¡Lanzamiento de Couchbase 4.5! Parte 2 es una continuación de este blog e incluye la cobertura de índices de matrices, soporte para más operadores como UNNEST, ALL, ANY AND EVERY etc..,
¿Tiene documentos con matrices incrustadas y necesita un medio eficaz para acceder a los datos almacenados en esas matrices? Las matrices son una de las potentes características del modelado de datos NoSQL/JSON. Las matrices pueden almacenar datos multivaluados dentro de un atributo de un documento, como varios números de teléfono, información sobre los hijos, horarios de vuelos, reseñas de productos, comentarios y respuestas de blogs, etc. No sólo mantiene todos los datos relevantes juntos en el mismo documento, sino que también mejora el rendimiento de las consultas al evitar JOINs innecesarios. Los arrays en documentos no son nuevos para Couchbase o N1QL (SQL para JSON), ya tiene una amplia selección de construcciones y operadores para almacenar, indexar y procesar arrays.
Couchbase 4.5 Developer Preview añade compatibilidad con Indexación de matrices con la capacidad de indexar y consultar elementos individuales del array o cualquier objeto/atributo anidado dentro del array. La indexación de matrices mejora enormemente el rendimiento de las consultas que implican matrices, especialmente el acceso a valores y atributos dentro de la matriz. Además, simplifica el tratamiento de los atributos de las matrices en la aplicación Consultas N1QL. Esto supone un gran salto con respecto a las versiones anteriores, en las que los índices secundarios podían crearse y consultarse posteriormente, pero sólo sobre el contenido de toda la matriz.
Veamos cómo funciona la magia. Considere la muestra-viaje cubo enviado con el producto, y el horario en los documentos con tipo = “ruta“

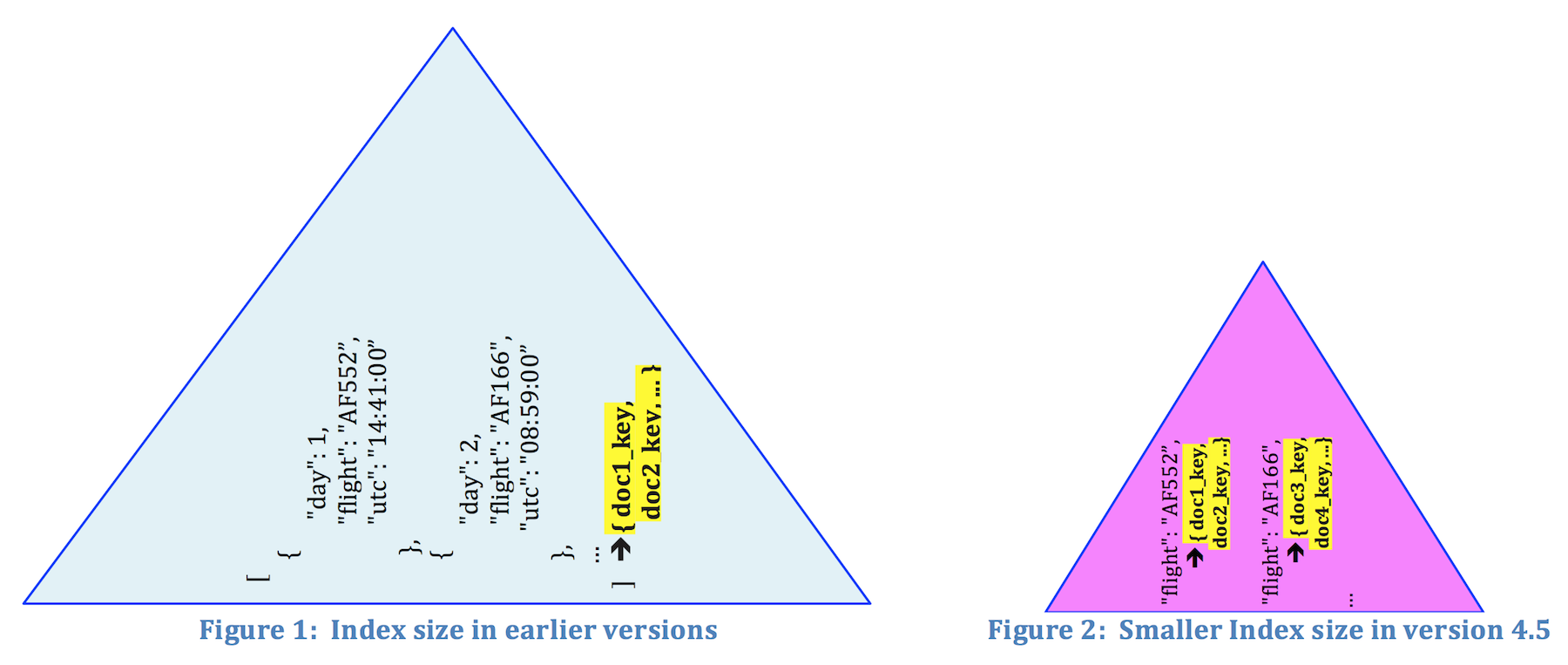
En versiones anteriores, cuando se creaba un índice en horario todo el array se indexa con todo su contenido/elementos como un único valor escalar. Esto significa que todo lo que se ve en el cuadro azul del ejemplo anterior se considera como un único valor de índice. Así, más tarde, cuando se consulta en horarioes necesario proporcionar el valor completo de la matriz en el campo Cláusula WHERE para utilizar el índice. Esto puede ser manejable para arrays simples/pequeños, pero en general tiene los siguientes problemas:
-
Indexación de datos de grano fino dentro de la matriz: ¿Qué pasa si desea indexar sólo subconjunto de la matriz, por ejemplo vuelo dentro del atributo horario o sólo para determinados días?
-
Tamaño del índice y rendimiento: Cuando se indexa toda la matriz, se consume más espacio de almacenamiento del índice y se tarda más en buscarlo. La figura 1 muestra el índice creado para el atributo horario con la versión anterior a 4.5.
-
Búsqueda en matrices: Al indexar todo el array no podemos buscar de forma eficiente datos específicos dentro del array. La aplicación tendría que buscar/SELECCIONAR primero todo el valor del array y luego procesarlo, para encontrar los datos de interés.
-
Matrices de gran tamaño: No es conveniente (y a veces es imposible) proporcionar el valor completo del array en una cláusula WHERE cuando el array tiene muchos elementos.
La indexación de arrays en Couchbase 4.5 aborda todos estos problemas y tiene mejoras en N1QL y el indexador para aprovechar los arrays indexados. Esto incluye soporte para índices parciales, arrays anidados, índices compuestos y operadores como ANY, IN, WITHIN, DISTINCT ARRAY. Veamos algunos ejemplos:
-
En primer lugar, cree un índice de matriz en horario utilizando el atributo ARREGLO DISTINTO que especifica los elementos exactos de la matriz o los atributos anidados que se utilizarán como claves de índice. La siguiente sentencia indexa "todos los vuelos programados en días laborables (es decir día <= 5)”. Obsérvese que sólo podemos crear índices sobre un subconjunto de los elementos de la matriz que nos interesan. Por lo tanto, el nuevo índice de matriz es compacto y eficiente (véase la Figura 2), y sólo almacena la información necesaria en el índice.
|
1 2 3 4 |
CREATE INDEX isched ON `travel-sample`(DISTINCT ARRAY v.flight FOR v IN schedule WHEN v.day <= 5 END) WHERE type = "route"; |
-
Ahora, el índice se puede utilizar en una sentencia SELECT o cualquier otra sentencia DML, especificando las claves del índice y los predicados del índice en la cláusula WHERE. En la versión actual, es necesario especificar los nombres exactos de las variables, teclas de índice (como v, v.día, v.vuelo), y predicados como (tipo = "ruta") y (v.día = 4) que coincidan con los especificados en la definición de CREATE INDEX. Este criterio de selección de índices es necesario para que N1QL elija automáticamente el índice correspondiente para procesar una consulta. Como de costumbre, cuando se crean múltiples índices coincidentes, La cláusula USE INDEX se puede utilizar para sugerir a N1QL que utilice un índice específico.
Por ejemplo, la siguiente consulta encuentra el " número de vuelos de UA programados el 4th día" utilizando el índice del array. La consulta utiliza el isched porque cumple los requisitos de selección de índices:
-
La variable v que es la variable exacta utilizada en la definición del índice.
-
La clave del índice v.vuelo en la cláusula WHERE.
-
Ambos predicados de índice (tipo = "ruta") y (v.día = 4) en la cláusula WHERE. Tenga en cuenta que (v.día = 4)se considera coincidente, ya que está "incluido" por (v.día <= 5)que se especifica en la definición de CREATE INDEX.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
EXPLAIN SELECT count(*) FROM `travel-sample` USE INDEX(isched) WHERE type = "route" AND ANY v IN schedule SATISFIES v.flight LIKE "UA%" AND v.day = 4 END; { "requestID": "90da999e-114d-4f13-ad6f-d4ab30512b1c", "signature": "json", "results" : [ { "#operator": "Sequence", "~children": [ { "#operator": "DistinctScan", "scans": [ { "#operator": "IndexScan", "index": "isched", "keyspace": "travel-sample", "namespace": "default", ... |
- Rendimiento: Los índices de matrices aumentan considerablemente el rendimiento de las consultas que pueden aprovechar el índice. Por ejemplo, la consulta anterior de (2), que utiliza el índice de matriz isched tardó aproximadamente 256 ms en mi portátil. Sin embargo, la siguiente consulta utilizando el índice def_type tardó casi 2,38 segundos. Esto supone un rendimiento 9 veces superior con índices de matriz.
|
1 2 3 4 5 |
SELECT count(*) FROM `travel-sample` USE INDEX(def_type) WHERE type = "route" AND ANY v IN schedule SATISFIES v.flight LIKE "UA%" AND v.day = 4 END; |
Puede obtener más información sobre la indexación de matrices y ver más ejemplos, como los índices de matrices compuestas y anidadas, en el documento Couchbase 4.5 documentacióny compruebe el demo.
Pruébelo y hágame llegar sus preguntas o comentarios, o simplemente dígame lo fantástico que es ;-)
¡Salud!