Ampliación de la búsqueda de texto completo en Couchbase Server 4.5 Beta
Couchbase Server 4.5 incluye un nuevo servicio, búsqueda de texto completo (BTS) . En este blog, voy a hablar de cómo FTS escala a través de nodos, cómo replicar índices, y cómo se comporta en un reequilibrio.
Desde el lanzamiento de Couchbase Server 4.5 Developer Preview, el equipo de FTS ha estado ocupado. La versión beta de Couchbase Server 4.5 no sólo elimina un montón de errores de FTS, sino que también incluye muchas grandes mejoras del FTS:
- Indexación 12 veces más rápida
- mejores estadísticas
- compatibilidad con la autenticación y el control de acceso basado en funciones
- registro de auditoría de los eventos del administrador
- apoyo a los resultados parciales
La nueva característica de búsqueda más notable en la beta 4.5 es la capacidad de ejecutar el servicio FTS a través de múltiples nodos. Puedes probarlo hoy con la beta, y lo que leas aquí se seguirá aplicando cuando Couchbase Server 4.5 pase a GA.
Permítanme quitarme de en medio el descargo de responsabilidad: FTS seguirá siendo una vista previa para desarrolladores en la versión GA de Couchbase Server 4.5, así que no lo ejecute en un servidor de producción, por favor.. FTS tiene muchas funciones muy útiles, pero aún no hemos marcado todas las casillas de rendimiento y pruebas de sistema de nuestra lista de tareas pendientes. Por otro lado, eso nos da la oportunidad de abordar algunas de las opiniones que estamos recibiendo de los primeros usuarios de prueba. (¿Tienes comentarios? No dudes en enviarme un correo electrónico directamente a will dot gardella at couchbase dot com)
Ok, vamos a lo bueno. Puedes usar el servicio de búsqueda para indexar y buscar texto en tus documentos Couchbase sin depender de un paquete de búsqueda de terceros. El nuevo servicio de búsqueda une los servicios de datos, índices y consultas y puede ser gestionado como otros servicios para propósitos de escalado multidimensional (MDS). Ten en cuenta que, a diferencia de N1QL, el servicio de búsqueda realiza tanto la consulta de texto completo como la indexación en un único servicio.
Servicio de búsqueda distribuida: bajo el capó
En la mayoría de los casos, los índices de búsqueda distribuida "simplemente funcionan": el servicio de Búsqueda de Texto Completo de Couchbase aprovecha el nuevo hardware a medida que añades nodos, y los índices de texto completo se sobreescriben y reequilibran junto con el servicio de datos. Esta sección habla de los mecanismos que permiten esto, que normalmente no necesitas conocer como usuario pero que a veces encontrarás, como en los resultados parciales de búsqueda (que se tratan más adelante).
Desde el principio, la búsqueda de texto completo se diseñó para distribuir índices de texto entre nodos, de forma muy similar a como el servicio de datos distribuye los datos en buckets. Si entiendes el buckets y vBucketsYa tienes un buen modelo mental para entender esto. El bucket es una unidad lógica de contención de datos con la que es fácil trabajar, y el vBucket es una porción física de los datos que están en un bucket, que vive en un nodo específico de un cluster. Cuando activas la replicación en un bucket, Couchbase Server crea copias de todos los vBuckets necesarios que componen ese bucket. Couchbase Server también se asegura de que la distribución de esos vBuckets es óptima, lo cual es en sí mismo un tema complejo, pero por ahora, puedes pensar en ello como el equilibrio de las ubicaciones de los vBuckets para que se distribuyan uniformemente entre los nodos.
FTS funciona de forma similar. Los índices de texto completo se dividen automáticamente en fragmentos denominados pindexesque es la abreviatura de "índices particionados" o "índices físicos", según a quién preguntes. Al igual que un bucket, un índice de texto completo es un concepto lógico. El pindex es la implementación física del índice, al igual que el vBucket es la implementación física del bucket.
Los pindexes se distribuyen físicamente entre los nodos de Couchbase que ejecutan el servicio de búsqueda, por muchos que sean. En la versión preliminar para desarrolladores, era un único nodo, pero esa restricción se ha eliminado en la versión Beta. En los ejemplos de abajo, usaremos sólo dos nodos para mantenerlo simple.
Añadir un nodo de búsqueda
Es hora de ponerse manos a la obra. Si tienes Couchbase Server 4.5 Beta o más reciente, estás listo para empezar. Vas a necesitar configurar más de un nodo, así que prepara una máquina virtual. Para este ejemplo, voy a usar un par de máquinas virtuales Windows Server 2012.
Empecemos con un único nodo que ejecute el servicio de búsqueda. Crearemos un índice simple en los documentos de hoteles del cubo de la muestra de viajes. Si no tienes la muestra de viajes instalada, puedes obtenerla haciendo clic en Ajustes > Cubos de muestra y marque la casilla.
Para los propósitos de esta demostración, cualquier índice de texto completo servirá. He creado un índice en type="hotel" (no olvides desactivar la asignación de tipos por defecto) con dos campos, "name" y "description", store = true, y "index only specified fields" sólo para que se construya rápido.
Aquí está el comando curl, por si tienes alergia a la interfaz de usuario:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 |
rizo -XPUT -H "Content-Type: application/json" http://localhost:8094/api/index/hotel -d '{ "tipo": "fulltext-index", "nombre": "hotel", "sourceType": "couchbase", "sourceName": "muestra-viaje", "planParams": { "maxPartitionsPerPIndex": 32, "numReplicas": 0, "hierarchyRules": null, "nodePlanParams": null, "pindexWeights": null, "planFrozen": false }, "params": { "mapping": { "byte_array_converter": "json", "default_analyzer": "standard", "default_datetime_parser": "dateTimeOptional", "default_field": "_all", "default_mapping": { "display_order": "1", "dinámico": true, "habilitado": false }, "default_type": "_default", "index_dynamic": true, "store_dynamic": falso, "type_field": "type", "tipos": { "hotel": { "display_order": "0", "dinámico": falso, "habilitado": true, "propiedades": { "descripción": { "dinámico": falso, "habilitado": true, "fields": [ { "analizador": "", "display_order": "0", "include_in_all": true, "include_term_vectors": true, "índice": true, "nombre": "descripción", "store": true, "tipo": "texto" } ] }, "name": { "dinámico": falso, "habilitado": true, "fields": [ { "analizador": "", "display_order": "1", "include_in_all": true, "include_term_vectors": true, "índice": true, "nombre": "nombre", "store": true, "tipo": "texto" } ] } } } } }, "store": { "kvStoreName": "forestdb" } }, "sourceParams": { "clusterManagerBackoffFactor": 0, "clusterManagerSleepInitMS": 0, "clusterManagerSleepMaxMS": 2000, "dataManagerBackoffFactor": 0, "dataManagerSleepInitMS": 0, "dataManagerSleepMaxMS": 2000, "feedBufferAckThreshold": 0, "feedBufferSizeBytes": 0 } }' |
Cuando hayas terminado, puedes buscar una palabra común como "Posada" para asegurarte de que todo funciona.
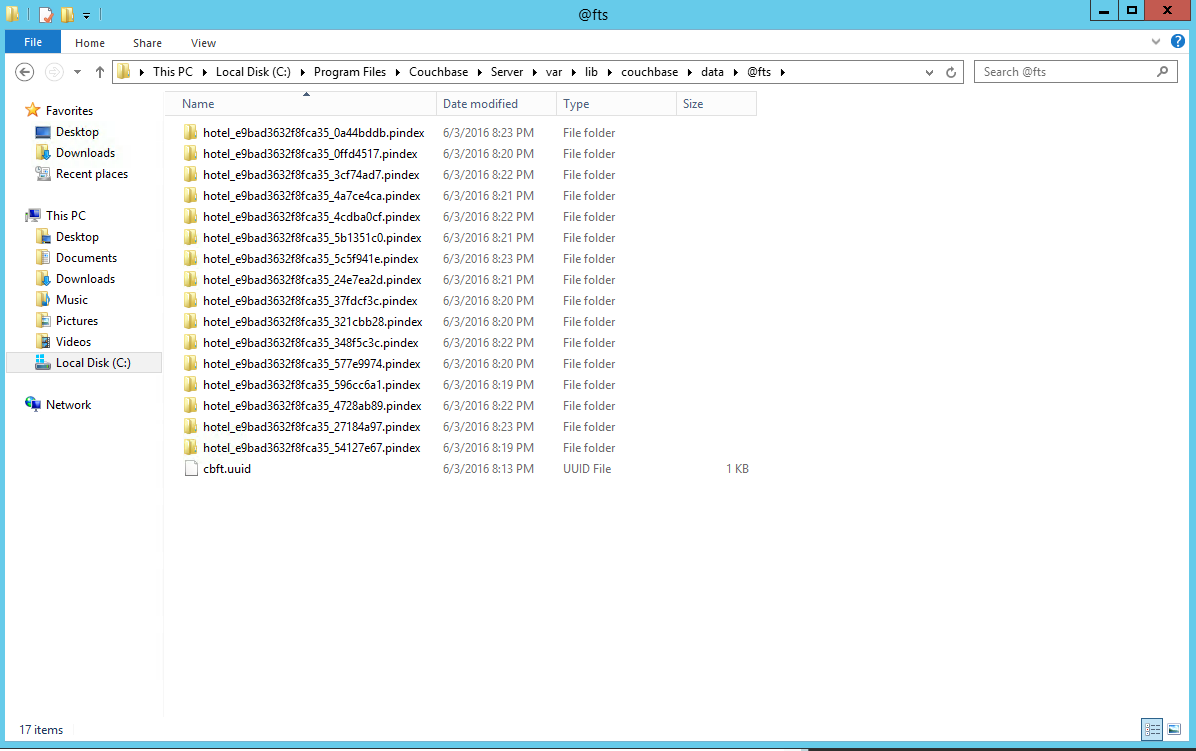
Cuando eches un vistazo a tu directorio de datos de Couchbase, verás un @fts directorio. Ábrelo y verás un montón de directorios que contienen los pindex.
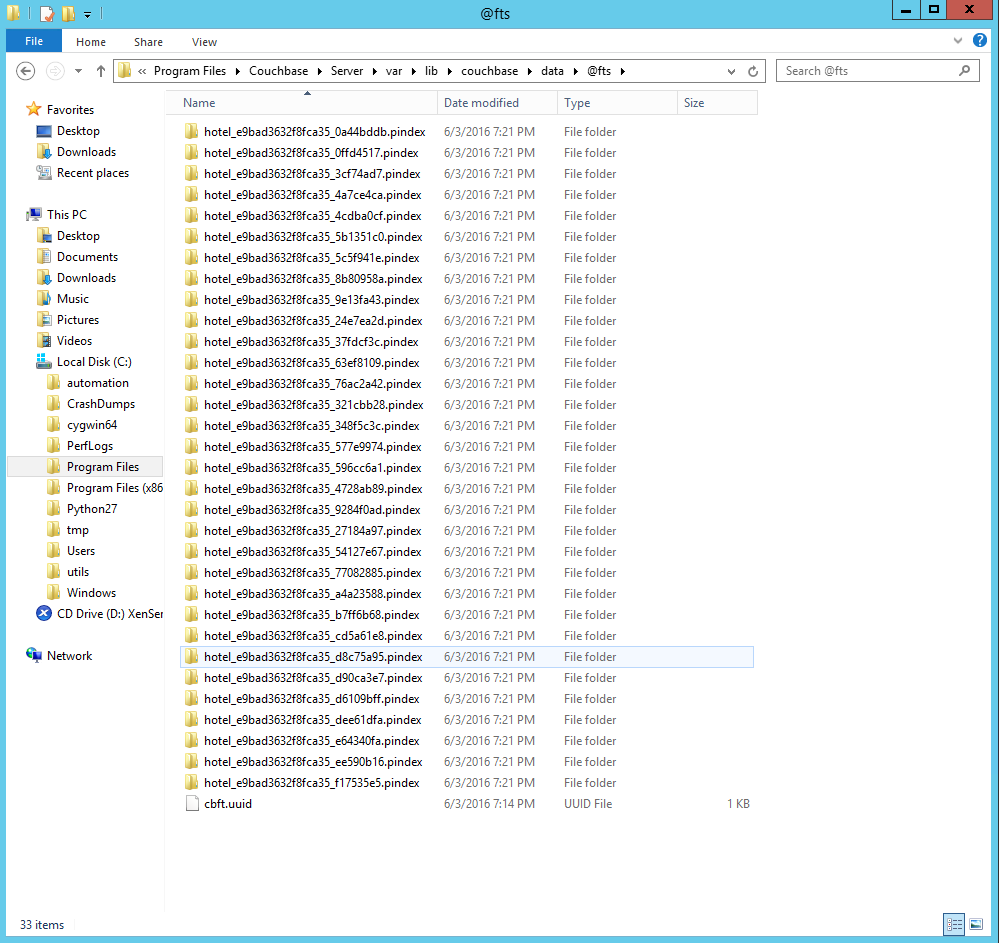
Segundo nodo de búsqueda y reequilibrio
Siga adelante y añada un segundo nodo al clúster, como haría normalmente. No olvide marcar la casilla para activar el servicio de búsqueda.
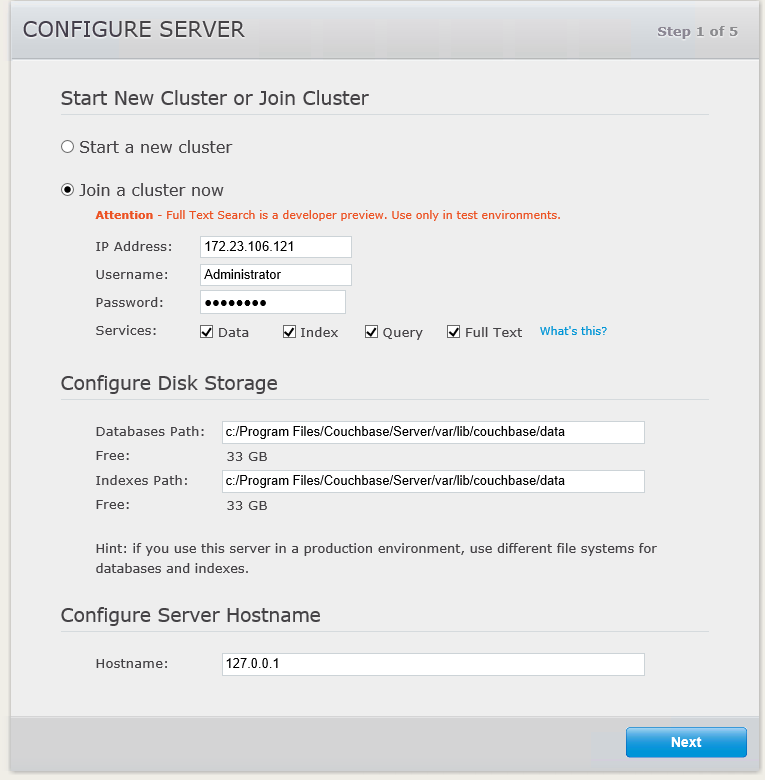
Verás una pantalla parecida a esta cuando termines, mostrando un servidor pendiente de reequilibrio.
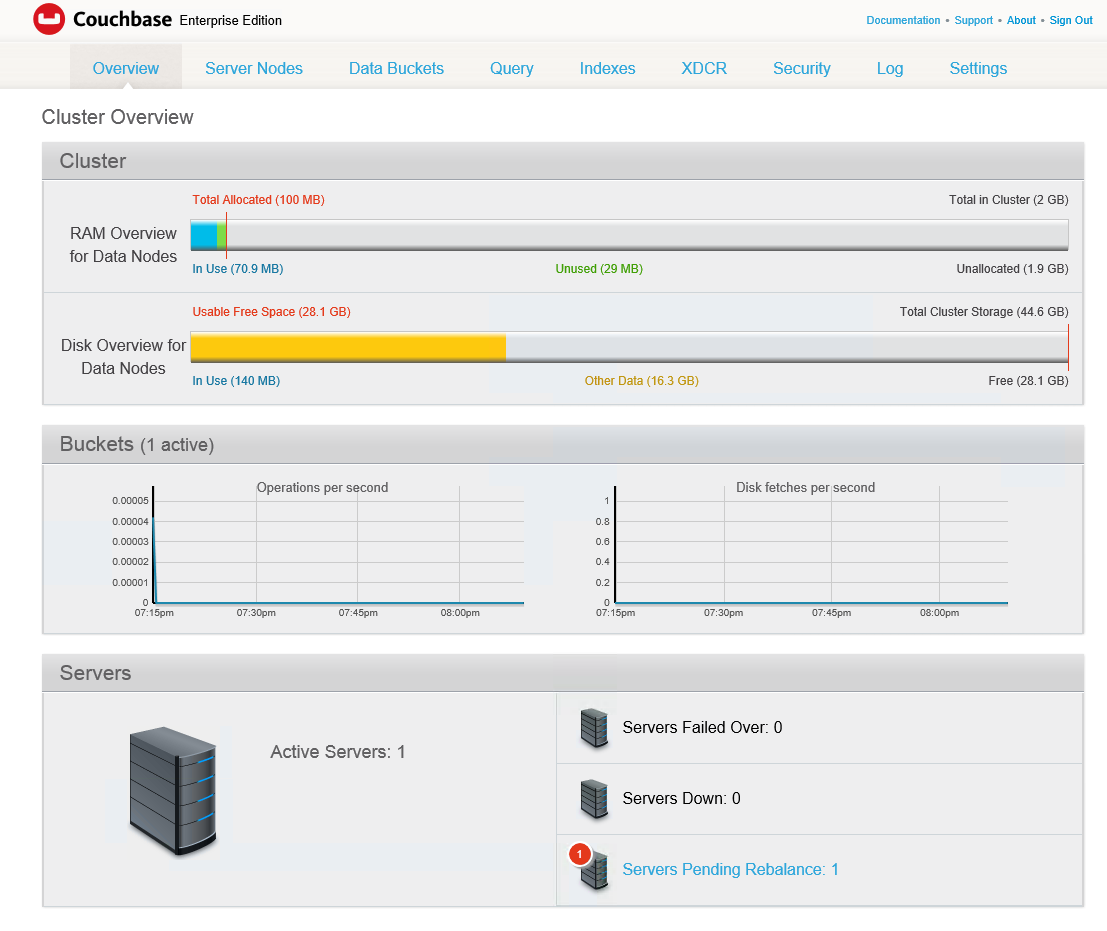
En este caso, veo una advertencia de fallo porque los datos de la muestra de viaje no tienen réplicas. Entro y pulso el botón de reequilibrio. Los documentos comienzan a copiarse en el nuevo nodo, se crean réplicas y las vistas de la muestra de viaje se muestran como "en construcción" porque son una forma de índice local, por lo que el reequilibrio de datos significa que las vistas también tienen que reconstruirse a medida que se mueven los datos activos. (Si quieres ahorrarte algo de tiempo para los propósitos de esta demostración, puedes borrar las vistas). Sus pindexes también se reequilibran sobre los nodos disponibles.
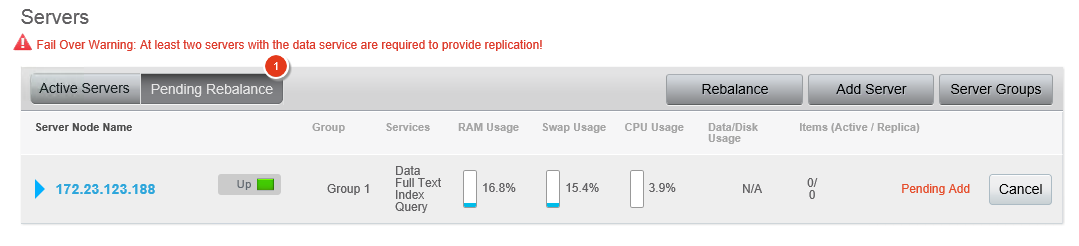
Una vez finalizado el proceso, ahora tendrás la mitad de los pindex en cada servidor.
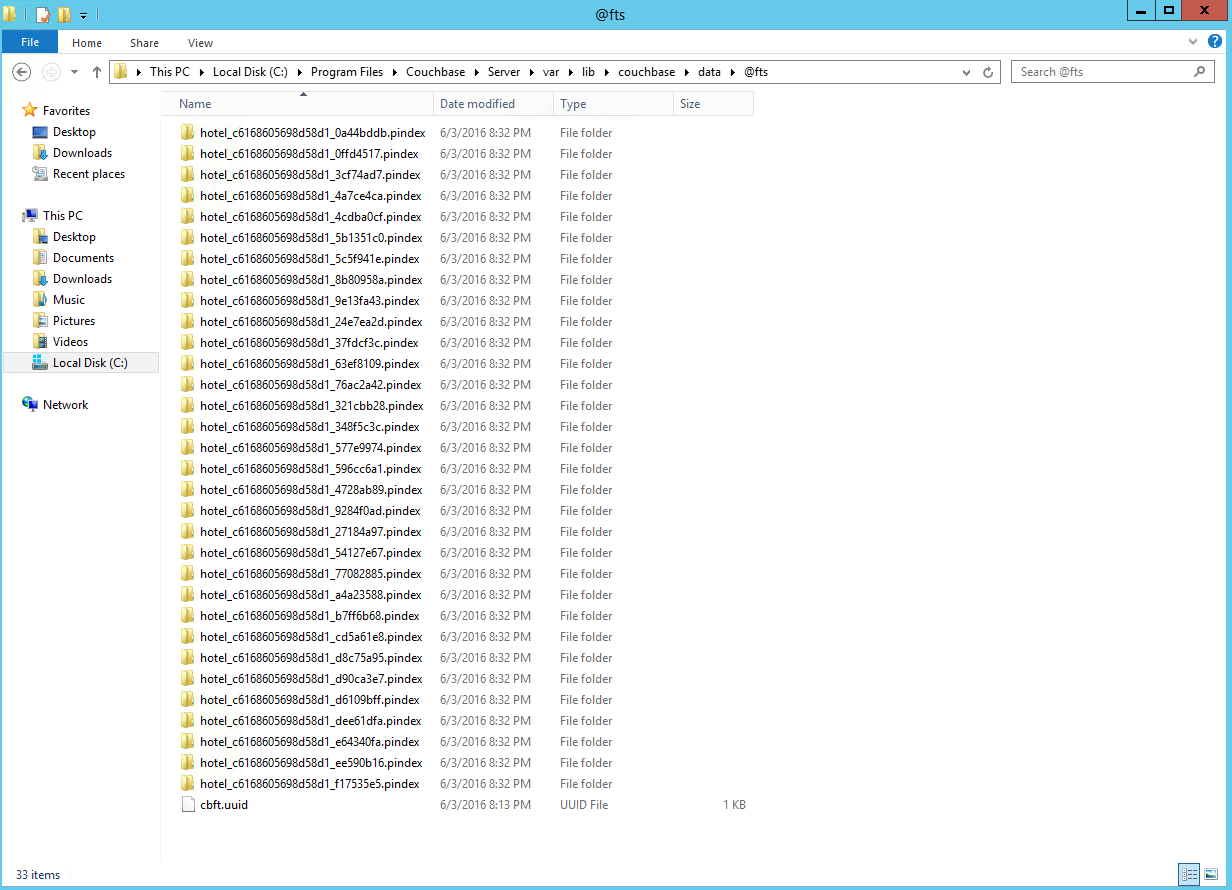
Para verificarlo, compruebe su da Couchbaseta de nuevo. Verás la mitad de directorios:
Réplicas de índices
Los índices de texto completo pueden ser replicados, al igual que puedes tener documentos activos y réplicas en Couchbase. Al igual que las réplicas de documentos, las réplicas de índices de texto se colocan automáticamente en el cluster en una distribución equilibrada dependiendo del hardware disponible. La replicación de índices de texto completo es principalmente para acelerar el failover. A diferencia de los documentos, los índices de texto completo no están en riesgo de pérdida de datos porque siempre pueden ser recreados reindexando usando la definición del índice.
Cuando crea o actualiza un índice de texto completo, tiene la opción de especificar una o dos réplicas. Para ello, vaya a la definición del índice, haga clic en Editary, a continuación, compruebe Mostrar configuración avanzada.
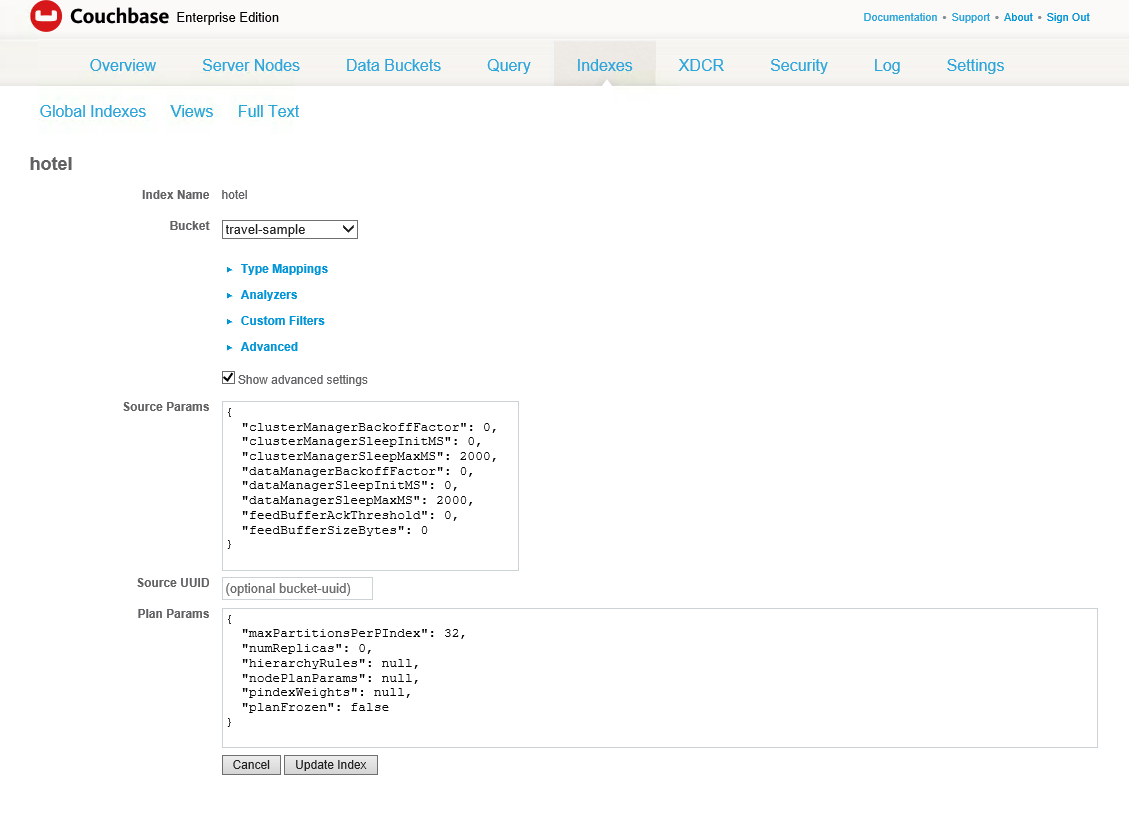
En Parámetros del plan, cambio numReplicas a 1 y, a continuación Índice de actualización.
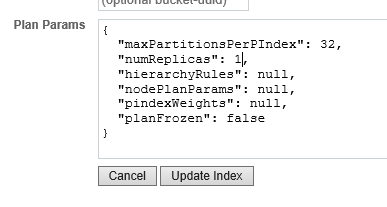
Tan pronto como guardes tu definición, Couchbase Server empezará a crear los índices de texto activo y réplica. Esto te dará otra copia del índice. De nuevo, puedes verificarlo mirando uno de los directorios data@fts y contando los pindexes. Cada nodo debería tener ahora 1/2 de los pindexes activos y 1/2 de los pindexes de réplica.
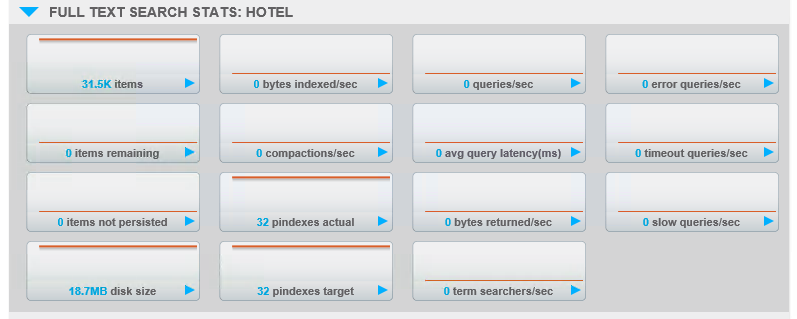
También puede verlo haciendo clic en el icono Nodos servidores haciendo clic en uno de los servidores y ampliando "Estadísticas de búsqueda de texto completo"para el índice creado. Verá las estadísticas de pindexes actual (cuántos existen) y pindexes target (cuántas deberían existir, dado el número de réplicas que ha solicitado).

Failing Over
Ahora conmute por error un nodo. Si busca ahora, obtendrá resultados parciales - es decir, obtendrá resultados de búsqueda de los píndex restantes. Esto es por diseño, ya que algunas aplicaciones pueden optar por continuar con resultados parciales en lugar de lanzar un error. Al fin y al cabo, con un conjunto de datos lo suficientemente grande, es posible que los usuarios ni siquiera se den cuenta de que faltan documentos.
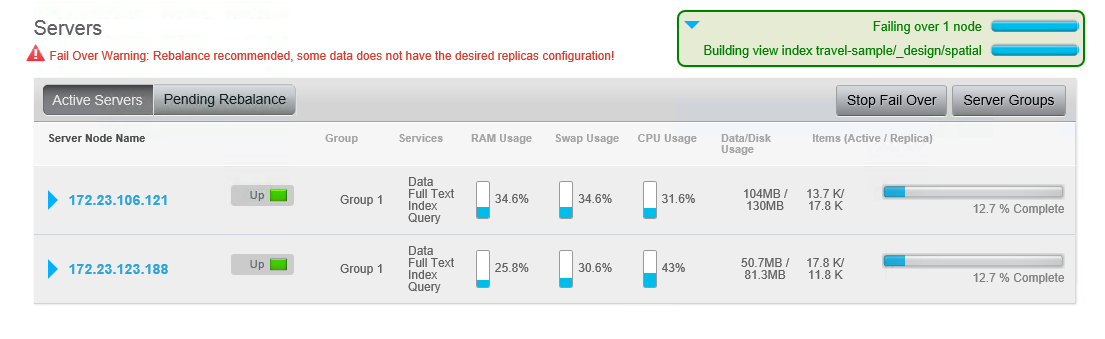
Ahora, reequilibre el nodo. El reequilibrio con réplicas es bastante rápido (si no ha eliminado antes las vistas de muestra de viaje, la conmutación por error tarda bastante más).
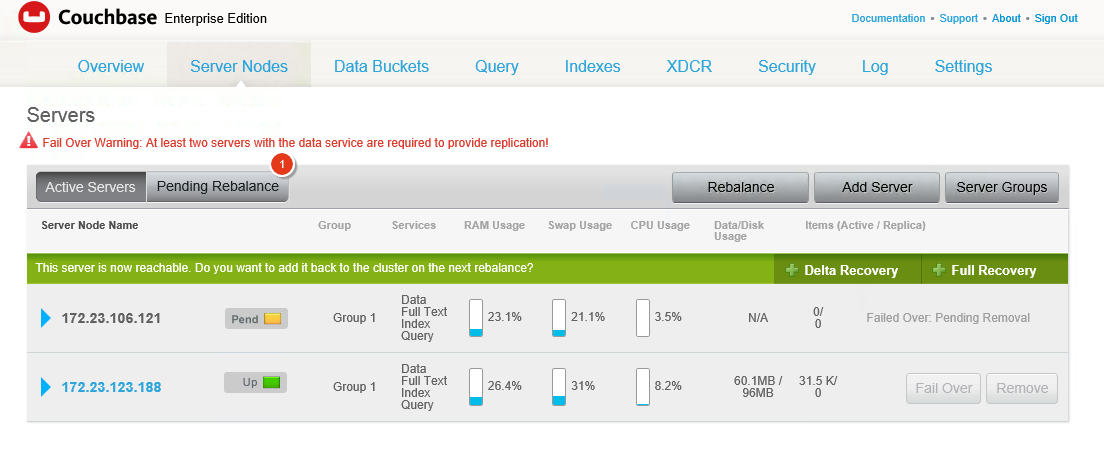
Cuando se pulsa reequilibrar, el otro nodo toma el relevo muy rápidamente activando réplicas - tanto réplicas de documentos como réplicas de pindex. Esta promoción es instantánea. Si la indexación está en curso, ya sea porque el índice no está completamente actualizado o porque se están produciendo mutaciones de documentos, los índices de texto completo pueden tardar más tiempo en crearse. A medida que los vBuckets se mueven, los nodos que ejecutan el servicio FTS reconectarán sus flujos DCP al lugar donde terminaron los vBuckets en el reequilibrio.
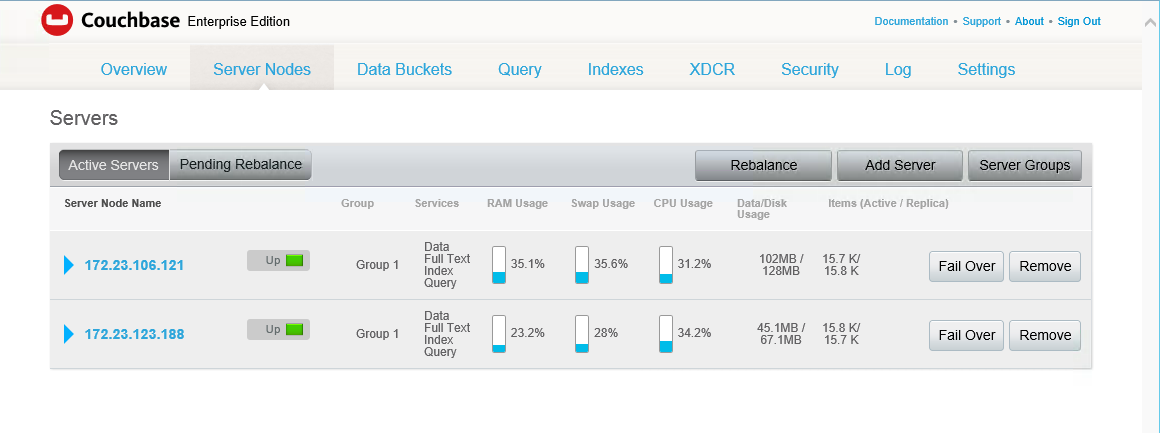
Deberías ver algo como esto cuando se complete el reequilibrio. Ahora no tenemos réplicas y hemos vuelto al número de pindexes que teníamos al principio:
Failing Over sin réplicas
Quizá te preguntes qué pasaría si hicieras el experimento anterior sin haber creado antes ninguna réplica de índice de texto completo. Eso también funciona, y merece la pena hacerlo al menos una vez para ver qué pasa. No tendrás primarios para algunos de tus pindexes - exactamente la mitad en este caso. No pasa nada: como he mencionado antes, no hay pérdida de datos, porque los píndices que faltan se pueden volver a crear reindexando los documentos con las definiciones de índice originales. Obtendrá resultados parciales y, además, durante más tiempo. Esto se debe a que, cuando se realiza un reequilibrio, los píndices que faltan tienen que empezar desde cero y no se recuperarán como lo harían si hubiera réplicas de píndices disponibles.
Pruébalo
Los índices de texto completo distribuidos son una de mis funciones favoritas de esta versión. No cabe duda de que se tarda más en explicarlas que en utilizarlas. Te invitamos a que los pruebes y nos digas qué te parecen. ¡Feliz búsqueda!