoutException se lanza. Normalmente tiene este aspecto:
|
1 2 3 4 5 6 |
Exception in thread "main" java.lang.RuntimeException: java.util.concurrent.TimeoutException at com.couchbase.client.java.util.Blocking.blockForSingle(Blocking.java:77) at com.couchbase.client.java.CouchbaseBucket.get(CouchbaseBucket.java:131) at Main.main(Main.java:34) Caused by: java.util.concurrent.TimeoutException ... 3 more |
Mirando este stack trace se pueden inferir un par de cosas, por ejemplo que la operación timed out era un GetRequest. Si en tiempo de ejecución necesitas más información, solías tener que envolverla basándote en tu propio contexto. Por ejemplo:
|
1 2 3 4 5 6 7 |
try { bucket.get("foo", 1, TimeUnit.MICROSECONDS); } catch (RuntimeException ex) { if (ex.getCause() instanceof TimeoutException) { throw new RuntimeException(new TimeoutException("id: foo, timeout: 1ms")); } } |
Esto es muy tedioso y todavía no le da una idea del comportamiento interno según sea necesario.
Para remediar esta situación, el nuevo cliente hace (más o menos) lo anterior por ti de forma transparente, pero añade aún más información sin que tengas que hacer nada. El mismo tiempo de espera en el nuevo SDK tendrá el siguiente aspecto:
|
1 2 3 4 5 6 7 8 9 10 |
Exception in thread "main" java.lang.RuntimeException: java.util.concurrent.TimeoutException: localId: 2C12AAA6637FB4FF/00000000147B092F, opId: 0x1, local: 127.0.0.1:60389, remote: 127.0.0.1:11210, timeout: 1000us at rx.exceptions.Exceptions.propagate(Exceptions.java:57) at rx.observables.BlockingObservable.blockForSingle(BlockingObservable.java:463) at rx.observables.BlockingObservable.singleOrDefault(BlockingObservable.java:372) at com.couchbase.client.java.CouchbaseBucket.get(CouchbaseBucket.java:131) at SimpleReadWrite.main(SimpleReadWrite.java:64) Caused by: java.util.concurrent.TimeoutException: localId: 2C12AAA6637FB4FF/00000000147B092F, opId: 0x1, local: 127.0.0.1:60389, remote: 127.0.0.1:11210, timeout: 1000us at com.couchbase.client.java.bucket.api.Utils$1.call(Utils.java:75) at com.couchbase.client.java.bucket.api.Utils$1.call(Utils.java:71) *snip* |
Puede que recuerdes algunos de los campos de la descripción del registro anterior, y eso es lo que se pretende. Ahora el propio tiempo de espera te proporciona información valiosa como los sockets local y remoto, el id de la operación así como el tiempo de espera establecido y el ID local utilizado para la resolución de problemas. Sin esfuerzo extra puedes tomar esta información y correlacionarla con las operaciones más lentas en el registro de umbrales.
En TimeoutException ahora le proporciona más información sobre "qué" fue mal y entonces usted puede ir a mirar el registro para averiguar "por qué" era lento.
Cambiar el Tracer
Por último, hay una función más. Como ya se ha dicho, el nuevo opentracing-api viene incluido por una razón. Sólo proporciona una descripción de la interfaz, pero esto es suficiente para abrir todas estas métricas y estadísticas a todo un universo de implementaciones de trazadores compatibles con OpenTracing. Puedes elegir uno de los disponibles en código abierto como jaegerUtiliza uno proporcionado por los proveedores de APM o incluso escribe el tuyo propio. El punto clave aquí es que el SDK utiliza una interfaz abierta y estandarizada a la que se pueden conectar otras cosas, incluyendo un Tracer útil y básico.
Como ejemplo, aquí está cómo usted puede intercambiar en nuestro trazador por defecto con uno de jaeger:
|
1 2 3 4 5 6 7 8 9 10 |
Tracer tracer = new Configuration( "my_app", new Configuration.SamplerConfiguration("const", 1), new Configuration.ReporterConfiguration( true, "localhost", 5775, 1000, 10000) ).getTracer(); CouchbaseEnvironment env = DefaultCouchbaseEnvironment.builder() .tracer(tracer) .build(); |
Sin ningún cambio en la aplicación real, todas las trazas y barridos se introducirán ahora en un motor de trazado distribuido en el que dispondrás de bonitas interfaces de usuario para visualizar el comportamiento del entorno de tu aplicación.
Una operación get como la del ejemplo anterior puede tener este aspecto en la página de resumen de jaeger:
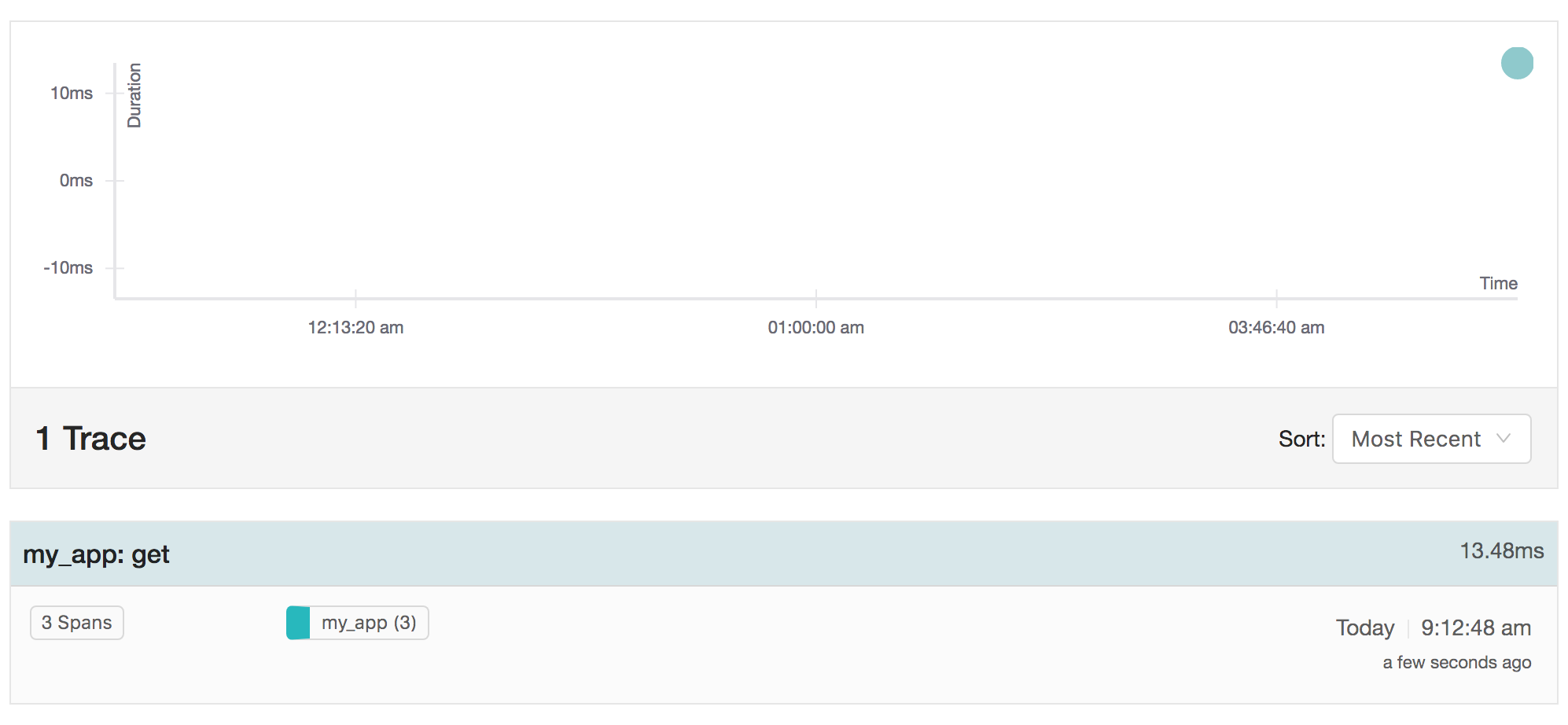
Al profundizar en la traza específica, se hacen visibles los tiempos de cada tramo y subtramo:
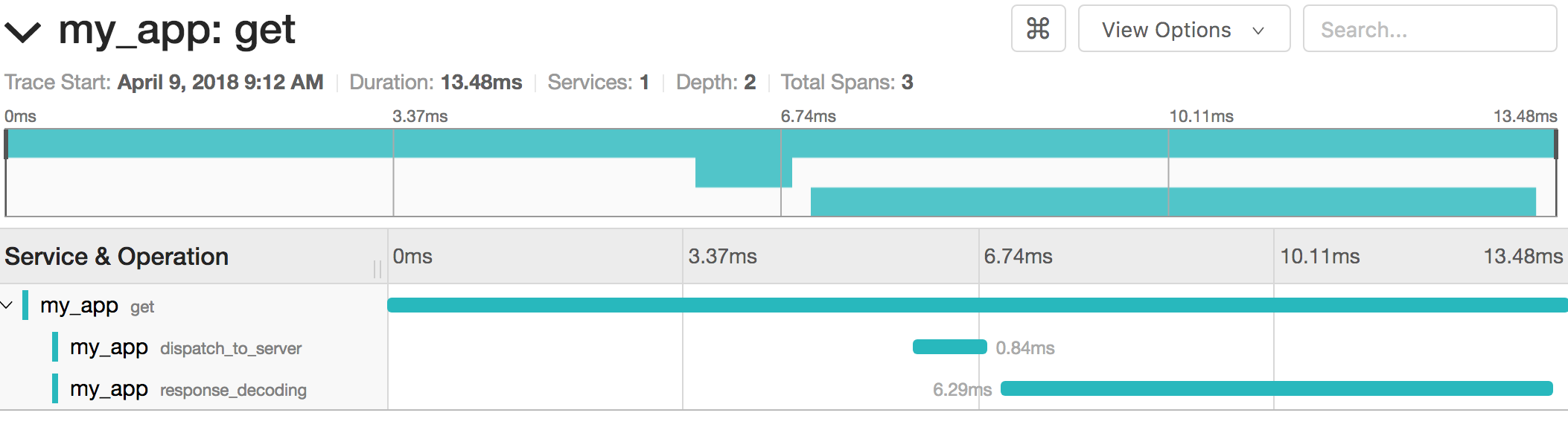
Cada tramo también contiene etiquetas que el SDK adjunta para un filtrado y análisis avanzados:
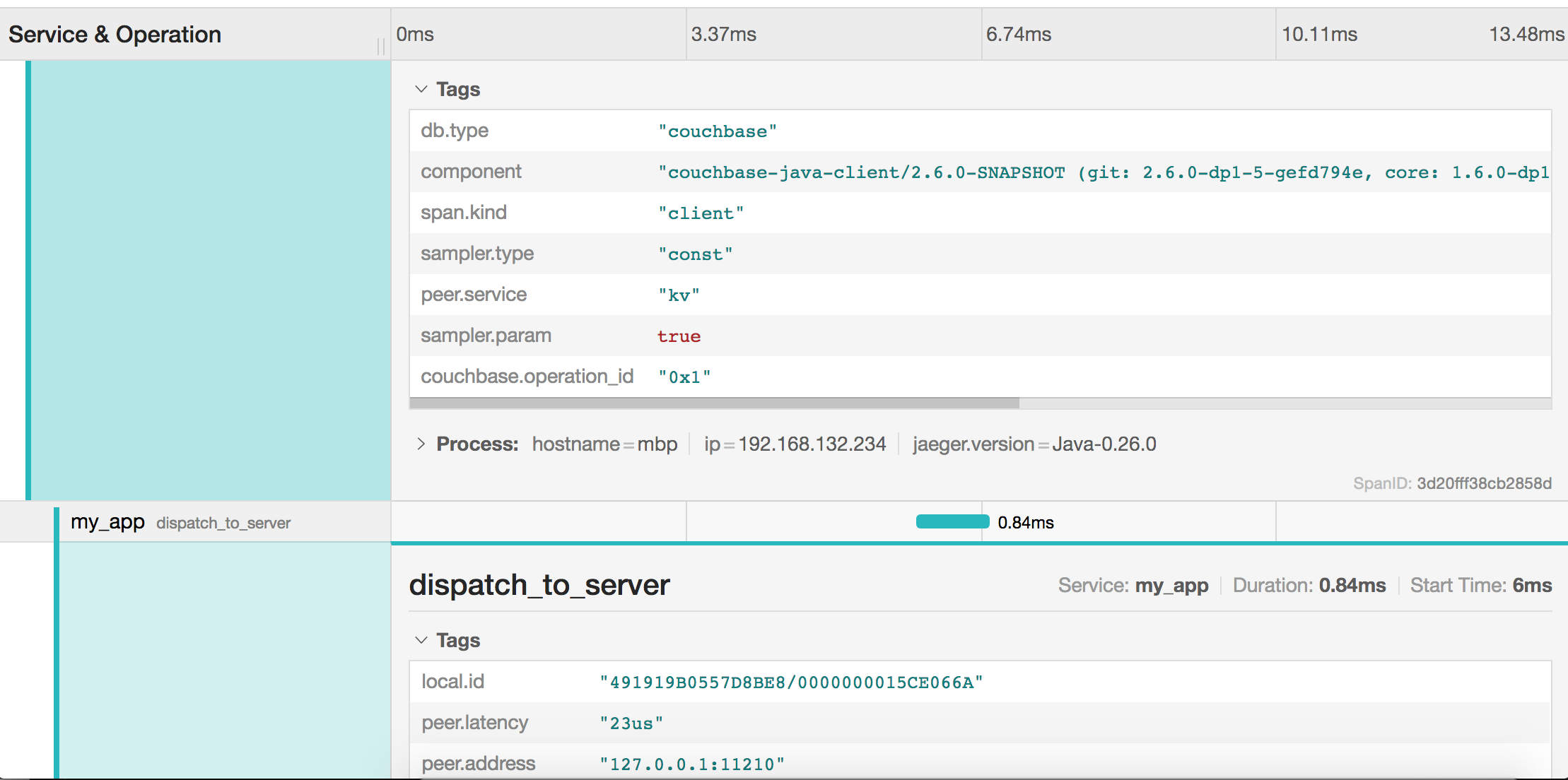
Resumen
Al mejorar nuestros SDK con Response Time Observability, ahora podemos proporcionar una visión más profunda de qué y por qué algo no funciona/rendimiento como se esperaba. Confiando en OpenTracing como interfaz, además, podemos hacer que sea independiente del proveedor y abrir la posibilidad de conectar la herramienta APM/tracing compatible de su elección si es necesario.