¿Cómo se pueden analizar todos los datos? Es decir, ¿cómo se pueden analizar todos los datos a partir de este momento?
Hadoop es el estándar de facto para almacenar y analizar muchos datos, muchísimos, pero ¿cómo se almacenan? ¿Cómo se analizan? Primero, se importan, como un lote. A continuación, se procesa, como un lote. ¿La palabra clave? Lote. Mientras se importa o procesa un lote de datos, se siguen generando datos. Si los datos se importan una vez al día, los datos en Hadoop están incompletos. Falta un día de datos. Si el procesamiento requiere una hora, los resultados están incompletos. Falta una hora de datos en la entrada.
¿Y si el análisis debe incluir datos generados en el último minuto?
Arquitectura Lambda, definida por Nathan Marz, creador de Storm, un procesador de flujos.
¿Y si se procesa un flujo continuo de datos? Cuando se generan datos, se procesan, antes de almacenarlos. Ahora, el análisis puede incluir datos generados en el último segundo, el último minuto o la última hora procesando los datos entrantes, no todos los datos.
Si puede combinar los datos procesados en Hadoop con los datos procesados de un procesador de flujos, podrá analizar todos los datos generados a partir de este momento.
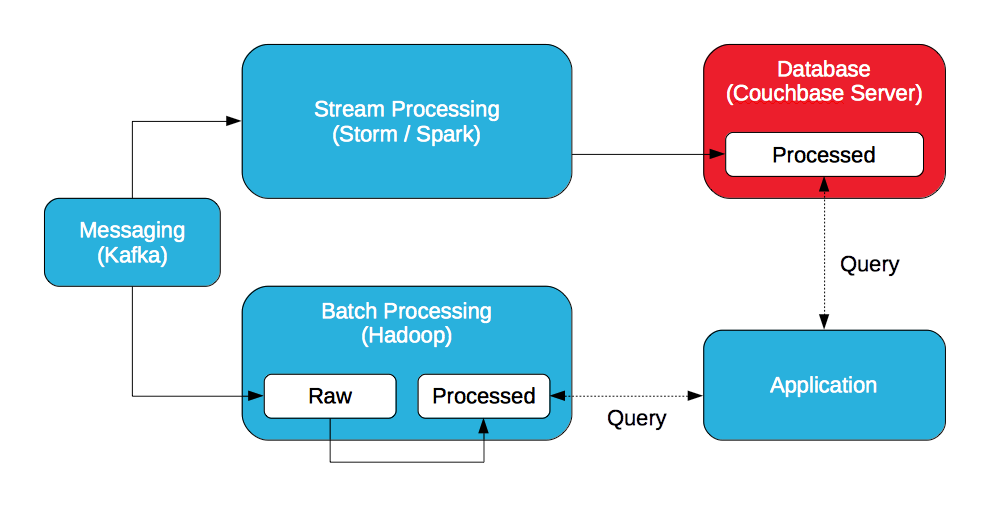
Mensajería
Un sistema de mensajería distribuida (Kafka, JMS o AMQP) es ideal para la ingesta de datos con alto rendimiento y baja latencia.
Procesamiento de flujos (capa de velocidad)
Un sistema de procesamiento de flujo distribuido (Storm, Spark Streaming) es ideal para analizar los datos entrantes en tiempo real. Mientras que Storm procesa datos individuales, Spark Streaming procesa minilotes de datos.
Hadoop (capa de lotes)
Hadoop almacena lotes de datos en bruto y los procesa con MapReduce / Pig o Spark.
Base de datos
Una base de datos distribuida es ideal para almacenar los datos procesados generados por el procesador de flujos. Un procesador de flujo no almacena ni los datos brutos ni los datos procesados. No almacena datos. La base de datos debe ser capaz de satisfacer los requisitos de alto rendimiento y baja latencia del procesador de flujo para que no se convierta en el cuello de botella.
Aplicación (capa de servicio)
Una aplicación consulta los datos procesados tanto en Hadoop como en la base de datos para crear una vista completa de los resultados. La aplicación puede consultar Couchbase Server con SQL (a través de N1QL) y / o vistasy Hadoop con Hive o Impala / Drill.
Si la idea es consultar los datos procesados, batch y streaming, ¿por qué no almacenar todos los datos procesados en la base de datos para que sea la capa de servicio?
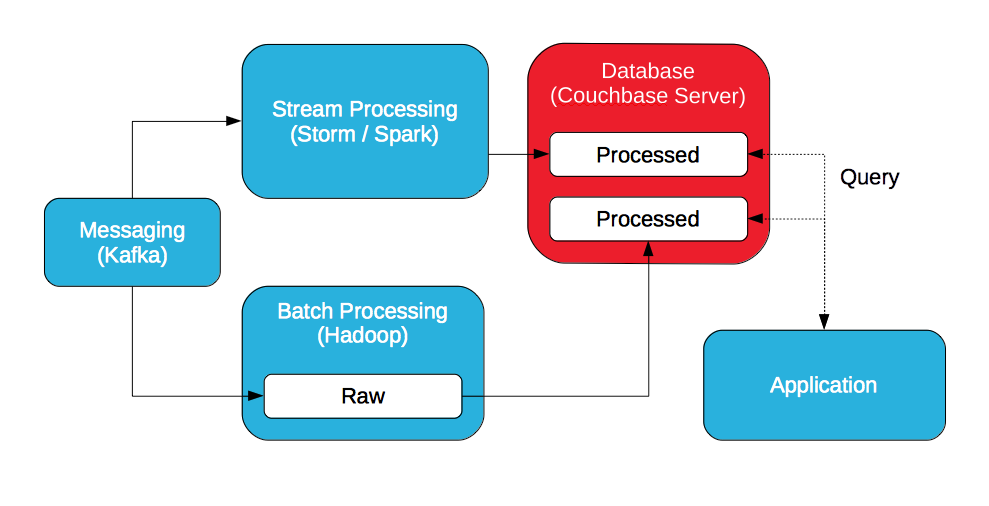
Hay dos opciones: almacenar los datos procesados en Hadoop y exportarlos a la base de datos o almacenar los datos procesados en la base de datos. Los datos se pueden exportar de Hadoop a Couchbase Server con un plugin para Sqoop.
Con Couchbase Server, se puede acceder a los datos procesados con una API de clave/valor o consultarlos con SQL (mediante N1QL). Además, los datos procesados pueden seguir tratándose y consultarse con vistas. Las vistas se implementan con map/reduce para ordenar, filtrar y agregar datos, pero aprovechan las actualizaciones incrementales.
Notas
Se necesita Hadoop. Aunque es posible implantar Spark sin Hadoop, las distribuciones de Cloudera, Hortonworks y MapR lo incluyen. Hadoop almacena muchos datos en bruto, Spark los procesa y la localización de los datos es importante. Además, Hadoop es más que Spark. Incluye MapReduce y Pig. Incluye Hive. Cloudera Enterprise incluye Impala, Hortonworks Data Platform incluye Tez y MapR incluye Drill.
A pesar de lo que un proveedor NoSQL pueda insinuar, te estoy mirando a ti DataStax, tanto Hadoop como NoSQL son necesarios. Una base de datos NoSQL no puede sustituir a Hadoop integrándose con Spark.
Shane - Es un tema interesante que estás viendo desde un punto de vista de CouchBase (ingestión de datos). El otro lado de esto es la capa App; la presentación y el uso comercial de los datos que se transmiten. He trabajado con muchos clientes que han dicho que quieren cuadros de mando y análisis de latencia cero, pero luego se sienten frustrados porque la granularidad de la información que se muestra es demasiado baja. El ejemplo que he utilizado con mis clientes es el "ticker bursátil". Te dice operación por operación lo que están haciendo las acciones de una empresa, pero no te dice nada sobre el rendimiento general del mercado, o el rendimiento a largo plazo de la empresa.
Estoy comentando, no criticando el artículo del Blog.
En mi experiencia, como arquitectos de la información, debemos ser muy juiciosos, tenemos que comunicar los pros y los contras del flujo de datos en las aplicaciones. En mi opinión, las empresas necesitan una línea de base histórica como componente de una infraestructura de datos. Datos históricos, posiblemente agregados y en flujo para un buen análisis predictivo.
Gracias, señor.
Es una idea pertinente. Sin embargo, la granularidad es configurable. Por ejemplo, un procesador de flujo podría evaluar todas las operaciones para identificar el rendimiento del mercado, no de una acción, en tiempo real. Las aplicaciones que aprovechan las vistas de Couchbase Server pueden además ordenar, filtrar y agregar datos para un acceso casi en tiempo real a través de cuadros de mando. Tal vez para agregar por industria o sector. Aunque, como has dicho, vale la pena combinar datos históricos con datos en tiempo real para obtener una imagen completa.