La sintaxis de las consultas es limitada. Las consultas son ilimitadas.
Predicado pushdown, agrupar por pushdown, paginación offset, paginación de teclas, optimización de la unión, optimización de la búsquedaya hemos hablado de todo. Aun así, es importante entender el flujo de ejecución de la consulta por defecto, sencillo, aunque lento.
Lukas Eder ha explicado el orden real de ejecución de SQL. Dado que N1QL se inspira en SQL y lo sigue de cerca, esa explicación también es válida aquí. Recomiendo encarecidamente su lectura.
Con N1QL, puede utilizar la explicación visual para ver la estructura del plan y el flujo de datos. Esta es una manera fácil de entender el orden de ejecución antes de optimizar el rendimiento mediante la creación de índices. He usado el ejemplo de recorrido incorporado y por lo tanto forzado el escaneo primario con la sugerencia USE INDEX.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
SELECT hotel.name, hotel.country, COUNT(hr.ratings.Service) csr, RANK() OVER(ORDER BY COUNT(hr.ratings.Service) ), DENSE_RANK() OVER(ORDER BY COUNT(hr.ratings.Service)) FROM `travel-sample` AS hotel USE INDEX (def_primary) INNER JOIN `travel-sample` AS airport ON (hotel.country = airport.country) LEFT OUTER UNNEST hotel.reviews AS hr WHERE hotel.type = "hotel" AND airport.type = "airport" AND hr.ratings.Service >= 4 GROUP BY hotel.name, hotel.country HAVING COUNT(hr.ratings.Service) > 0 ORDER BY COUNT(hr.ratings.Service) OFFSET 0 LIMIT 10 |
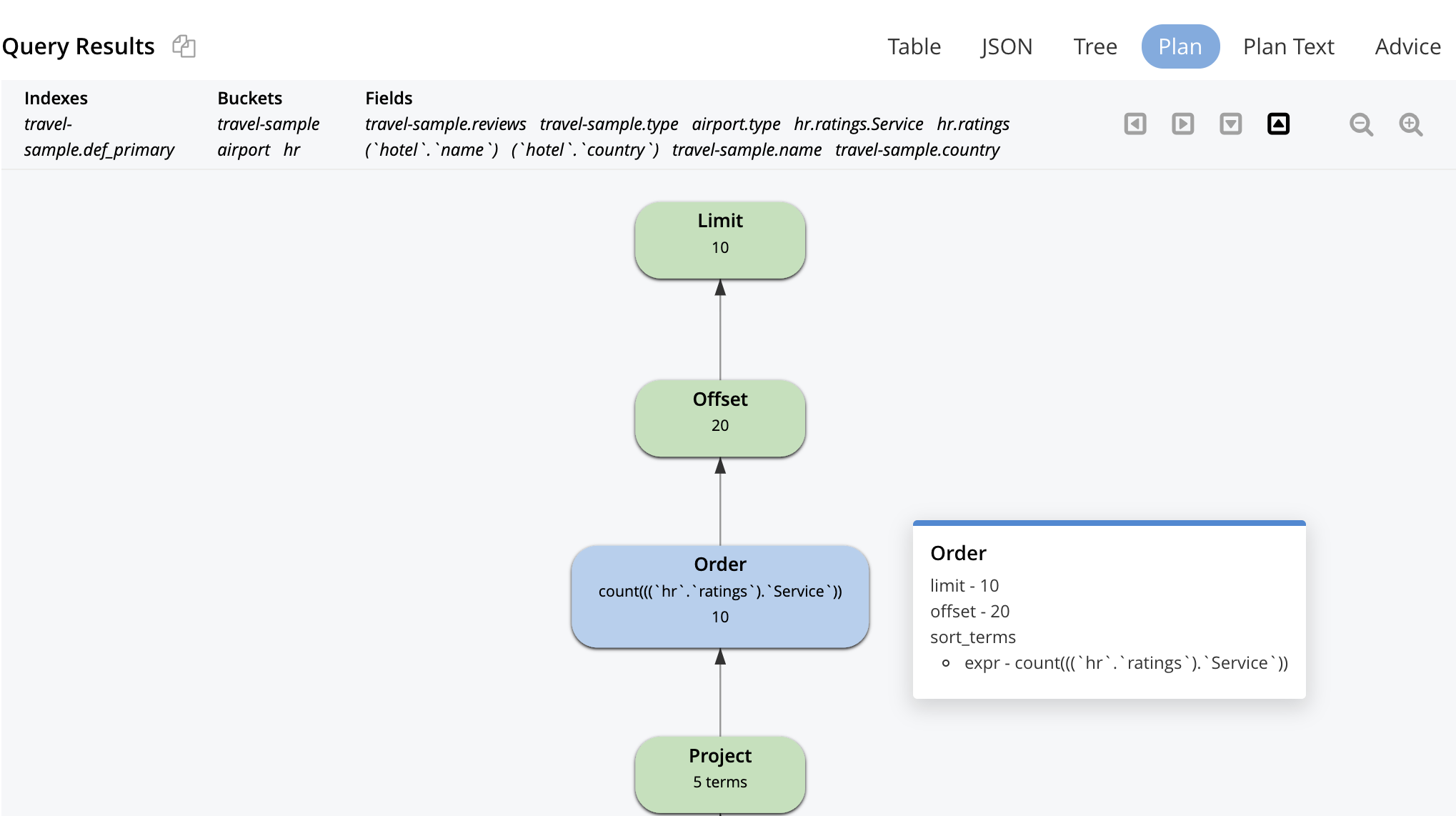
Este es el plan visual. La ejecución del plan y el flujo de datos es ascendente. Comienza con el escaneo del índice primario y un escaneo del índice secundario, termina con el operador de paginación LIMIT antes de devolver los resultados a la aplicación.
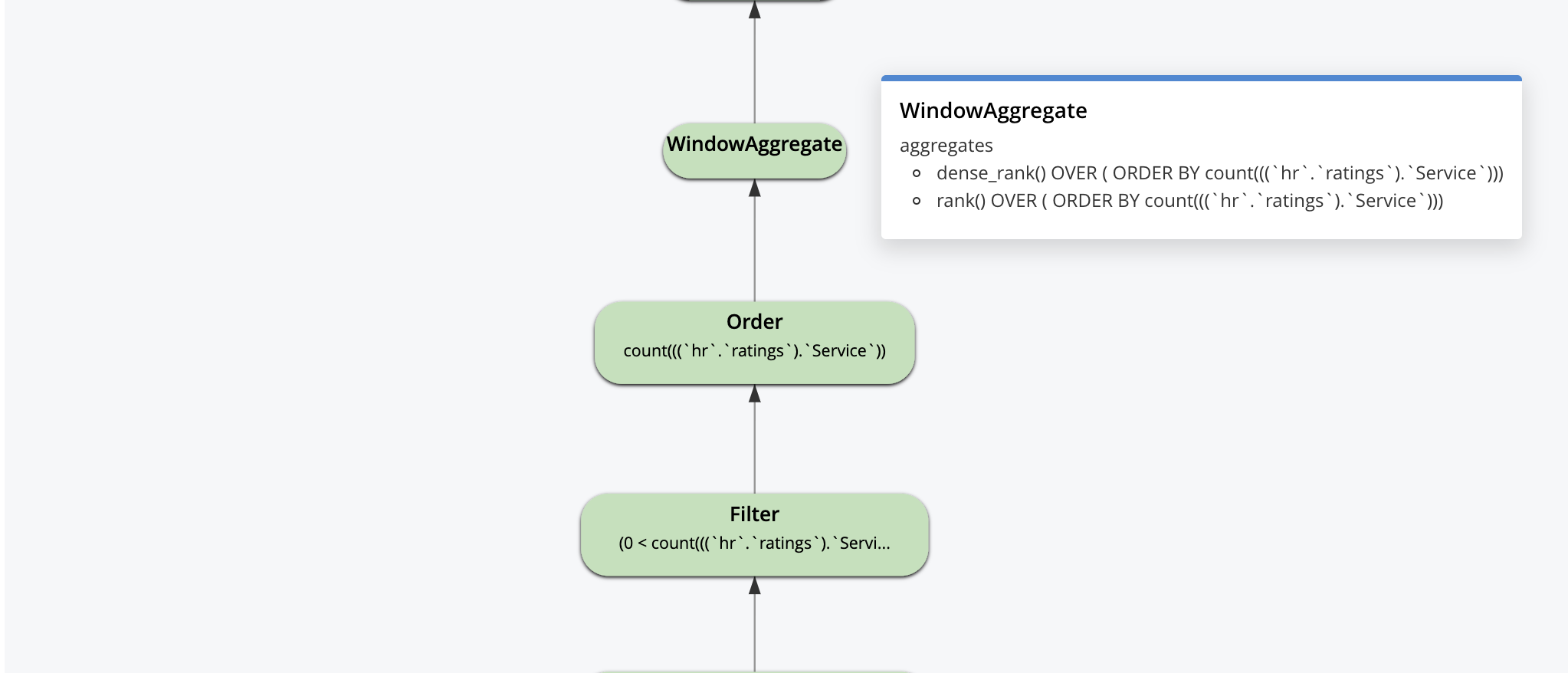
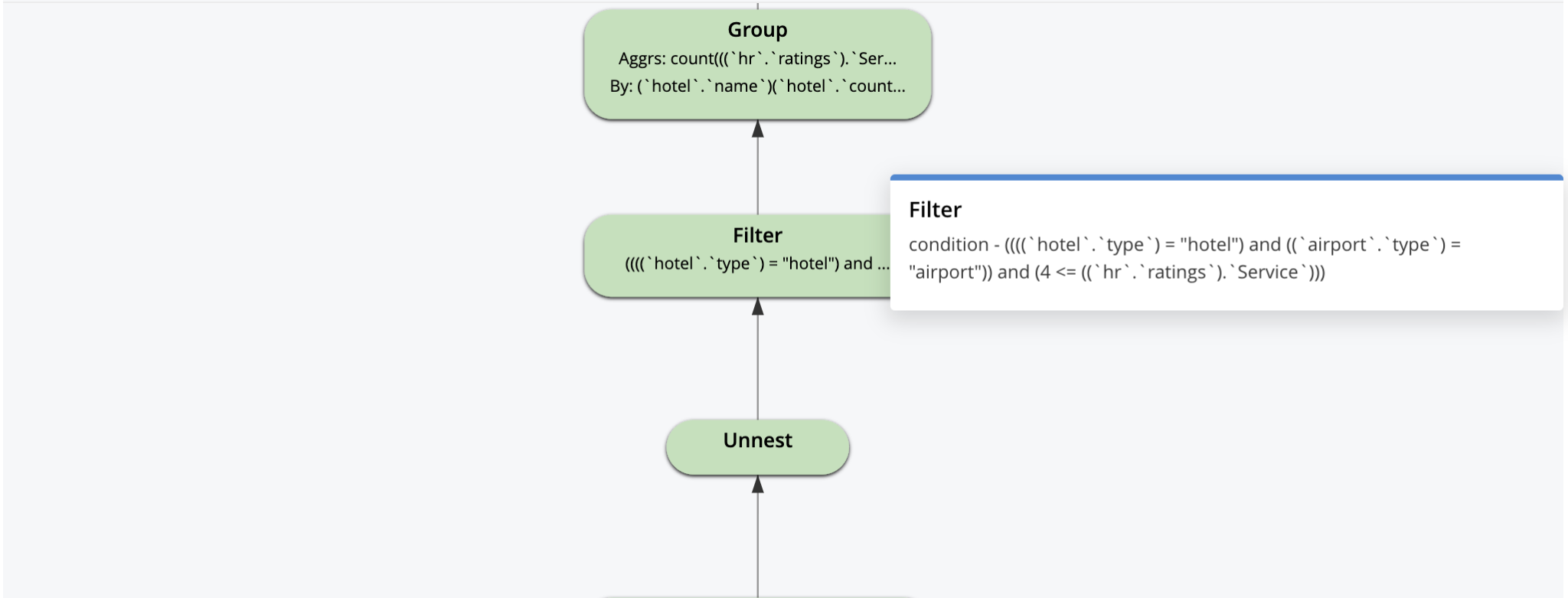
La explicación visual es interactiva. Puede hacer clic en cada operador para ver los parámetros establecidos para ese operador por el optimizador, como se muestra para algunos de los operadores a continuación.
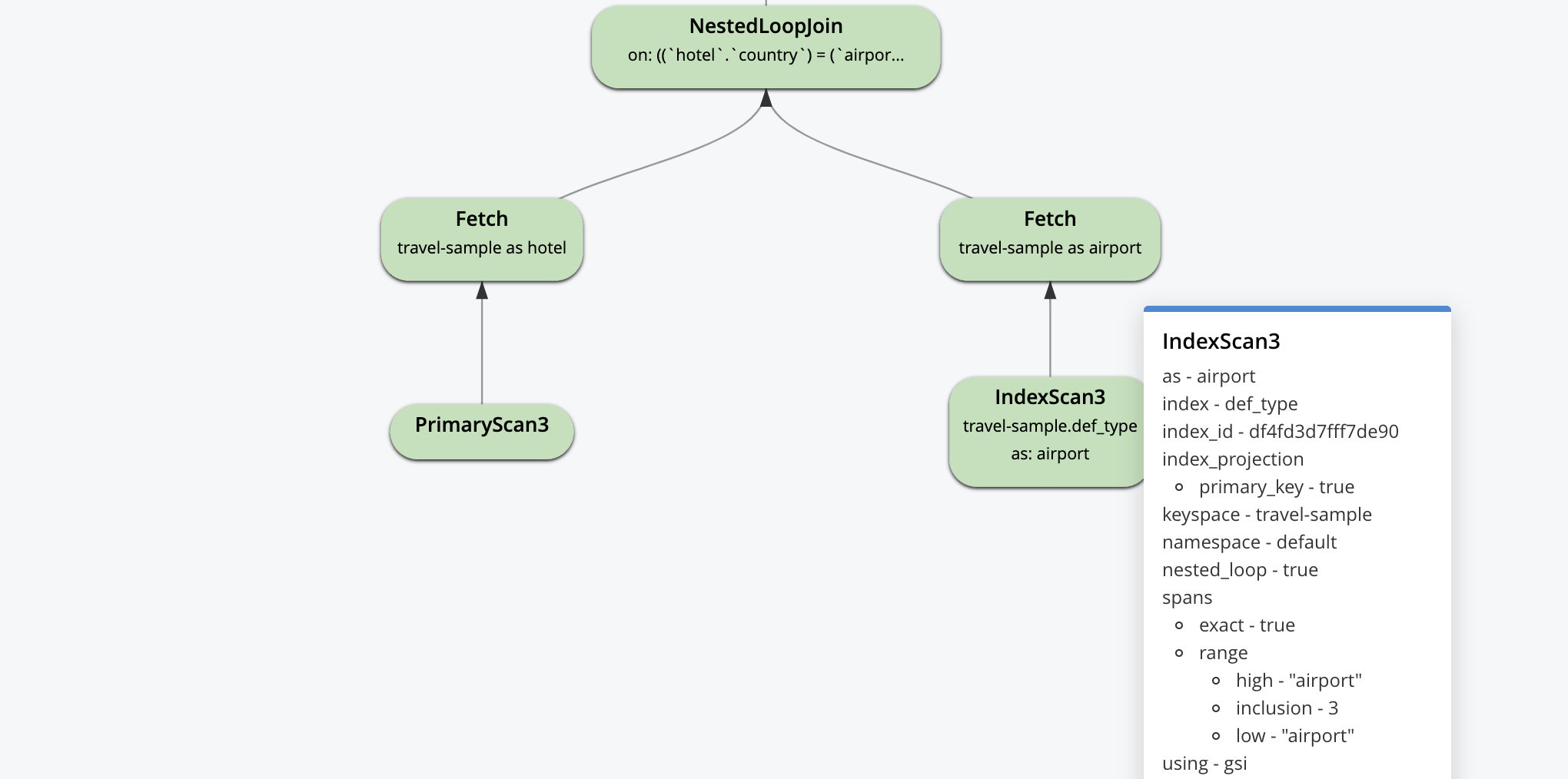
El plan de consulta comienza con esto, lógicamente. Cada optimización por encima de esto es pensada por personas/herramientas y seleccionada por el optimizador para construir una máquina de flujo de datos para cada consulta. El objetivo del optimizador es crear máquinas que hagan el menor trabajo posible y, aún así, ofrezcan los resultados correctos.