El objetivo de Couchbase es permitir que cada vez más aplicaciones empresariales aprovechen y adopten el modelo de datos NoSQL/JSON. N1QL simplifica esta transición de las bases de datos relacionales tradicionales, y está construido con toneladas de características para lograr lo mejor de ambos mundos. Continuando el tren de Couchbase Server 4.5, la versión 4.5.1 trae múltiples mejoras de funcionalidad, usabilidad y rendimiento en N1QL. Estas mejoras abordan muchos de los problemas críticos de nuestros clientes, y en general muestran la fuerza y sofisticación de N1QL.
Mientras que algunas de las nuevas mejoras mejoran la funcionalidad existente, otras, como la función SUFFIXES(), enriquecen las consultas N1QL con una mejora del rendimiento de las consultas LIKE. Otras mejoras se refieren a la creación y manipulación dinámica de objetos JSON, la precisión de los números, la sintaxis UPDATE para matrices anidadas, etc,
Estoy seguro de que esto necesitará una serie, pero en este blog destacaré las mejoras de LIKE-query y UPDATE. Ver Couchbase Server 4.5.1 Novedades y notas de la versión para consultar la lista completa de mejoras de N1QL. ¡Felicitaciones al equipo de N1QL!
Comparación eficaz de patrones en consultas LIKE con SUFFIXES()
La concordancia de patrones es una funcionalidad muy utilizada en las consultas SQL, y normalmente se consigue utilizando el operador LIKE. En particular, es muy importante que la búsqueda de comodines sea eficiente. LIKE 'foo%' puede implementarse eficientemente con un índice estándar, pero no LIKE '%foo%'. Este tipo de coincidencia de patrones con comodín inicial es vital para cualquier aplicación que tenga un cuadro de búsqueda para coincidir con palabras parciales o para sugerir de forma inteligente un texto coincidente. Por ejemplo,
- Un sitio web de reservas de viajes que quiere mostrar aeropuertos coincidentes cuando el usuario empieza a introducir algunas letras del nombre del aeropuerto.
- Un usuario que busca todos los correos electrónicos con una palabra específica o parcial en el asunto.
- Encontrar todos los temas de un foro o entradas de blog con palabras clave específicas en el título.
En Couchbase Server 4.5.1, N1QL aborda este problema añadiendo una nueva función de cadena SUFFIXES(), y combinándola con la funcionalidad de Indexación de Array introducida en Couchbase Server 4.5. Juntas, aportan una diferencia de magnitud al rendimiento de las consultas LIKE con comodines principales como LIKE "%foo%". La funcionalidad principal de SUFFIXES() es muy simple, básicamente produce un array de todas las posibles subcadenas de sufijos de una cadena dada. Por ejemplo
|
1 |
SUFIXES("N1QL") = [ "N1QL", "1QL", "QL", "L" ] |
La siguiente imagen muestra una técnica única para combinar SUFIXES() con la indexación de matrices para impulsar mágicamente COMO rendimiento de la consulta.
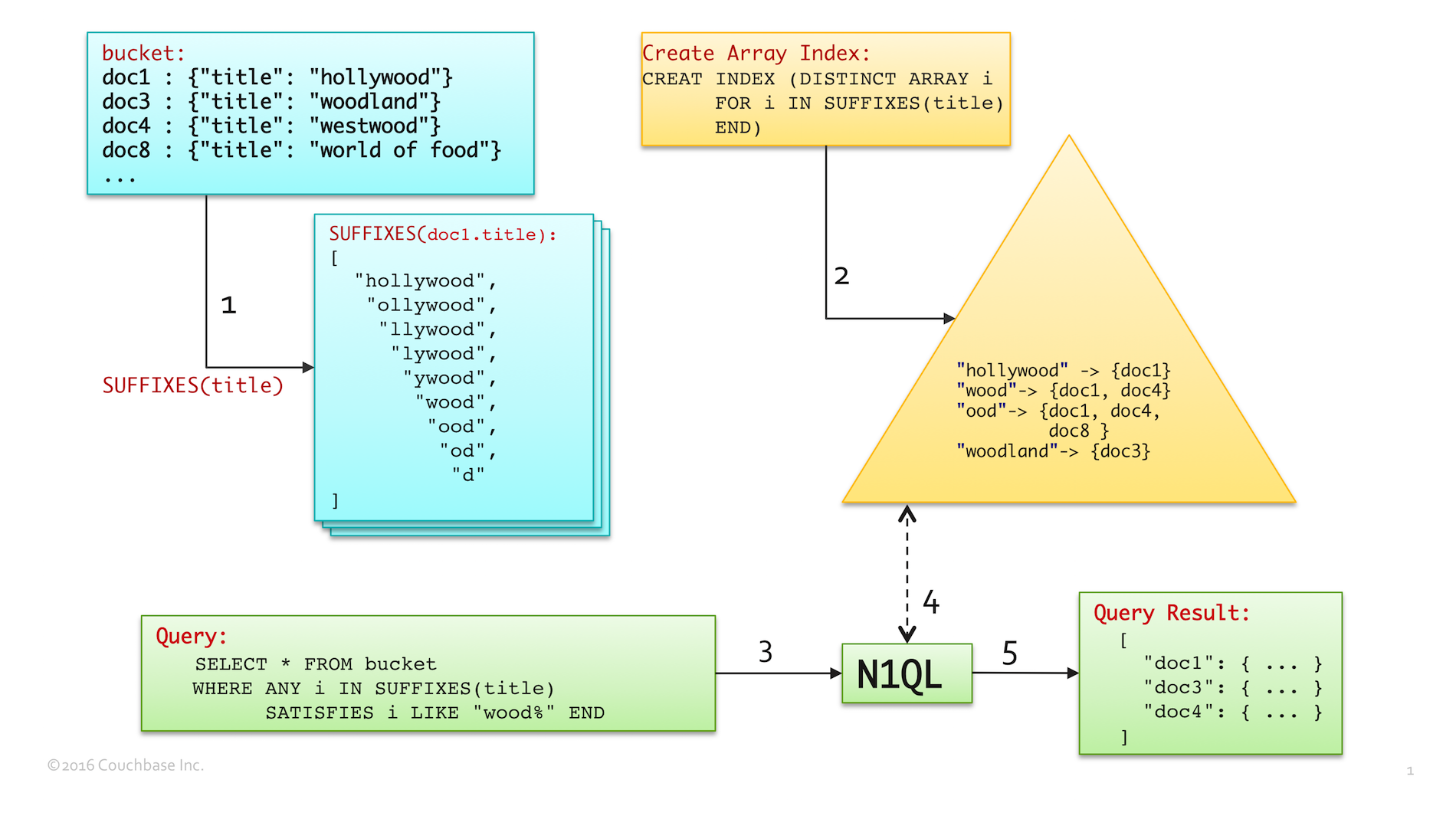
- Paso1 (en azul) muestra la matriz de subcadenas de sufijos generada por
SUFIXES()paradoc1.title - El paso2 (en amarillo) muestra el índice de matriz creado con las subcadenas de sufijos generadas en el paso1. Observe que la entrada de índice para
"madera"señaladoc1ydoc4ya que es una de las subcadenas de sufijos de los títulos de ambos documentos. Del mismo modo,"ood"señaladoc1,doc4ydoc8. - El paso 3 (en verde) ejecuta una consulta equivalente a
SELECT title FROM bucket WHERE title LIKE "%wood%". El predicado LIKE se transforma para utilizar el índice de array utilizando la construcción ANY. Consulte la documentación para obtener más detalles sobre el uso de la indexación de matrices.- Tenga en cuenta que, el comodín inicial se elimina en el nuevo
LIKE "madera%"predicado. - Se trata de una transformación precisa, ya que la búsqueda de índices de matriz para
"madera"apunta a todos los documentos cuyo título tiene la subcadena final"madera"
- Tenga en cuenta que, el comodín inicial se elimina en el nuevo
- En el paso 4, N1QL busca en el índice de matrices todos los documentos que coincidan con
"madera%". Que devuelve{doc1, doc3, doc4}porque- la búsqueda en el índice produce un span, que obtiene documentos de
"madera"a"wooe" doc1ydoc4coinciden debido a la entrada de índice "madera" que genera SUFFIXES() al crear el índice de la matriz.doc3coincide debido a su correspondiente entrada de índice para"bosque"
- la búsqueda en el índice produce un span, que obtiene documentos de
- Por último, en el paso 5, N1QL devuelve los resultados de la consulta.
Veamos un ejemplo práctico con el viaje-muestra que multiplicaron por 12 el rendimiento de la consulta.
- Supongamos un documento con un campo de cadena cuyo valor son unas pocas palabras de texto o una frase. Por ejemplo, el título de un monumento, la dirección de un lugar, el nombre de un restaurante, el nombre completo de una persona/lugar, etc., Para esta explicación, consideramos
títulodehitodocumentos enviaje-muestra. - Crear índice secundario en
títulocampo utilizandoSUFIXES()como:
123CREAR ÍNDICE idx_title_suffixEN `viaje-muestra`(DISTINTO ARRAY s PARA s EN SUFIXES(título) FIN)DONDE tipo = "hito";
SUFIXES(título)genera todas las posibles subcadenas de sufijos detítuloy el índice tendrá entradas para cada una de esas subcadenas, todas ellas referenciando a los documentos correspondientes. - Consideremos ahora la siguiente consulta, que busca todos los documentos con la subcadena
"tierra"entítulo. Esta consulta produce el siguiente plan, y se ejecuta en aproximadamente 120ms en mi portátil. Usted puede ver claramente, que obtiene todos loshitoy, a continuación, aplica elLIKE "%land%"para encontrar todos los documentos coincidentes.
12345678910111213141516171819202122232425262728293031323334353637383940414243EXPLICAR SELECCIONAR * DESDE `viaje-muestra` UTILICE ÍNDICE(def_tipo) DONDE tipo = "hito" Y título COMO "%land%";[{"plan": {"#operator": "Secuencia","~niños": [{"#operator": "IndexScan","índice": "def_type","index_id": "e23b6a21e21f6f2","espacio clave": "viaje-muestra","espacio de nombres": "por defecto","vanos": [{"Rango": {"Alto": [""hito""],"Inclusión": 3,"Bajo": [""hito""]}}],"usando": "gsi"},{"#operator": "Fetch","espacio clave": "viaje-muestra","espacio de nombres": "por defecto"},{"#operator": "Paralelo","~niño": {"#operator": "Secuencia","~niños": [{"#operator": "Filtro","condición": "(`viaje-muestra`.`tipo`) = "hito") y ((`viaje-muestra`.`título`) como "%terreno%"))"}]} - En Couchbase 4.5.1, esta consulta puede reescribirse para aprovechar el índice de array
idx_title_suffixcreado en (2).
12345678910111213141516171819202122232425262728293031323334353637383940414243444546EXPLICAR SELECCIONE título DESDE `viaje-muestra` UTILICE ÍNDICE(idx_title_suffix) DONDE tipo = "hito" YCUALQUIER s EN SUFIXES(título) SATISFACE s COMO "land%" FIN;[{"plan": {"#operator": "Secuencia","~niños": [{"#operator": "DistinctScan","escanear": {"#operator": "IndexScan","índice": "idx_title_suffix","index_id": "75b20d4b253214d1","espacio clave": "viaje-muestra","espacio de nombres": "por defecto","vanos": [{"Rango": {"Alto": [""carril""],"Inclusión": 1,"Bajo": [""terreno""]}}],"usando": "gsi"}},{"#operator": "Fetch","espacio clave": "viaje-muestra","espacio de nombres": "por defecto"},{"#operator": "Paralelo","~niño": {"#operator": "Secuencia","~niños": [{"#operator": "Filtro","condición": "(`viaje-muestra`.`tipo`) = "hito") y cualquier `s` en sufijos((`muestra-de-viaje`.`título`)) satisface (`s` como "terreno%") fin)"},
Tenga en cuenta que:
- La nueva consulta de (4) utiliza
LIKE "land%"en lugar deLIKE "%land%". El predicado anterior sin comodín inicial'%'produce una búsqueda de índice mucho más eficiente que la posterior, que no puede empujar el predicado al índice. - el índice de la matriz
idx_title_suffixse crea con todas las posibles subcadenas de sufijos detítuloy, por lo tanto, la búsqueda de cualquier subcadena del sufijo del título puede encontrar una coincidencia satisfactoria. - en el plan de consulta 4.5.1 anterior de (4), N1QL desplaza el predicado LIKE a la búsqueda del índice y evita el procesamiento adicional de cadenas de concordancia de patrones. Esta consulta se ejecutó en 18 ms.
- De hecho, con el siguiente índice de matriz de cobertura, la consulta se ejecutó en 10 ms, es decir, 12 veces más rápido.
|
1 2 3 |
CREAR ÍNDICE idx_title_suffix_cover EN `viaje-muestra`(DISTINTO ARRAY s PARA s EN SUFIXES(título) FIN, título) DONDE tipo = "hito"; |
Ver esto blog para más detalles sobre una aplicación real de esta función.
Mejoras en UPDATE para trabajar con matrices anidadas
Las aplicaciones empresariales suelen tener datos complejos y necesitan modelar documentos JSON con varios niveles de objetos y matrices anidados. N1QL soporta expresiones complejas y construcciones de lenguaje para navegar y consultar tales documentos con matrices anidadas. N1QL también soporta Indexación de matricescon el que se pueden crear índices secundarios sobre los elementos de la matriz y consultarlos posteriormente.
En Couchbase Server 4.5.1, la función ACTUALIZACIÓN para navegar por matrices anidadas en documentos y actualizar campos específicos en elementos de matrices anidadas. La página PARA-cláusula de la ACTUALIZACIÓN se ha mejorado para evaluar funciones y expresiones, y la nueva sintaxis permite anidar varias sentencias PARA para acceder y actualizar campos en matrices anidadas.
Considere el siguiente documento con matriz anidada como:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
{ artículos: [ { subpuntos: [ { nombre: "N1QL" }, { nombre: "GSI" } ] } ], docType: "couchbase" } |
El nuevo ACTUALIZACIÓN de 4.5.1 puede utilizarse de diferentes formas para acceder y actualizar matrices anidadas:
-
12ACTUALIZACIÓN por defecto SET s.nuevoCampo = nuevoValorPARA s EN ARRAY_FLATTEN(artículos[*].subpuntos, 1) FIN;
-
123ACTUALIZACIÓN por defectoSET s.nuevoCampo = nuevoValorPARA s EN ARRAY_FLATTEN(ARRAY i.subpuntos PARA i EN artículos FIN, 1) FIN;
-
123ACTUALIZACIÓN por defectoSET i.subpuntos = ( ARRAY OBJECT_ADD(s, nuevoCampo, nuevoValor)PARA s EN i.subpuntos FIN ) PARA i EN artículos FIN;
Tenga en cuenta que:
- En
SET-evalúa funciones comoOBJECT_ADD()yARRAY_FLATTEN() PARApueden utilizarse de forma anidada con expresiones para procesar elementos de matrices en diferentes niveles de anidación.
Para ver un ejemplo práctico, considere el cubo de muestra viaje-muestra incluido en 4.5.1.
- En primer lugar, vamos a añadir una matriz anidada de vuelos especiales a la matriz de programación en
viaje-muestracubo, para algunos documentos.
123456ACTUALIZACIÓN `viaje-muestra`SET horario[0] = {"día" : 7, "vuelos_especiales" :[ {"vuelo" : "AI444", "utc" : "4:44:44"},{"vuelo" : "AI333", "utc" : "3:33:33"}] }DONDE tipo = "ruta" Y destinoaeropuerto = "CDG" Y fuenteaeropuerto = "TLV"; - La siguiente sentencia UPDATE añade un tercer campo a cada vuelo especial:
12345678910111213141516171819202122232425262728ACTUALIZACIÓN `viaje-muestra`SET i.vuelos_especiales = ( ARRAY OBJECT_ADD(s, nuevoCampo, nuevoValor )PARA s EN i.vuelos_especiales FIN )PARA i EN horario FINDONDE tipo = "ruta" Y destinoaeropuerto = "CDG" Y fuenteaeropuerto = "TLV";SELECCIONE horario[0] de `viaje-muestra`DONDE tipo = "ruta" Y destinoaeropuerto = "CDG" Y fuenteaeropuerto = "TLV" LÍMITE 1;[{"$1": {"día": 7,"vuelos_especiales": [{"vuelo": "AI444","nuevoCampo": "nuevoValor","utc": "4:44:44"},{"vuelo": "AI333","nuevoCampo": "nuevoValor","utc": "3:33:33"}]}}]
Hay muchas más mejoras importantes en N1QL y características de rendimiento en la versión 4.5.1 de Couchbase Server. Escribiré sobre ellas en mi siguiente blog/parte2.
Descargar 4.5.1 y pruébalo. Hágame saber cualquier pregunta / comentario, o simplemente lo impresionante que es ;-)
¡Salud!