Últimamente se habla mucho del almacenamiento de clase empresarial. Pure Storage, líder reconocido en el sector, nos dio recientemente la oportunidad de desplegar Couchbase en uno de sus entornos de laboratorio. El clúster de 8 nodos fue capaz de soportar fácilmente una carga de trabajo de 1 millón de operaciones/segundo de escritura 100%. Se generó una carga de trabajo de 1.000.000 de escrituras/segundo utilizando nuestra herramienta pillowfight ejecutada desde uno de los nodos del clúster con los siguientes parámetros:
Esta carga de escritura sostenida de 1 millón de escrituras por segundo del clúster tiene el siguiente aspecto:

Esta carga de trabajo, aunque impresionante, no ejercitó la matriz de almacenamiento en lo más mínimo. De hecho, era difícil incluso localizar mucha carga en absoluto en el Pure Dashboard. La razón de esto, es que con pillowfight utilizamos un documento de 64 bytes exclusivamente. Es una carga de trabajo perfectamente razonable cuando se considera un caso de uso de internet de las cosas con un montón de pequeñas claves/valores escritos a alta velocidad. ¿Y en el caso de un almacén de perfiles de usuario? ¿Cómo se comportaría una carga de trabajo de escritura de alta velocidad 100% en este entorno utilizando una aplicación del mundo real y datos de perfil de usuario con un estilo realista?
Arnés de prueba
Para esta aplicación se requiere un arnés de pruebas y un generador de carga de rápido despliegue y node.js es la plataforma perfecta. El código fuente está disponible en github . Primero se necesita un objeto de capa de datos con un método de creación:
var punto final=“10.21.16.121:8091”;
var grupo = nuevo couchbase.Grupo(punto final);
var db = racimo.openBucket("usuario",función (err) {
si (err) {
consola.registro(=>ERROR CONEXIÓN DB:', err);
}
});
función crear(clave, artículo){
db.upsert(clave, artículo, función(err, resultado){
si(err){
}si no {
}
});
}
A continuación, se necesita una forma de crear usuarios. Utilizar la maravillosa librería "faker.js" para crear usuarios simplifica esta tarea. Usar faker para crear un usuario es increíblemente simple, y hay funciones de ayuda que abstraen esta funcionalidad aún más. Creando un simple bucle for los usuarios son creados con faker y pasados a la capa de datos descrita anteriormente:
para(i=0;i<límite;i++){
var u=farsante.ayudantes.userCard();
conexión.db.crear(u.correo electrónico,u);
}
}
Se requiere un bucle de control para realizar la ingesta en Couchbase:
checkOps(función(hecho){
consola.registro(hecho);
si (parseInt(hecho, 10) < umbral) {
loadTextUserProfile(testBatch);
consola.registro("INGEST:Añadido:",testBatch);
}
si no {
consola.registro("INGEST:Ocupado:", hecho);
}
});
}, testInterval
);
El bucle de control hace uso de la lógica de estrangulamiento, que es una buena característica para cualquier tipo de prueba de rendimiento y análisis de estrés. Esta función llama al punto final de reposo en un nodo del clúster y comprueba cuántas operaciones por segundo está procesando actualmente el clúster:
http.consiga("https://" + punto final + "/pools/default/buckets/user", función (res) {
var datos=“”;
res.setEncoding(utf8);
res.en(datos, función (trozo) {
datos += trozo;
});
res.en(Fin,función(){
var analizado=JSON.analizar(datos);
opsV(analizado.basicStats.opsPerSec);
});
});
}
Resultados
Al igual que en el caso de uso del Internet de las cosas, los resultados de rendimiento del almacén de perfiles de usuario fueron impresionantes. En poco tiempo fuimos capaces de generar cerca de 500 millones de usuarios, con una carga de trabajo sostenida de 400.000 escrituras por segundo.
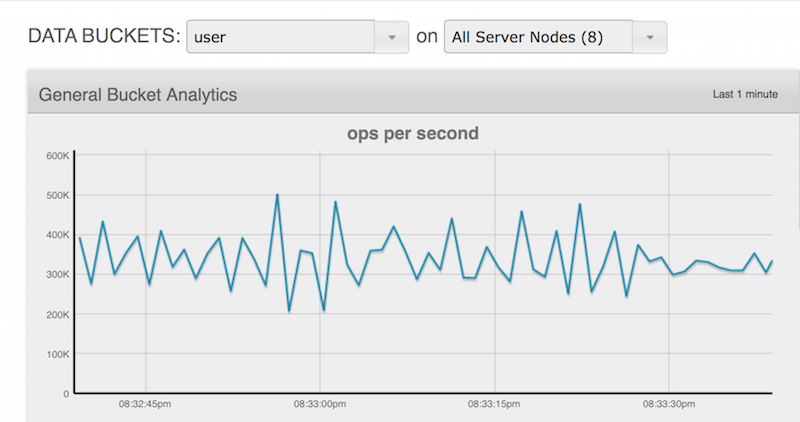
Para mantener el interés, utilizamos el desalojo completo y ajustamos la memoria para que fuera aproximadamente 10% del tamaño final del conjunto de datos.

El sistema Pure funcionó a la perfección. Alcanzamos los límites de procesamiento de la CPU mucho antes de que el sistema de almacenamiento se quedara sin margen:
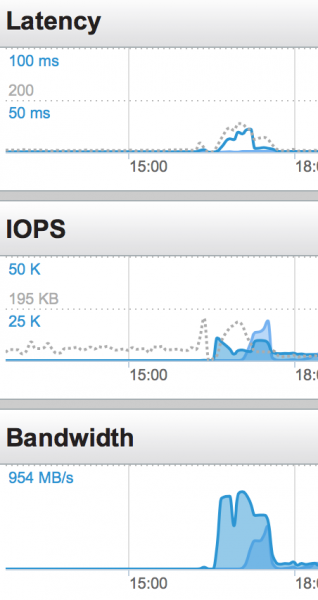
Aún más impresionante que el propio rendimiento de la carga de trabajo es la huella de almacenamiento. Este es uno de los aspectos más difíciles del almacenamiento en un sistema distribuido. La tecnología de desduplicación de Pure es excepcional.

Al utilizar una granularidad de 512 bytes, una precisión 4 veces más fina que la de los sistemas de la competencia, Pure es capaz de desduplicar eficazmente una carga de trabajo realmente difícil. En nuestro entorno de pruebas, que genera usuarios falsos, los datos son aleatorios y están distribuidos uniformemente. En una carga de trabajo del mundo real, cabría esperar que la desduplicación fuera aún mejor. Con el conjunto de datos de usuarios aleatorios vimos una desduplicación consistente de 1,6 a 1, con 1 réplica de Couchbase habilitada. Esperamos realizar más pruebas comparativas con la tecnología de Pure en el futuro, y estamos entusiasmados con el rendimiento de Couchbase utilizando su sistema.