Index advisor for N1QL Statement (ADVISE statement ) es oficialmente lanzado en Couchbase Server 6.6.
Está diseñado hacer los mejores esfuerzos proporcionar índice secundario global recomendación para cada espacio clave en la consulta que es mejor que todos los índices existentes actualmente y los índices en construcción diferida.
Veamos más explicaciones sobre las partes destacadas de la funcionalidad:
-
- Mejores esfuerzos:
- No se garantiza la exhaustividad: no se recomiendan índices cuando no hay predicados ni filtros derivados.
- Corrección sin falsos positivos.
- Sólo recomienda índices GSI, no recomienda índices primarios.
- La recomendación de índices se realiza para cada espacio de claves implicado en la consulta.
- Mejor: El optimizador de consultas preferirá el índice recomendado a todos los demás índices existentes en la ejecución de la consulta. Sin embargo, no se garantiza que el índice recomendado sea el óptimo para la consulta. En la versión actual, el asesor de índices sólo es compatible con el optimizador de consultas basado en reglas. El optimizador de consultas basado en costes estará disponible en la próxima versión.
- Mejores esfuerzos:
Con el fin de mejorar la robustez de la funcionalidad anterior y aportar continuamente mejoras al asesor de índices, se han introducido algunas características innovadoras en esta versión, este artículo profundizará en los detalles de diseño de varias de ellas.
Marco de verificación de índices virtuales
Para una recomendación de índice de cobertura, garantizar la corrección de la propiedad de cobertura es muy difícil debido a la complejidad de los objetos anidados en los índices ARRAY tanto para los predicados ARRAY como para la operación UNNEST. Para para asegurarse de que el índice de cobertura recomendado puede construir una exploración de cobertura real en la ejecución de la consulta, se ha introducido un nuevo marco de retroalimentación con fines de verificación.
Como se muestra en el siguiente diagrama, el asesor de índices crea índices GSI virtuales para los candidatos a índice de cobertura recomendados y retroalimenta al optimizador de consultas para verificar si serían seleccionados por el optimizador entre todos los demás índices existentes para generar un plan de ejecución. El índice virtual es una estructura de datos en memoria que imita los metadatos de un archivo índice normal y permite al optimizador considerarlo igual que los demás índices normales al generar operadores de exploración de índices. Si el índice virtual aparece en un operador de escaneo de cobertura en la fase de verificación, confiamos en devolverlo, ya que se comportará de la misma manera tras ser creado por los usuarios.
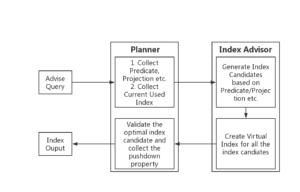
Al mismo tiempo, el bucle de retroalimentación de verificación también ayuda a evaluar las propiedades pushdown de los índices de cobertura recomendados. Hay un nuevo campo en la salida de los índices de cobertura como "index_property" para proporcionar las propiedades de pushdown del índice de la siguiente manera:
-
- Pulsador LIMIT
- OFFSET pushdown
- pushdown de ORDEN
- empuje de GROUPBY & AGGREGATES
- FULL GROUPBY & AGGREGATES pushdown
Una vez establecida esta función, estamos listos para explorar las nuevas áreas que se describen a continuación.
Index Pushdowns en las recomendaciones sobre índices de cobertura
Los pushdowns de índices son optimizaciones de rendimiento en las que el motor de consulta traslada más trabajo al indexador.
El asesor de índices se esfuerza al máximo por explorar la posibilidad de recomendar índices de cobertura con mayores propiedades de pushdown para mejorar aún más el rendimiento de la consulta.
Como se muestra en el diagrama siguiente, se aplicarán tres tipos de pushdowns sobre el índice de cobertura: GROUP BY/agregado, ORDER BY y limit/offset cuando corresponda. Vamos a entrar en los detalles de cada uno de ellos.
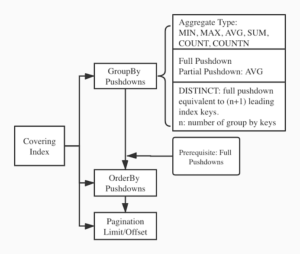
Índice Agrupación/Agregación
Index Advisor sigue el diseño de Agrupación y agregación de índices en los siguientes aspectos:
-
- Soporta seis tipos de agregaciones: MIN, MAX, AVG, SUM, COUNT y COUNTN.
- Esfuerzos para ajustar el orden de las claves de índice para lograr una agregación total/parcial que mejore el rendimiento.
- La agregación completa se refiere al escenario en el que el indexador se encarga de la agregación completa del grupo, lo que permite al motor de consulta omitir todo este operador.
- En agregación parcial, El indexador envía la agregación parcial de grupos a la consulta y responde a la consulta para fusionar los resultados intermedios y crear el grupo final y el operador de agregación.
-
- Tratamiento especial de la agregación DISTINCT, que sólo es posible cuando se aplican desgloses completos.
Requisitos previos:
-
- Todos los predicados se traducen exactamente a escaneos de rango con un índice de cobertura, no hay JOIN ni NEST en la consulta.
Cómo funciona para Agregados sin DISTINTO:
-
- Generar claves de índice basadas en predicados, siguiendo las reglas de recomendación de índices.
- Ajuste las posiciones de las claves GROUP BY para que sean equivalentes/dependientes de las claves de índice principales omitiendo las de los predicados de igualdad, mientras que tl orden dentro de estas claves GROUP BY no importa.
- Para aquellas expresiones GROUP BY que no sean equivalentes/dependientes de las claves de índice, añádalas a las claves de índice.
- Para aquellas expresiones GROUP BY equivalentes a la condición de índice, mueva la condición de índice a las claves de índice.
- Añadir proyecciones para generar un índice de cobertura, con unLas expresiones ggregate pueden estar en cualquier parte de las claves del índice o depender de las claves del índice o meta().id.
Cómo funciona para Agregados w DISTINCT :
-
- Sólo cuando se aplica el empuje total.
- Las mismas reglas anteriores se aplican a las expresiones GROUP BY.
- Las expresiones agregadas distintas deben ser equivalentes a/dependientes de (n+1) claves de índice principales omitiendo las de los predicados de igualdad, en las que n representa el número de elementos GROUP BY.
Ordenación por índices
Cuando las claves ORDER BY están alineadas con el orden de las claves del índice, el optimizador de consultas puede omitir la generación del operador ORDER BY. El Asesor de Índices hace todo lo posible para realizar el ajuste correspondiente.
-
- Reubique las claves de índice ORDER BY sobre los pushdowns GROUP BY/Aggregate o índices de cobertura normales si GROUP BY no existe para generar índices con propiedades pushdown ORDER BY.
- Sólo se aplica en la parte superior de los pushdowns FULL GROUP BY/Aggregate.
- Las expresiones ORDER BY siguen el orden de las claves de índice omitiendo las de los predicados de igualdad.
- Cuando el término ORDER BY se pueda desplazar hacia abajo, añada "DESC" al término que tiene orden descendente.
- A diferencia de los pushdowns GROUP BY/Aggregate, el orden dentro de los términos ORDER BY importa. En los casos en los que existan tanto GROUP BY como ORDER BY en la consulta, pero los pushdowns de índice no puedan cumplirse juntos, el asesor de índices los procesará por separado y se basará en el marco de verificación mencionado anteriormente para elegir el mejor.
Paginaciones
El asesor de índices no tiene un procesamiento específico para las reducciones de límites/desplazamientos, de hecho se aplicará sobre las dos reducciones anteriores si existe alguna de ellas o se aplicará directamente al índice de cobertura original.
Veamos varios ejemplos como se muestra a continuación, en los que la propiedad pushdown será verificada por el bucle de retroalimentación del índice virtual y se mostrará en la "pushdown_property" si procede.
Ejemplo 1:
|
1 2 3 4 |
ADVISE SELECT sum(d) FROM shellTest WHERE a = 10 and b < 10 and c is not null GROUP BY c |
La salida del índice de cobertura se muestra a continuación, en la que la expresión GROUP BY "c" se ha ajustado para que esté justo después de la clave de índice "a" que proviene del predicado de igualdad.
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "FULL GROUPBY & AGGREGATES pushdown, GROUPBY & AGGREGATES pushdown", "index_statement": "CREATE INDEX adv_a_c_b_d ON `shellTest`(`a`,`c`,`b`,`d`)", "keyspace_alias": "shellTest" } ] |
Ejemplo 2:
|
1 2 3 4 5 |
ADVISE SELECT c11 FROM shellTest WHERE test_id = \"advise\" ORDER BY c11 DESC LIMIT 2 |
En esta salida, "c11" puede ser objeto de un pushdown ORDER BY, por lo que se añade "DESC" a esta clave de índice.
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "ORDER pushdown, LIMIT pushdown", "index_statement": "CREATE INDEX adv_test_id_c11DESC ON `shellTest`(`test_id`,`c11` DESC)", "keyspace_alias": "shellTest" } ] |
Ejemplo 3:
|
1 2 3 4 |
ADVISE SELECT avg(c), sum(DISTINCT d) FROM shellTest WHERE a = 10 and b < 10 GROUP BY b |
En este ejemplo, hay un agregado DISTINTO en "d".
El agregado DISTINCT sólo se aplica al pushdown completo con expresión de agregado DISTINCT en las (n+1) claves principales.
- "a" proviene del predicado de igualdad, omitido.
- "b" sigue como expresión GROUP BY.
- Las claves de índice de los predicados y GROUP BY cumplen los requisitos para los pushdowns completos.
- "d" vendrá después de la expresión GROUP BY "b" y delante de "c", ya que procede del agregado DISTINCT.
El resultado de salida:
|
1 2 3 4 5 6 7 |
"covering_indexes": [ { "index_property": "FULL GROUPBY & AGGREGATES pushdown, GROUPBY & AGGREGATES pushdown", "index_statement": "CREATE INDEX adv_a_b_d_c ON `shellTest`(`a`,`b`,`d`,`c`)", "keyspace_alias": "shellTest" } ] |
Resumen
Index Advisor hace todo lo posible por optimizar los índices recomendados para mejorar el rendimiento de las consultas. El marco de verificación mejora la corrección y la solidez, y la compatibilidad con los pushdowns de índices mejorará aún más el rendimiento de las consultas.