Hace seis mil años, los sumerios inventaron la escritura para procesar transacciones - Gray & Reuter
Se mire por donde se mire, MongoDB es una popular base de datos JSON orientada a documentos. En la última docena de años, ha crecido desde sus humildes comienzos de un único bloqueo por base de datos a una moderna transacción multi-documento con aislamiento instantáneo. MongoDB University ha formado a un gran número de desarrolladores para que desarrollen en la base de datos MongoDB.
Actualmente existen muchas bases de datos JSON. Aunque es fácil empezar con MongoDB para aprender NoSQL y el esquema JSON flexible, muchos clientes eligen Couchbase por rendimiento, escala y SQL. A medida que avances en la evaluación y evolución de tu base de datos, deberías aprender sobre otras bases de datos JSON. Estamos trabajando en un curso de formación online para que los expertos en MongoDB aprendan Couchbase fácilmente. Hasta que lo publiquemos, tendrás que leer este artículo :-)
Si conoces RDBMS como Microsoft SQL Server y Oracle, tenemos cursos fáciles de seguir para aprender a hacer el mapeo de tus conocimientos de bases de datos a Couchbase con estos dos cursos:
- CB116m - Introducción a Couchbase para expertos en MSSQL
- CB116o - Introducción a Couchbase para expertos de Oracle
RESUMEN
MongoDB y Couchbase tienen muchas cosas en común. Ambos son NoSQL bases de datos distribuidas; Ambos utilizan el modelo JSON; Ambos tienen lenguajes de consulta de alto nivel con soporte para operaciones select-join-project; Ambos tienen índices secundarios; Ambos tienen un optimizador que elige el plan de consulta automáticamente. Ambos soportan la replicación intra- e inter-cluster.
Como era de esperar, hay diferencias. Algunas son más significativas que otras. Couchbase está diseñado para ser distribuido desde el principio. Por ejemplo, el contenedor de datos Bucket está siempre distribuido - sin nada que fragmentar. Simplemente añade nuevos nodos y el sistema distribuirá automáticamente. La replicación dentro del clúster no requiere nuevos servidores: basta con establecer el número de réplicas y listo. Desde el punto de vista de la interacción del desarrollador, la gran diferencia es el lenguaje de consulta en sí: MongoDB tiene un lenguaje de consulta propio y Couchbase tiene N1QL - SQL para JSON. MongoDB también utiliza su índice basado en B-Tree para la búsqueda y recientemente ha publicado 1TP4Buscarbeta para el servicio Atlas utilizando Apache Lucene; Couchbase tiene una función integrada de Búsqueda de texto completo.
Con suerte, las diferencias en Couchbase son las que hacen tu vida más fácil. Vamos a profundizar.
TEMAS DE ALTO NIVEL
- Recursos
- Arquitectura
- Objetos de la base de datos
- Tipos de datos
- Modelo de datos
- SDK
- Lenguaje de consulta
- Índices
- Optimizador
- Transacciones
- Analítica
RECURSOS
MongoDB |
Couchbase |
|
|
Docs |
||
|
Foros |
||
|
Última versión (abril de 2020) |
4.2.6 |
6.5.1 |
|
Licencia |
https://www.mongodb.com/licensing/server-side-public-license/faq |
|
|
Lenguaje de consulta |
ARQUITECTURA
Versión portátil:
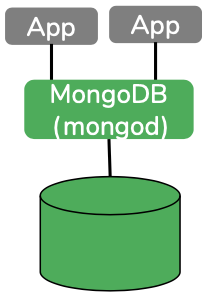
MongoDB: Simplemente instale y utilice el Mongodb en su ordenador portátil con los parámetros adecuados; usted está listo y funcionando. Un solo proceso para manejar toda la base de datos. Esto ha cambiado un poco en 4.2 donde necesitarías mongos para ejecutar tus transacciones. Todas las características de MongoDB (datos, indexación, consulta) están disponibles aquí - excepto la búsqueda de texto completo disponible sólo en el servicio Atlas.
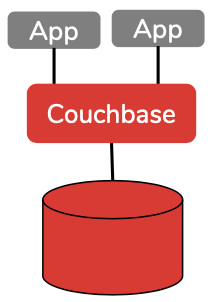 Couchbase: Couchbase es diferente. Se ha abstraído cada uno de los servicios (datos, índice, consulta, búsqueda, análisis, eventos) y usted tiene la opción de elegir cuál de las características que desea ejecutar en su instancia para optimizar los recursos. Una instalación típica tiene datos, índice y consulta. La búsqueda, los eventos y los análisis se ejecutarán en su portátil: instálelos y utilícelos según su caso de uso.
Couchbase: Couchbase es diferente. Se ha abstraído cada uno de los servicios (datos, índice, consulta, búsqueda, análisis, eventos) y usted tiene la opción de elegir cuál de las características que desea ejecutar en su instancia para optimizar los recursos. Una instalación típica tiene datos, índice y consulta. La búsqueda, los eventos y los análisis se ejecutarán en su portátil: instálelos y utilícelos según su caso de uso.
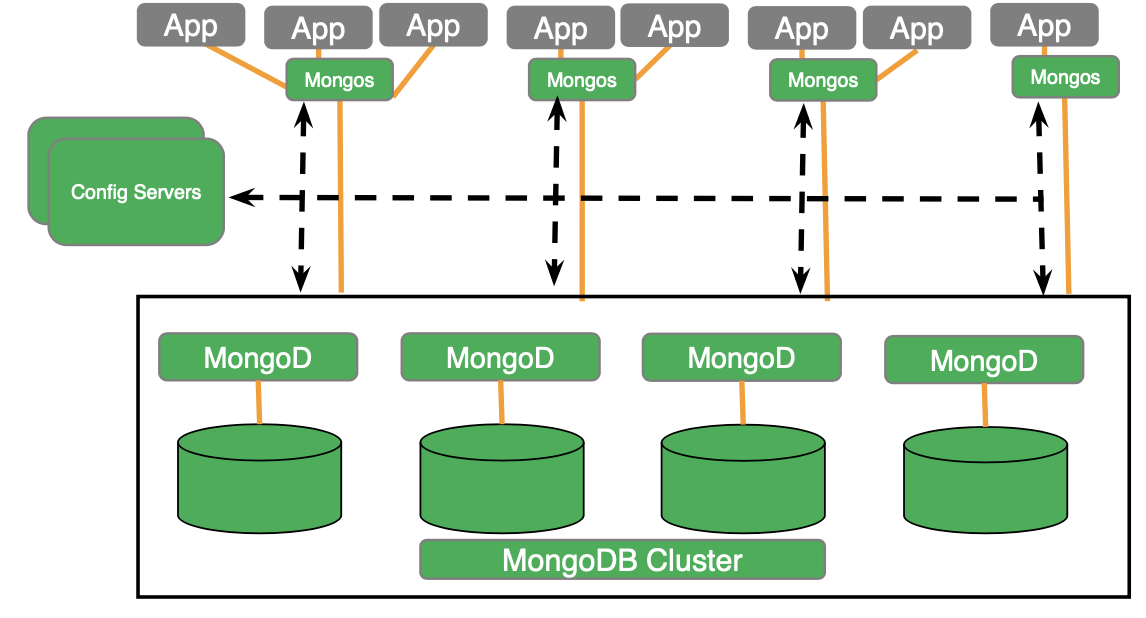
Despliegue en clúster: Como la mayoría de las bases de datos NoSQL, tanto MongoDB como Couchbase pueden escalarse. En MongoDB, puedes escalar mediante fragmentación la colección en varios nodos. Se puede dividir por hash o por rango. Sin una división explícita, cada colección permanece en una única división. Los servidores de configuración almacenan los metadatos y la configuración del cluster. MongoDB se distribuye uniformemente y Couchbase se distribuye multidimensionalmente. El proceso (servicio) de Mongodb gestiona los datos, el índice y la consulta en cada fragmento (nodo), mientras que Mongos realiza el procesamiento distribuido de la consulta y la fusión de los resultados intermedios y no gestiona ningún dato o índice. Mongos actúa como coordinador y mongodb es la abeja obrera.
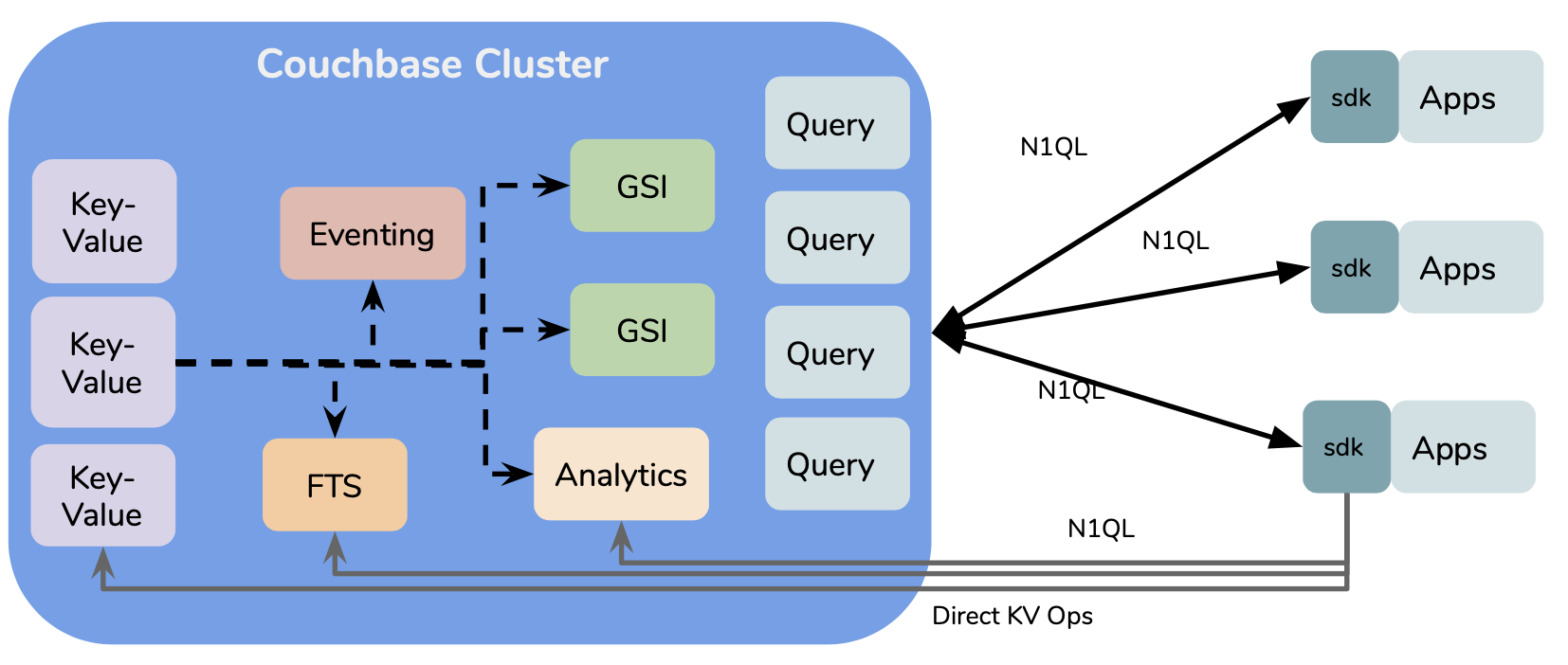
Couchbase puede desplegarse en una distribución uniforme en la que cada nodo gestiona los datos y todos los servicios: datos, índices, consultas, análisis y eventos. Cada servicio es una capa de la base de datos tradicional. Estos servicios están débilmente acoplados: se ejecutan en diferentes espacios de proceso y se comunican a través de una red. Por tanto, pueden desplegarse uniformemente en un único nodo o distribuirse multidimensionalmente en un clúster. La elección depende de la carga de trabajo y de los acuerdos de nivel de servicio. Los datos se almacenan en buckets. Todos los buckets están particionados por hash entre nodos determinados - esto es automático y no requiere ninguna especificación. Cuando la aplicación dispone de las claves de los documentos, puede operar directamente sobre los datos sin que intervenga ningún nodo. Esta es una de las principales diferencias arquitectónicas que contribuyen al alto rendimiento y escalabilidad de Couchbase. Además, no hay servidores de configuración. Los metadatos y su gestión están integrados en el núcleo de la base de datos. El servicio de datos gestiona los datos, el cluster y la replicación dentro de un cluster Couchbase. La replicación entre múltiples clusters de Couchbase es gestionada por XDCR. Lee este artículo para entender los mecanismos de replicación en MongoDB y Couchbase: Replicación en bases de datos de documentos NoSQL (Mongo DB vs Couchbase)

Dentro del despliegue del clúster.
Se explican los componentes del clúster de MongoDB y su despliegue aquí y lo asumo como conocimiento previo. Evitaré repetirlo.
El despliegue de Couchbase comienza con el servicio de datos clave-valor. Este es el almacén de datos (consistente) de valor-clave distribuido por hash. También tiene replicación intracluster incorporada, eliminando la necesidad de servidores de réplica o servidores de configuración separados. El servicio de consultas orquesta la ejecución de N1QL consultas. Utiliza GSI (indexación secundaria global), FTS (Búsqueda de texto completo) según sea necesario. FTS gestiona el índice de texto completo y puede consultarse directamente o a través del N1QL servicio de consulta. La función Eventing permite desencadenar automáticamente una acción (mediante la ejecución de una función Javascript) en caso de mutación de los datos. La base de datos Couchbase Motor de análisis es un motor de datos y consultas MPP. Hace una copia de los datos y los redistribuye en sus nodos, ejecuta la consulta en paralelo para obtener el mejor rendimiento posible. Todo ello se puede utilizar sin problemas mediante el rico conjunto de API disponibles en nuestro SDKs disponible en todas las lenguas populares.
OBJETOS DE BASE DE DATOS
MongoDB tiene una colección y una base de datos como los objetos lógicos con los que los usuarios tienen que trabajar. Couchbase tradicionalmente sólo tenía el Cubos. Bucket funcionaba tanto para la gestión de recursos (por ejemplo, la cantidad de memoria utilizada), la seguridad, así como el contenedor de datos. En 6.5, introdujimos la noción de recogida y alcance como vista previa para desarrolladores. Esta jerarquía bucket:scope:collection es análoga a database:schema:table de RDBMS. Esto hace que la base de datos sea más segura y mejor multi-tenant. En 6.5, sin la vista previa para desarrolladores, cada cubo utiliza un ámbito y una colección por defecto, lo que hace que la transición sea fluida.

|
RDBMS |
MongoDB |
Couchbase |
|
Base de datos |
Base de datos |
Cubo |
|
Cuadro |
Colección |
Cubo Futuro: Colección |
|
Fila |
Documento (BSON) |
Documento (JSON estándar) |
|
Columna |
Campo/Atributo |
Campo/Atributo |
|
Partición (Tabla/colección/cubo) |
No particionado por defecto. El particionamiento de hash y rango (sharding) es soportado manualmente. |
Partición (hash automático) |
Notas para los desarrolladores
En MongoDB, empiezas con tu instancia (despliegue) y creas bases de datos, colecciones e índices.
En Couchbase, empiezas con tu instancia y creas tus buckets e índices. Cada bucket puede tener múltiples tipos de documentos, por lo que cada documento debe tener un campo designado por la aplicación para reconocer su tipo. {"tipo": "parts"}. Dado que cada bucket puede tener cualquier número de tipos de documentos, debes evitar crear demasiados buckets. Esto también significa que, cuando cree un índice, le interesará crear un índice para cada tipo: cliente, piezas, pedidos, etc. Así, la creación del índice incluirá una cláusula WHERE para el tipo de documento.
CREATE INDEX ix_customer_zip ON customer(zip) WHERE type = "customer";
SELECT * FROM cliente WHERE código postal = 94040 AND tipo = "cliente"
Cada documento de MongoDB contiene un campo de id de documento _id proporcionado explícitamente o generado implícitamente.
En Couchbase, los usuarios deben generar e insertar una clave de documento inmutable para cada documento. Al insertar vía N1QL, puedes usar la función UUID() para generar una por ti. Pero, es una buena práctica tener una estructura regular de la clave del documento.
TIPOS DE DATOS
El modelo de datos de MongoDB es BSON y el modelo de datos de Couchbase es JSON. El tipo propietario BSON tiene algunos tipos, no en JSON. JSON tiene tipos de cadena, numérico, booleano (verdadero/falso), matriz, objeto. BSON tiene string, numérico, booleano, array, objeto, binario, UTC DateTime, timestamp, y muchas otras extensiones propietarias personalizadas, La diferencia más común es el DateTime y el timestamp. En Couchbase, todos los datos relacionados con el tiempo se almacenan como cadena en formato ISO 8601. Couchbase N1QL tiene una plétora de funciones para extraer, convertir, y calcular sobre el tiempo. Los detalles completos de las funciones son disponible en este artículo.
|
Tipo de datos |
MongoDB |
Couchbase |
JSON |
|
Números |
Número BSON |
Número JSON |
{ "id": 5, "saldo":2942.59 } |
|
Cadena |
BSON Cadena |
Cadena JSON |
{"nombre": "Joe", "ciudad": "Morrisville" } |
|
booleano |
Booleano BSON |
Booleano JSON |
{"prima": true, "pendiente": false} |
|
datetime |
Formato de datos personalizado |
Cadena JSON ISO 8901 con funciones de extracción, conversión y aritmética |
{ "soldate": “2017-10-12T13:47:41.068-07:00” } MongoDB: { "soldate": ISODate(“2012-12-19T06:01:17.171Z”)} |
|
datos espaciales |
GeoJSON |
Admite el vecino más próximo y la distancia espacial. |
"geometría": {"tipo": "Punto", "coordenadas": [-104.99404, 39.75621]} |
|
FALTA |
Sin soporte |
FALTA |
|
|
NULL |
JSON Nulo |
JSON null |
{ "última_dirección": null } |
|
Objetos |
Objetos JSON flexibles |
Objetos JSON flexibles |
{"dirección": {"calle": "1, Main street", "city": Morrisville, "zip": "94824″} |
|
Matrices |
Matrices JSON flexibles |
Matrices JSON flexibles |
{"hobbies": ["tenis", "esquí", "lego"]} |
TODO SOBRE DESAPARECIDOS
MISSING es el valor de un campo ausente en el documento JSON o literal.
{"nombre": "joe"} En el documento falta todo menos el campo "nombre". También puede establecer el valor de un campo en DESAPARECIDO para que el campo desaparezca. Las bases de datos relacionales tradicionales utilizan lógica de tres valores con verdadero, falso y NULL. Con la adición de MISSING, N1QL utiliza la lógica de 4 valores.
Tienes las siguientes expresiones con FALTA.
|
FALTA |
Devuelve true si el documento no tiene un campo de estado FROM CLIENTE WHERE estado es FALTA; |
|
NO FALTA |
Devuelve true si el documento tiene un campo de estado FROM CLIENTE WHERE estado es NO FALTA; |
|
DESAPARECIDO Y NULO |
MISSING es una cantidad desconocida null es un UNKNOWN conocido. Puede comprobar un valor nulo de forma similar a MISSING con la expresión IS NULL o IS NOT NULL. JSON válido: {"status": null} |
|
valor FALTANTE |
Simplemente haga desaparecer el campo de cualquier tipo configurándolo como DESAPARECIDO UPDATE CUSTOMER SET status = MISSING WHERE cxid = "xyz232" |
MODELIZACIÓN DE DATOS
| Relación | MongoDB | Couchbase |
| 1:1 |
|
|
| 1:N |
|
|
| N:M |
|
|
GESTIÓN DEL ESPACIO FÍSICO
| Tipo de índice | MongoDB | Couchbase |
| Almacenamiento en mesa | Directorio del sistema de archivos | Directorio del sistema de archivos |
| Almacenamiento de índices | Directorio del sistema de archivos | Directorio del sistema de archivos |
| Particionamiento - Datos | Se admite la fragmentación por rangos y por hash. | Partición hash
Almacenado en 1024 vbuckets |
| Particionamiento - Índice | Vinculado a la estrategia de fragmentación de colecciones, ya que todos los (sub) índices son locales a cada nodo mongod. | Siempre separado del cubo
Índice global (puede utilizar una estrategia diferente a la del cubo/colección) Admite la partición hash de los índices. Partición de rangos, la indexación parcial es manual mediante índices parciales. |
SDKs
Mi conocimiento personal de ambos SDK es limitado. Debería haber APIs, drivers y conectores equivalentes con los dos productos. Si no es así, por favor háganoslo saber.
| SDK | MongoDB | Couchbase |
| Java | Controlador java de MongoDB | SDK Java de Couchbase,
Simba y CDATA JDBC |
| C | Controlador C de MongoDB
Controlador ODBC |
Couchbase C SDK,
Simba y CDATA ODBC |
| .NET, LINQ | Proveedor Mongodb .NET. | Proveedor .NET de Couchbase
Proveedor LINQ |
| PHP, Python, Perl, Node.js | SDK de MongoDB en todos estos idiomas | SDK de Couchbase en todos estos idiomas |
| golang | Mongodb go sdk | SDK de Couchbase Go |
LENGUAJE DE CONSULTA
SELECCIONAR: Mongo tiene múltiples APIs para seleccionar los documentos. find(), aggregate() pueden hacer el trabajo de simples sentencias SELECT. Veremos aggregate() más adelante en esta sección.
|
1 2 3 4 5 6 7 |
/* MongoDB */ db.CUSTOMER.find({zip:94040}) /* Couchbase: N1QL */ SELECT * FROM CUSTOMER WHERE zip = 94040; |
INSERTAR
En MongoDB, proporcionar _id es opcional. Si no proporcionas su valor, Mongo generará el valor del campo y lo guardará. Proporcionar document KEY es obligatorio en Couchbase.
|
1 2 3 4 5 6 7 8 9 |
/* MongoDB */ db.CUSTOMER.save({_id: "xyz124", {“id”: “xyz124”, “name”: “Joe Montana”, “status”: “Premium”, “zip”: 94040}) /* Couchbase:N1QL */ INSERT INTO CUSTOMER(KEY, VALUE) VALUES (‘xyz124’, {“id”: “xyz124”, “name”: “Joe Montana”, “status”: “Premium”, “zip”: 94040}) |
ACTUALIZACIÓN
|
1 2 3 4 5 6 7 |
/* MongoDB */ db.CUSTOMER.update({_id:”xyz124’},{zip:94587}) /* Coudhbase:N1QL */ UPDATE CUSTOMER SET zip = 94587 WHERE id = ‘xyz124’ |
BORRAR
|
1 2 3 4 5 6 7 8 |
/* MongoDB */ db.CUSTOMER.remove({_id:‘pqr482’}) /* Couchbase:N1QL. One of the statements will do for this data/schema. */ DELETE FROM CUSTOMER WHERE id = ‘pqr482’; DELETE FROM CUSTOMER WHERE META().id = ‘pqr482’; |
FUSIONAR: La operación MERGE en un conjunto de documentos JSON es a menudo necesaria como parte de su proceso ETL o actualizaciones diarias. La sentencia MERGE puede involucrar fuentes de datos complejas con predicados complejos basados en reglas de negocio. Couchbase proporciona la operación MERGE estándar con la misma semántica. En MongoDB, tenías que escribir un largo programa para hacer esto, pero entonces algunas de las reglas de la operación MERGE (por ejemplo, cada documento SOLO debe ser actualizado una vez) son difíciles de hacer cumplir desde una aplicación. En Couchbase, puedes simplemente usar la función Declaración MERGEcomo los RDBMS.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
/* MongoDB */ Unavailable. Need to work around using aggregate(), custom-logic program, and update(). /* Couchbase:N1QL Second statement is ANSI SQL Compliant*/ MERGE INTO CUSTOMER USING (SELECT id FROM CN WHERE x < 10) AS CN ON KEY CN.id WHEN MATCHED THEN UPDATE SET CUSTOMER.o4=1; MERGE INTO CUSTOMER USING (SELECT id FROM CN WHERE x < 10) AS CN ON (CN.id = META(CUSTOKMER).id) WHEN MATCHED THEN UPDATE SET CUSTOMER.o4=1; |
DESCRIBE:
Los datos JSON son autodescriptivos y flexibles. MongoDB Schema helper está disponible a través de Visualización de la brújula sólo en la edición Enterprise.
Couchbase tiene INFER para analizar y entender el esquema. Tanto el servicio de consulta como el servicio analítico pueden inferir el esquema.
-
- Servicio de consulta Comando INFER
- El Servicio de Análisis ha array_infer_schema() función.
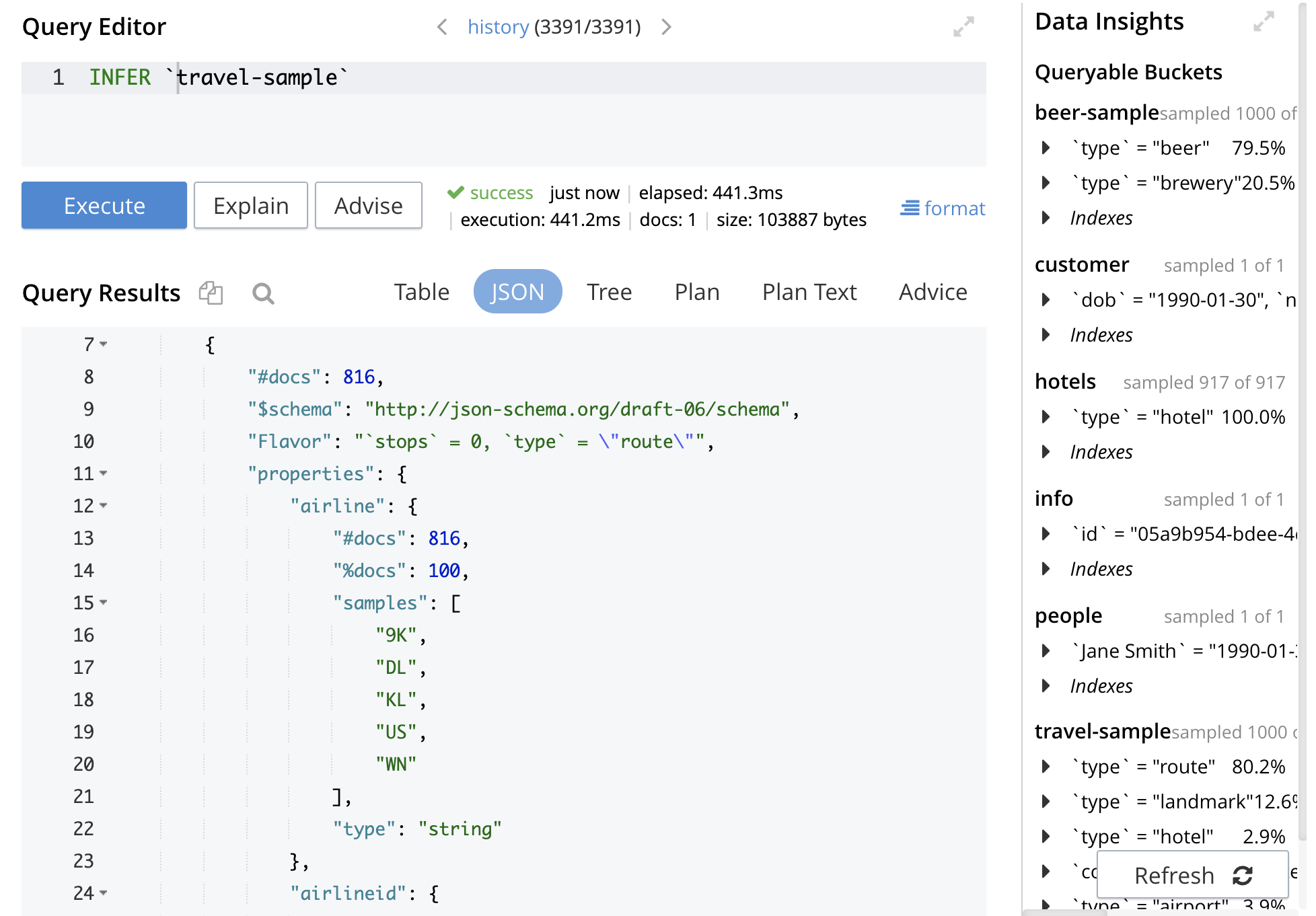
Este es el ejemplo de la salida INFER.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 293 294 295 296 297 298 299 300 301 302 303 304 305 306 307 308 309 310 311 312 313 314 315 316 317 318 319 320 321 322 323 324 325 326 327 328 329 330 331 332 333 334 335 336 337 338 339 340 341 342 343 344 345 346 347 348 349 350 351 352 353 354 355 356 357 358 359 360 361 362 363 364 365 366 367 368 369 370 371 372 373 374 375 376 377 378 379 380 381 382 383 384 385 386 387 388 389 390 391 392 393 394 395 396 397 398 399 400 401 402 403 404 405 406 407 408 409 410 411 412 413 414 415 416 417 418 419 420 421 422 423 424 425 426 427 428 429 430 431 432 433 434 435 436 437 438 439 440 441 442 443 444 445 446 447 448 449 450 451 452 453 454 455 456 457 458 459 460 461 462 463 464 465 466 467 468 469 470 471 472 473 474 475 476 477 478 479 480 481 482 483 484 485 486 487 488 489 490 491 492 493 494 495 496 497 498 499 500 501 502 503 504 505 506 507 508 509 510 511 512 513 514 515 516 517 518 519 520 521 522 523 524 525 526 527 528 529 530 531 532 533 534 535 536 537 538 539 540 541 542 543 544 545 546 547 548 549 550 551 552 553 554 555 556 557 558 559 560 561 562 563 564 565 566 567 568 569 570 571 572 573 574 575 576 577 578 579 580 581 582 583 584 585 586 587 588 589 590 591 592 593 594 595 596 597 598 599 600 601 602 603 604 605 606 607 608 609 610 611 612 613 614 615 616 617 618 619 620 621 622 623 624 625 626 627 628 629 630 631 632 633 634 635 636 637 638 639 640 641 642 643 644 645 646 647 648 649 650 651 652 653 654 655 656 657 658 659 660 661 662 663 664 665 666 667 668 669 670 671 672 673 674 675 676 677 678 679 680 681 682 683 684 685 686 687 688 689 690 691 692 693 694 695 696 697 698 699 700 701 702 703 704 705 706 707 708 709 710 711 712 713 714 715 716 717 718 719 720 721 722 723 724 725 726 727 728 729 730 731 732 733 734 735 736 737 738 739 740 741 742 743 744 745 746 747 748 749 750 751 752 753 754 755 756 757 758 759 760 761 762 763 764 765 766 767 768 769 770 771 772 773 774 775 776 777 778 779 780 781 782 783 784 785 786 787 788 789 790 791 792 793 794 795 796 797 798 799 800 801 802 803 804 805 806 807 808 809 810 811 812 813 814 815 816 817 818 819 820 821 822 823 824 825 826 827 828 829 830 831 832 833 834 835 836 837 838 839 840 841 842 843 844 845 846 847 848 849 850 851 852 853 854 855 856 857 858 859 860 861 862 863 864 865 866 867 868 869 870 871 872 873 874 875 876 877 878 879 880 881 882 883 884 885 886 887 888 889 890 891 892 893 894 895 896 897 898 899 900 901 902 903 904 905 906 907 908 909 910 911 912 913 914 915 916 917 918 919 920 921 922 923 924 925 926 927 928 929 930 931 932 933 934 935 936 937 938 939 940 941 942 943 944 945 946 947 948 949 950 951 952 953 954 955 956 957 958 959 960 961 962 963 964 965 966 967 968 969 970 971 972 973 974 975 976 977 978 979 980 981 982 983 984 985 986 987 988 989 990 991 992 993 994 995 996 997 998 999 1000 1001 1002 1003 1004 1005 1006 1007 1008 1009 1010 1011 1012 1013 1014 1015 1016 1017 1018 1019 1020 1021 1022 1023 1024 1025 1026 1027 1028 1029 1030 1031 1032 1033 1034 1035 1036 1037 1038 1039 1040 1041 1042 1043 1044 1045 1046 1047 1048 1049 1050 1051 1052 1053 1054 1055 1056 1057 1058 1059 1060 1061 1062 1063 1064 1065 1066 1067 1068 1069 1070 1071 1072 1073 1074 1075 1076 1077 1078 1079 1080 1081 1082 1083 1084 1085 1086 1087 1088 1089 1090 1091 1092 1093 1094 1095 1096 1097 1098 1099 1100 1101 1102 1103 1104 1105 1106 1107 1108 1109 1110 1111 1112 1113 1114 1115 1116 1117 1118 1119 1120 1121 1122 1123 1124 1125 1126 1127 1128 1129 1130 1131 1132 1133 1134 1135 1136 1137 1138 1139 1140 1141 1142 1143 1144 1145 1146 1147 1148 1149 1150 1151 1152 1153 1154 1155 1156 1157 1158 1159 1160 1161 1162 1163 1164 1165 1166 1167 1168 1169 1170 1171 1172 1173 1174 1175 1176 1177 1178 1179 1180 1181 1182 1183 1184 1185 1186 1187 1188 1189 1190 1191 1192 1193 1194 1195 1196 1197 1198 1199 1200 1201 1202 1203 1204 1205 1206 1207 1208 1209 1210 1211 1212 1213 1214 1215 1216 1217 1218 1219 1220 1221 1222 1223 1224 1225 1226 1227 1228 1229 1230 1231 1232 1233 1234 1235 1236 1237 1238 1239 1240 1241 1242 1243 1244 1245 1246 1247 1248 1249 1250 1251 1252 1253 1254 1255 1256 1257 1258 1259 1260 1261 1262 1263 1264 1265 1266 1267 1268 1269 1270 1271 1272 1273 1274 1275 1276 1277 1278 1279 1280 1281 1282 1283 1284 1285 1286 1287 1288 1289 1290 1291 1292 1293 1294 1295 1296 1297 1298 1299 1300 1301 1302 1303 1304 1305 1306 1307 1308 1309 1310 1311 1312 1313 1314 1315 1316 1317 1318 1319 1320 1321 1322 1323 1324 1325 1326 1327 1328 1329 1330 1331 1332 1333 1334 1335 1336 1337 1338 1339 1340 1341 1342 1343 1344 1345 1346 1347 1348 1349 1350 1351 1352 1353 1354 1355 1356 1357 1358 1359 1360 1361 1362 1363 1364 1365 1366 1367 1368 1369 1370 1371 1372 1373 1374 1375 1376 1377 1378 1379 1380 1381 1382 1383 1384 1385 1386 1387 1388 1389 1390 1391 1392 1393 1394 1395 1396 1397 1398 1399 1400 1401 1402 1403 1404 1405 1406 1407 1408 1409 1410 1411 1412 1413 1414 1415 1416 1417 1418 1419 1420 1421 1422 1423 1424 1425 1426 1427 1428 1429 1430 1431 1432 1433 1434 1435 1436 1437 1438 1439 1440 1441 1442 1443 1444 1445 1446 1447 1448 1449 1450 1451 1452 1453 1454 1455 1456 1457 1458 1459 1460 1461 1462 1463 1464 1465 1466 1467 1468 1469 1470 1471 1472 1473 1474 1475 1476 1477 1478 1479 1480 1481 1482 1483 1484 1485 1486 1487 1488 1489 1490 1491 1492 1493 1494 1495 1496 1497 1498 1499 1500 1501 1502 1503 1504 1505 1506 1507 1508 1509 1510 1511 1512 1513 1514 1515 1516 1517 1518 1519 1520 1521 1522 1523 1524 1525 1526 1527 1528 1529 1530 1531 1532 1533 1534 1535 1536 1537 1538 1539 1540 1541 1542 1543 1544 1545 1546 1547 1548 1549 1550 1551 1552 1553 1554 1555 1556 1557 1558 1559 1560 1561 1562 1563 1564 1565 1566 1567 1568 1569 1570 1571 1572 1573 1574 1575 1576 1577 1578 1579 1580 1581 1582 1583 1584 1585 1586 1587 1588 1589 1590 1591 1592 1593 1594 1595 1596 1597 1598 1599 1600 1601 1602 1603 1604 1605 1606 1607 1608 1609 1610 1611 1612 1613 1614 1615 1616 1617 1618 1619 1620 1621 1622 1623 1624 1625 1626 1627 1628 1629 1630 1631 1632 1633 1634 1635 1636 1637 1638 1639 1640 1641 1642 1643 1644 1645 1646 1647 1648 1649 1650 1651 1652 1653 1654 1655 1656 1657 1658 1659 1660 1661 1662 1663 1664 1665 1666 1667 1668 1669 1670 1671 1672 1673 1674 1675 1676 1677 1678 1679 1680 1681 1682 1683 1684 1685 1686 1687 1688 1689 1690 1691 1692 1693 1694 1695 1696 1697 1698 1699 1700 1701 1702 1703 1704 1705 1706 1707 1708 1709 1710 1711 1712 1713 1714 1715 1716 1717 1718 1719 1720 1721 1722 1723 1724 1725 1726 1727 1728 1729 1730 1731 1732 1733 1734 1735 1736 1737 1738 1739 1740 1741 1742 1743 1744 1745 1746 1747 1748 1749 1750 1751 1752 1753 1754 1755 1756 1757 1758 1759 1760 1761 1762 1763 1764 1765 1766 1767 1768 1769 1770 1771 1772 1773 1774 1775 1776 1777 1778 1779 1780 1781 1782 1783 1784 1785 1786 1787 1788 1789 1790 1791 1792 1793 1794 1795 1796 1797 1798 1799 1800 1801 1802 1803 1804 1805 1806 1807 1808 1809 1810 1811 1812 1813 1814 1815 1816 1817 1818 1819 1820 1821 1822 1823 1824 1825 1826 1827 1828 1829 1830 1831 1832 1833 1834 1835 1836 1837 1838 1839 1840 1841 1842 1843 1844 1845 1846 1847 1848 1849 1850 1851 1852 1853 1854 1855 1856 1857 1858 1859 1860 1861 1862 1863 1864 1865 1866 1867 1868 1869 1870 1871 1872 1873 1874 1875 1876 1877 1878 1879 1880 1881 1882 1883 1884 1885 1886 1887 1888 1889 1890 1891 1892 1893 1894 1895 1896 1897 1898 1899 1900 1901 1902 1903 1904 1905 1906 1907 1908 1909 1910 1911 1912 1913 1914 1915 1916 1917 1918 1919 1920 1921 1922 1923 1924 1925 1926 1927 1928 1929 1930 1931 1932 1933 1934 1935 1936 1937 1938 1939 1940 1941 1942 1943 1944 1945 1946 1947 1948 1949 1950 1951 1952 1953 1954 1955 1956 1957 1958 1959 1960 1961 1962 1963 1964 1965 1966 1967 1968 1969 1970 1971 1972 1973 1974 1975 1976 1977 1978 1979 1980 1981 1982 1983 1984 1985 1986 1987 1988 1989 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 2000 2001 2002 2003 2004 2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 2020 2021 2022 2023 2024 2025 2026 2027 2028 2029 2030 2031 2032 2033 2034 2035 2036 2037 2038 2039 2040 2041 2042 2043 2044 2045 2046 2047 2048 2049 2050 2051 2052 2053 2054 2055 2056 2057 2058 2059 2060 2061 2062 2063 2064 2065 2066 2067 2068 2069 2070 2071 2072 2073 2074 2075 2076 2077 2078 2079 2080 2081 2082 2083 2084 2085 2086 2087 2088 2089 2090 2091 2092 2093 2094 2095 2096 2097 2098 2099 2100 2101 2102 2103 2104 2105 2106 2107 2108 2109 2110 2111 2112 2113 2114 2115 2116 2117 2118 2119 2120 2121 2122 2123 2124 2125 2126 2127 2128 2129 2130 2131 2132 2133 2134 2135 2136 2137 2138 2139 2140 2141 2142 2143 2144 2145 2146 2147 2148 2149 2150 2151 2152 2153 2154 2155 2156 2157 2158 2159 2160 2161 2162 2163 2164 2165 2166 2167 2168 2169 2170 2171 2172 2173 2174 2175 2176 2177 2178 2179 2180 2181 2182 2183 2184 2185 2186 2187 2188 2189 2190 2191 2192 2193 2194 2195 2196 2197 2198 2199 2200 2201 2202 2203 2204 2205 2206 2207 2208 2209 2210 2211 2212 2213 2214 2215 2216 2217 2218 2219 2220 2221 2222 2223 2224 2225 2226 2227 2228 2229 2230 2231 2232 2233 2234 2235 2236 2237 2238 2239 2240 2241 2242 2243 2244 2245 2246 2247 2248 2249 2250 2251 2252 2253 2254 2255 2256 2257 2258 2259 2260 2261 2262 2263 2264 2265 2266 2267 2268 2269 2270 2271 2272 2273 2274 2275 2276 2277 2278 2279 2280 2281 2282 2283 2284 2285 2286 2287 2288 2289 2290 2291 2292 2293 2294 2295 2296 2297 2298 2299 2300 2301 2302 2303 2304 2305 2306 2307 2308 2309 2310 2311 2312 2313 2314 2315 2316 2317 2318 2319 2320 2321 2322 2323 2324 2325 2326 2327 2328 2329 2330 2331 2332 2333 2334 2335 2336 2337 2338 2339 2340 2341 2342 2343 2344 |
INFER `travel-sample`; { "requestID": "59c444b1-a468-486b-aac3-949be1ddaed1", "clientContextID": "634e367b-ac7c-4815-90da-1506d6902d78", "signature": null, "results": [ [ { "#docs": 816, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "`stops` = 0, `type` = \"route\"", "properties": { "airline": { "#docs": 816, "%docs": 100, "samples": [ "9K", "DL", "KL", "US", "WN" ], "type": "string" }, "airlineid": { "#docs": 816, "%docs": 100, "samples": [ "airline_1629", "airline_2009", "airline_3090", "airline_4547", "airline_5265" ], "type": "string" }, "destinationairport": { "#docs": 816, "%docs": 100, "samples": [ "ACK", "ATL", "BWI", "CMH", "MAN" ], "type": "string" }, "distance": { "#docs": 816, "%docs": 100, "samples": [ 49.792009674515775, 335.34343397923425, 775.5437991859698, 2524.506189235734, 6139.9648921034795 ], "type": "number" }, "equipment": { "#docs": [ 1, 815 ], "%docs": [ 0.12, 99.87 ], "samples": [ [ null ], [ "73W 738", "763", "CNA", "CRJ", "ERJ CRJ" ] ], "type": [ "null", "string" ] }, "id": { "#docs": 816, "%docs": 100, "samples": [ 3645, 20935, 36958, 59930, 64450 ], "type": "number" }, "schedule": { "#docs": 816, "%docs": 100, "items": { "#docs": 17124, "$schema": "https://json-schema.org/draft-06/schema", "properties": { "day": { "type": "number" }, "flight": { "type": "string" }, "utc": { "type": "string" } }, "type": "object" }, "maxItems": 31, "minItems": 10, "samples": [ [ { "day": 0, "flight": "9K006", "utc": "19:36:00" }, { "day": 0, "flight": "9K802", "utc": "22:34:00" }, { "day": 0, "flight": "9K210", "utc": "20:08:00" }, { "day": 0, "flight": "9K316", "utc": "01:02:00" }, { "day": 1, "flight": "9K408", "utc": "05:50:00" }, { "day": 1, "flight": "9K452", "utc": "12:34:00" }, { "day": 1, "flight": "9K799", "utc": "04:36:00" }, { "day": 2, "flight": "9K157", "utc": "19:35:00" }, { "day": 2, "flight": "9K923", "utc": "01:09:00" }, { "day": 3, "flight": "9K201", "utc": "09:24:00" }, { "day": 4, "flight": "9K355", "utc": "04:29:00" }, { "day": 4, "flight": "9K845", "utc": "12:24:00" }, { "day": 4, "flight": "9K515", "utc": "17:56:00" }, { "day": 4, "flight": "9K472", "utc": "11:16:00" }, { "day": 4, "flight": "9K506", "utc": "04:17:00" }, { "day": 5, "flight": "9K040", "utc": "20:32:00" }, { "day": 5, "flight": "9K273", "utc": "04:29:00" }, { "day": 5, "flight": "9K131", "utc": "22:14:00" }, { "day": 5, "flight": "9K494", "utc": "18:54:00" }, { "day": 6, "flight": "9K037", "utc": "21:13:00" }, { "day": 6, "flight": "9K786", "utc": "16:07:00" }, { "day": 6, "flight": "9K724", "utc": "15:53:00" } ], [ { "day": 0, "flight": "DL113", "utc": "15:48:00" }, { "day": 0, "flight": "DL864", "utc": "09:13:00" }, { "day": 1, "flight": "DL880", "utc": "23:27:00" }, { "day": 2, "flight": "DL399", "utc": "06:42:00" }, { "day": 2, "flight": "DL705", "utc": "15:54:00" }, { "day": 2, "flight": "DL630", "utc": "21:52:00" }, { "day": 3, "flight": "DL570", "utc": "00:02:00" }, { "day": 4, "flight": "DL702", "utc": "18:46:00" }, { "day": 4, "flight": "DL668", "utc": "20:09:00" }, { "day": 4, "flight": "DL214", "utc": "10:27:00" }, { "day": 4, "flight": "DL748", "utc": "13:36:00" }, { "day": 5, "flight": "DL935", "utc": "20:48:00" }, { "day": 6, "flight": "DL074", "utc": "19:27:00" }, { "day": 6, "flight": "DL618", "utc": "10:54:00" }, { "day": 6, "flight": "DL983", "utc": "19:41:00" }, { "day": 6, "flight": "DL951", "utc": "17:45:00" }, { "day": 6, "flight": "DL546", "utc": "12:19:00" } ], [ { "day": 0, "flight": "KL362", "utc": "22:09:00" }, { "day": 0, "flight": "KL430", "utc": "10:39:00" }, { "day": 0, "flight": "KL249", "utc": "18:12:00" }, { "day": 1, "flight": "KL670", "utc": "16:10:00" }, { "day": 1, "flight": "KL164", "utc": "00:58:00" }, { "day": 2, "flight": "KL015", "utc": "16:29:00" }, { "day": 3, "flight": "KL731", "utc": "17:12:00" }, { "day": 4, "flight": "KL047", "utc": "14:58:00" }, { "day": 4, "flight": "KL854", "utc": "08:41:00" }, { "day": 4, "flight": "KL173", "utc": "21:20:00" }, { "day": 5, "flight": "KL006", "utc": "19:12:00" }, { "day": 5, "flight": "KL886", "utc": "21:32:00" }, { "day": 6, "flight": "KL448", "utc": "22:24:00" }, { "day": 6, "flight": "KL286", "utc": "14:05:00" }, { "day": 6, "flight": "KL170", "utc": "03:36:00" } ], [ { "day": 0, "flight": "US931", "utc": "19:24:00" }, { "day": 0, "flight": "US257", "utc": "20:54:00" }, { "day": 1, "flight": "US375", "utc": "08:22:00" }, { "day": 1, "flight": "US674", "utc": "20:41:00" }, { "day": 1, "flight": "US866", "utc": "03:58:00" }, { "day": 1, "flight": "US142", "utc": "16:05:00" }, { "day": 2, "flight": "US572", "utc": "19:33:00" }, { "day": 2, "flight": "US270", "utc": "12:58:00" }, { "day": 2, "flight": "US151", "utc": "07:46:00" }, { "day": 3, "flight": "US513", "utc": "13:58:00" }, { "day": 3, "flight": "US410", "utc": "00:44:00" }, { "day": 3, "flight": "US262", "utc": "14:52:00" }, { "day": 3, "flight": "US962", "utc": "05:32:00" }, { "day": 3, "flight": "US527", "utc": "17:42:00" }, { "day": 4, "flight": "US068", "utc": "04:14:00" }, { "day": 4, "flight": "US448", "utc": "09:39:00" }, { "day": 4, "flight": "US914", "utc": "07:16:00" }, { "day": 4, "flight": "US090", "utc": "06:06:00" }, { "day": 4, "flight": "US514", "utc": "14:38:00" }, { "day": 5, "flight": "US817", "utc": "09:41:00" }, { "day": 5, "flight": "US665", "utc": "03:49:00" }, { "day": 6, "flight": "US740", "utc": "07:27:00" }, { "day": 6, "flight": "US803", "utc": "18:37:00" }, { "day": 6, "flight": "US300", "utc": "09:08:00" }, { "day": 6, "flight": "US496", "utc": "07:05:00" } ], [ { "day": 0, "flight": "WN044", "utc": "13:39:00" }, { "day": 0, "flight": "WN799", "utc": "07:15:00" }, { "day": 0, "flight": "WN792", "utc": "09:16:00" }, { "day": 1, "flight": "WN030", "utc": "09:51:00" }, { "day": 1, "flight": "WN377", "utc": "03:41:00" }, { "day": 2, "flight": "WN081", "utc": "01:53:00" }, { "day": 2, "flight": "WN413", "utc": "04:49:00" }, { "day": 2, "flight": "WN132", "utc": "16:06:00" }, { "day": 2, "flight": "WN882", "utc": "21:16:00" }, { "day": 2, "flight": "WN773", "utc": "04:55:00" }, { "day": 3, "flight": "WN286", "utc": "04:17:00" }, { "day": 3, "flight": "WN295", "utc": "04:35:00" }, { "day": 4, "flight": "WN932", "utc": "16:34:00" }, { "day": 4, "flight": "WN315", "utc": "00:35:00" }, { "day": 4, "flight": "WN016", "utc": "09:10:00" }, { "day": 4, "flight": "WN509", "utc": "22:28:00" }, { "day": 5, "flight": "WN090", "utc": "13:46:00" }, { "day": 6, "flight": "WN456", "utc": "04:05:00" }, { "day": 6, "flight": "WN111", "utc": "05:10:00" } ] ], "type": "array" }, "sourceairport": { "#docs": 816, "%docs": 100, "samples": [ "HYA", "JFK", "ORD", "SJU", "VLD" ], "type": "string" }, "stops": { "#docs": 816, "%docs": 100, "samples": [ 0 ], "type": "number" }, "type": { "#docs": 816, "%docs": 100, "samples": [ "route" ], "type": "string" } }, "type": "object" }, { "#docs": 109, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "`type` = \"landmark\"", "properties": { "activity": { "#docs": 109, "%docs": 100, "samples": [ "buy", "do", "drink", "eat", "see" ], "type": "string" }, "address": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "samples": [ [ null ], [ "310 Uxbridge Rd, W12 7LJ", "Craven Cottage, Stevenage Rd, ...", "Warwick Road, SW5 9TA" ] ], "type": [ "null", "string" ] }, "alt": { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "samples": [ [ null ], [ "previously Shanghai Red's" ] ], "type": [ "null", "string" ] }, "city": { "#docs": 109, "%docs": 100, "samples": [ "Carpentras", "Llanddona", "Llangrannog", "London", "Los Angeles" ], "type": "string" }, "content": { "#docs": 109, "%docs": 100, "samples": [ "Hosts frequent conventions, ex...", "Originally a dance hall, this ...", "The Hollywood Wax Museum is th...", "The home of Premier League foo...", "several annual horse racing, b..." ], "type": "string" }, "country": { "#docs": 109, "%docs": 100, "samples": [ "France", "United Kingdom", "United States" ], "type": "string" }, "directions": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "samples": [ [ null ], [ "about 10 min walk from both Pu...", "tube: Earl's Court or West Bro...", "tube: Shepherd's Bush Market" ] ], "type": [ "null", "string" ] }, "email": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "samples": [ [ null ], [ "enquiries@fulhamfc.com", "info@eco.co.uk", "notes@bushhallmusic.co.uk" ] ], "type": [ "null", "string" ] }, "geo": { "#docs": 109, "%docs": 100, "properties": { "accuracy": { "#docs": 109, "%docs": 100, "samples": [ "APPROXIMATE", "RANGE_INTERPOLATED", "ROOFTOP" ], "type": "string" }, "lat": { "#docs": 109, "%docs": 100, "samples": [ 34.101757, 44.037882130818225, 51.4749, 51.4888, 51.5064 ], "type": "number" }, "lon": { "#docs": 109, "%docs": 100, "samples": [ -118.338056, -0.2317, -0.2216, -0.1977, 5.064881989019341 ], "type": "number" } }, "samples": [ { "accuracy": "APPROXIMATE", "lat": 51.4749, "lon": -0.2216 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 34.101757, "lon": -118.338056 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 44.037882130818225, "lon": 5.064881989019341 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 51.5064, "lon": -0.2317 }, { "accuracy": "ROOFTOP", "lat": 51.4888, "lon": -0.1977 } ], "type": "object" }, "hours": { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "samples": [ [ null ], [ "10AM-midnight daily" ] ], "type": [ "null", "string" ] }, "id": { "#docs": 109, "%docs": 100, "samples": [ 11755, 16141, 16149, 16387, 40348 ], "type": "number" }, "image": { "#docs": [ 1, 108 ], "%docs": [ 0.91, 99.08 ], "samples": [ [ null ], [ "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki...", "https://en.wikivoyage.org/wiki..." ] ], "type": [ "null", "string" ] }, "image_direct_url": { "#docs": 7, "%docs": 6.42, "samples": [ "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "https://upload.wikimedia.org/w...", "" ], "type": "string" }, "name": { "#docs": 109, "%docs": 100, "samples": [ "Bush Hall", "Earl's Court Exhibition Centre", "Fulham FC", "Hippodrome of Saint-Ponchon", "Hollywood Wax Museum" ], "type": "string" }, "phone": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "samples": [ [ null ], [ "+44 20 7385-1200", "+44 20 8222-6955", "+44 870 442 1222" ] ], "type": [ "null", "string" ] }, "price": { "#docs": [ 108, 1 ], "%docs": [ 99.08, 0.91 ], "samples": [ [ null ], [ "Adults (13+) $15.95, children ..." ] ], "type": [ "null", "string" ] }, "state": { "#docs": [ 3, 106 ], "%docs": [ 2.75, 97.24 ], "samples": [ [ null ], [ "Alsace-Champagne-Ardenne-Lorra...", "Basse-Normandie", "California", "Provence-Alpes-Côte d'Azur", "Île-de-France" ] ], "type": [ "null", "string" ] }, "title": { "#docs": 109, "%docs": 100, "samples": [ "Carpentras", "Hollywood", "London/Hammersmith and Fulham", "London/South Kensington-Chelse...", "Wales Coast Path" ], "type": "string" }, "tollfree": { "#docs": 109, "%docs": 100, "samples": [ null ], "type": "null" }, "type": { "#docs": 109, "%docs": 100, "samples": [ "landmark" ], "type": "string" }, "url": { "#docs": [ 106, 3 ], "%docs": [ 97.24, 2.75 ], "samples": [ [ null ], [ "https://www.bushhallmusic.co.uk...", "https://www.eco.co.uk/", "https://www.fulhamfc.com/" ] ], "type": [ "null", "string" ] } }, "type": "object" }, { "#docs": 23, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "`type` = \"hotel\"", "properties": { "address": { "#docs": [ 2, 21 ], "%docs": [ 8.69, 91.3 ], "samples": [ [ null ], [ "68, rue de Longchamp", "Capstone Road, ME7 3JE", "Gower Holiday Village, Scurlag...", "Knockard Road,PH16 5HJ, 0870 0...", "Llanbedrgoch" ] ], "type": [ "null", "string" ] }, "alias": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "former Concorde Lafayette" ] ], "type": [ "null", "string" ] }, "checkin": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "3PM" ] ], "type": [ "null", "string" ] }, "checkout": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "noon" ] ], "type": [ "null", "string" ] }, "city": { "#docs": [ 1, 22 ], "%docs": [ 4.34, 95.65 ], "samples": [ [ null ], [ "Inyo County", "Medway", "Paris", "Pitlochry", "Riverside County" ] ], "type": [ "null", "string" ] }, "country": { "#docs": 23, "%docs": 100, "samples": [ "France", "United Kingdom", "United States" ], "type": "string" }, "description": { "#docs": 23, "%docs": 100, "samples": [ "(Year Round). This RV campgro...", "3-star boutique hotel.", "40 bed summer hostel about 3 m...", "Easily accessible from West En...", "Great 62 bed hostel near the t..." ], "type": "string" }, "directions": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "downtown" ] ], "type": [ "null", "string" ] }, "email": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "julia@number38thegower.co.uk" ] ], "type": [ "null", "string" ] }, "fax": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "+1-310-821-8098" ] ], "type": [ "null", "string" ] }, "free_breakfast": { "#docs": 23, "%docs": 100, "samples": [ false, true ], "type": "boolean" }, "free_internet": { "#docs": 23, "%docs": 100, "samples": [ false, true ], "type": "boolean" }, "free_parking": { "#docs": 23, "%docs": 100, "samples": [ false, true ], "type": "boolean" }, "geo": { "#docs": 23, "%docs": 100, "properties": { "accuracy": { "#docs": 23, "%docs": 100, "samples": [ "APPROXIMATE", "RANGE_INTERPOLATED", "ROOFTOP" ], "type": "string" }, "lat": { "#docs": 23, "%docs": 100, "samples": [ 33.9829, 36.60545, 48.86522, 51.35785, 56.7049 ], "type": "number" }, "lon": { "#docs": 23, "%docs": 100, "samples": [ -117.14634, -116.1545, -3.7291, 0.55818, 2.28566 ], "type": "number" } }, "samples": [ { "accuracy": "APPROXIMATE", "lat": 56.7049, "lon": -3.7291 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 36.60545, "lon": -117.14634 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 48.86522, "lon": 2.28566 }, { "accuracy": "RANGE_INTERPOLATED", "lat": 51.35785, "lon": 0.55818 }, { "accuracy": "ROOFTOP", "lat": 33.9829, "lon": -116.1545 } ], "type": "object" }, "id": { "#docs": 23, "%docs": 100, "samples": [ 7392, 10025, 12928, 21663, 22461 ], "type": "number" }, "name": { "#docs": 23, "%docs": 100, "samples": [ "Hotel Longchamp Elysées", "Medway Youth Hostel", "Pitlochry Youth Hostel", "Ryan Campground", "Stovepipe Wells RV Campground" ], "type": "string" }, "pets_ok": { "#docs": 23, "%docs": 100, "samples": [ false, true ], "type": "boolean" }, "phone": { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "samples": [ [ null ], [ "+44 1248 450051", "+44 870 770 5964" ] ], "type": [ "null", "string" ] }, "price": { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "samples": [ [ null ], [ "$10 per night", "$23 a night" ] ], "type": [ "null", "string" ] }, "public_likes": { "#docs": 23, "%docs": 100, "items": { "type": "string" }, "maxItems": 9, "minItems": 0, "samples": [ [], [ "Julius Tromp I", "Corrine Hilll", "Jaeden McKenzie", "Vallie Ryan", "Brian Kilback", "Lilian McLaughlin", "Ms. Moses Feeney", "Elnora Trantow" ], [ "Mr. Franco Collins", "Cloyd Stark", "Eliseo Herman" ], [ "Ms. Wiley Torp", "Missouri Sauer", "Chanel Kirlin", "Trystan Rolfson", "Mr. Emma Oberbrunner", "Marina Stracke", "Cody Hand", "Tracey Price", "Raven Romaguera" ], [ "Stefan Greenfelder", "Rosemary Doyle", "Abdullah Lindgren", "Gregorio Emard" ] ], "type": "array" }, "reviews": { "#docs": 23, "%docs": 100, "items": { "#docs": 3, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "", "properties": { "author": { "#docs": 3, "%docs": 100, "samples": [ "Cornelius Brakus", "Dorcas VonRueden", "Jo Collier" ], "type": "string" }, "content": { "#docs": 3, "%docs": 100, "samples": [ "A decent-sized room for the lo...", "GOOD DEAL FOR THE PRICE AND LO...", "Stay away of this hotel!! With..." ], "type": "string" }, "date": { "#docs": 3, "%docs": 100, "samples": [ "2012-09-05 22:33:09 +0300", "2012-09-11 19:21:15 +0300", "2014-06-11 09:35:15 +0300" ], "type": "string" }, "ratings": { "#docs": 3, "%docs": 100, "properties": { "Business service (e.g., internet access)": { "#docs": 1, "%docs": 33.33, "samples": [ 1 ], "type": "number" }, "Check in / front desk": { "#docs": 2, "%docs": 66.66, "samples": [ 2, 5 ], "type": "number" }, "Cleanliness": { "#docs": 2, "%docs": 66.66, "samples": [ 4, 5 ], "type": "number" }, "Location": { "#docs": 3, "%docs": 100, "samples": [ 2, 3, 5 ], "type": "number" }, "Overall": { "#docs": 3, "%docs": 100, "samples": [ 1, 4, 5 ], "type": "number" }, "Rooms": { "#docs": 3, "%docs": 100, "samples": [ 1, 3, 5 ], "type": "number" }, "Service": { "#docs": 3, "%docs": 100, "samples": [ 2, 3, 5 ], "type": "number" }, "Value": { "#docs": 3, "%docs": 100, "samples": [ 2, 5 ], "type": "number" } }, "samples": [ { "Cleanliness": 4, "Location": 3, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } ], "type": "object" } }, "type": "object" }, "maxItems": 9, "minItems": 0, "samples": [ [ { "author": "Bernhard Armstrong III", "content": "When I told the cab driver where I was staying, he did a double take. That should have been my warning but since I had no where else to go, I was stuck. To say this place is tired is an understatement. Upon entering, it took me about 10 minutes to locate the 'front desk'...which is little more than a recessed kiosk. I got to the elevator and into my room. The room was cavernous...very large and covered in old stained pink carpeting. The doors rattled and the lock didn't seem secure. At night, I wedged a chair against the door for added protection. This was a huge room but the sparse furniture in the room was all set around the walls and made the room uncomfortably large. The bed was set against one wall and the small tv was set all the way across the room on an old dresser. It was so far away, the remote didn't work unless I got out of bed and walked up a few feet. The casino itself is old...old...old. Carpeting is old, stained and tired. Much like the elephant's graveyard, I truly believe this is where gamblers to go die. I played some texas hold 'em there and true to some of the 'press' the owner sat down and played with us. He was a nice enough guy but has some serious health problems and drank himself into a stupor while playing. The drink lady obviously knew him well and had been there for years. She was visibly concerned about his health and questioned his drinking...which just aggrevated the owner. It was not a pleasant scene and was actually depressing. The owner eventually staggered away. While at the table, I struck up a conversation with the guy next to me. We were having a pleasant conversation and this particular dealer ragged on us incessantly about 'table talking'. I like social games and that's half the fun but this guy ragged us to the point that we quit tipping him. The other guy eventually told the dealer to go ---- himself and left and I followed suit. The casino is a block off from the Fremont Street Experience and block you have to cross is a concern. The cab driver warned me not to be out at night in that area. He said there were a lot of crack heads and they were known to mug people. I ended up playing downtown a lot but made my way back before dark each evening. Careful Kitty's is ok. It's an old diner. Food was alright and the service was friendly. There were lots of old tired-looking people hanging around who appeared to have health related problems. I'm truly sorry for these people but I was there to have fun and it was just depressing. I went back there once with my girlfriend to show her the place. She couldn't believe I actually stayed there. She played some slots and then said that the place 'creeped' her out and she wanted to leave NOW... I'll stay downtown anytime and actually prefer it to the strip but I'll never make this mistake again. The room was cheap but I paid a much higher price by sacrificing my enjoyment. I've been to Vegas many times and this was, by far, the worse experience I've ever had.", "date": "2012-03-26 11:54:35 +0300", "ratings": { "Cleanliness": 2, "Overall": 1, "Rooms": 1, "Service": 3, "Value": 1 } } ], [ { "author": "Jo Collier", "content": "A decent-sized room for the low $100s two stops from Times Square on the express train. If you're looking to see New York (and not spend your days at your accommodation) Hotel Newton works very well. It's a nice place, seems well kept. Had no trouble at all-- worked great as a place to sleep and keep our stuff while we touristed. It is walking distance from few things, but the location's best because you're a block and a half from the 96th st station, which will take you downtown pretty quickly on an express train.", "date": "2014-06-11 09:35:15 +0300", "ratings": { "Cleanliness": 4, "Location": 3, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } }, { "author": "Cornelius Brakus", "content": "Stay away of this hotel!! With the same price you could have hotel with better location, clean room and own bathroom. Our room was very small, awfully cold, dirty (and the cleaning lady did not clean it while on our stay) and the shared bathroom was awful. Our stay did feel like we would be in a motel. Also, this is not a three star hotel as it did say on Booking.com, this is fairly a 1 star hotel, or more like a hostel.", "date": "2012-09-05 22:33:09 +0300", "ratings": { "Business service (e.g., internet access)": 1, "Check in / front desk": 2, "Location": 2, "Overall": 1, "Rooms": 1, "Service": 2, "Value": 2 } }, { "author": "Dorcas VonRueden", "content": "GOOD DEAL FOR THE PRICE AND LOCATION,a friendly,helpful staff..rooms are clean,rm 502,503 view of broadway.. nothing to see but cars.. quiet ,safe area,,rite aid close by,mcdonald's for nite snacks. Sept 2008 visit, 4 adults 2 rooms,..saved 500.00-600.00 each by staying here instead of Sheraton or Park Central. The Newton hotel is ideally located on the main subway line at 96th Street. An express Brooklyn bound train takes you to the heart of Times Sqaure in just a few minutes. We would stay here again.. looked at many sites, not disappointed in the pick..", "date": "2012-09-11 19:21:15 +0300", "ratings": { "Check in / front desk": 5, "Cleanliness": 5, "Location": 5, "Overall": 5, "Rooms": 5, "Service": 5, "Value": 5 } } ], [ { "author": "Joshua Rogahn", "content": "I am a very demanding traveller and the AVIA exceeded my expectations with the delivery of a 5 star hotel experience at a 3 star rate. Beautiful new hotel with outstanding room amenities (double sided fireplace, huge flatscreen TV's, tasteful and modern decoration, comfy beds etc.). Concierge was very helpful, connected and knowledgeable and it became readily apparent that she truly cares about the guests' experience in Napa. Restaurant recommendations were \"spot on\" and she booked us on a truly memorable, first class tour of the Napa Valley (at a fraction of the price and hassle of what we could have arranged ourselves). An all round excellent experience here.", "date": "2013-12-22 18:40:29 +0300", "ratings": { "Overall": 5 } }, { "author": "Madisyn Greenholt", "content": "What a wonderful find! Nestled in the heart of downtown is this \"urban oasis\" that delivers a warm and hospitable lodging experience. A definite departure from some of the \"teddy bear and lace\" experiences from previous trips, the AVIA Napa starts and ends with you feeling as if you were a long-lost member of the family, home for a short visit. The rooms are comfortable and inviting. Appointed with luxurious linens that covered one of the most comfortable beds that we have ever slept in. The bathrooms are bright and spacious with plenty of room for two. Our room had a lovely soaking tub and a large flat screen television. The restaurant only serves breakfast and lunch, which works out fine since most people are out wine tasting or shopping during the day. Breakfast was a feast for the eyes and the stomach, offering everything from steel cut oatmeal to perfect omelets. The dinner menu features a variety of delectable \"small plates\" with something for every palate. Everything was very good!", "date": "2013-11-10 19:53:53 +0300", "ratings": { "Cleanliness": 5, "Location": 5, "Overall": 5, "Rooms": 5, "Service": 5, "Value": 5 } }, { "author": "Griffin Barton", "content": "stayed here during my last trip. the rooms are clean. bathroom is big but not that functional. free wifi and bottled water. location is quite a walk from nathan road, so if you intent to go back and forth your hotel room you might find it a task. there is noise that you can hear inside the room on weekend nights because there are clubs near the hotel. overall it is still good value!", "date": "2014-05-05 23:33:30 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 5, "Rooms": 5, "Service": 4, "Sleep Quality": 5, "Value": 5 } }, { "author": "Marguerite Crist", "content": "Good location! Worth it to spend a little more on the deluxe room. Although for some weird reason the lift always smelled of cigarettes! Don't know why?!? Non smoking rooms no smell.", "date": "2013-10-21 19:04:09 +0300", "ratings": { "Cleanliness": 4, "Location": 5, "Overall": 4, "Rooms": 4, "Service": 3, "Value": 3 } } ], [ { "author": "Miss Alycia Schulist", "content": "Such an awesome & trendy hotel! As my husband says : 'Off it's head' Wish we got to stay longer. A surpise or two in our room each day, from lolliops to water to chocolates. Cant wait to get back there", "date": "2015-08-06 06:15:56 +0300", "ratings": { "Cleanliness": 5, "Overall": 5, "Service": 5, "Sleep Quality": 5, "Value": 5 } }, { "author": "Reynold O'Connell", "content": "We have just returned from a flying visit to Barcelona to visit family and friends. A great excuse to travel at any time but now having had the \"ME experience\" we are saving the pennies (or cents) at a furious rate so we can head back as soon as possible. The hotel is located just off Avenguda Diagonal, not so far from the \"Gherkin\" building and was easily reached by airport bus transfer and short taxi ride. First impressions at reception were very good indeed. It is a boutique style hotel and the mood is nicely understated - not pretentious but very welcoming. After a speedy check - in we were shown to our rooms on the 23 rd floor. We were very fortunate to be able to have booked a suite and nothing at all disappointed, from the spectacular views of the city to the high quality furnishings and extras provided. All the electronics are Sony, Philips etc. and the bathroom complimentaries are all high quality brands. The hotel provides just about everything in the room for your stay as standard and anything else is just a phone call to reception away. Our rooms also meant that we had access to the \"Level\". This is a lounge on the 25 th floor where guests can avail themselves of complimentary beer, wine, spirits and light snacks which are refreshed throughout the day. It's a great place to meet for breakfast or for drinks before you venture out into the city. The hotel restaurant has recently been awarded it's first Michelin star and we met the chef on a tour of the hotel. He took great pleasure in showing us his kitchens which were prepping up for that evenings sittings. And that also sums up the whole attitude of the staff at this hotel. They are all obviously proud of their hotel and the work that they do in there. If they can do anything for you, it is done well and with a lovely manner. Our stay in Barcelona was greatly enhanced by our stay in the ME hotel - I hope yours will be too", "date": "2014-05-11 05:34:53 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 5, "Rooms": 5, "Service": 5, "Sleep Quality": 5, "Value": 5 } }, { "author": "Elton Willms IV", "content": "When you arrive after a day of sightseeing at 5:30pm and your room is not yet cleaned... I leave it up to you to decide whether this is your type of hotel. So now you have to wait out in the passage or the foyer for them to clean the room...! (NO we did NOT accidentally leave the \"Do not disturb\" signs on the door or anything else that could have prevented them from cleaning the room - we were out of the room at 9am) Also have the following comments on the hotel; 1. Rooms on the small side 2. No Tea/Coffee facilities in the room - Room service took 35min to deliver 4 coffees at a cost of around EUR 20 3. No bath - sure the hotel is funcky but a nice bath after a day out is really nice 4. Agree with previous reviewer regarding the light/curtain swithes that can be confusing. I'm in IT and it took me a while to work it out. The curtain slider in our room was out of order. 5. Lighting in the room not suitable for getting any work done. Some people are lucky to go on a work trip or vacation without having to work at night, well I had to and it was very taxing on the eyes. 6. Location is NOT close to La Rambla or Gothic Q as suggested by other reviewers. No quick return to the hotel. Nearest tube station about 3 blocks away. Must say it is nice and quiet. 7. Privacy in bathroom. Guess some guests may find it spectacular - not me. If price is your determining factor, you may enjoy this hotel. Please do not expect old world charm. This is all very modern steel and glass.", "date": "2014-06-09 15:13:13 +0300", "ratings": { "Cleanliness": 3, "Location": 2, "Overall": 2, "Rooms": 2, "Service": 2, "Sleep Quality": 2, "Value": 3 } }, { "author": "Arjun Turner", "content": "We (me and my husband ) have been to many hotels all over Europe but I really don't think we will visit this particular one in the future again.We stayed at ME Barcelona between 11/09 to 17/09 during a medical congress my husband had to attend .Our room was viewing the pool and part of the city (it was at the 7th floor) ,but it wasn't the location that mattered at all .The room had only a chair next to the desk and a sofa beside the bed itself . There was no lamp on the desk and the lamp over the sofa didn't work .Also my reading lamp (on my side of the bed ) didn't work .The lighting therefore was very poor for anyone who would like to work or write or read . The only bearable spot to do all that was just ONE SIDE OF THE BED .Beside all this , (and the most annoying ) every time the shower in the room just over our own was used , water was running inside our OWN shower from the ceiling . Shall I mention that TV didn't work ? ( we didn't care about this that much though) .We mentioned the lamps and the shower problem to the concierge ( all of them are very friendly and speak very good english ) and as a result somebody knocked our door once and mentioned the lamps but at that particular time I was resting and couldn't receive him .No second attempt was made after that apparently . To the positive side I will mention that due to a party that would have taken place during our last night at the hotel we were offered a level room (20th floor )to avoid the inconvenience of the noise, where all lamps were working at least and you wouldn't have to fret if your unknown upper level neighbor would think to take his/her shower at the same time as you. Beside that ,breakfast was decent and for all that are kin in modern cold design the hotel is a treat .The area is a disadvantage though , the stench from the sewers was at some points unbearable the minute you stepped outside the hotel gate.", "date": "2014-09-08 13:41:38 +0300", "ratings": { "Cleanliness": 3, "Location": 2, "Overall": 2, "Rooms": 2, "Service": 2, "Sleep Quality": 4, "Value": 2 } }, { "author": "Miss Abelardo Mitchell", "content": "We stayed here for 4 nights in June having just spent 3 nights in the W Barcelona. We booked on Last Minute.com so got a cheaper price than normal room rates however it was still more expensive than other hotels closer to the city centre. We were wanting a bit of luxury for a week and thought Barcelona was ideal for a part relaxing beach/sun holiday and part city break. We only booked this hotel because it had a pool and a 5* rating. We arrived at the hotel and the check-in queue was enormous so we had a relaxing drink in the comfortable bar area. To be fair check in was quick once we got the front of the queue but the entire foyer area smelt a bit wierd. The place is trying too hard to be cool with dubious colour choices for furnishings and steel walls??!!! Our room was ok the bed very comfortable and we got a good nights sleep (we were woken every morning by the maids at about 9am though). The bathroom had no extractor ran that we could find and after a shower the condensation ran down the glass panel separating the room from the bathroom and left dirty marks on the window ledge. I wouldn't say the room was spotless but it was adequate. This hotel was in quite a poor location - ok so fairly close to the nearest tube station (10 mins walk) and tram stop (5 mins) but a way out of the city. Cabs in barcelona are fairly cheap though so this isn't really a massive issue. The worst part about our stay was that on our last day we were enjoying the sun in the pool area when we were asked to leave due to there being a private party in the area. There was no pre warning or notification of this and we had to get up and tramp down to the beach via the tube to enjoy our last day of sun (I am 5 months pregnant with twins so was hoping for a relaxing day!!!!!!!!) I wouldn't recommend this hotel if you are expecting 5* luxury. If you are happy for 3-4* quality and service in a fairly poor location this hotel could just be for you!", "date": "2013-11-27 03:52:23 +0300", "ratings": { "Cleanliness": 2, "Location": 1, "Overall": 3, "Rooms": 3, "Service": 2, "Sleep Quality": 4, "Value": 2 } }, { "author": "Abdullah Lubowitz", "content": "... all that glitters, is not gold and the Hotel Me really didn't hit a good note with me. We were here for a business convention and on first look, the hotel and the rooms look great - until you try to utilise them. The hotel is a taxi ride to any tourist areas of Barcelona or a 30 min walk. There is a decent area about 8 mins walk for restaurants but this is NOT a city centre hotel. The rooms are attempting to be model and minimalist but end up being unfunctional and uncomfortable. Here's my room issues: 1. No kettle/coffee maker in the room. Virtually unheard of in a hotel of it's \"class\". 2. Cement floor in room, slippery when wet and cold. Carpets, wood, whatever ... not this cheap alternative. 3. Chair at desk is not a work station chair but a cheap, \"trendy\" plastic design - not good. 4. Impossible to shower without getting the bathroom floor drenched. 5. The wrap around curtain on 2 walls ... whose idea was this? Only one wall is window but the curtain covers both and is VERY slow on it's automatic open/close. Furthermore, it didn't close all the way and left a 3 inch gap for the light to stream in at 6am. 6. There is a control panel for all the lights and AC. Each button pressed done something different, each time. Everybody I spoke to had this problem. 7 Outrageously priced mini-bar and room service (18Euro for a hamburger) and as your miles from anyway, it's a good weight loss hotel! Beds were good, TV was ok, other bathroom facilities good - and their maid service is some of the best I've seen. Other problems. Bar staff are worthless. People waiting to be served, while 2 of them stocked and cleaned, 1 served - very slowly. 5euro for a 330ml glass of tap beer is twice the price of anywhere we drank. Outside the elevators on every floor smelled of toilets - probably because the rooms toilets backed onto that area. Poor ventilation? Breakfast is a very generous 11am finish except at weekends when it's even better at 12noon. Arriving at 11.05 on a Saturday, we were told it was finished. Questioning why, \"because we have to set up for a lunch meeting in this room\". Even though we told her the note in the room said 12, when we checked in we were told 12 - she said there is nothing she could do, even though we could see a full buffet breakfast table and people eating. It was only after demanding a manager that another staff member made a call and let us in - it should not have came to this. Smokers - forget it if it rains, there is no area even remotely or partially covered outside! Overall, this hotel just failed. It has a few good points but it's not comfortable, doesn't provide you a feeling of luxury or a level of relaxation and just feels a bit like they don't know what they're doing.", "date": "2012-03-29 11:12:46 +0300", "ratings": { "Cleanliness": 5, "Location": 1, "Overall": 2, "Rooms": 2, "Service": 3, "Sleep Quality": 2, "Value": 1 } }, { "author": "Kory Schultz", "content": "We were booked into the ME for 9 nights, we checked out after 3, staff were very unfriendly and unhelpfull. the rooms are among the smallest Ive ever stayed in. Cannot understand how this hotel got rated with 5 star, no way, 3 star at best..The walls in room were marked, the corridors looked as if thay had never been hoovered. The sockets were loose. On the 2nd day, no one cleaned our room or made bed, we had to ring twice for toilet rolls and towels, The air con did not go down past 23. We couldnt wait to check out, we moved to the arts hotel where we found a real 5 star hotel", "date": "2014-05-19 00:36:42 +0300", "ratings": { "Cleanliness": 1, "Location": 2, "Overall": 1, "Rooms": 1, "Service": 1, "Value": 1 } }, { "author": "Curt Nolan", "content": "A visually stunning hotel. The rooms were compact but very well designed. No hint of problems with smells, music and drains that have been mentioned on previous reviews. BUT - two big problems: 1. After being told that I was entitled to one item of clothing to be ironed per day - complimentary, I gave my shirt to the very charming lady who showed me my room. The shirt didn't turn up until 45 minutes after I was supposed to leave the following morning making me late for a meeting. I also had to make several calls to get the shirt back. 2. The 22 Euro club sandwich and fries was inedible. A disgrace. It doesn't matter how beautiful and stylish a hotel is, if it can't get the basics right - it should and will fail. I would have whole heartedly recommended this hotel at 9pm on my day of arrival - now, I wouldn't. That's why it's a shame.", "date": "2014-08-09 00:49:46 +0300", "ratings": { "Cleanliness": 5, "Location": 3, "Overall": 2, "Rooms": 5, "Service": 1, "Value": 3 } } ], [ { "author": "Ozella Sipes", "content": "This was our 2nd trip here and we enjoyed it as much or more than last year. Excellent location across from the French Market and just across the street from the streetcar stop. Very convenient to several small but good restaurants. Very clean and well maintained. Housekeeping and other staff are all friendly and helpful. We really enjoyed sitting on the 2nd floor terrace over the entrance and \"people-watching\" on Esplanade Ave., also talking with our fellow guests. Some furniture could use a little updating or replacement, but nothing major.", "date": "2013-06-22 18:33:50 +0300", "ratings": { "Cleanliness": 5, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 5, "Value": 4 } }, { "author": "Barton Marks", "content": "We found the hotel de la Monnaie through Interval and we thought we'd give it a try while we attended a conference in New Orleans. This place was a perfect location and it definitely beat staying downtown at the Hilton with the rest of the attendees. We were right on the edge of the French Quarter withing walking distance of the whole area. The location on Esplanade is more of a residential area so you are near the fun but far enough away to enjoy some quiet downtime. We loved the trolly car right across the street and we took that down to the conference center for the conference days we attended. We also took it up Canal Street and nearly delivered to the WWII museum. From there we were able to catch a ride to the Garden District - a must see if you love old architecture - beautiful old homes(mansions). We at lunch ate Joey K's there and it was excellent. We ate so many places in the French Quarter I can't remember all the names. My husband loved all the NOL foods - gumbo, jambalya and more. I'm glad we found the Louisiana Pizza Kitchen right on the other side of the U.S. Mint (across the street from Monnaie). Small little spot but excellent pizza! The day we arrived was a huge jazz festival going on across the street. However, once in our rooms, you couldn't hear any outside noise. Just the train at night blowin it's whistle! We enjoyed being so close to the French Market and within walking distance of all the sites to see. And you can't pass up the Cafe du Monde down the street - a busy happenning place with the best French dougnuts!!!Delicious! We will defintely come back and would stay here again. We were not hounded to purchase anything. My husband only received one phone call regarding timeshare and the woman was very pleasant. The staff was laid back and friendly. My only complaint was the very firm bed. Other than that, we really enjoyed our stay. Thanks Hotel de la Monnaie!", "date": "2015-03-02 19:56:13 +0300", "ratings": { "Business service (e.g., internet access)": 4, "Check in / front desk": 4, "Cleanliness": 4, "Location": 4, "Overall": 4, "Rooms": 3, "Service": 3, "Value": 5 } } ] ], "type": "array" }, "state": { "#docs": [ 21, 2 ], "%docs": [ 91.3, 8.69 ], "samples": [ [ null ], [ "California" ] ], "type": [ "null", "string" ] }, "title": { "#docs": 23, "%docs": 100, "samples": [ "Death Valley National Park", "Gillingham (Kent)", "Joshua Tree National Park", "Paris/16th arrondissement", "Pitlochry" ], "type": "string" }, "tollfree": { "#docs": [ 22, 1 ], "%docs": [ 95.65, 4.34 ], "samples": [ [ null ], [ "+1-000-821-8277" ] ], "type": [ "null", "string" ] }, "type": { "#docs": 23, "%docs": 100, "samples": [ "hotel" ], "type": "string" }, "url": { "#docs": [ 2, 21 ], "%docs": [ 8.69, 91.3 ], "samples": [ [ null ], [ "https://paris-hotel-longchamp.c...", "https://www.number38thegower.co...", "https://www.syha.org.uk/hostels...", "https://www.walestouristsonline...", "https://www.yha.org.uk" ] ], "type": [ "null", "string" ] }, "vacancy": { "#docs": 23, "%docs": 100, "samples": [ false, true ], "type": "boolean" } }, "type": "object" }, { "#docs": 3, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "`type` = \"airline\"", "properties": { "callsign": { "#docs": 3, "%docs": 100, "samples": [ "BEE MED", "CYCLONE", "REUNION" ], "type": "string" }, "country": { "#docs": 3, "%docs": 100, "samples": [ "France", "United Kingdom", "United States" ], "type": "string" }, "iata": { "#docs": 3, "%docs": 100, "samples": [ "KJ", "UU", "ZA" ], "type": "string" }, "icao": { "#docs": 3, "%docs": 100, "samples": [ "CYD", "LAJ", "REU" ], "type": "string" }, "id": { "#docs": 3, "%docs": 100, "samples": [ 792, 1191, 1543 ], "type": "number" }, "name": { "#docs": 3, "%docs": 100, "samples": [ "Access Air", "Air Austral", "British Mediterranean Airways" ], "type": "string" }, "type": { "#docs": 3, "%docs": 100, "samples": [ "airline" ], "type": "string" } }, "type": "object" }, { "#docs": 49, "$schema": "https://json-schema.org/draft-06/schema", "Flavor": "`type` = \"airport\"", "properties": { "airportname": { "#docs": 49, "%docs": 100, "samples": [ "Hickam Air Force Base", "Joigny", "RNAS WATTON", "Sky Ranch at Carefree", "Villaroche" ], "type": "string" }, "city": { "#docs": 49, "%docs": 100, "samples": [ "Carefree", "Honolulu", "Joigny", "Melun", "WATTON" ], "type": "string" }, "country": { "#docs": 49, "%docs": 100, "samples": [ "France", "United Kingdom", "United States" ], "type": "string" }, "faa": { "#docs": [ 13, 36 ], "%docs": [ 26.53, 73.46 ], "samples": [ [ null ], [ "BZR", "GRI", "IGQ", "PRC", "RCA" ] ], "type": [ "null", "string" ] }, "geo": { "#docs": 49, "%docs": 100, "properties": { "alt": { "#docs": 49, "%docs": 100, "samples": [ 13, 173, 302, 732, 2568 ], "type": "number" }, "lat": { "#docs": 49, "%docs": 100, "samples": [ 21.318681, 33.8180947, 47.992222, 48.604725, 52.33 ], "type": "number" }, "lon": { "#docs": 49, "%docs": 100, "samples": [ -157.922427, -111.8979242, 0.51, 2.671119, 3.392222 ], "type": "number" } }, "samples": [ { "alt": 13, "lat": 21.318681, "lon": -157.922427 }, { "alt": 173, "lat": 52.33, "lon": 0.51 }, { "alt": 302, "lat": 48.604725, "lon": 2.671119 }, { "alt": 732, "lat": 47.992222, "lon": 3.392222 }, { "alt": 2568, "lat": 33.8180947, "lon": -111.8979242 } ], "type": "object" }, "icao": { "#docs": [ 7, 42 ], "%docs": [ 14.28, 85.71 ], "samples": [ [ null ], [ "18AZ", "EGYR", "LFGK", "LFPM", "PHIK" ] ], "type": [ "null", "string" ] }, "id": { "#docs": 49, "%docs": 100, "samples": [ 1310, 1384, 4346, 7055, 8397 ], "type": "number" }, "type": { "#docs": 49, "%docs": 100, "samples": [ "airport" ], "type": "string" }, "tz": { "#docs": 49, "%docs": 100, "samples": [ "America/Phoenix", "Europe/London", "Europe/Paris", "N", "Pacific/Honolulu" ], "type": "string" } }, "type": "object" } ] ], "status": "success", "metrics": { "elapsedTime": "441.291712ms", "executionTime": "441.241719ms", "resultCount": 1, "resultSize": 103887 }, "profile": { "phaseTimes": { "authorize": "753.932µs", "instantiate": "6.388µs", "parse": "151.233µs", "plan": "7.117µs", "run": "441.069318ms" }, "phaseOperators": { "authorize": 1 }, "executionTimings": { "#operator": "Authorize", "#stats": { "#phaseSwitches": 4, "execTime": "1.738µs", "servTime": "752.194µs" }, "privileges": { "List": [ { "Target": "travel-sample", "Priv": 7 } ] }, "~child": { "#operator": "Sequence", "#stats": { "#phaseSwitches": 1, "execTime": "9.743µs" }, "~children": [ { "#operator": "InferKeyspace", "#stats": { "#itemsOut": 1, "#phaseSwitches": 7, "execTime": "9.345µs", "kernTime": "438.011515ms" }, "keyspace": "travel-sample", "namespace": "", "using": "default" }, { "#operator": "Stream", "#stats": { "#itemsIn": 1, "#itemsOut": 1, "#phaseSwitches": 6, "execTime": "2.257622ms", "kernTime": "438.028393ms" } } ] }, "~versions": [ "7.0.0-N1QL", "7.0.0-1784-enterprise" ] } } } |
EXPLICAR
Explain te dice el plan de consulta para cada consulta - los índices elegidos, los predicados y otros pushdowns, tipos de join, orden de join, etc. Tanto MongoDB como Couchbase producen explain en forma JSON - algo natural para bases de datos JSON.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 |
MongoDB Enterprise > db.CUSTOMER.find({zip:94040}).explain() { "queryPlanner" : { "plannerVersion" : 1, "namespace" : "test.CUSTOMER", "indexFilterSet" : false, "parsedQuery" : { "zip" : { "$eq" : 94040 } }, "winningPlan" : { "stage" : "FETCH", "inputStage" : { "stage" : "IXSCAN", "keyPattern" : { "zip" : 1 }, "indexName" : "zip_1", "isMultiKey" : false, "multiKeyPaths" : { "zip" : [ ] }, "isUnique" : false, "isSparse" : false, "isPartial" : false, "indexVersion" : 2, "direction" : "forward", "indexBounds" : { "zip" : [ "[94040.0, 94040.0]" ] } } }, "rejectedPlans" : [ ] }, "serverInfo" : { "host" : "MacBook-Pro-4.attlocal.net", "port" : 27017, "version" : "4.0.0", "gitVersion" : "3b07af3d4f471ae89e8186d33bbb1d5259597d51" }, "ok" : 1 } MongoDB Enterprise > |
En Couchbase, simplemente precedes la sentencia con EXPLAIN. Puedes explicar cualquier sentencia en N1QL.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 |
EXPLAIN SELECT * FROM CUSTOMER WHERE zip = 94040; [ { "plan": { "#operator": "Sequence", "~children": [ { "#operator": "IndexScan3", "index": "ix_customer", "index_id": "b312ed00505a074d", "index_projection": { "primary_key": true }, "keyspace": "CUSTOMER", "namespace": "default", "spans": [ { "exact": true, "range": [ { "high": "94040", "inclusion": 3, "low": "94040" } ] } ], "using": "gsi" }, { "#operator": "Fetch", "keyspace": "CUSTOMER", "namespace": "default" }, { "#operator": "Parallel", "~child": { "#operator": "Sequence", "~children": [ { "#operator": "Filter", "condition": "((`CUSTOMER`.`zip`) = 94040)" }, { "#operator": "InitialProject", "result_terms": [ { "expr": "self", "star": true } ] } ] } } ] }, "text": "SELECT * FROM CUSTOMER WHERE zip = 94040;" } ] |
El banco de trabajo de consultas también tiene una explicación visual junto con la creación de perfiles. (para una consulta)
La cláusula "GROUP BY" de MongoDB forma parte de la API aggregate(). He aquí la comparación.
A diferencia de SQL y N1QL, la API de consulta de MongoDB tiene mucho significado implícito sin definiciones formales. Con N1QL, conoces las agrupaciones (b y c) y agregaciones (SUM(a)) explícitamente.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
/* MongoDB */ Grouping and aggregation is combined. $group : { [ { a:”$a”}, {b:”$b”}, {c: “$c”}, count: { $sum: 1 } ] } /* Couchbase: N1QL */ SELECT b, c, SUM(a) FROM t GROUP BY b, c |
|
1 2 3 4 5 6 |
/* MongoDB */ ORDER BY { $sort : { age : -1, posts: 1 } } /* Couchbase: N1QLL */ ORDER BY age DESC, posts ASC |
OFFSET y LIMIT
Estos se utilizan comúnmente para el método de paginación offset. tanto Mongo y Couchbase apoyo. Sin embargo, paginación de teclas es un enfoque superior que utiliza menos recursos y rinde mejor. Mongo utiliza las cláusulas $skip y $limit y N1QL utiliza OFFSET y LIMIT. No estoy seguro de las optimizaciones de paginación realizadas en MongoDB.
Las uniones suelen desaconsejarse en las bases de datos NoSQL y en MongoDB en particular. Pero el mundo real es complejo y no se puede desnormalizar en una sola colección. MongoDB tiene el operador $lookup para el join y hace un bucle anidado entre una colección (potencialmente sharded) a otra colección (no puede ser sharded). En Couchbase, todos los buckets están particionados (sharded). Operaciones JOINs (INNER JOIN, LEFT OUTER JOIN, RIGHT OUTER JOIN, joins con subconsultas, NEST y UNNEST) Tenemos un artículo detallado que muestra las operaciones equivalentes entre MongoDB y JSON. Le recomiendo que lea el artículo Uniendo JSON: Comparando Couchbase y MongoDB.
| Tipo de JOIN | MongoDB | Couchbase |
| INNER JOIN | No. $lookup es un join externo izquierdo limitado sólo en colecciones no separadas. Las aplicaciones tienen que hacer eso y luego eliminar los documentos sin los documentos coincidentes. | La cláusula ON requiere una referencia a la clave del documento. Sólo Equi-join |
| LEFT OUTER JOIN | Búsqueda limitada 1TP4.
No se pueden unir matrices. Es necesario aplanar las matrices manualmente antes de la unión. |
Unión exterior izquierda completa que incluye predicados de matriz en la cláusula ON. |
| UNIÓN EXTERNA DERECHA | No compatible. Debe gestionarse en la aplicación | Compatibilidad limitada con RIGHT OUTER JOIN; se ha solucionado utilizando otros JOINs. |
| UNIÓN EXTERNA COMPLETA | No compatible. Debe gestionarse en la aplicación | Trabajado alrededor con el uso de otros JOINs. |
|
1 2 3 4 5 6 7 8 9 |
/* MongoDB */ db.grantPrivilegesToRole() db.revokePrivilegesFromRole() /* Couchbase: N1QL */ GRANT query_select ON orders, customers TO bill, linda; REVOKE query_update ON `travel-sample` FROM debby |
ÍNDICES
A continuación se muestra una visión general de las capacidades de índice de MongoDB y Couchbase. Ambos tienen una gran variedad de índices. Los tipos de índices de Couchbase y su uso están bien documentados en el artículo: Cree el índice correcto y obtenga el rendimiento adecuado. Además, Couchbase cuenta con un asesor de índices integrado para la declaración individual así como el carga de trabajo y, además, tiene la Servicio Index Advisor que se actualiza mensualmente.
| Tipo de índice | MongoDB | Couchbase |
| Índice primario | Escaneado de tablas, índice primario | Índice primario |
| Índice secundario | Índice secundario | Índice secundario |
| Índice compuesto | Índice compuesto | Índice compuesto |
| Índice funcional
(Índice de expresión) |
No disponible | Índice funcional, Índice de expresión |
| Índice parcial | No disponible | Índice parcial |
| Índice de rango particionado | Rango particionado, Intervalo, Lista, Ref, Hash, Índice híbrido particionado | Alcance manual particionado mediante Índice parcial |
| ARRAY Índice | 1. Índice basado en árbol B con una clave de matriz por índice.
2. La clave de una matriz puede ser simple o compuesta (multiclave). |
1. Índice basado en árbol B con una clave de matriz por índice.
2. La clave de la matriz puede ser compuesta 3. Uso de SEARCH(): Índice basado en árbol invertido con un número ilimitado de claves de matriz por índice. |
| Índice de matrices en expresiones | No disponible | Sí |
| Objetos | Sí | Sí |
BÚSQUEDA DE TEXTO COMPLETO
El producto MongoDB tiene incorporado búsqueda de texto y ahora está experimentando con la integración de Lucene en su servicio Atlas a través de la aplicación 1TP4Buscarbeta función. Couchbase tiene un indexación de búsqueda de texto completo que puedes ejecutar en tu portátil y en el clúster. De nuevo, tenemos un artículo detallado que compara el búsqueda de texto característica por característicacon ejemplos. Couchbase 6.5 integra el FTS con N1QL, haciendo que la consulta vaya aún más lejos.
OPTIMIZADOR
Un optimizador de consultas intenta reescribir la consulta para optimizarla mejor, elegir el índice más apropiado, decidir el pushdown del índice, el orden de unión, el tipo de unión y crea un plan que el motor puede ejecutar. Cada base de datos tiene un optimizador especializado que entiende las capacidades y peculiaridades del motor.
| Característica | MongoDB | Couchbase |
| Tipo de optimizador | Consulta basada en la forma | Basado en reglas |
| Selección del índice | Consulta basada en la forma | Basado en reglas
Basado en los costes (vista previa en 6.5) |
| Reescritura de consultas | No | Sí, limitado. |
| JOIN Orden | Tal y como está escrito, procedimental utilizando el marco de agregación | Especificado por el usuario (de izquierda a derecha) |
| Tipo de unión | Bucle anidado | Bucle anidado
Unión Hash |
| CONSEJOS | Sí. $hint | Sí.
USAR ÍNDICE, USAR HASH |
| EXPLICAR | 1TP4Explicar | EXPLICAR |
| Explicación visual | Sí | Sí. |
| Perfiles de consulta | Sí | sí |
TRANSACCIONES
Las bases de datos NoSQL se inventaron para evitar el SQL y las transacciones. Con el tiempo, cada base de datos está añadiendo uno u otro, ¡o ambos! MongoDB ha añadido transacciones multidocumento con aislamiento de instantáneas. Couchbase ha añadido transacciones multidocumento con aislamiento de lectura comprometida. Las transacciones multidocumento siguen sin ser compatibles con N1QL.
| Característica | MongoDB | Couchbase |
| Actualizaciones del índice | Los índices se actualizan de forma sincrónica | Los índices se actualizan de forma asíncrona |
| Atomicidad | Documento único
Multidocumento (en 4.2) |
Documento único
Multidocumento (en 6.5) |
| Coherencia | Los datos y los índices se actualizan de forma sincrónica. Por defecto, lectura sucia en Datos e índices. | El acceso a los datos es siempre coherente
Los índices tienen varios niveles de coherencia (UNBOUNDED, AT_PLUS, REQUEST_PLUS) |
| Aislamiento | Por defecto: Lectura sucia
Transacción: Aislamiento de instantáneas |
Bloqueo optimista con comprobación CAS
Transacciones: Aislamiento atómico monotónico |
| Durabilidad | Duradero con opción mayoritaria de escritura. | Durable con confirmación tras la replicación |
ANÁLISIS
Análisis de Couchbase está diseñado para ofrecerle información sobre sus datos JSON sin ETL: NoETL para NoSQL. Los datos JSON en el almacén de datos clave-valor se copian en el servicio de análisis que distribuye los datos en su almacenamiento. El servicio de consulta Couchbase, servicio de datos está diseñado para manejar un gran número de operaciones concurrentes o consultas para ejecutar las aplicaciones. El servicio de análisis está diseñado para analizar un gran número de documentos con el fin de obtener información sobre el negocio. En términos tradicionales, el servicio de análisis está diseñado para OLAP y el resto para OLTP. MongoDB no tiene un servicio de análisis equivalente. Tendrías que sobrecargar tu cluster existente con cargas de trabajo tanto OLTP como OLAP. Como aprenderás, no hay almuerzo gratis. Los grandes escaneos necesarios para la carga de trabajo analítica afectarán a las latencias de sus consultas OLTP. A continuación, empiece a asignar nuevos nodos para sus copias secundarias y terciarias de los datos en los que puede realizar la carga de trabajo de lectura. ¿Qué ocurrirá o debería ocurrir en caso de conmutación por error? El secundario toma el relevo, pero de nuevo afecta a tu carga de trabajo OLTP.
Hay una segunda razón para tener un servicio distinto: el procesamiento de consultas para analítica requiere un enfoque diferente al de las consultas OLTP. Hay un gran conjunto de recursos para que usted aprenda acerca de este servicio, incluyendo el libro de Don Chamberlin, co-inventor de SQL.
- SQL++ para USUARIOS de SQL: UN TUTORIAL: https://resources.couchbase.com/analytics/sql-book
- Couchbase Analytics: Under the Hood - Connect Silicon Valley 2018: https://www.youtube.com/watch?v=1dN11TUj58c
- De SQL a NoSQL
- Más allá de filas y columnas: A la cuarta va la vencida - Couchbase Connect 2016: https://www.youtube.com/watch?v=HVJNxgLKtbo
- NoETL para NoSQL - Análisis en tiempo real con Couchbase: https://www.youtube.com/watch?v=MIno71jTOUI
- N1QL: ¿Consultar o analizar?
- Parte 2: N1QL: ¿Consultar o analizar?
Resumen: Part Deux
Las bases de datos son extraordinariamente útiles. Son matizables y también pegajosas. Son esenciales para la civilización. Los sumerios inventaron la escritura para procesar transacciones: crear una base de datos con tablillas de arcilla para llevar la cuenta de los impuestos, las tierras, el oro y averiguar información. Siempre habrá bases de datos. Cada base de datos es diferente, ya sean bases de datos SQL o bases de datos NoSQL. No todas las bases de datos SQL son iguales. No todas las bases de datos NoSQL son iguales. Comprender las diferentes bases de datos aumenta la flexibilidad y la eficacia de su organización.
RECURSOS: Segunda parte
- SQL++ para USUARIOS de SQL: UN TUTORIAL: https://resources.couchbase.com/analytics/sql-book
- N1QL Guías prácticas
- Blogs de Couchbase 6.5: https://www.couchbase.com/blog/tag/6.5/